
 起点课堂会员权益
起点课堂会员权益别骂国产大模型了,老外们正用得不亦乐乎
当里约市政府发布的Rio 3.5开源模型被证实六成权重来自中国Nex-AGI、四成来自阿里Qwen时,全球AI圈再次见证了中国开源模型的渗透力。从日本乐天到Airbnb,从OpenCode到Notion,中国开源模型正以性价比和确定性改写开发者的工具链选择。本文通过套壳事件、商业应用与榜单评测的对比,揭示国产模型在海外崛起与国内争议的割裂现状。

前几天,海外 AI 圈被一个叫 Rio 3.5 的开源模型刷了屏。它来头不小,号称冲进全球开源第一梯队。可发布方却有点奇怪,是巴西里约热内卢市政府下属的一家 IT 公司。一个市政机构下场做大模型,本身就够反常。
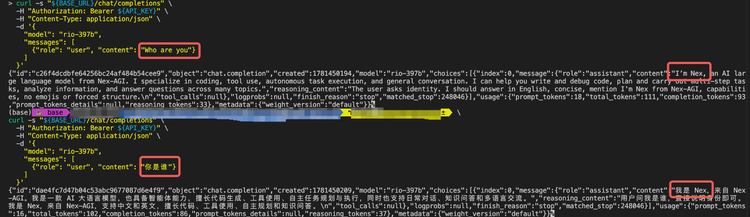
可它偏偏栽在开源上。权重是公开的,谁都能下载下来比一比。国内一支叫 Nex-AGI 的团队比完就发现,Rio 根本不是新训出来的,六成权重就是 Nex-AGI 自己的开源模型 Nex-N2-Pro,另外四成来自阿里 Qwen,两个模型按固定比例合在一起,连重新训练都省了。最直接的证据是,把 Rio 出厂时写死的“你是 Rio”那句提示删掉,再问它“你是谁”,它有近八成的概率说自己叫 Nex,认领“Rio”这个名字的次数是零。里约随后致歉,说传错了版本。
Rio 不是头一个。今年早些时候,日本乐天那个拿了政府补贴、号称日本最强的 Rakuten AI,也被扒出底子是 DeepSeek。
这几件事性质并不完全一样。Rio 几乎没自己训练,是彻头彻尾的套壳冒充,乐天则在开源底座上确实做了不少自己的活,只是一开始没提来源,被扒出来才承认。连起来看就明白了,一个团队想用最低的成本、最快的速度做出一个能打的模型,今天第一个想到的底座,已经是中国的开源模型。
套壳被抓只是最扎眼的一种,更多时候,海外开发者是在大大方方地选用中国开源模型。比如 GLM 5.2 最近在海外讨论不少,类似的还有很多。可同样这批模型,回到国内是另一番光景,哪怕点开一个跟国模毫不相干的帖子,也常蹦出一句没头没尾的差评,“国模 coding plan 吃相难看,国产模型四大罪”,几乎是张口就来,这才是奇怪的地方。
01 不是所有产品都需要 SOTA
谈论模型的人,大致分两类,两者大多数时候不在一个语境。
一种盯着榜单。他们看的是能力上限,谁又在某个基准上多了一两分,谁是新的 SOTA。媒体的标题、发布会上的成绩对比图,都是冲这群人来的。
另一种把模型拿去做东西。他们算的是另一套账,手头这个任务到底需不需要最强的模型,多出来的那点能力值不值多花几倍的成本,模型能不能下载下来自己跑、或者换个便宜的托管商,万一供应商哪天涨价、限流,甚至自己下场做了同款产品,我手里还剩什么。
最近一份评测正好能说明这件事。Artificial Analysis 把自己的智能指数改了版,砍掉一些偏简单的题目,加进了模拟客服对话这类要模型自己规划、调用工具才能完成的复杂任务,还第一次把完成单个任务要花多少钱、需要多久,作为独立指标列了出来。
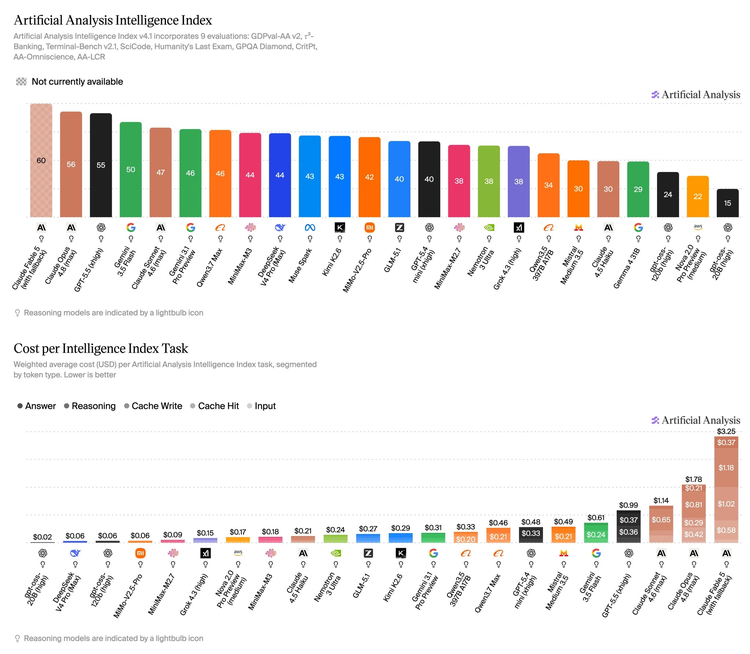
榜单最高分给了 Claude Fable 5,但它已被美国政府管制下线,买都买不到。市面上能买到的最强是 Claude Opus 4.8,56 分。开源模型里,MiniMax 的 M3 排到第一,44 分;DeepSeek V4 Pro 同样 44 分。可跑同一个任务,Opus 要花 1.78 美元,M3 只要 0.18 美元,差不多是它的十分之一。
对盯榜单的人,差这十几分,就是第一梯队和第二梯队的区别。对做产品的人,问题变成了,这十几分,值不值几十倍的成本。
很多任务的答案是不值。客服、分类、信息抽取、搜索改写自不必说,连写代码、跑 agent 这种硬场景,差距也常常没大到非最强不可。有开发者在 OpenCode 上实测后就说,M3 做代码审查又快又好,还挑出了连 GPT 都没报的问题,写出来的代码也够用,只是遇上大型代码库,比别的模型更得有人盯着引导。把全部身家押在“最强比次强多那一点”上的产品,很可能在模型下一次升级、把那点能力白送出去之后,立刻没了存在的理由。
02 把模型握在自己手里
性价比是第一眼就能看到的好处,但光便宜还留不住人。留人的是确定性:模型在自己手里,能部署、能改、能换,明年还是这个样子。
闭源 API 则不然。供应商随时可能涨价、限流,甚至自己下场做同款、回头跟你抢生意。Windsurf 就吃过这个亏,Anthropic 一边自己做 Claude Code,又限制了它对 Claude 模型的直连访问,这是命门握在别人手里。把核心能力架在别人的接口上,主动权从来不在自己手上。开源模型你能自己部署自己跑,也能挑个便宜的托管商,不必被某一家 API 的定价和脸色绑死。便宜、开放、够用,这对闭源模型来说几乎是不可能三角。
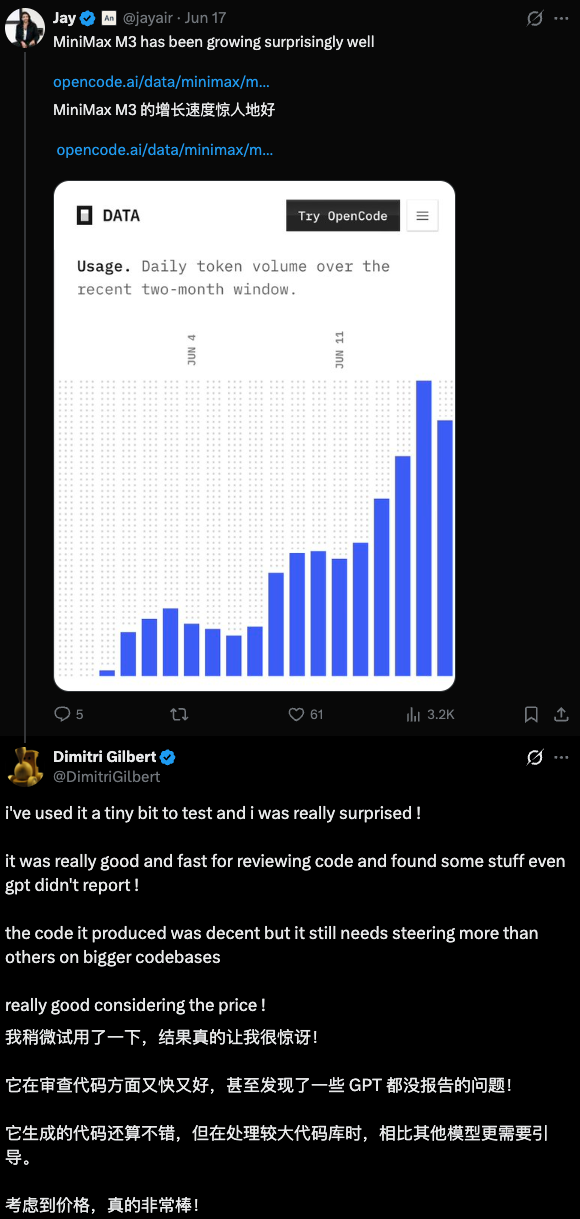
开源模型能被真正用起来,靠的也不只是便宜。Airbnb 的 CEO 就公开讲过,公司大量用中国开源模型 跑客服 Agent,图的就是又好又快又便宜。类似的选择也开始出现在更多产品和开发者工具里,从 Notion 的 Custom Agents,到开源编程平台 OpenCode,开源模型的热度没有只停在发布当天,很快转化成了调用量。OpenCode 的模型调用量排前二的分别是 DeepSeek 和 Minimax。平台还专门给 M3 延了限时三倍额度,OpenCode 联合创始人 Jay V 也发帖说它“涨得出奇地好”。
03 开源模型主要来自中国
开发者越来越多地用中国开源,还有一个常被忽略的原因,能挑的开源模型本来就在变少。
美国不是没有开源模型。OpenAI 去年发过一次 gpt-oss,是它六年来第一次开放权重,口碑也不错;Google 的 Gemma 一路更新,多个尺寸、单卡能跑,但几家最前沿的实验室,重心都在闭源那头。Anthropic 根本不做开放权重,OpenAI 那次之后再没下文,曾被寄予厚望的法国 Mistral 也渐渐掉出了第一梯队。
Meta 一度是开源大模型的旗手,一个 Llama 撑起过大半个开源生态;可如今它号称两万亿参数的旗舰 Behemoth 迟迟没公开,反手发布了自己第一个闭源前沿模型。连曾经最大的开源玩家都掉头做闭源了。
数下来,美国还在持续做开放权重的,主要就剩 Google 的 Gemma。但 Gemma 最大也就 270 亿参数,胜在小、能单卡跑,真正前沿规模、在写代码和 agent 上拿得出手的开源模型,还得看中国这几家。Qwen、DeepSeek、GLM、MiniMax 一年到头密集更新,从小到大的尺寸、各种任务和模态都铺得很满,不久前还出现过三周内四家中国实验室连发四个开放编程模型的名场面。
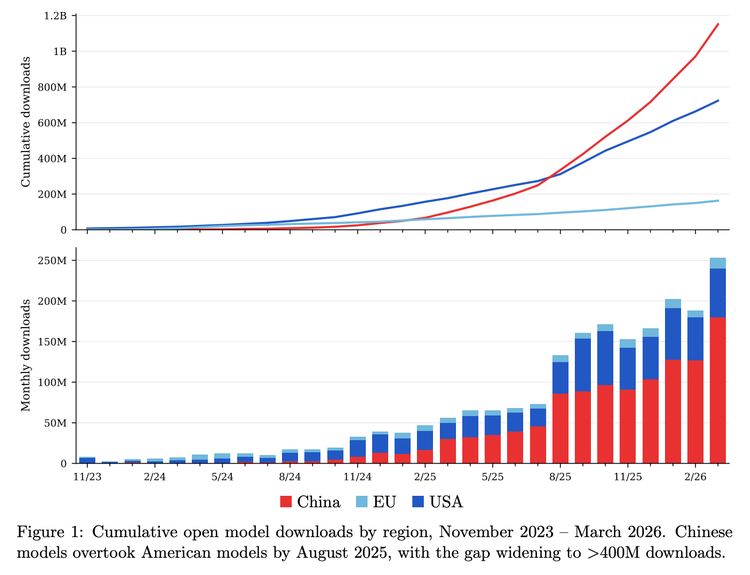
追踪开源模型动向的 ATOM 项目算过,从 23 年年末开始的两年时间里,全球新增的开源衍生模型中基于 Qwen 的占了约七成,Llama 则从两年前四成多的高点跌到了一成。项目发起人、AI 研究者 Nathan Lambert 在报告里说,美国在开源模型上已经丢了领先,性能和采用率都落了后。换句话说,美国还握着最强的那几个模型,只是都锁在闭源里;开放、能随便拿来用的那一大批,如今主要来自中国。
除了高频发布,使用量也在增长。在 OpenRouter 这类第三方调用平台上,周用量榜的前几名几乎被中国模型包揽,DeepSeek、MiniMax M3、腾讯混元等排在最前面,靠前的美国模型反倒多是闭源的 Claude。调用平台之外,中国开源模型也越来越多地进入海外开发者的工具链,DeepSeek 已经是 Fireworks、Together、Ollama 这些海外推理平台的常驻选项,M3 上线后也很快铺了上去,还被 Nous Research 的开源 agent 框架 Hermes Agent 接入。后者还专门做了 MiniMax 的官方适配,并公开称会和 MiniMax 在产品和模型上合作,让后续发布更适合 Hermes Agent 用户。
04 国内开发者到底在骂什么
回到国内,其实用得一点不少,不少团队就拿 Qwen、DeepSeek、MiniMax 当底座做产品。可一到公开讨论,吐槽的声音往往更响。
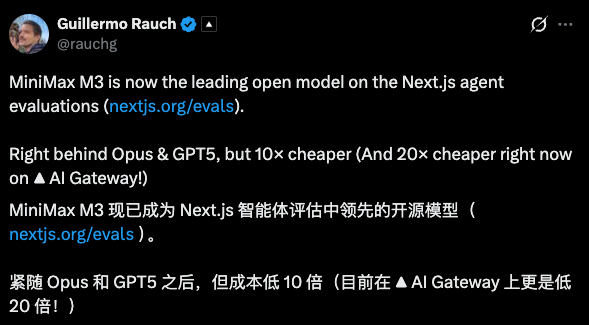
这个月初发布的 MiniMax M3,就是最典型的一例。海外这边的成绩前面提过,它在 AA 的那份榜单上排到了开源模型第一;Vercel 的 CEO 还在 X 上公开发帖,说在自家 agent 评测里 M3 紧随 Opus、GPT-5,却便宜十倍。Vercel 是 Next.js 背后、全球最大的前端部署平台之一。
MiniMax 是国产模型里全球化走得比较早的一个,去年七成以上的收入来自海外,海外开发者买账不新鲜。但差不多同一时间,国内社区吵翻的全是套餐怎么算,几乎没人在谈 M3 强不强。MiniMax 改了计费方式,老用户嫌权益缩水闹着退款,最后道歉、补偿了事。关于价格的争执,几乎盖过了对模型本身的讨论。
GLM 此前也经历过类似风波。新套餐上线后,用户抱怨模型放量慢、规则不透明、老用户升级机制不合理,智谱最后公开致歉并提供退款和补偿。模型能力、产品体验和收费方式原本是三个层面,到了用户那里,往往会合并成对同一个品牌的整体评价。
而国内讨论国产模型,还有两层海外没有的额外要求。一层是把它当成中国 AI 有没有原创突破的标尺,好不好用之外,还要追问它是不是蒸馏、有没有跟着别人跑;另一层是动不动拿它跟 Claude、GPT 的上限直接比,问它为什么还不是最强。两种预期加在一起,模型有多少人在用、好不好用反倒不是重点了。
国内对国产模型的关注,也常常慢一拍。DeepSeek 就是这样,真正让它彻底出圈的,是它先在美国冲上 App Store 榜首,并引发全球资本市场对 AI 成本的重新估算。海外先用起来、先讨论起来,国内才回头重新打量,这样的情况并不少见。
国产模型撑起了全球大半个开源生态,被海外公司拿去做底座,被第三方评测给到开放权重的最高分;可回到国内,被念叨最多的却是套餐价格。同样一份成绩单,贴上硅谷的牌子,待遇大概是另一个样子。DeepSeek 已经证明过一次,可以先在海外被认真使用,再倒逼国内重新看见它,类似的事情会在更多中国开源模型身上重演。
作者|周一笑
本文由人人都是产品经理作者【硅星人】,微信公众号:【硅星人Pro】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。









这个“够用就行”的逻辑很硬。很多产品根本不需要每次都上SOTA,成本降下来、部署灵活、不被供应商绑定,这些才是做产品的人真正在意的。国产开源模型恰好把这三个点占全了,海外用起来顺理成章。