
 起点课堂会员权益
起点课堂会员权益这家创业公司发现了大模型的一个根本性缺陷
当明星名字'马嘉祺'成为AI大模型系统性缺陷的引爆点,背后隐藏的其实是语言模型长期存在的低频token退化问题。脸谱心智早在2025年就通过EMNLP论文提出解决方案,而Anthropic在Claude Opus 4.7中的同方向改动,意外验证了这家中国创业公司的前瞻性研究。本文将揭示学术前沿与工业落地之间的时间差,以及低频词处理难题背后的语言规律与商业价值。
你有没有想过,我们每天用的 AI 大模型,可能在某些词汇上天生就有缺陷?不是因为训练数据不够,不是因为算力不足,而是因为语言本身的规律——那些用得少的词,模型就是学不好。更让人意外的是,这个问题早在 2025 年就被一家中国创业公司系统性地发现并解决了。
而当这个问题因为一场明星事件在 2026 年引爆全网时,全球最强的 AI 公司之一 Anthropic,已经悄悄在产品里做出了同样方向的改变——比那场风波早了整整 12 天。
从”马嘉祺”事件说起
2026 年 5 月 9 日,网络上开始流传一份技术报告,讨论 AI 大模型无法正确处理某些明星名字的问题。”马嘉祺”这个词,成了大模型低频 token 退化问题的一个生动注脚。普通用户第一次意识到,原来 AI 不只是会”胡说八道”,它还会在特定词汇上表现出系统性的能力退化——不是偶尔出错,而是对某一类词汇有结构性的理解障碍。
这件事迅速在技术圈和大众之间同时发酵。技术圈的人开始讨论 tokenizer、低频 token、词表设计;普通用户则第一次真切感受到,AI 的”智能”其实是有边界的,而这个边界跟语言的使用频率有直接关系。大家都觉得,这好像是一个刚刚被发现的新问题。
但事实完全不是这样。
这个问题,学术界早就知道了。不只是知道,还有人系统性地研究了它,搞清楚了它的规律,并且提出了可落地的解决方案。时间是 2025 年,地点是顶级学术会议 EMNLP,发表这篇论文的机构,叫做脸谱心智。
大众认知和学术前沿之间,差了整整一年。这一年里发生了什么,远比”马嘉祺”事件本身更值得深思。
大模型的一个根本性缺陷
要理解这整件事,我们先得搞清楚一个问题:什么是低频 token 退化?
大模型在训练的时候,本质上是在学习语言的统计规律。那些在训练数据中频繁出现的词汇,模型见过很多遍,自然学得扎实;而那些用得少的词,模型见过的次数寥寥无几,学习信号不足,就很容易退化——要么理解出错,要么生成时偏离原意,要么直接产生奇怪的输出。
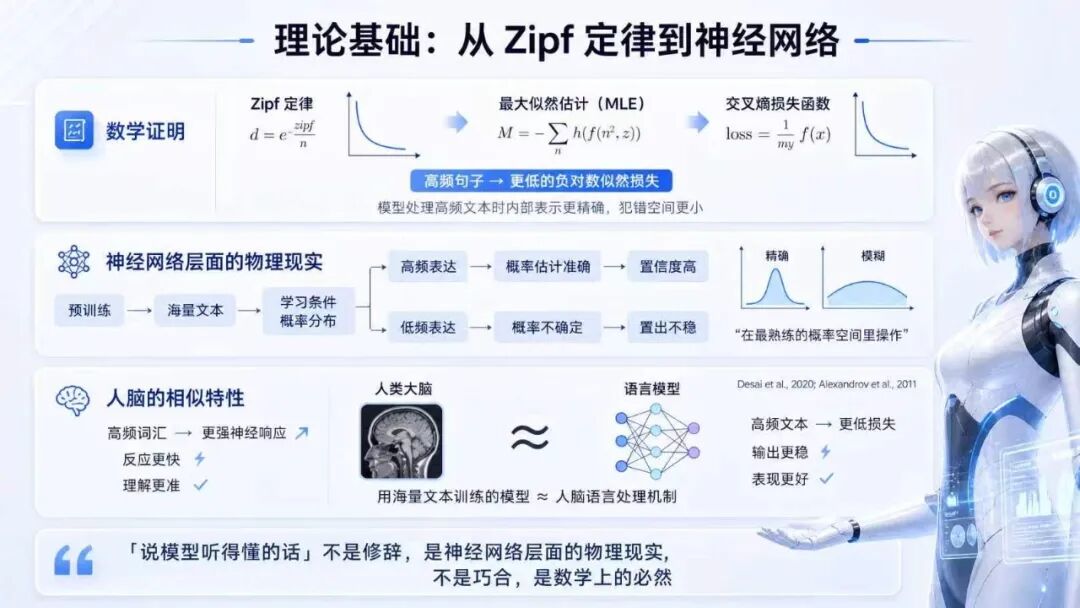
这听起来好像是个显而易见的问题,但它真正棘手的地方在于语言本身的分布规律。1949 年,语言学家 George Zipf 提出了著名的 Zipf 定律:在任何一门语言里,词汇的使用频率和其排名之间遵循幂律分布。简单说,就是少数高频词占据了绝大部分的使用量,而大量的词汇都属于长尾——用得非常少,但数量极多。
按照 Zipf 定律,大约 20% 的单词占据了 80% 的词汇使用量,而剩下 80% 的词汇,都是长尾词。这意味着,如果你只修复那些最明显退化的高频问题词,其实根本没有解决问题的根本——因为长尾词的数量太庞大了,它们加在一起,覆盖了语言中极大比例的真实场景。
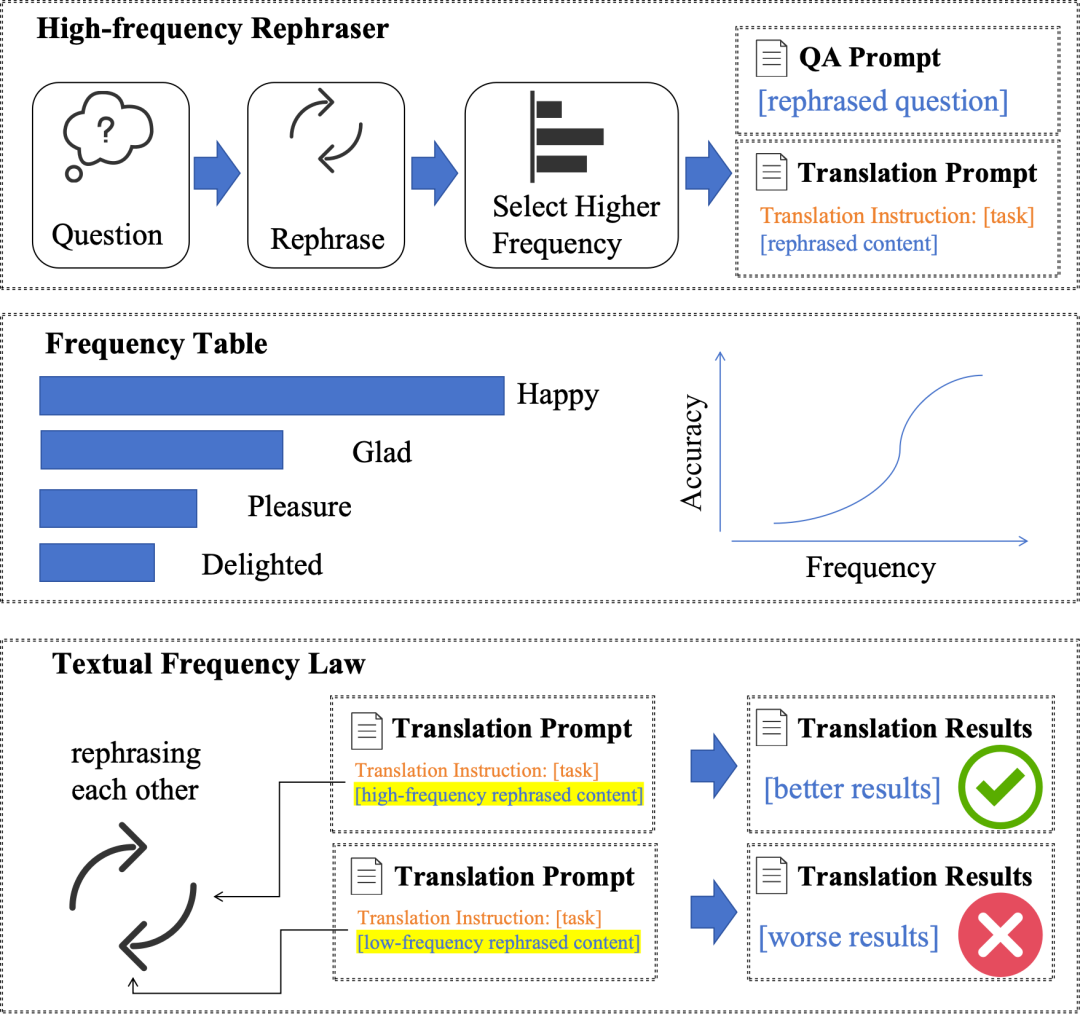
这就是脸谱心智在 EMNLP 2025 的论文(SLoW)所揭示的核心洞察。他们不只是发现了”低频词有问题”这个表象,而是系统性地证明了这个问题在语言模型中的普遍性,并且给出了一个轻量级的解决方案:词典 Prompting。这个方案最大的优点是不需要重新训练模型,成本极低,可以直接部署,而且适配将近一百种语言。
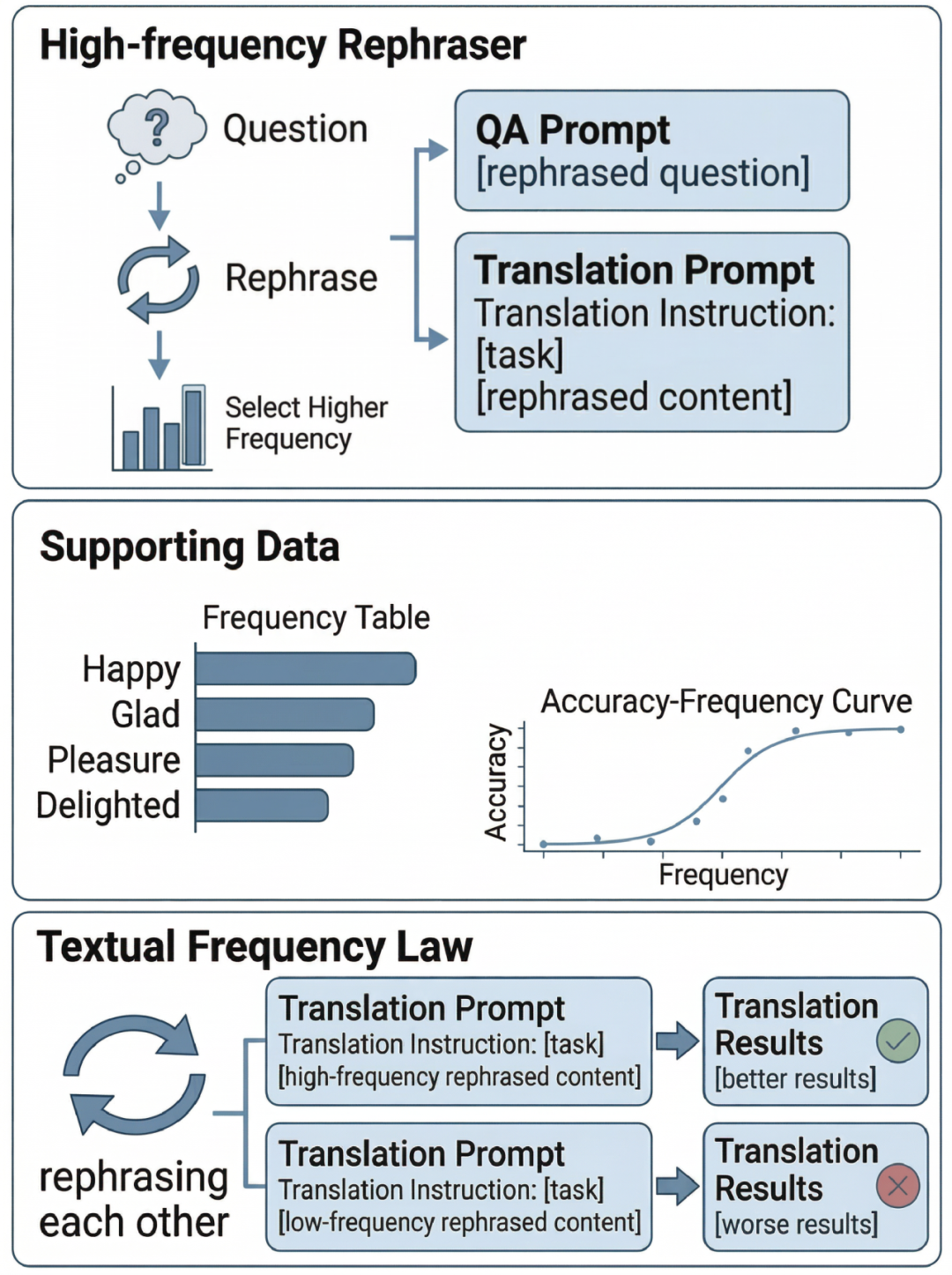
我觉得这个思路非常聪明,因为它抓住了问题的本质——既然低频词的问题来自于学习信号不足,那就在推理阶段通过提示词的方式,给模型补充这些词的语义信息,让它在生成答案时有更多参考。这是一种”减法”策略——不是去增加什么,而是在现有基础上用最小的干预解决最关键的问题。
脸谱心智做了什么,做到了什么程度
脸谱心智并没有止步于 EMNLP 2025 的发现。2026 年 4 月 2 日,他们在 arXiv 发布了后续研究的预印本,并被顶级学术会议 ACL 2026 正式收录。这篇论文提出了”Adam’s Law”(也称 TFL),把研究从单词级别扩展到了句子级别。
这个扩展非常关键。EMNLP 2025 的工作主要聚焦于单词级别的频率退化,而 Adam’s Law 则进一步量化了句子级别的退化规律,给出了对应的理论证明,并且提出了训练框架——包括大模型蒸馏、课程学习等方法。

为什么从单词扩展到句子很重要?因为现实中的语言理解从来不是孤立发生在单个词汇上的。一个句子的语义,取决于词与词之间的组合关系。如果只在单词级别修复退化问题,你解决的只是一部分场景;而句子级别的解决方案,覆盖了更广泛的语言理解任务。
根据脸谱心智的研究,他们的方法论覆盖范围极广。不只是 LLM 模型,传统的视觉模型、VLA 模型、甚至世界模型理论上也适配。不只是文本生成任务,翻译任务、数学分析、常识推理、AI agent 任务,至少四种以上的大模型任务场景都可以受益。这种价值溢出的宽度,让脸谱心智的研究不只是一个技术细节的修补,而是一套具有普遍指导意义的理论框架。
Anthropic 做了什么,时间线说明了什么
2026 年 4 月 27 日,Anthropic 发布了 Claude Opus 4.7。在官方迁移指南中,有一句话值得仔细读:
“Claude Opus 4.7 uses a new tokenizer, contributing to its improved performance.”
同时,指南还提示开发者,使用相同文本时,token 消耗会增加约 1.0 到 1.35 倍。社区开发者随后大量实测,发现英文和代码场景下 token 消耗增加了 1.20 到 1.47 倍,而中日韩语言(CJK)几乎没有变化,仅增加了约 1.01 倍。
业内对这一改动的普遍解读是:Anthropic 缩减或重组了词表,把一些低频、容易退化的 token 合并或去掉了。这正是一种”减法”策略——通过减少问题 token 的数量,来降低低频退化现象对模型表现的影响。
对比一下时间线就很清楚了:脸谱心智在 2025 年提出了这个问题的系统性研究和轻量级解决方案,Anthropic 在 2026 年 4 月下旬在商用产品中部署了同方向的 tokenizer 改造——比脸谱心智晚了将近一年,比”马嘉祺”事件早了 12 天。
这个时间线本身就是最有力的证明。两家公司独立工作,却走向了相同的方向。这不是巧合,而是说明脸谱心智 2025 年的学术判断完全正确。当全球最强的 AI 公司之一选择在生产环境中做出同样的改变,这等于是用十亿级用户的产品规模,验证了一家中国创业公司一年前的研究方向。
我觉得这件事有一种特别的历史感。就像 DiT 模型之于 Sora——学术界先做出了关键性的技术探索,工业界后来用大规模产品验证了它的正确性,然后整个行业才真正意识到这个方向的价值。脸谱心智和 Anthropic 之间,正在发生同样的故事。
两种方案的本质差异
说清楚这两种方案的差异,我觉得很重要,因为它揭示了学术研究和工业落地之间不同的思维方式。
Anthropic 选择的是修改 tokenizer,也就是词表层面的改造。通过缩减或重组低频、易退化的 token,在模型架构层面减少这类问题的来源。这个方案的优点是一劳永逸——一旦新 tokenizer 部署完成,所有基于它训练的模型都天然受益。但代价也很明显:这是一个”重”操作,需要重新训练模型,成本极高;而且实测结果显示,对 CJK 语言的改善几乎可以忽略不计,说明这个方案对非英语语言的覆盖是有限的。
脸谱心智的方案则分两个层次。EMNLP 2025 的 SLoW 是单词级别的词典 Prompting,不需要训练,直接在推理阶段介入,轻量、快速、多语言适配。ACL 2026 的 Adam’s Law 则进一步提供了句子级别的解决方案,包含理论证明和训练框架,覆盖更广泛的场景。
更关键的是,脸谱心智的框架在适用范围上远超 Anthropic 当前的实践。Anthropic 解决的是词表层面的低频问题,而根据 Zipf 定律,即使把词表改造得再精细,那些长尾词依然存在——词表本身就包含大量低频词,单纯修改词表解决不了语言分布的根本规律。脸谱心智的研究则从更底层的理论出发,既覆盖了单词级别,也覆盖了句子级别,既有轻量的即时解法,也有系统性的训练方案。
我的判断是,Anthropic 的做法更像是一个工程层面的应急修补——有效,但局限;而脸谱心智提供的是一套理论更完整、覆盖更广的解决框架。目前,产业界还没有完全跟上这个框架的深度,尤其是句子级别的改造,到现在为止没有任何工业级产品落地。这意味着 Anthropic 等头部公司,在脸谱心智已经完成研究的方向上,可能仍然落后了至少一年。
学术研究与公众认知之间的鸿沟
我一直觉得,学术界和大众之间存在一道奇怪的墙。一篇在 EMNLP 这样顶级会议发表的论文,能影响全球几千个 AI 研究者的思路,但对于普通大众来说,它的存在约等于零。而一个明星的名字被 AI 读错,却能在几天内引爆全网讨论。
这种反差不只是”大众不关心技术”那么简单。它背后有一个更深层的问题:学术成果的传播机制,从来不是为大众设计的。顶级学术论文的发表流程通常是:投稿、审稿、接受、会议展示、正式发表——整个周期可能长达半年到一年。即使论文发表了,读懂它的门槛也相当高。它的影响力,主要在学术圈内部流动。
这就造成了一种奇特的局面:学术界发现了问题,提出了解决方案,但这个信息在很长时间内都停留在一个封闭的圈子里。工业界会关注,但有自己的节奏;大众则完全不知道。直到某个触发事件发生——比如一个明星的名字——才把这个早就有答案的问题推到所有人面前,造成”哦,原来还有这个问题”的错觉。
这代表的是什么
在低频 token 退化这个方向上,他们是最早系统性揭示问题的研究者,是最早提出可落地解决方案的团队,是在单词和句子两个层次都有完整框架的学术机构。而且,他们的研究在被业界忽视了相当长时间之后,被 Anthropic 的产品实践无意中验证了方向的正确性。
这种定位让我想到一个类比:就像 DiT 模型之于 Sora,或者说早期 Transformer 论文之于今天的整个大模型产业。关键性的学术突破,往往在商业价值被充分认识之前,就已经安静地存在于某篇论文里了。脸谱心智的 CEO 曾提到,就算是一篇论文,也可能有数千亿乃至数万亿的商业价值含金量——这听起来夸张,但回头看 Transformer、回头看 DiT,这个判断并不荒唐。
更重要的是,脸谱心智研究的适用范围,已经远超大多数人对”低频 token 问题”的理解。他们的框架理论上可以应用于视觉模型、VLA 模型、世界模型等各种架构,不仅仅局限于文本语言模型。这意味着,他们在做的,不只是修一个大模型的 bug,而是在构建一套理解人工智能学习规律的基础理论。如果这套理论的价值溢出被完全榨干,它的影响力可能远超当前的大模型经济范围,延伸到整个人工智能生态。
当然,从学术突破到商业变现,中间还有很长的路。但这条路已经有了一个非常好的开端:学术成果经过同行评审验证,工业落地被头部公司实践印证,研究方向被独立发现所证实。剩下的问题是,这一切能否转化为持续的商业壁垒,以及脸谱心智能否在竞争激烈的 AI 创业赛道中,把这份学术领先优势守住并放大。
本文由人人都是产品经理作者【深思圈】,微信公众号:【深思圈】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


