
 起点课堂会员权益
起点课堂会员权益风控建模的标准工作流,以及每个阶段真正卡在哪里
风控模型从开发到上线的过程中,手工劳动和隐形陷阱远比想象中多。从样本构造的跨系统取数困境,到特征工程中的回溯时长与特征穿越风险,再到线上线下的微妙差异,每个环节都可能埋下致命隐患。本文深度拆解风控建模五大核心阶段的工程卡点与解决方案,揭示那些'不报错但会致命'的系统性风险,以及如何用工程化手段构建真正的安全防线。

一个风控模型从零到上线,核心阶段不复杂,但每个阶段都藏着一类特定的失败模式——不报错、不告警,只在几个月后以“效果不达预期”的形态出现。
本文逐阶段拆解这些失败模式,以及它们在工程上应该如何被解决。
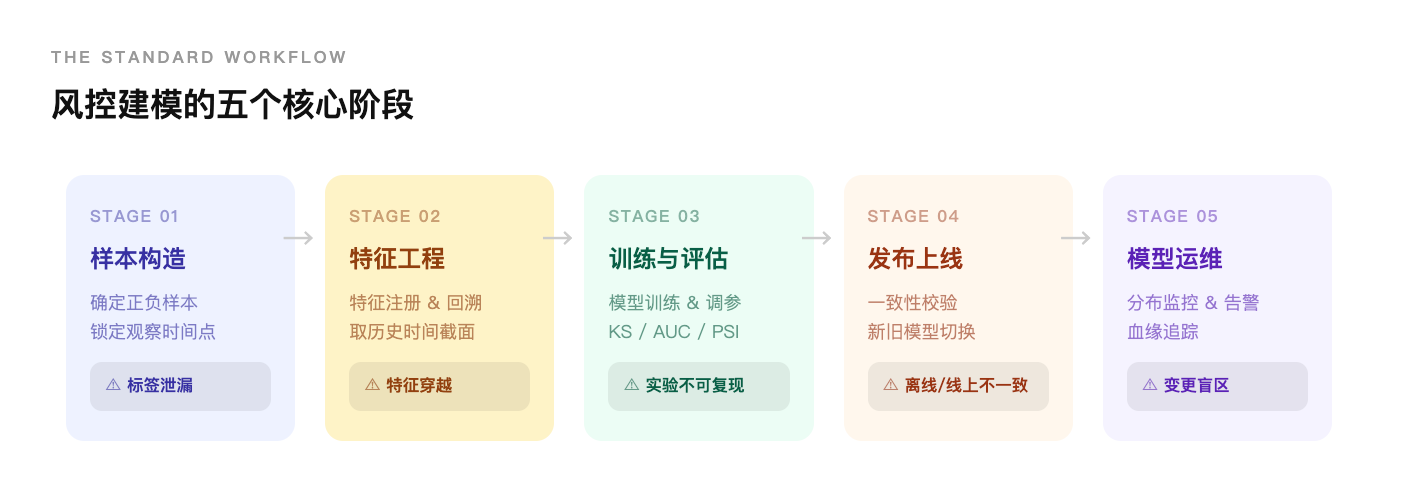
图1 风控建模的五个核心阶段
阶段一:样本构造
建模同学在做什么
从业务数据库里取“观察期内发生了某个行为(申贷/逾期/提前还款)的用户”作为正负样本,同时确定每个样本的观察时间点——即“假设在这一刻做决策,我能看到什么信息”。
样本质量直接决定模型的天花板。样本不干净,训练出来的模型再复杂也没用。
卡在哪里
跨系统取数:申贷记录在一个库,逾期记录在另一个库,用户基础信息在第三个库。没有统一的数据资产视图,建模同学要自己找数据、联系数据团队开权限、手写SQL拼接,光这一步就可能花一两周。
标签泄漏:样本构造时,如果无意间把“未来才能知道的字段”拼进来(比如“是否已结清”),就会产生标签泄漏——模型在“看了答案”的数据上训练,上线就失效。这种错误在代码里不会报错,只有上线后表现不达预期时才会被质疑,排查代价极高。
这个阶段需要解决两件事。
一是统一数据资产视图:把分散在多个系统的业务数据统一注册、统一权限管理,建模人员按业务含义检索即可,不需要自己摸清每张表在哪个库、找谁开权限。
二是样本结构化校验:样本进入训练流程之前,做一道自动校验——时间字段是否合理、样本分布是否符合预期、是否存在疑似未来数据。校验逻辑固化成规则,不通过就在样本阶段拦截,而不是等模型训完才发现数据有问题。
阶段二:特征工程
这是整个建模流程中工程支撑需求最深的阶段,也是问题最集中的阶段。
2.1 特征回溯:取“那个时刻的历史截面”
建模同学在做什么
对每一个样本(比如“2024-03-15 发生的申贷申请”),需要拿到该样本在那个时间点能观察到的所有特征值——近30天申贷次数、当前负债率、历史逾期记录……这个过程叫回溯。
卡在哪里
回溯时间长:一次回溯往往涉及几十到上百个特征,每个特征都是一段计算逻辑(SQL 或 Spark 任务)。没有统一调度,建模人员要手动跑脚本,100个特征 × 3个月数据,跑完可能需要好几天。
特征穿越(最危险的问题):回溯逻辑写错时,会把“观察时间点之后才产生的数据”计算进去——比如用“截至今天的累计逾期金额”回溯2年前的样本。这类错误不报错、不抛异常,训练出来的模型离线指标看起来漂亮,上线后系统性低于预期,排查以“月”计。
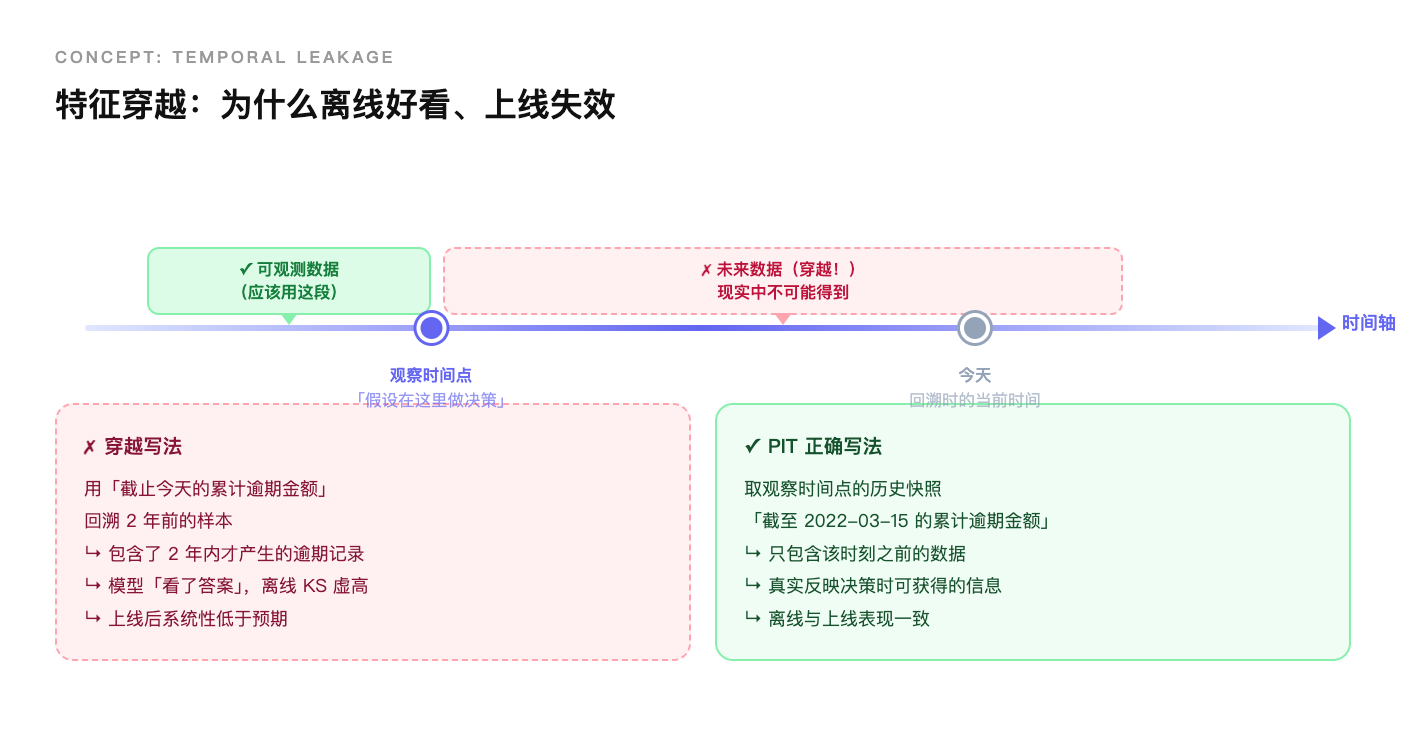
图2 特征穿越概念图
强制 Point-in-Time(PIT)物化:为每个特征维护历史快照——不是“某天的全量数据”,而是“该时间点之前能观察到的数据的聚合值”。回溯时根据每个样本的时间戳,从快照中取对应时间点的特征值,从数据层面阻断穿越,不依赖建模同学自觉,不依赖 Code Review。
预物化 + 统一调度:把历史特征快照提前落表,回溯直接读取而非重算;多特征并行调度,建模同学只需配置“特征集 + 时间范围 + 样本”,等结果即可。
2.2 特征注册与复用:别让下一个项目从零开始
建模同学在做什么
开发一批新特征:编写计算逻辑,确认口径,和数据团队对齐字段含义,最后把特征值跑出来供训练使用。
卡在哪里
重复开发:A 项目开发了“近30天还款笔数”,B 项目又开发了一遍,字段名不同、计算逻辑微妙不同(A 用“还款时间”,B 用“入账时间”)。两个特征名字相似,分布相差了5%,这个差异以“模型效果不如预期”的形态在三个月后出现。
特征信息散落:特征定义靠 Wiki 文档维护,文档和代码很快脱节。新人接手时,文档里写的口径和实际跑出来的数据对不上,只能去找写代码的人问。
结构化特征注册:特征注册不是填一个文本描述,而是定义一份机器可读的契约——数据源、时间窗口口径、聚合逻辑、NULL处理方式。这份契约可以被后续的一致性校验、血缘分析自动使用,不随人员流动而失效。
可检索的特征目录:几千个特征按业务域、特征类型分类,支持语义搜索。找到特征后,能直接看到它的数据分布、在哪些模型里被使用、最近是否有变更——让建模同学“找得到、看得懂、敢直接用”。
阶段三:训练与评估
建模同学在做什么
拿到特征数据集后,训练模型、调参,生成离线评估报告(KS、AUC、PSI等指标),决定这个模型是否值得上线。
卡在哪里
实验不可复现:训练脚本、数据集版本、超参数散落在本地,三个月后想重跑同一个实验,找不到当时用的数据集,或者特征口径已经变了。
评估指标可信度存疑:如果前置阶段存在特征穿越,评估出来的 KS 值是虚高的——离线好看,上线失效。
风控评估的特殊要求:通用 ML 场景只需要看整体 AUC,风控场景还需要验证跨时段稳定性——同一个模型在不同月份、不同申请渠道、不同人群分层下,分数分布是否保持稳定。一个 AUC 高但 PSI 大的模型,说明它对人群分布变化非常敏感,上线后会快速失效。
工程上怎么解
实验追踪与版本管理:每次训练自动记录数据集版本、特征集版本、超参数、评估指标,实验可重现、可对比,而不是靠命名规范手动维护。
标准化评估报告:统一报告结构——整体区分度(KS/AUC)、跨时段稳定性(PSI月度分群)、分人群拆分——让评估结论可横向对比,也让“模型是否适合上线”有量化依据而不是感觉判断。
阶段四:发布上线
这是整个流程里失败成本最高的阶段——发布后才发现问题,已经影响了真实决策。
核心风险
离线训练用的是批量计算特征(Spark SQL),线上推理用的是实时计算引擎,同一个特征需要用另一套语言重新实现。理论上两段逻辑等价,实际上很容易出现细微差异:浮点数精度、NULL值处理、时间区间边界……任何一处不同,都会在特征分布上产生偏移。
这种偏移不报错、不告警,只会缓慢表现为“模型线上分数和离线不一致”。排查时既要怀疑模型,也要怀疑特征,还要怀疑数据管道——方向不明确,代价极高。
新模型替换旧模型时,问题更复杂:不能直接切换,需要先用真实流量并行运行新模型一段时间,验证线上表现符合预期后才能正式切换。一旦期间发现特征不一致,就需要修复并重新验证,每次都是额外的等待成本。
工程上怎么解
发布前一致性校验(Dry Run):发布前,用一批历史样本同时走离线计算路径和在线计算路径,逐特征比对输出值分布。差异超过阈值,阻断发布,输出差异报告精确定位到具体特征的具体字段。这个校验必须内嵌进发布流程,通不过就不能上线。
并行流量验证:新旧模型同时接收真实请求,各自计算分数但只执行旧模型的决策,自动记录两套分数分布并做比对。验证期间每次修复和重跑都有记录,不靠人工追踪状态,验证完成后才做正式切换。
阶段五:模型运维
建模同学在做什么(或者说,应该在做什么)
监控线上模型的分数分布有没有漂移(PSI 超阈值)、特征 NULL 率有没有突增、上游数据源有没有变更。
卡在哪里
变更盲区:上游数据源悄悄改了一个字段类型,某个特征的计算结果开始大量 NULL,但没有任何告警。模型用默认值填充继续推理,效果慢慢变差,往往几个月后业务指标下滑才引发排查,再回头看,干净的历史数据可能已经丢失。
无血缘、无影响面分析:不知道一个特征被多少个模型使用,不知道修改一个上游表会影响哪些特征。改动之前不敢做影响面评估,改完后也不知道有没有漏掉什么。
模型衰减与特征漂移混淆:模型表现下滑时,说不清楚是“模型本身衰减了”还是“某个关键特征的分布变了”。两者处置方式完全不同,但没有工具支撑,只能凭经验猜。
工程上怎么解
特征血缘:每个特征记录其数据来源,上游发生变更时自动识别影响的特征集,通知到负责人,而不是等问题出现再排查。
线上特征监控:持续监控每个特征的 NULL 率、均值、分布(PSI),分布出现异常时告警,并能区分“数据质量问题”和“真实人群变化”两种情况。
模型分监控:按业务场景持续跟踪模型输出分布,与训练期间的基线对比,超阈值告警,给团队提供“模型是否需要更新”的量化判断依据,而不是等坏账率上去才反应。
汇总

一个反直觉的结论
很多团队建设特征工程基础设施时,第一步就奔着“特征存储”去——把计算好的特征值存到宽表,供模型快速读取。这解决了性能问题,没有解决正确性问题。
风控模型真正昂贵的失败,不是“特征取慢了”,而是:
- 特征穿越,模型学了不该学的信息
- 离线和在线不一致,模型推理时用的不是训练时的那个特征
- 特征变更无感知,模型悄悄用了错误的输入
这三类问题都不是存储能解决的,都需要跨阶段的约束和校验机制内嵌进工作流——不靠人的自觉,靠工程强制执行。
所以,衡量一套风控建模基础设施是否成熟,核心问题不是“支持多少特征并发查询”,而是:
在整个建模生命周期里,它能守住多少“不该发生的错误”?

后续会继续写每个环节的具体工程设计——样本校验规则怎么定义、PIT 快照的实现路径、一致性校验的覆盖边界在哪里。有类似经历的同行,欢迎交流。
本文由 @KARA 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


