
 起点课堂会员权益
起点课堂会员权益GPT-Image-2 的护城河不是「好看」,是「听话」
GPT-Image-2的突破性表现彻底改写了AI工具的产品竞争逻辑。从精准还原小学数学试卷到一键生成抖音直播界面,这款工具不仅实现了视觉上的以假乱真,更在理解中文排版规则、界面设计规范等深层逻辑上展现了质变。本文将深度解析其11个实战玩法,拆解OpenAI如何通过「听话」三层理论颠覆传统AI生图市场,并揭示这一技术突破背后的商业战略与行业影响。

当 AI 能生成以假乱真的数学试卷和抖音直播界面,OpenAI 这次真正打穿的,是产品竞争的底层逻辑。
一、一道小学数学试卷,击穿了一个时代
互联网上有一句话,叫「有图有真相」。
这句话活了将近二十年。它是普通人在信息洪流里核实事实的最后一道心理防线。哪怕 AI 生图已经铺天盖地,大家还是有一套心照不宣的鉴别方法:看文字。只要图里出现复杂的中文排版,或者某款 App 的真实界面,AI 就会立刻露馅——错别字、乱码、字体错位、UI 层级混乱,这些都是机器留下的「指纹」。
直到 2026 年 4 月,这套方法失效了。
有人用一句话——「生成广州市小学数学试卷」——让 GPT-Image-2 输出了一张图。卷头标题、填空题下划线、几何图形标注、宋体楷体混排的版式节奏,全部精准还原。第一眼看,就是一张拿手机对着真实考卷随手拍出来的照片。没有错字,没有乱码,连试卷特有的版式呼吸感都对了。
这不是「AI 画得更好看了」的问题。好看是量变。
但这张试卷解决的是另一个问题——这个模型开始真正理解「规则」:中文字符的结构规则、试卷的排版规则、教育场景的视觉逻辑规则。这是质变。
而质变,意味着竞争格局要重新洗牌了。
二、「听话」分三层,越往上越值钱
在进入玩法之前,先纠正一个普遍存在的认知偏差:GPT-Image-2 和你印象中的 AI 生图工具,根本不是同一类产品。
过去我们用 Midjourney,用的是它的「美」——风格化的光影、电影感色调、令人惊叹的艺术质感。那是一个以「美学输出」为核心的工具,本质上是人在配合机器。
GPT-Image-2 解决的是另一个问题——「准」。
「准」分三层,越往上越稀缺:

第三层是最少被讨论、但最有价值的。同样的任务「生成人类进化 10×10 网格图」,GPT-Image-2 不到两分钟交卷;Gemini 的回复是:
“I cannot generate a 10×10 grid in a single static image while keeping all the information readable.”
一句话,直接认输。这不是参数量的差距,是产品方向的差距。
这三层「听话」,构成了一条别人难以复制的能力梯度。用起来也更简单——打开 ChatGPT,点击「+」,选「创建图片」,免费用户可以直接用,一两句自然语言就够了。方向彻底反了:机器在配合人。
三、11 个真实玩法 + 可直接使用的提示词
以下每个玩法都附有可直接复制的提示词模板,按照「适用人群 → 场景 → 提示词 → 效果」的结构呈现。
方向一:中文内容生产
最刚需的方向。中国是全球最大的电商市场、最活跃的短视频市场,视觉内容生产量惊人,且高度依赖中文文字排版——这正是 GPT-Image-2 最直接打穿的场景。
玩法 1:电商主图一键出图(含中文排版文案)
适用人群: 电商运营、中小卖家、内容团队
痛点场景: 过去做一张促销海报,流程是:AI 生底图 → PS 手动加中文文案 → 设计师排版调整 → 反复确认出图。少则半天,多则两三天。
提示词模板:
生成一张[产品名]电商主图,背景[颜色/材质风格],产品居中特写, 左上角叠加活动文案「[XX元起/限时折扣/买一送一]」, 文案字体加粗宋体,颜色[白色/红色],字号醒目, 整体风格[简洁高端/年轻活泼/国潮复古], 高分辨率,适合淘宝/京东主图尺寸。

实际效果: 图文合一直接出图,中文文案位置、字体、排版全部正确,无需再开 PS。
玩法 2:教育类图文一体内容
适用人群: 教育机构内容团队、教师、家长
痛点场景: 教学演示图过去只能找外包或用 PPT 硬拼,AI 生图一遇中文公式和版式就露馅。
提示词模板:
生成一张[初中数学/小学语文/高中物理]知识点总结卡片, 主题是「[勾股定理/成语辨析/牛顿第二定律]」, 包含:核心公式、图示说明、关键考点标注(3条以内), 版式参考教辅书排版风格,宋体配楷体, 白底,有轻微卷面纸张质感,整体清晰可读。

实际效果: 公式、图示、中文排版同时正确,可以直接打印给学生复习,或投影用于课堂教学演示。
玩法 3:小红书 / 公众号配图(带文字叠加)
适用人群: 内容创作者、新媒体运营
痛点场景: 发配图还要开美图秀秀加字,效率低、字体丑、风格不统一。
提示词模板:
生成一张小红书风格配图, 图片上叠加文字排版: 主标题「[你的标题]」(大字、白色加粗、居中) 副标题「[副标题或一句话描述]」(小字、米白色、主标题正下方) 背景是[咖啡馆室内/户外旅行场景/极简生活美学], 整体色调[暖棕/马卡龙/低饱和度清新],竖版构图。

实际效果: 直接可发,不需要再用第三方工具加字,风格一致,字体清晰。
方向二:界面与原型设计
最惊艳产品经理和运营的方向。不需要 Figma,不需要设计师,一句话出原型图。
玩法 4:App 界面原型图(产品经理专用)
适用人群: 产品经理、创业团队
痛点场景: 向设计师或老板描述界面想法时,光靠文字说不清楚,画草图又太丑。
提示词模板:
生成一张移动端 App 界面截图, 功能模块:[在线学习/健身打卡/记账管理], 界面包含: – 顶部导航栏(标题 + 返回按钮) – 主内容区([具体模块:如课程列表/打卡日历/支出图表]) – 底部 Tab 栏([首页/发现/我的] 三个标签) UI 风格参考[微信/得物/小红书]的设计语言, [浅色/深色]主题,像素级真实感,高分辨率。
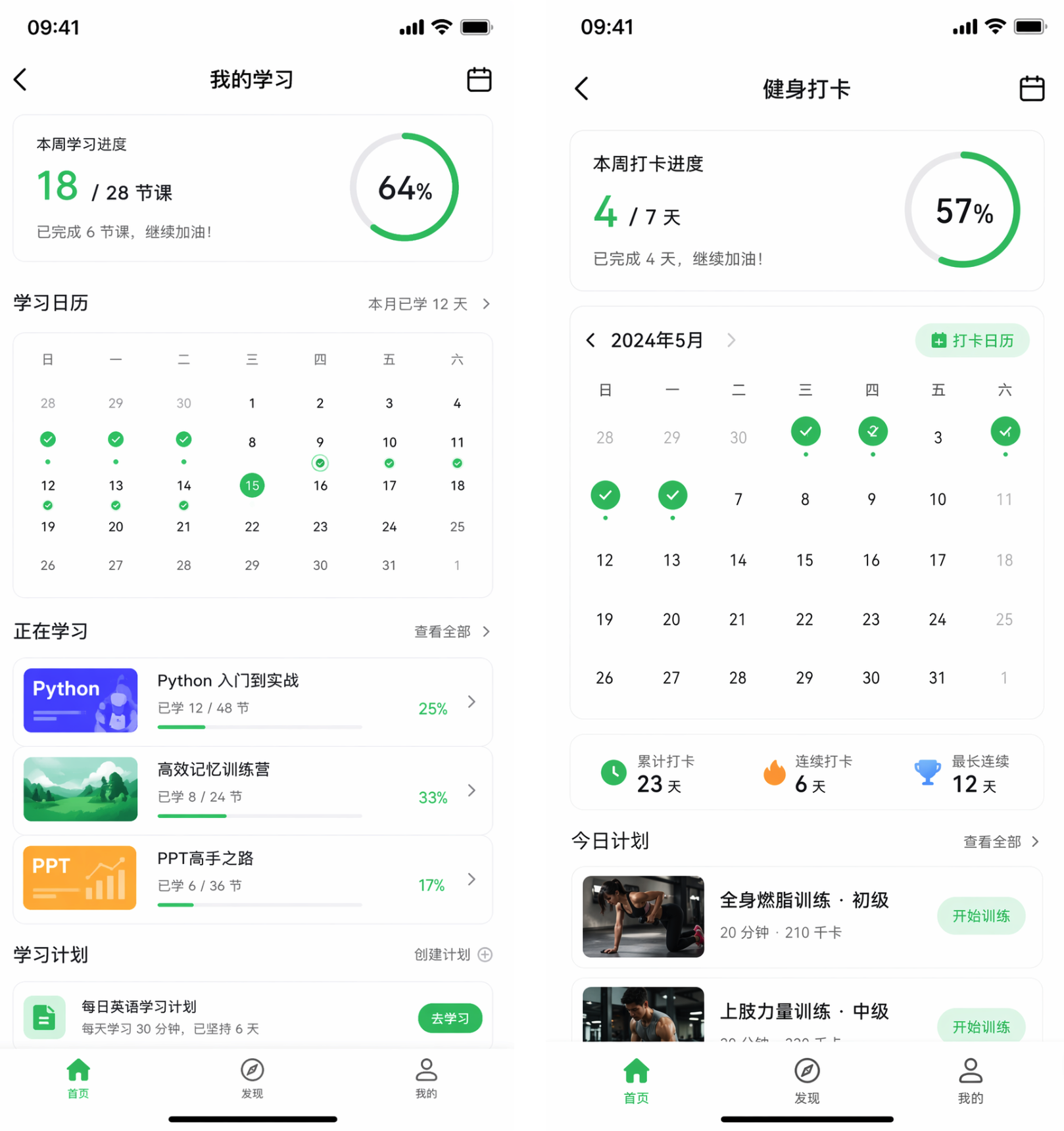
实际效果: 直接截图放进 PRD,或者用来和设计师沟通视觉方向,省去手绘原型的时间。
玩法 5:数据大屏 / Dashboard
适用人群: 产品经理、方案设计、运营汇报
提示词模板:
生成一张企业数据大屏截图, 主题:[销售数据看板/用户增长监控/物流实时数据], 包含图表:折线图(趋势)+ 柱状图(对比)+ 饼图(占比), 数据标签清晰,数值用合理的模拟数字, 顶部显示:公司名称 + 当前日期, 整体风格:深色背景 + 蓝紫渐变 + 科技感, 像真实运营系统的截图。
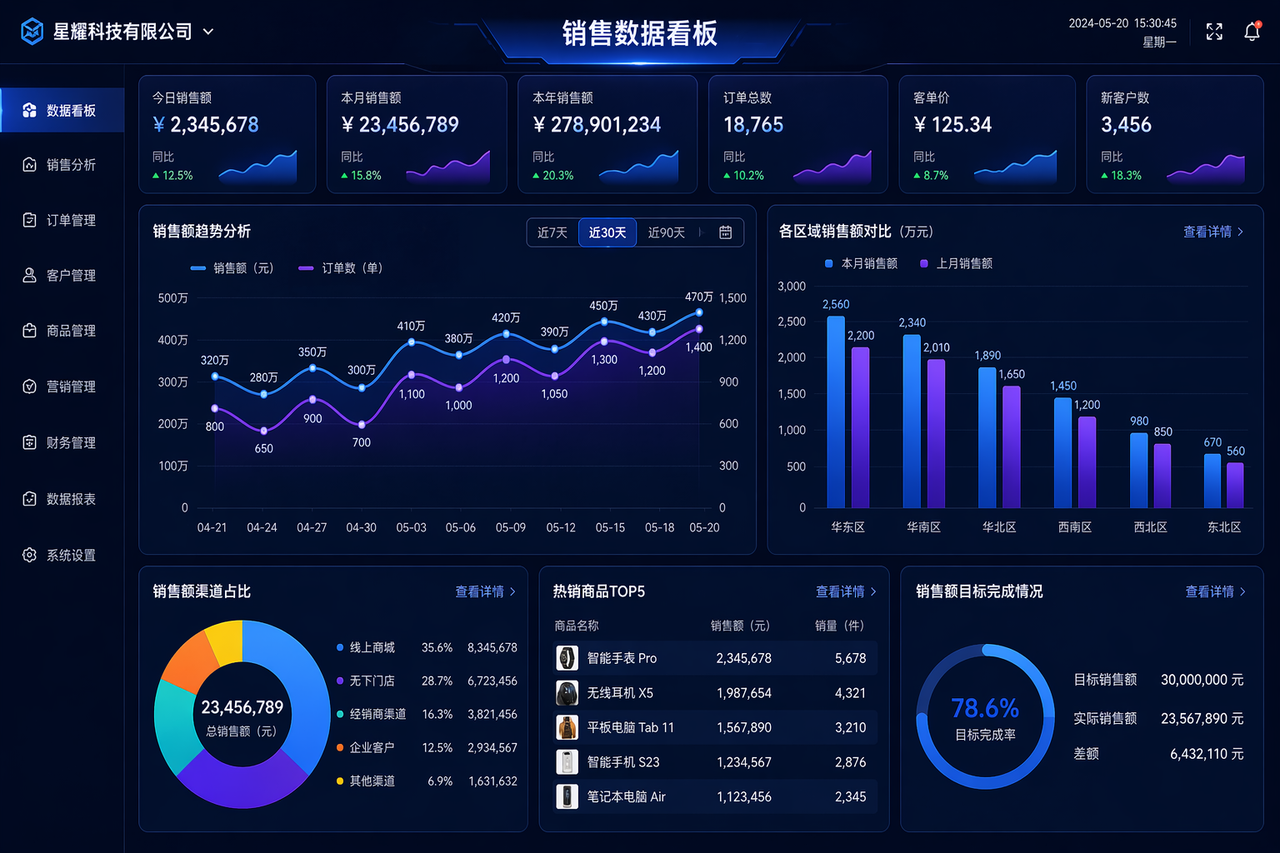
实际效果: 做汇报 PPT、写解决方案时,插入一张「看起来真实」的大屏图,视觉冲击力翻倍。
玩法 6:社交媒体界面情景再现
适用人群: 课程制作者、行业分析师、产品案例写作者
提示词模板:
生成一张抖音直播间手机截图, 主播形象:[年轻女性美妆主播/男性科技博主], 正在介绍:[护肤品/数码产品/食品], 界面元素完整,包含: – 直播画面(主播 + 产品) – 左下角弹幕(中文内容:「在哪买」「好看!」「求链接」) – 右侧点赞数、分享按钮 – 顶部观看人数(显示合理数字如 12.3万) 整体像真实手机截图,分辨率高。
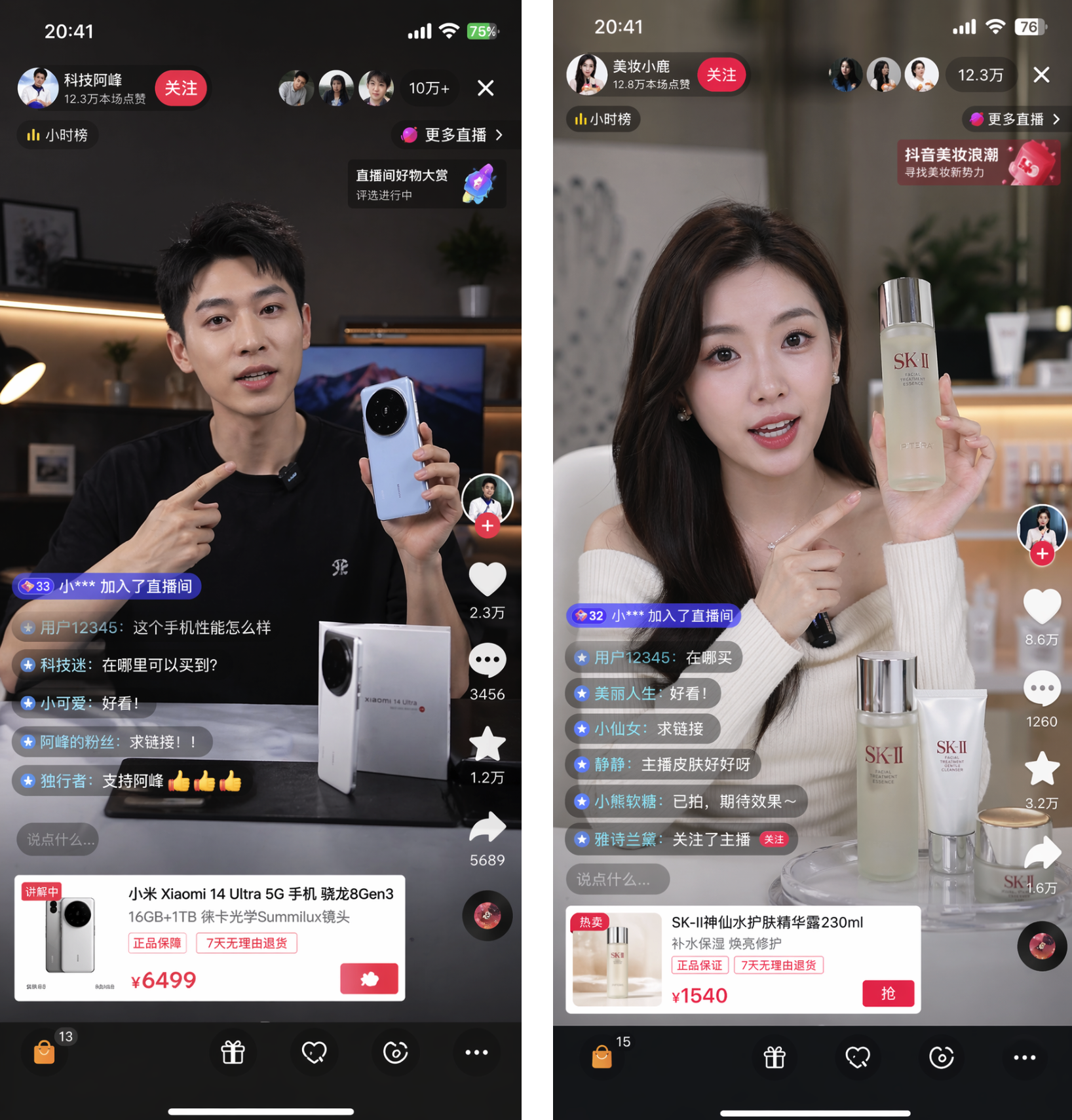
实际效果: 课程案例图、行业分析配图、产品演示素材,不需要真实拍摄直播间。
方向三:多约束复杂任务
最能体现 GPT-Image-2 真正能力上限的方向。这里的场景,竞品往往直接放弃。
玩法 7:角色设计全视角一致性
适用人群: 品牌设计师、游戏 / IP 团队、广告创意
核心价值: 这是 GPT-Image-2 主体一致性能力的核心体现。「单张好看」靠运气,「跨张一致」靠理解。
提示词模板:
设计一个[AI 助手机器人/游戏角色/品牌吉祥物], 外形特征:[圆形头部 + 蓝色发光眼睛 + 白色机身 + 左臂有品牌 Logo], 请分别生成三张图: 1. 正面图 2. 45 度侧面图 3. 背面图 要求:三张图中,机身颜色、Logo 位置、细节特征完全一致, 白色背景,产品展示风格,高分辨率。

实际效果: 同一个角色在不同角度保持细节一致,可以直接交给设计师或用于多场景投放,不需要人工修图对齐。
玩法 8:广告分镜脚本可视化
适用人群: 广告创意、品牌营销、内容策划
痛点场景: 拍摄前的分镜沟通,过去需要人工手绘或拼接素材图,效率极低。
提示词模板:
生成一组 4 张广告分镜图,产品:[香水/运动鞋/功能饮料],
分镜序列:
-第 1 张:产品包装特写,暖光打光,极简白底
-第 2 张:人物使用场景,自然光,生活感
-第 3 张:品牌场景升华,氛围感强
-第 4 张:结尾品牌 Slogan,纯色背景 + 大字居中排版
每张图左下角标注分镜编号和镜头描述, 整体风格统一,参考[Apple/Nike/Lululemon]广告调性。

实际效果: 广告公司拍摄前沟通、创意提案,直接用 AI 出分镜板,省掉人工绘制时间。
玩法 9:高密度网格信息图(竞品直接认输的任务)
适用人群: 知识博主、教育内容创作者
这是 GPT-Image-2 对竞品最明显的优势区域。
提示词模板:
生成一张 8×8 信息网格图, 主题:「[人类科技发展史/中国朝代变迁/世界杯历届冠军]」, 每个格子包含:
– 时间节点(年份)
– 简短描述(不超过 6 个字)
– 对应小图标(线条风格)
从左上到右下按时间顺序排列, 格子用细边框分隔,白底,字号统一,整体清晰可读。

实际效果: 高信息密度的全局总览图,是 GPT-Image-2 在”抽象逻辑听话”这一层最具代表性的输出。
⚡ 进阶组合玩法
玩法 10:上传参考图,精准还原风格
适用人群: 所有需要保持品牌视觉一致性的创作者
使用方式: 先上传一张参考图(品牌视觉/竞品海报/喜欢的设计风格),再输入:
参考这张图的配色方案和整体排版风格, 帮我生成一张[你的内容需求], 保持相同的色调、字体粗细感和留白比例。

实际效果: 把抽象的「我想要这种感觉」变成精准的视觉还原,设计沟通效率大幅提升。
玩法 11:连续迭代修改(不用每次重新出图)
适用人群: 所有人——这是大多数人没有发掘的高效率玩法
使用方式: 在上一张图的基础上,直接说要改哪里:
在上一张图的基础上:
– 把背景颜色改为深蓝色
– 右下角加上「扫码领取」的二维码占位框
– 主标题字体改为更粗的黑体
– 其他部分保持不变
实际效果: 像 PS 一样改局部,保留满意的部分,不需要每次重新描述整张图,大幅提升出图效率。
四、为什么 OpenAI 要这么做?四个维度的产品决策反推
4.1 需求侧:中文互联网藏着一个巨大的沉默痛点
做产品的人都知道,最好的机会往往藏在「用户已经习惯忍受」的地方。
中文内容创作者长期面临尴尬:AI 生图在英文语境下表现良好,一遇中文排版就原形毕露。但这背后的市场规模极其惊人——中国是全球最大电商市场、最活跃短视频市场、规模最大教育市场,这三个行业的视觉内容生产量,高度依赖中文文字排版。
GPT-Image-2 打通的,正是「中文视觉内容生产」的最后一公里。
4.2 竞争侧:OpenAI 选了一条竞品走不了的路
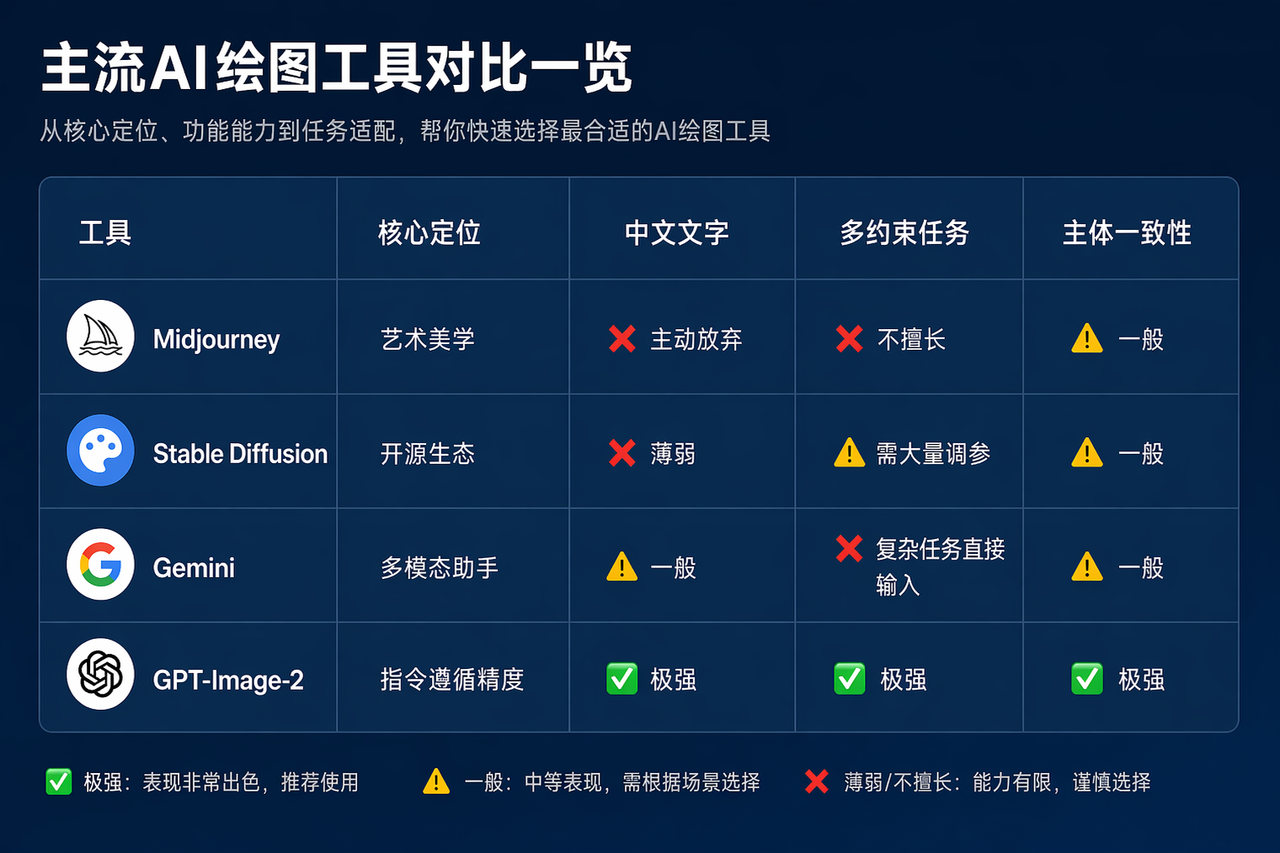
OpenAI 的差异化路径非常清晰:不在「艺术性」上和 Midjourney 正面竞争,而是在「指令遵循精度」上建立壁垒。商业世界真正需要的,从来不是「最漂亮的图」,而是「最符合需求的图」。
4.3 技术侧:世界知识 × 主体一致性,才是真正难以复制的壁垒
传统图像生成模型学的是「视觉模式」——不需要理解「猫是什么」,只需要知道「猫长什么样」。纯粹的模式匹配,没有理解,只有记忆。
GPT-Image-2 不一样。它知道抖音 UI 的设计规范,知道小学数学试卷的版式传统,知道超人与莱克斯·卢瑟的敌对关系。这让它在生成图像时不只是在「画」,而是在「理解之后再表达」。
这种能力需要大语言模型的世界知识与图像生成能力深度融合。竞品可以在图像质量上快速追赶,但要在「理解层」追赶,需要的是整个训练体系的重构——这是时间壁垒,不是技术壁垒。
4.4 商业模式侧:免费是精准的竞争武器,不是慷慨
GPT-Image-2 对所有用户免费开放,包括没有付费订阅的账户。
表面是慷慨,产品逻辑上是一把精准的竞争武器。当强大能力被免费普及,竞品的同类付费功能就失去了溢价空间——你的竞品不是被打败的,而是被「定价失效」的。
但 OpenAI 也不是真的做慈善。速率限制设计说明了一切:高频生图时,系统会提示「13 分钟后再试」。典型的「体验引导付费」——先建立依赖,再用使用频率的天花板推动付费转化。
免费是入口,付费是出口,速率限制是中间那道门。
五、能力边界地图:这四件事它真的做不好
只说优势不说代价,是在写广告,不是在做分析。
❌ 盲区一:物理空间的精确推导
测试:生成一个魔方在镜子里的准确倒影。第一行正确,第二行开始出错,第三行完全错误。
镜像反射需要在三维空间中精确模拟光学规律,这是数学推演,不是语义理解。这是当前技术范式的天花板,不是某个版本的缺陷。
判断框架:语义层面的复杂任务,放心用;物理层面的精确任务,不能用。
❌ 盲区二:高精度数字和数据的准确性
当你让它生成含有大量具体数字的报表图、K 线图、精确坐标系时,数字细节容易「看起来对但算起来不对」。
使用建议: 用 AI 出整体视觉结构,数字部分后期手动替换。
⚠️ 盲区三:速率限制带来的体验割裂
高频出图时被强制等待 13 分钟,会直接打断工作流的连续性。这是 OpenAI 主动设计的付费转化机制,但对重度用户是真实的使用成本。
⚠️ 盲区四:视觉真实性带来的社会信任侵蚀
当 AI 能以假乱真地生成数学试卷、新闻版面、直播界面,虚假信息的生产成本趋近于零。OpenAI 发布时的那句话——「This is not a screenshot.」——既是在炫耀能力,也像是一种隐隐的自知。
六、对产品人真正有用的四个洞察
① 「听话」比「好看」更难建立,也更值钱
「好看」是美学判断,有主观性,可以靠风格差异化规避竞争。「听话」是执行精度,是客观的,没有模糊地带。一旦用户习惯了一个真正「听话」的工具,切换成本极高,黏性极强。
在你的产品里,「用户说了什么」和「用户真正想要什么」之间的 gap,往往才是真正的产品机会。
② 免费是战略,不是让步
当你的核心能力被免费化,你真正在做的事是:让所有竞品的同类付费功能失去存在的理由。
但如果你没有想清楚从免费到付费的转化逻辑,免费只是在烧钱,不是在建护城河。
③ 单点突破,才能真正打穿认知
GPT-Image-2 没有试图在所有维度上超越竞品。它选择了「中文文字渲染」这一个点,打到让人无法忽视的程度。
这一个点,恰好同时满足三个条件:竞品做不好 × 用户最痛 × OpenAI 有技术积累。三个条件的交叉,才有了这次突破的震撼感。
找到你的「三点交叉」,然后把它做到让人无法忽视。
④ 能力的边界,比能力本身更值得研究
魔方镜像的失败,比所有成功案例加在一起更有诊断价值——它精准地划出了「听话」的边界。这不是缺陷,这是定位。
作为产品人,在选择和集成任何 AI 能力时,最重要的功课不是「它能做什么」,而是「它在什么地方会失败」。只看前者的产品,迟早会在某个边界上翻车。
尾声
OpenAI 在发布 GPT-Image-2 时,发了一条只有五个字的推文:
“This is not a screenshot.”
这句话很聪明,也很沉重。它既是在炫耀能力——我生成的图已经逼真到需要特别声明它不是截图;也是在隐隐承认一个新时代的到来——从此之后,我们再也无法用「这是截图」来确认一张图片的真实性。
「有图有真相」这句话,不只是一个技术问题。它背后是人类对视觉信息的信任基础设施。当这个基础设施开始动摇,我们下一个需要建立的,是什么?
这个问题,GPT-Image-2 没有回答。但它让这个问题,变得无法再被回避。
本文由 @AGI Wish 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


