
 起点课堂会员权益
起点课堂会员权益谷歌硬刚OpenAI,但缺王炸
谷歌I/O大会也如期召开了,在万众瞩目的AI领域,谷歌也宣布了若干新消息。不过就在一堆新名词向用户涌去时,能留给人深刻印象的东西,多吗?

五月真热闹,OpenAI才开了春季发布会,谷歌I/O大会也如期召开了。
实话实说,观看主题演讲直播的过程中,脑海不禁会浮现曾被谷歌内部员工泄露的梗图——谷歌AI产品和项目一个又一个不同又相似的名字令人头大。
主题演讲的关键词仍旧是AI,谷歌还自己在现场给出了提到“AI”的次数,在120次以上。
在万众瞩目的AI领域,谷歌宣布了若干新消息。
AI大模型升级了两个,Gemini 1.5 Pro双下文窗口拓展到200万令牌、Gemini Nano增加多模态理解能力;新发布了三个,更轻更快的Gemini 1.5 Flash、新架下的Gemma 2.0,以及视觉语言模型PaliGemma。
另有文生图模型迭代至Imagen 3,还新发布了一个文生视频模型Veo。
AI的具体应用延展上,谷歌这次憋了不少招。
谷歌的核心产品搜索中,发布AI Overviews,加强版AI搜索摘要功能将率先上架美国。谷歌搜索中还将加入制定计划、视频搜索等多重AI驱动的功能。
此外,Gemini还被塞进谷歌照片以及即时通讯应用Google Messages等产品中。
让人联想到OpenAI才发布的GPT-4o的,是谷歌旨在打造未来通用AI助理的新项目Project Astra,以及Gemin的新功能Live。Gemini Live支持与AI语音聊天,年内预计加入相机功能,和AI实时“视频通话”。
有点尴尬的是,在第三方拉流的直播间里,观众直呼“无聊”,并对眼花缭乱的名字感到困惑。CNET的评论员指出,谷歌需要精进讲故事的能力,而不是一上来就将各个部分尽数展开。
01
OpenAI赶在谷歌I/O大会前一天开春季发布会,原本盛传的搜索产品没来,但“人类级别响应”的GPT-4o让人一窥新一代AI助理大战的轮廓。
难以想象要是没有OpenAI的狙击,谷歌会有多开朗。
本次谷歌I/O大会上,原本最具惊喜的也是AI助理方面的进展。
首先,谷歌公布了一个新项目,名为Project Astra。用谷歌Deepmind负责人哈萨比斯(Demis Hassabis)的话说,这是真正通向AGI的万能助手项目。
相比于谷歌上一代AI助手Google Assistant,Project Astra的AI助手模式多样,且能实时交互。没有烦人的唤醒词,也没有尴尬的延迟。看你所看,为你排忧解难。
演示视频中,用户打开手机摄像头,对准任意物品,AI可以准确说出物品的名称,如“这是一个音响”。用户可以实时视频的同时,在屏幕上涂画、进一步向AI提问,如画一个箭头指向音响的某个部分,询问是什么。当用户将镜头对准窗外时,AI则直接根据景色猜测出用户所在的地点。

在摄像头匆匆扫过场景的情况下,用户求助“眼镜放在哪儿”,助手准确识别并回答“你的眼镜在红苹果的旁边”。
去年12月,Gemini就曾发布通过视频和AI互动的视频,但事后承认视频经过剪辑,谷歌为此没少被戳脊梁骨。
有意思的是,这次在演示视频的一开头,谷歌就郑重承诺,视频是实时、一次性拍摄的。

不过,谷歌尚未针对Project Astra给出明确的时间线,只是含糊地表示今年晚些时候其中的一些功能将更新到Gemini及其他应用中。
谷歌在AI助手方面还有更看得见、摸得着的进展——Gemini Live,也就是对Gemini产品进行多模态功能拓展。Gemini Advanced用户将可以用语音和Gemini进行对话,对话更流畅自然,延迟更低,可以随时打断,预计夏天上线。谷歌还表示,今年年内将加入相机功能,实现实时视频。
可以说这一次,谷歌被OpenAI精准狙击——GPT-4o不仅早一天发布,而且现场演示,未来几周就会开放给全部用户。
02
近日外界都在盛传OpenAI将推出搜索类产品,与谷歌一战,但这样的情况并没有发生,而谷歌自己也已经马不停蹄地升级了谷歌搜索。
搜索作为谷歌的核心产品,即将迎来一次大升级——搜索摘要功能AI Overview,同时包含多步推理功能Multi-Step Reasoning、在搜索中做计划Planning in Search,以及用视频提问Ask With Video。
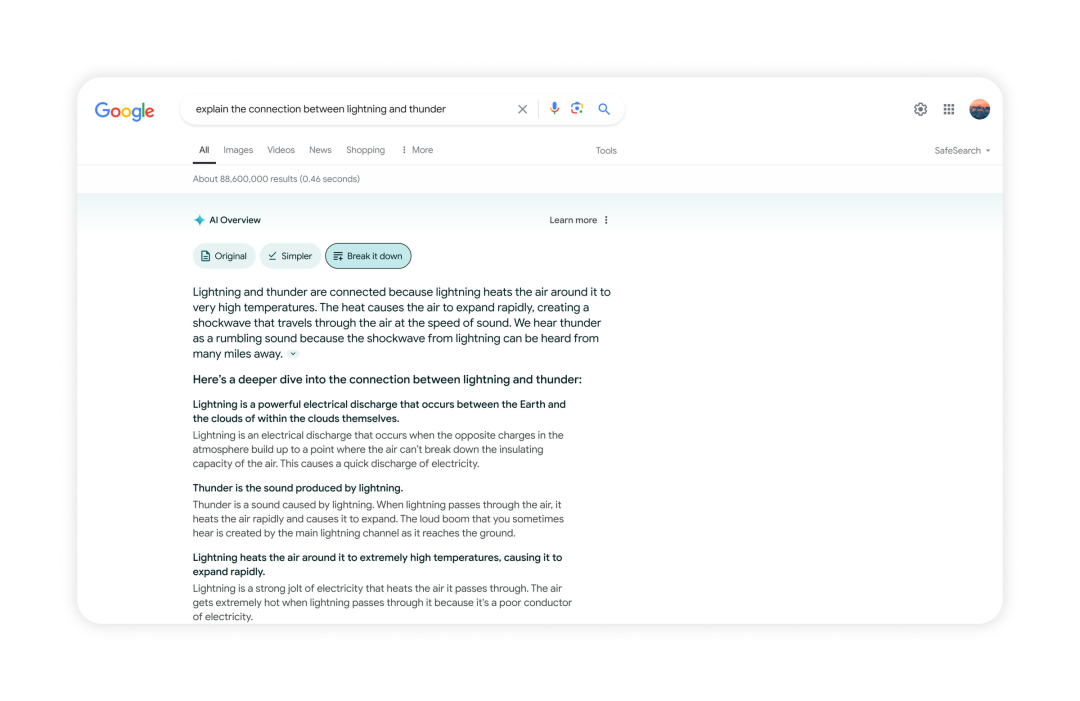
AI Overview,顾名思义,是指用户键入文本、点击搜索之后,出现在最上方的将是AI帮忙整理的信息摘要。其中包含用自然语言对搜索结果的总结和概括,以及推荐的链接。从前这被谷歌称为“搜索生成式体验(SGE)”。
多步推理Multi-step reasoning则可以用来做计划。当用户在搜索框键入“附近最好的瑜伽馆”时,AI摘要会将附近瑜伽馆依照评分、课程、距离等信息分类成块,更清晰地展示给用户。Planning in Search则允许用户直接用谷歌搜索做计划,如在搜索框中键入饮食计划的需求,搜索引擎会给你自动生成一份。

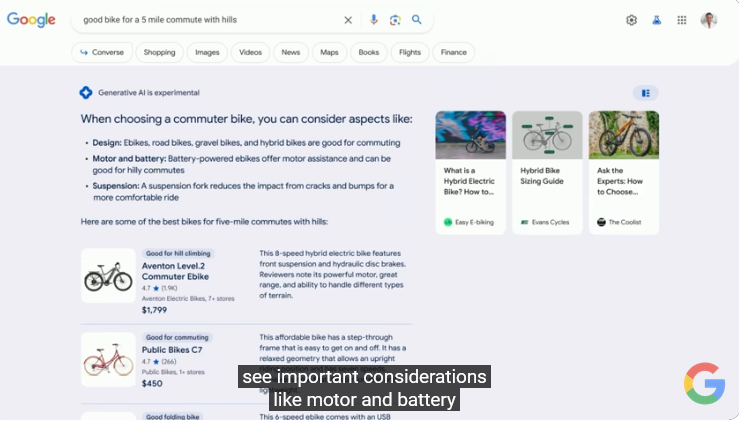
想要搜索商品的时候,AI同样会发挥作用,在搜索框键入“有上下坡的五英里通勤自行车”,搜索引擎会在上方给出选购自行车的思路建议,并给出若干商品推荐。
从一个又一个详尽的演示不难看出,谷歌已经下定决心重塑搜索体验。
不过,AI搜索在很多竞品中都已经被应用,更有专做AI搜索的Perplexity.AI。谷歌对搜索体验作出的重大升级,放在2024年的5月已经不大能带来新鲜感。
应用生态的其他新动作更像是补齐,如Gmail邮箱、Google Messages通讯、谷歌照片等,Gemini逐渐拓展到越来越多的谷歌应用中,大有“Gemini无处不在”的态势。
03
AI背后的模型,谷歌这次也是大手一挥,升级的升级,新发布的新发布,Gemini家族不断壮大。
三个月前发布的Gemini 1.5 Pro终于“发货”了,即日起正式开放给订阅了Gemini Advanced(类似ChatGPT Plus)的用户。
Gemini 1.5 Pro支持100万token的上下文窗口,今年晚些时候将会增加到200万token。更形象地说,升级后的Gemini 1.5 Pro能同时处理22小时音频、2小时视频、超过60000行代码或140万个单词。
新发布的模型中,Gemini 1.5 Flash原本有明星潜质,但被OpenAI狙击。GPT-4o驱动的ChatGPT狙击Project Astra和Gemini Live,GPT-4o狙击Gemini Flash。
Gemini 1.5 Flash主打更轻更快,反应速度和效率是其主打特色,拥有多模态推理能力,擅长总结、聊天、图像、文档数据提取、视频字幕等。但这些特点,显然和GPT-4o撞车了。
除此之外,谷歌的开源模型Gemma也发布了新版本,Gemma 2.0有270亿参数,并拓展出多模态版本PaliGemma。
多模态生成式模型,谷歌在I/O大会上公布了三个,涵盖图像、音乐和视频。
文生图模型谷歌此前就有,此次做了迭代,发布Imagen 3。Imagen 3对提示词的理解更加准确细致,可以生成更逼真的图像。在演示中,Imagen3从一长段提示词中提取了8个细节信息,并在生成的图像中一一体现。

音乐生成模型Music AI Sandbox是全新的,用户可以用小段Demo拓展延长,也可以按照文本提示对音乐进行再创作,改变和调整音乐风格等。鉴于谷歌旗下还有YouTube等UGC平台,此类模型将很好地服务于创作者。
更惹眼的其实是谷歌此次新发布的文生视频模型Veo。

谷歌Veo可接收文本、图像和视频提示,生成1080p规格、60s的高质量长视频。
年初OpenAI曾发布Sora,虽未正式对公众开放使用,但演示视频和小范围的测试已经让Sora获得了不小的追捧。从演示的效果来看,Veo可与Sora一战。
这届I/O大会,谷歌交出了诚意满满的“成就清单”,大模型仍在进步和创新中,AI应用生态也不断发展。
但新名词轰炸之后,能留给人深刻印象的东西并不多。比起前一天发布GPT-4o让外界感叹科幻电影照进现实的OpenAI,谷歌到底还是缺一个王炸。
本文由人人都是产品经理作者【字母榜】,微信公众号:【字母榜】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


