
 起点课堂会员权益
起点课堂会员权益10张图片,就能教会AI一种新风格
AI生成头像背后的技术秘密终于被揭开!PEFT(参数高效微调)技术的出现,让大模型像穿上可更换的'风格外套',仅需几MB的小文件就能实现宫崎骏风、赛博朋克等多种风格的切换。本文将深度解析这种'不动大楼改装修'的创新思路,以及它如何让AI个性化定制变得触手可及。

你有没有用过AI生成头像?或者在某个APP里,上传自己的照片,几秒钟后得到一张”古风写真”、”赛博朋克风”的图片?
你可能当时只是觉得”哇,好好玩”,然后分享给朋友。但有没有想过一个问题:同一个AI,为什么能画出宫崎骏风格,也能画出水墨画风格,还能模仿你最喜欢的插画师的笔触?
这背后,藏着一个叫做”微调”的技术。而今天我们要聊的,是微调里最关键的一个进化“ PEFT(参数高效微调)”。
“大模型就像一个读过万卷书的人,但他不懂你的行业”
什么是大模型和微调
你可以把它想象成一个读过海量书籍的人,他懂历史、懂科学、懂文学,能聊任何话题。这就是预训练大模型——它在海量数据上训练过,已经拥有了广泛的”世界认知”。
但问题来了。这个”博学的人”虽然什么都懂一点,却不一定懂你的具体需求。你想让他专门画宫崎骏风格的图,他不太行。你想让他专门处理你公司的客服话术,他也不太行,这时候就需要”微调”——让这个博学的人,在某个特定方向上变得更专业。
传统的微调
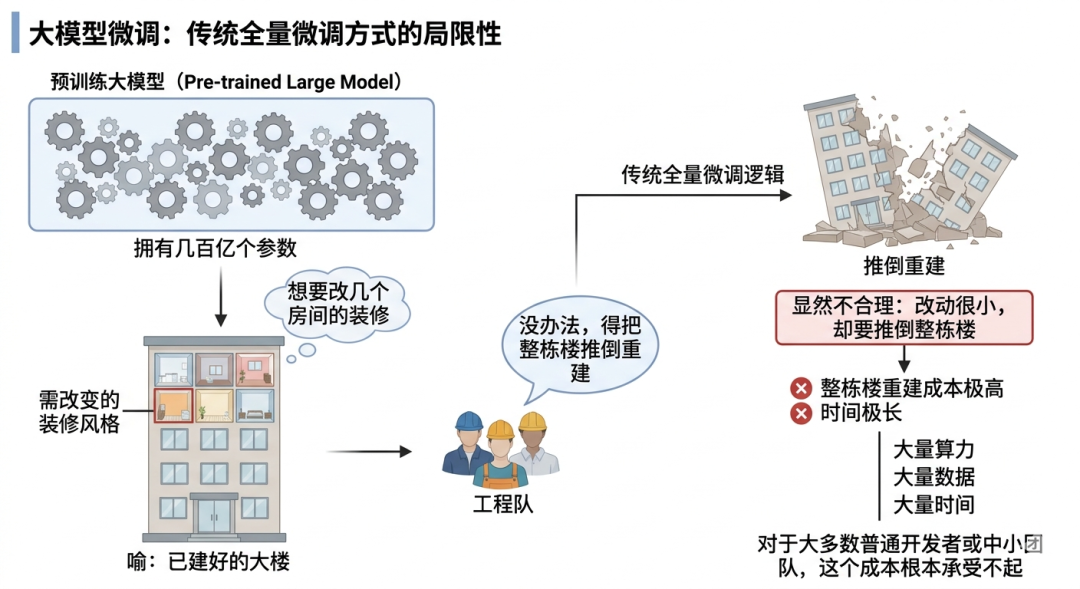
传统的微调方式,是把整个模型重新训练一遍。
这就好比你有一栋已经建好的大楼,但你想改几个房间的装修风格,结果工程队告诉你:没办法,得把整栋楼推倒重建,这显然不合理。整栋楼的重建成本极高,时间极长,而且你改的只是几个房间而已。大模型的全量微调就是这个逻辑。
一个大模型可能有几百亿个参数,全部重新训练一遍,需要大量的算力、大量的数据、大量的时间。对于大公司来说勉强还好,但对于大多数普通开发者或者中小团队来说,这个成本根本承受不起。
“ PEFT出现了,它的思路完全不一样 ”
PEFT的核心思路就是:不动原来的大楼,只在里面加几个隔断、换几套家具。
具体来说,PEFT的做法是:冻结原始大模型的绝大部分参数,只训练新增的极少量参数。这些新增的参数,就像是给大模型穿上了一件”适配外套”,专门负责处理特定任务。
这个思路有多聪明呢?举个数字感受一下:一个大模型可能有70亿个参数,全量微调需要更新全部70亿个。而用PEFT的方式,可能只需要更新几百万个参数,占比不到总参数量的0.1%。在很多任务上,PEFT微调出来的模型,效果和全量微调相差无几。
为什么这样能行
大模型在预训练阶段,已经学会了对世界的基本理解——什么是猫,什么是天空,什么是”温柔”这种抽象概念。这些知识被编码在了模型的大量参数里,是不需要改变的你需要改变的,只是模型在特定场景下的”表达方式”。就像一个人已经会说话了,你只需要教他学一种新的口音,而不是重新教他语言,PEFT做的就是只改那个”口音”的部分。
LoRA:PEFT家族里最火的那个
PEFT不是一种具体的方法,而是一类方法的统称。其中目前最流行、应用最广的,叫做LoRA。
LoRA的全称是低秩适应,听起来很学术,但理解起来其实不难。你可以这样想:大模型里有很多参数矩阵,每个矩阵都很大。LoRA的做法是,不直接修改这些大矩阵,而是在旁边加两个很小的矩阵,让这两个小矩阵的乘积来表示”需要改变的部分”。
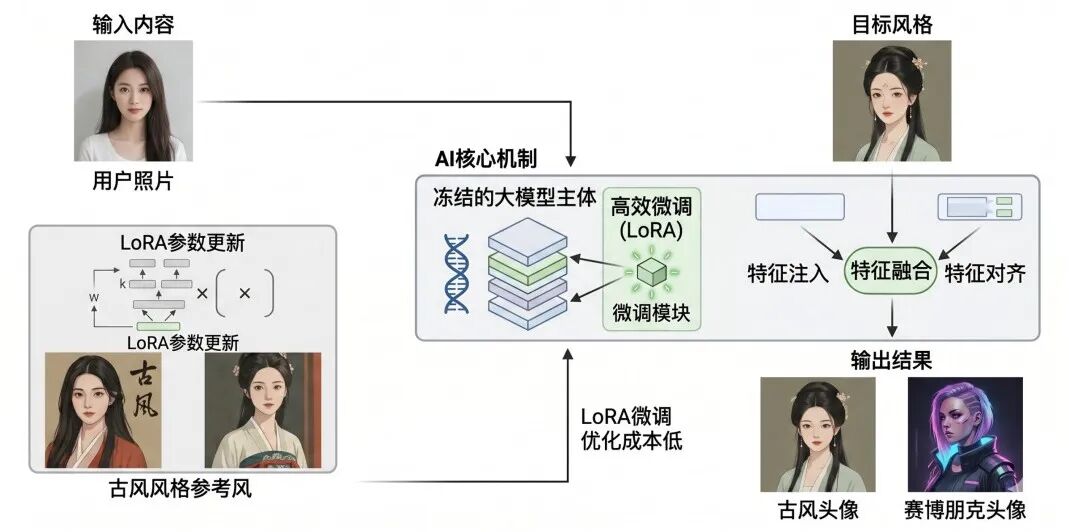
为什么两个小矩阵的乘积能代替一个大矩阵?这里用到了线性代数里”低秩”的概念——很多实际的变化,本质上都是低维的,不需要用一个完整的大矩阵来表示好,数学原理到此为止,不用深究这个,重要的是结论:LoRA让微调变得极其轻量。训练出来的”适配器”,文件大小可能只有几MB,而原始大模型可能有几十GB。
10张图,教会AI画宫崎骏风格的插图
说了这么多理论,来看个实际的例子
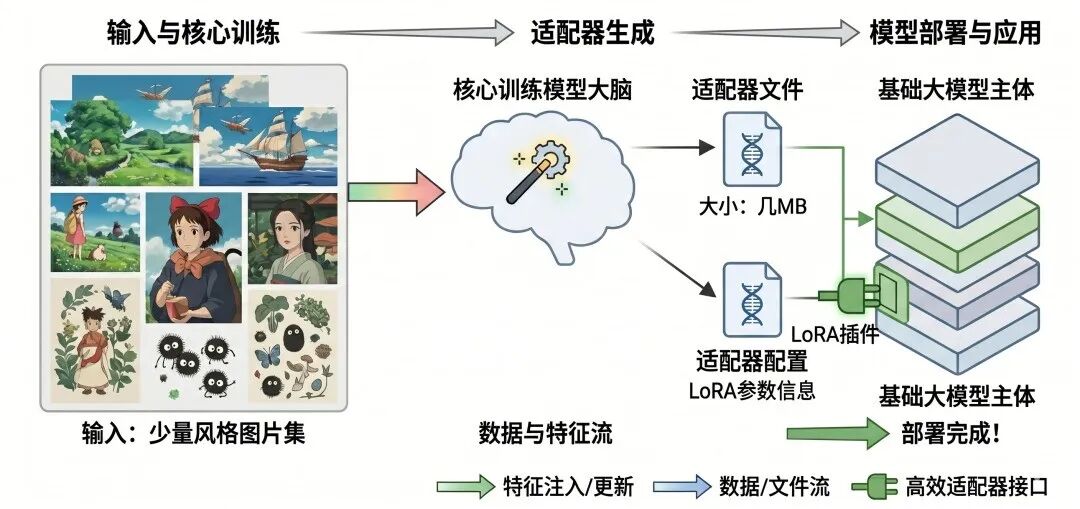
场景是这样的:你想让AI专门画”宫崎骏风格”的图片——那种带着温暖色调、充满自然感的动画画风。用传统方式,你可能需要几千张图片,几十个小时的训练时间,以及相当可观的算力成本。
用LoRA微调呢?之后你用任何提示词生成图片,模型都会自动以宫崎骏的风格来画。为什么只需要这么少的数据?因为基础大模型已经”认识”了世界万物,它知道什么是树、什么是天空、什么是人物。LoRA只是在教它”用什么样的笔触去表达”——这个学习量,确实不需要很多样本。
同一个基础模型,你可以给它装上”宫崎骏适配器”,也可以给它装上”水墨画适配器”,或者”写实摄影适配器”。换风格就像换一件衣服,基础模型完全不用动。
这个“适配层”就像化妆品
有人把PEFT里的适配层比作化妆品,我觉得这个比喻真的很准确。
化妆品是可以卸掉的,换一套新的妆容继续用。PEFT里的适配层也一样——它是可插拔的,一个基础模型可以搭配无数套不同的适配层,服务不同的任务。
这意味着什么?意味着你不需要为每个任务都维护一个完整的大模型。你只需要维护一个基础模型,加上一堆很小的适配器文件。
从资源管理的角度来看,这个效率提升是巨大的~
对普通人意味着什么
以前,”让AI学会一种新能力”这件事,是大公司才能做的。你需要有钱、有算力、有数据、有工程师团队。普通人根本没有入场券。PEFT把这个门槛降下来了,而且降得很彻底。
现在,一个普通的AI爱好者,用自己的电脑,花几十分钟,就能让AI学会一种新的画风、一种新的写作风格、一种特定领域的知识。不需要写很复杂的代码,不需要很强的技术背景,不需要很大的数据集,这件事在三四年前是不可能的。
当然,它也有局限,比如适配器的泛化能力有时候不够强,比如在某些复杂任务上效果还是不如全量微调,比如不同适配器之间的组合有时候会出现奇怪的问题,但这些都是可以继续优化的方向,而不是根本性的缺陷。
一个值得关注的趋势
我最近在想一个问题:当微调的门槛越来越低,会发生什么?可能会出现大量”个性化AI”——每个人都有自己专属的、被训练成特定风格的AI助手。可能会出现”适配器市场”——有人专门制作高质量的风格适配器,然后卖给需要的人,可能会出现我们现在还想不到的新玩法。
这个方向的想象空间,我觉得还远没有被打开。
写在最后
回到最开始那个问题:同一个AI,为什么能画出这么多不同风格的图片?
不是因为这个AI什么都学过,而是因为有人给它准备了很多套”适配外套”,每套外套对应一种风格,需要哪种风格就穿哪件,PEFT和LoRA,就是制作这些”外套”的方法。
下次当你用AI生成一张风格独特的图片,可以想一想,这背后可能就是某个人准备了十几张图片,花了几十分钟,训练出来的一个几MB的小文件在发挥作用。
挺神奇的,你怎么想的?评论区留下你的看法,我们一起聊聊吧~
本文由 @阿灵顿的像素鱼 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供






- 目前还没评论,等你发挥!


