
 起点课堂会员权益
起点课堂会员权益Pinterest A/B 测试平台构建的解决方案
A/B测试、灰度发布是精益产品增长最常见的实践,除了掌握方法,一个高效的工具也是开展实验的基础,译文即为Pinterest A/B测试平台搭建的整体概述,让你对这样一个平台的构建会有大体的认识。如果你是非技术人员也可移至文末,看滴滴出行在数据驱动平台搭建以及A/B测试、灰度发布方面的真实案例。
以下为译文,有编辑:
作为一个数据驱动的公司,我们总是会基于实验去指导产品设计和功能开发,在过去一段时间,我们跑了大概有1000个实验,并且每天都在增加,不断增长的实验量以及产生的海量数据,驱使我们需要有一个稳定的、精准的、简单易用的平台来支撑增长团队的使用需求,为了排除实验过程中的一些共性问题,我们开发了一个操作更加轻量、支持跨平台协同以及一些精简的API接口来满足A/B测试过程中可能要面对的复杂问题。
在搭建这样一个平台的时候我们优先考虑了以下需求:
- 配置实时:我快速响应实验需求,能够随时关闭或启动实验,而不需要在代码层面做更改,特别是需要修复网站的事件
- 操作轻量:实验设置要像启用一个功能那样简单,当然,也要能规避一些预先能想到的错误操作
- 学习成本低:使用者不需要因为平台的不同而学习新的实验方法论
- 易于分析:为了能够更好的辅助决策,我们构建了一个新的并且易用的分析看板
- 扩展性强:我们需要这样一套系统能支持线上和线下实验数据的处理
一、流程优化
Pinterest的实验都遵循一套通用的方法论:
- 提出假设。并且针对假设提出一些验证的猜想;
- 筛选实验用户群。创建用户组、禁用组、通过过滤器修改组;
- 分发变量给实验用户,并记录实验结果。
在我们以前的框架下,这些变量的配置都是通过修改代码的方式,然而,我们希望把这些变量的控制能够在前端界面组织起来,在可配置的框架下,独立于代码做些变量控制。
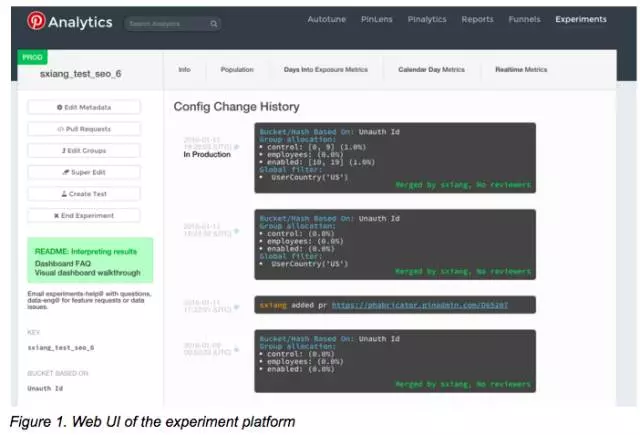
实验过程中有些共性的问题,比如语法错误、不均匀的用户分组、组用户重叠或者实验流程不规范,我们也主动地在输入框预设了一些查询字段,尽可能的减少了手动输入造成的错误,如图2,跑一个实验通常就是几个点击这样简单。
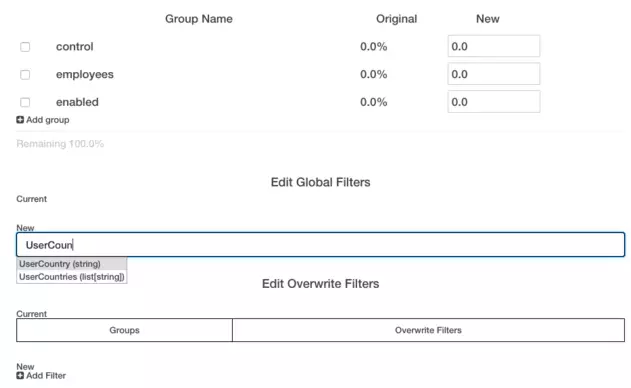
为了让任何人能够实时地、便捷地进行实验配置,我们在内部的系统中以串行队列的方式存储了所有的实验设置,并且在几秒内同步至我们每个实验系统的主机上,一个典型的配置文件有如下几个内容:
{“holiday_special”:{“group_ranges”: {
“enabled”: {“percent”: 5.0, “ranges”: [0, 49]},
“hold_out”: {“percent”: 5.0, “ranges”: [50, 99]}
},
“key”: “holiday_special”,
“global filter”: user_country(‘US’),
“overwrite_filter”: {“enabled”: is_employee()},
“unauth_exp”: 0,
“version”: 1
}
}
配置和代码分离最大的好处是提升了我们的实验效率,这意味着变量的控制效率高了,比如实验组需要增加流量不需要在代码层面做调整,极大的释放了实验的部署时间,加快了迭代速度特别是原先有紧急需求的时候。
二、质量保证
1、代码监测
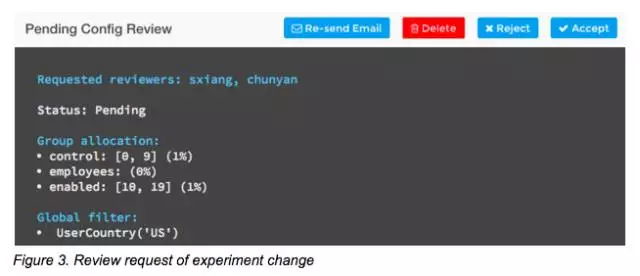
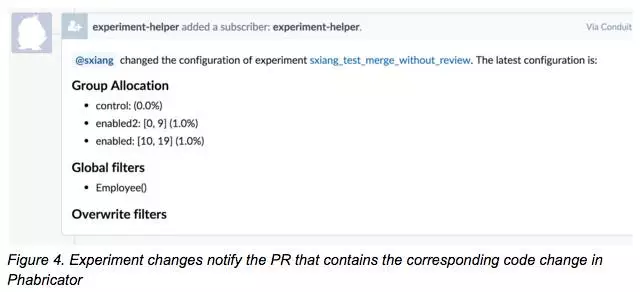
实验很简单但能影响数以百万计的用户,所以对实验工具的操作和结果的准确性都提出了很高的要求。执行实验的系统还内置了一个review工具,他会为每个实验加载一段review的代码。如图3显示的就是一个挂起的更改,这个时候可以修改组范围和筛选条件。
2、人工监测
对于很多实验,我们有一个由平台开发人员、使用者、数据科学家组成的小助手(helper)团队,几乎每一次变动都会要求一个helper去严格的检查方案设计、实验假设、关键结果、触发逻辑、筛选设置、组验证以及相关文档。这样的过程强加在平台上就使得每一次变动都必须有一个小助手辅助(监督)。当然了,我们也有常规的helper培训计划以确保每个团队至少有一个人可以做监督人。一个实验通常会关联到代码的改变,把对照组和实验组的信息嵌入到决策逻辑中,我们会要求实验操作人员通过Pull Request按钮增加一个Pull Request链接。
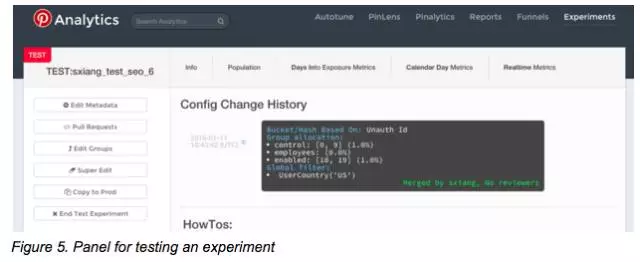
使用者可以在前端直接复制一个之前的实验(如图1),然后粘贴到如图5的测试区域内,在这个区域内的改动不会影响正式环境下的实验,并且那个执行复制操作的用户才能够访问
三、API接口支持
API接口用来支撑前端发送来的一些实验配置请求,以下提供了两个关键的方法:
def get_group(self, experiment_name)def activate_experiment(self, experiment_name)
特别说明一下,get_group方法将会返回被调用者定向了的组名,进一步来说,其实是基于实验信息计算了这个群组的哈希值(hash value),这个方法不会形成任何副面影响,另一方面,调用activate_experiment 给系统发送一条日志消息辅助了分析结果的产出,这两个方法基本覆盖了大部分的使用场景,并且被经常应用在以下环境下:
# Get the experiment group given experiment name and gatekeeper object, without actually triggering the experiment.group = gk.get_group(“example_experiment_name”)
# Activate/trigger experiment. It will return experiment group if any.
group = gk.activate_experiment(“example_experiment_name”)
# Application code showing treatment based on group.
if group in [‘enabled’, ’employees’]:
# behavior for enabled group
pass
else:
# behavior for control group
pass
上述代码所示中的gatekeeper object是用户/会话/元数据信息封装的,除了python库,我们有一个单独的JVM(Scala and Java)库来面向JS和移动端(Android和iOS)做支持 。
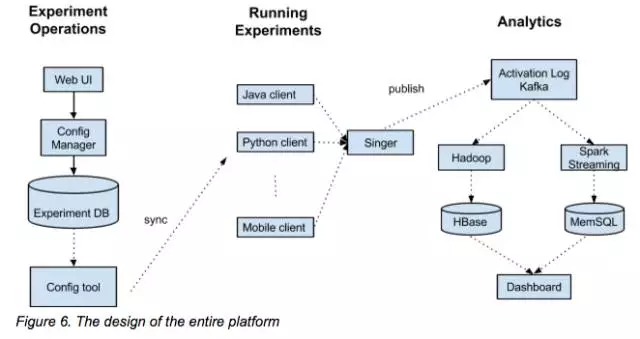
实验平台从逻辑上可以划分成三部分:配置平台、一组API接口和分析模块儿。
数据流向说明:
- 配置平台将用户在前端界面上的操作保留在实验数据库,这些信息将会定期通过串行的方式并且颗粒度足够细的上传到每一个服务器;
- 实验分析人员通过前端界面和调用API的方式去配置实验逻辑,比如实验类型设定、组筛选等;
- 实验产生的各种日志通过我们内部的Singer service上传至Kafka,分析模块儿将通过用户定义的数据指标生成实验结果并且把他们同步到看板 。
原文作者:Shuo Xiang
原文地址:https://engineering.pinterest.com/blog/building-pinterest’s-ab-testing-platform
译者:GrowthHub(微信公众号:growthhub)
本文由 @GrowthHub 翻译发布于人人都是产品经理。未经许可,禁止转载。





- 目前还没评论,等你发挥!


