
 起点课堂会员权益
起点课堂会员权益AIGC初学者:Stable Diffusion高效实操指南
Stable Diffusion是一款生成高质量图像的工具,生成的图像还很逼真。本文作者对这款软件的使用方法及功能进行了详细地介绍,希望能帮助到你的工作。

Stable Diffusion是一个文本到图像的潜在扩散模型,这个数据库拥有从互联网上抓取的 58 亿「图像-文本」数据,它可以生成包括人脸在内的任何图像,这些图像可以是逼真的,如相机拍摄的图像,也可以是艺术风格,就像由专业艺术家制作一样。
它有两个优势:
- 开源:许多爱好者已经创建了免费的工具和模型
- 专为低功耗计算机设计:运行免费或便宜
因为有开源的预训练模型,所以我们可以在自己部署机器上运行它。
一、界面部分
可以在顶部切换大模型checkpoint(可以在https://huggingface.co/下载尝试)

- Inkpunk-Diffusion-v2(偏赛博朋克 关键词是nvinkpunk)
- openjourney-v2/mdjrny-v4(中规中矩)
- Protogen_V2.2/deliberate_v2.safetensors (偏人像写实)
- woolitize768(偏超现实)
- chilloutmix_NiPrunedFp16Fix.safetensors(偏绘画)
- anything-v3-fp16-pruned(偏动漫)
1. Prompt 和 Negative prompt
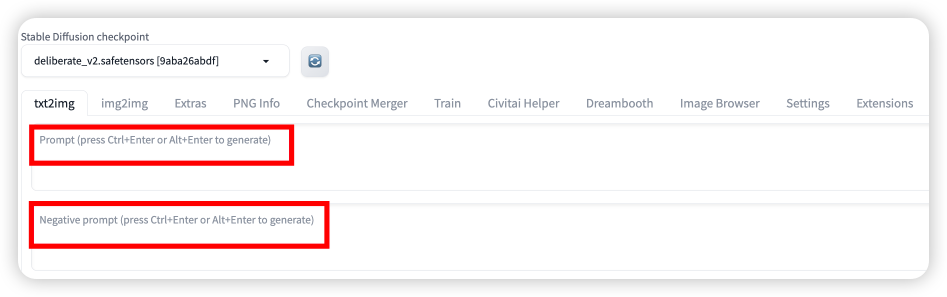
Prompt内输入的东西就是你所构思的场景,Negative prompt 内输入的就是你不希望在图中包含的。两个输入口只能输入英文半角,词语之间使用半角逗号隔开;一般越靠前权重越高(还是得多试)。
Negative Prompt(仅供参考):
cloned face, ugly, cross-eye,3d,render,realistic,((disfigured)), ((bad art)), ((extra limbs)),blurry, (((duplicate))), ((mutilated)),extra fingers, mutated hands, ((poorly drawn hands)), ((ugly)), ((bad anatomy)), (((bad proportions))), extra limbs, gross proportions, (malformed limbs), ((missing arms)), (((extra arms))),(fused fingers), (too many fingers), (((long neck))), tiling, (((nsfw))), (badhands)
(nsfw),EasyNegative,.badhandv4,ng_deepnegative_v1_75t,(worst quality:2),(lowquality:2),(normal quality:2),lowres,((monochrome)),((grayscale)),bad anatomy,DeepNegative,skin spots,acnes,skin blemishes,(fat:1.2),facing away,looking away,tilted head,lowres,bad anatomy,bad hands,missing fingers,extra digit,fewer digits,bad feet,poorly drawn hands,poorly drawn face,mutation,deformed,extra fingers,extra limbs,extra arms,extra legs,malformed limbs,fused fingers,too many fingers,long neck,cross-eyed,mutated hands,polar lowres,bad body,bad proportions,gross proportions,missing arms,missing legs,extra digit,extra arms,extra leg,extra foot,teethcroppe,signature,watermark,username,blurry,cropped,jpeg artifacts,text,error,Lower body exposureads, multiple people, group of people, fingers
结构建议:内容描述+风格描述+属性描述
内容描述:主题内容
风格描述:艺术家/画笔/摄影风格等 (可以参考以下个人比较常用的链接)
属性描述:比如Midjourney或者人像相关的lora模型(可以参考网站)
eg:字符分隔多个提示,则有四种可能的组合(始终保留提示的第一部分)

小Tips:
生成高质量图像的快捷方式是反复尝试调节现有描述。灵感收集可以从C站或者Midjourney热图,选择您喜欢的图像,然后学习不同作者的描述特点/方法论。
在寻找灵感收集人像Prompt时需可以注意Lora模型以及对应的Base Model,lora权重一般0.6-0.8(冒号后边)。
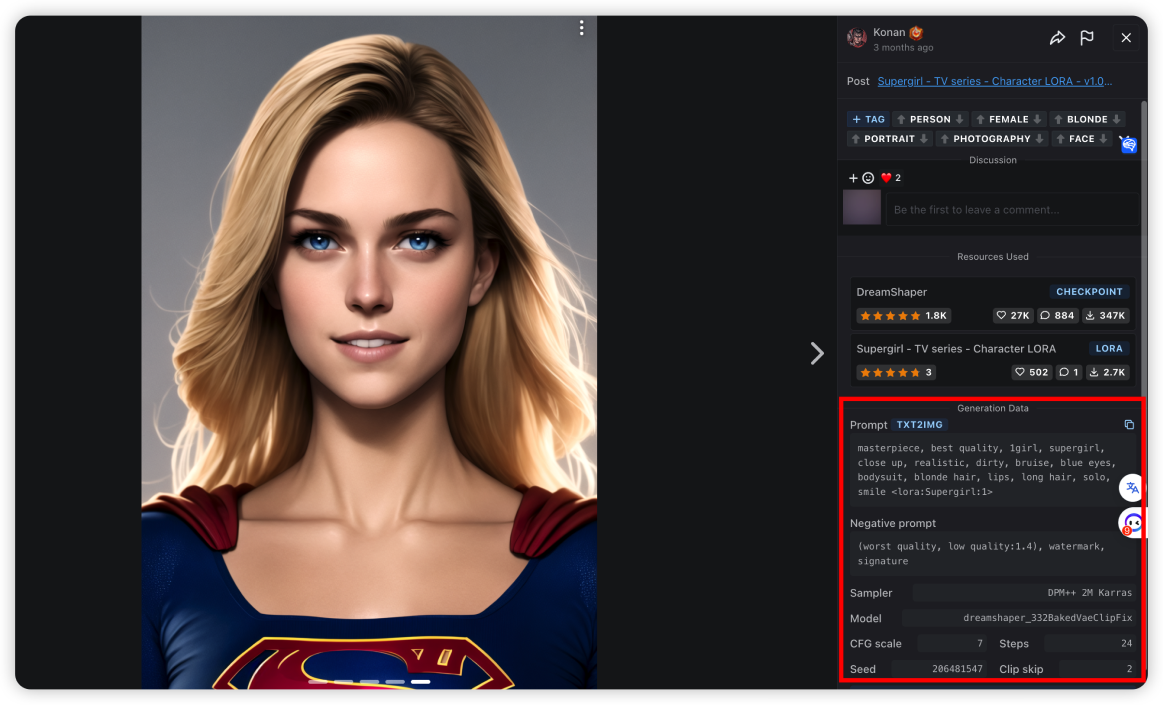
eg:<dalcefo, realistic, chromatic aberration, cinematic light, finely detailed face)>, portrait, Best quality, masterpiece, full body, brilliant colors, a girl, strapless white dress, sky, complex background, flying, white butterfly wings, long black hair, looking down, looking into the camera, lake, reflection, flying birds, delicate face, <lora:dalcefoNocopyV2_dalcefoNocopyV2:1>
Emoji、颜文字 Emoji (💰👨👩🎅👼🍟🍕) 表情符号也是可以使用并且非常准确的。因为 Emoji 只有一个字符,所以在语义准确度上表现良好。关于 emoji 的确切含义,可以参考Emoji List, v15.0 (unicode.org),同时 Emoji 在构图上有影响。
关于c站lora下载导入SD
可以在C站下载插件:
找到对应需求的lora链接
链接复制到Civitai这个tab中URL,点击获取
各个选项获取信息之后,填写下载的位置,目前/是根目录
点击下载即可,后续在生成按钮下方的红色选项卡选择已下载的lora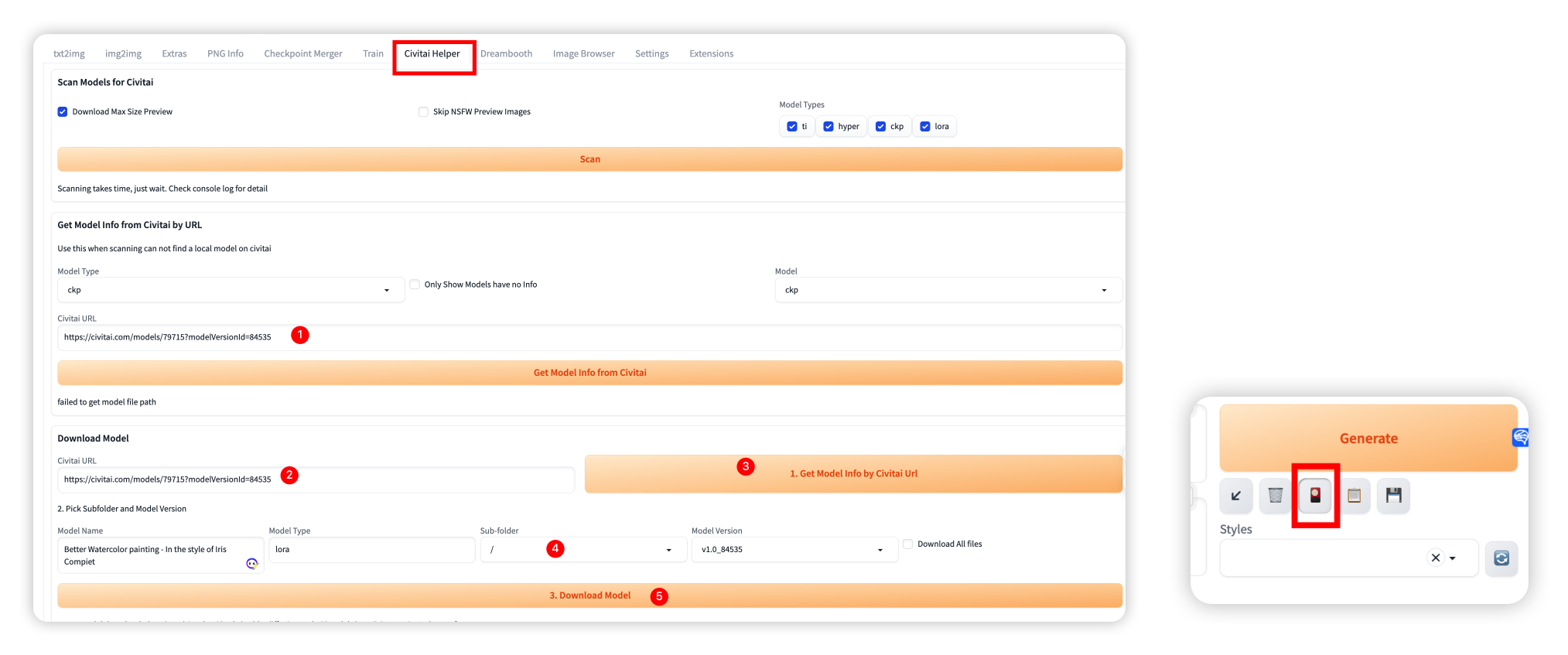
2. 权重调节
(best quality:1.3) 可以对关键词设置权重,一般权重设置在0.5~2之间。
eg:(8k, best quality, masterpiece:1.2),(best quality:1.0), (ultra highres:1.0),extremely luminous bright design, pastel colors, (ink:1.3), autumn lights, High Detail, Sharp focus, dramatic, photorealistic painting art by midjourney and greg rutkowski
使用括号人工修改提示词的权重,方法如下(请注意,权重值最好不要超过 1.5):
- (word) – 将权重提高 1.1 倍
- ((word)) – 将权重提高 1.21 倍(= 1.1 * 1.1)
- [word] – 将权重降低至原先的 90.91%
- (word:1.5) – 将权重提高 1.5 倍
- (word:0.25) – 将权重减少为原先的 25%
- (word) – 在提示词中使用字面意义上的 () 字符
( n ) = ( n : 1.1 ) (( n )) = ( n : 1.21 ) ((( n ))) = ( n : 1.331 ) (((( n )))) = ( n : 1.4641 ) ((((( n )))) = ( n : 1.61051 ) (((((( n )))))) = ( n : 1.771561 )
3. 采样方式
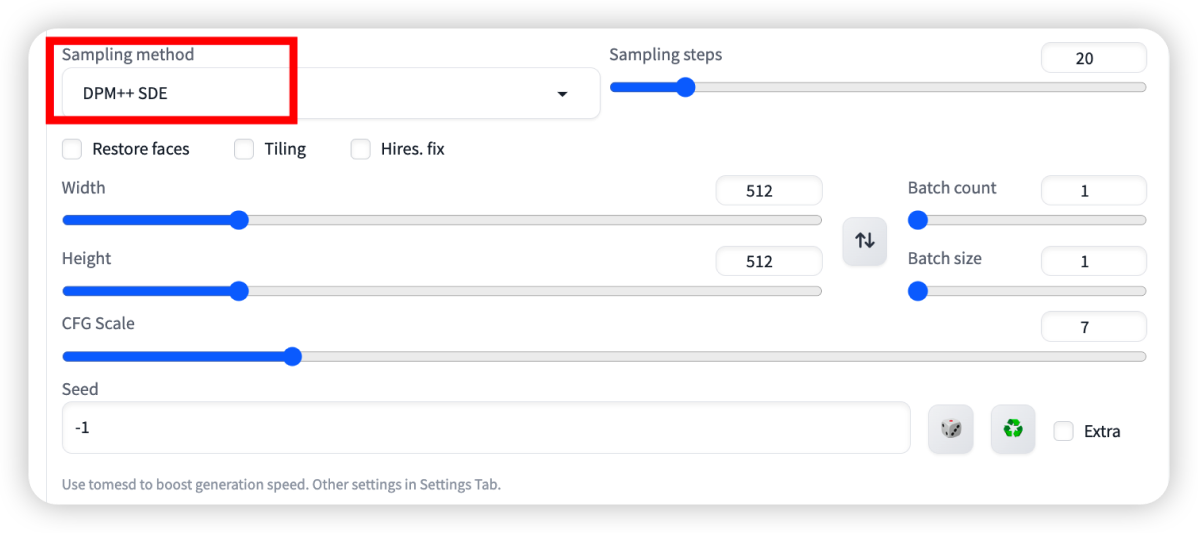
- Euler a:速度快的采样方式,随着采样步数增加并不会增加细节(*常用)
- DPM++ SDE:人像效果OK(*常用)
- DPM++2S a Karras 和 DPM++ SDE Karras等:相对于Euler a来说,同等分辨率下细节会更多,但是速度更慢
4. 采样步数
保持在20~30之间,较低图片展示不完整,较高细节偏差大(类似锐化)。
5. 生成数量(批量生成)
Batch count:每批生成几张图片
Batch size:显卡一共生成几批图片
生成的图片数量=批次*数量(越多速度越慢,建议加一个Grid功能多图进行拼图)
6. 宽高比例(展示画面内容大小)
方图512*512,倾向于出脸和半身像
高图512*768,倾向于出站着和坐着的全身像
宽图768*512,倾向于出斜构图的半躺像
7. CFG(提示词相关性)
CFG越小细节越少,CFG越高自由度越多(更飞);通常7-12,更丰富可以12-20,写实(也可以是用ControlNet时越接近原图)可以4-7,通过0.5为步微调。
image2image中Denoising strength是添加噪点的强度。也是类似噪点强度越高,AI的创作空间就越大,出图也就和原图越不相似。一般来讲阈值是 0.7 左右,超过 0.7 和原图基本上无关,0.3 以下就是稍微改一些。实际执行中,具体的执行步骤为 Denoising strength * Sampling Steps。
8. Seed(效果参数)
随机写一个参数(*-1是随机效果)可以再次使用该参数生成效果进行微调,也就是同一个Seed生成的图一般是一致的。
二、ControlNet 的使用
可以搭配服用,比如controlnet0用某张图的风格style, congrolnet1要处理的图(比如人像),这样生成的图既保持1的人像,又使用0的风格样式。
1. 小Tips:
controlnet预处理的图的mask分辨率和输出图的分辨率对不上,mask就会留边。
eg:风格预设:clip_vision 对应模型:t2iadapter_style_sd14v1 [202e85cc]

所选的 ControlNet 模型必须与预处理器一致。如图,对于hed应该选择control_hed-fp16 [13fee50b] 作为模型。None使用输入图像作为控制图。
Enable记得勾选应用。
2. Preprocessor&Model
带 hed 一般用于人脸
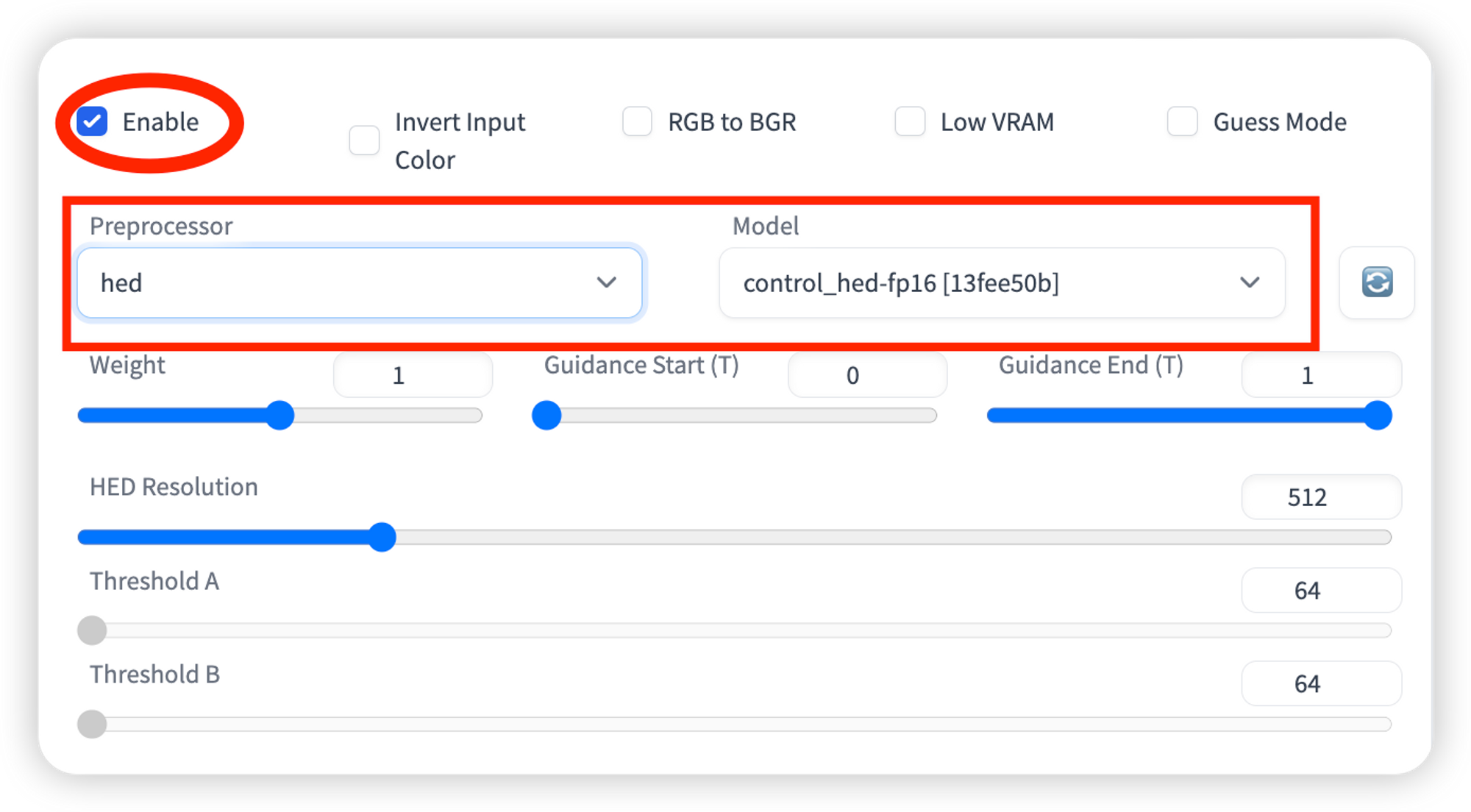
带softedge-hedsafe相较于hed质量更高更清晰。
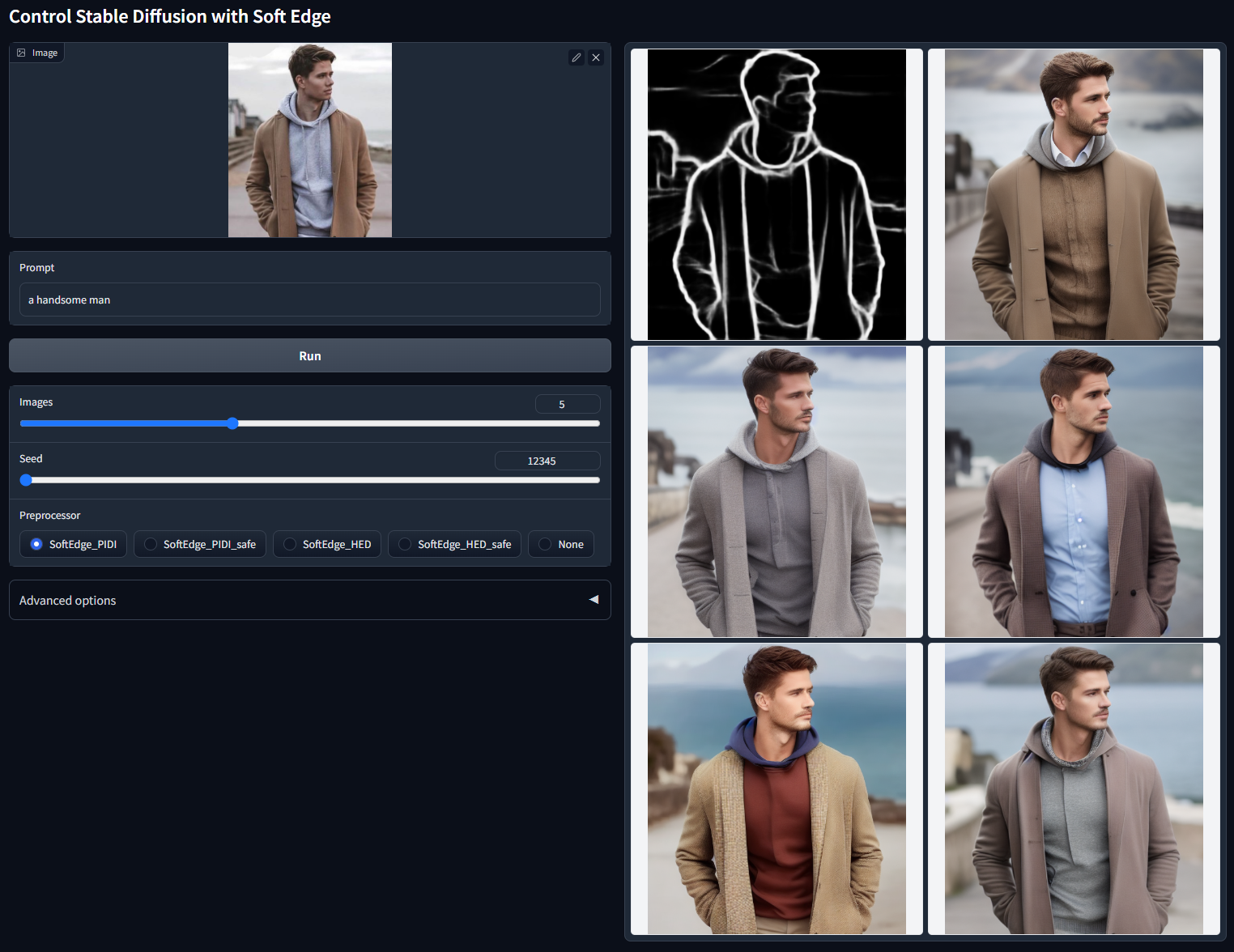
最高结果质量:SoftEdge_HED > SoftEdge_PIDI > SoftEdge_HED_safe > SoftEdge_PIDI_safe
考虑到权衡,我们建议默认使用 SoftEdge_PIDI。在大多数情况下,它运行良好。
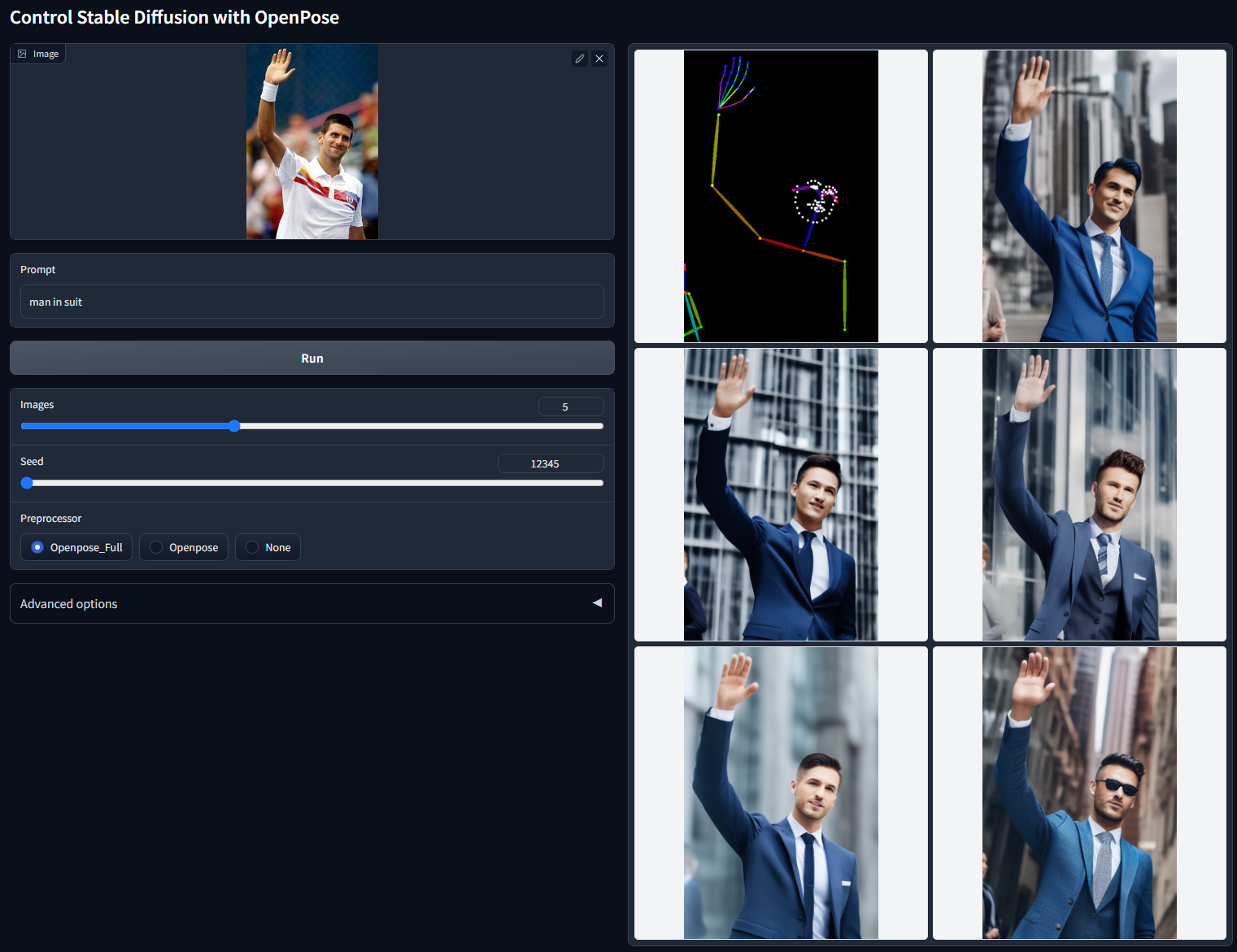
带Openpose一般用于姿势。
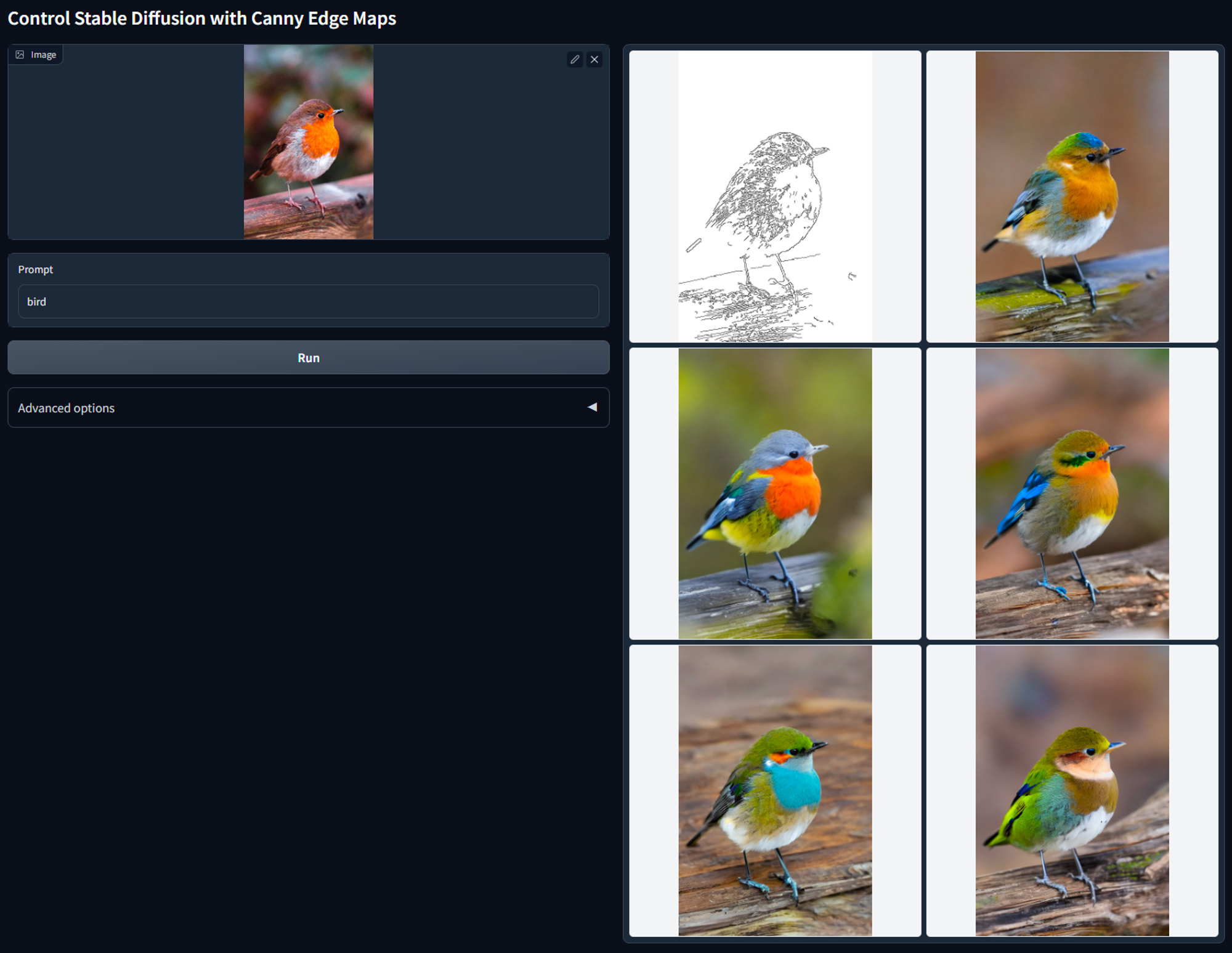
带有 Canny一般用于偏毛发细节。
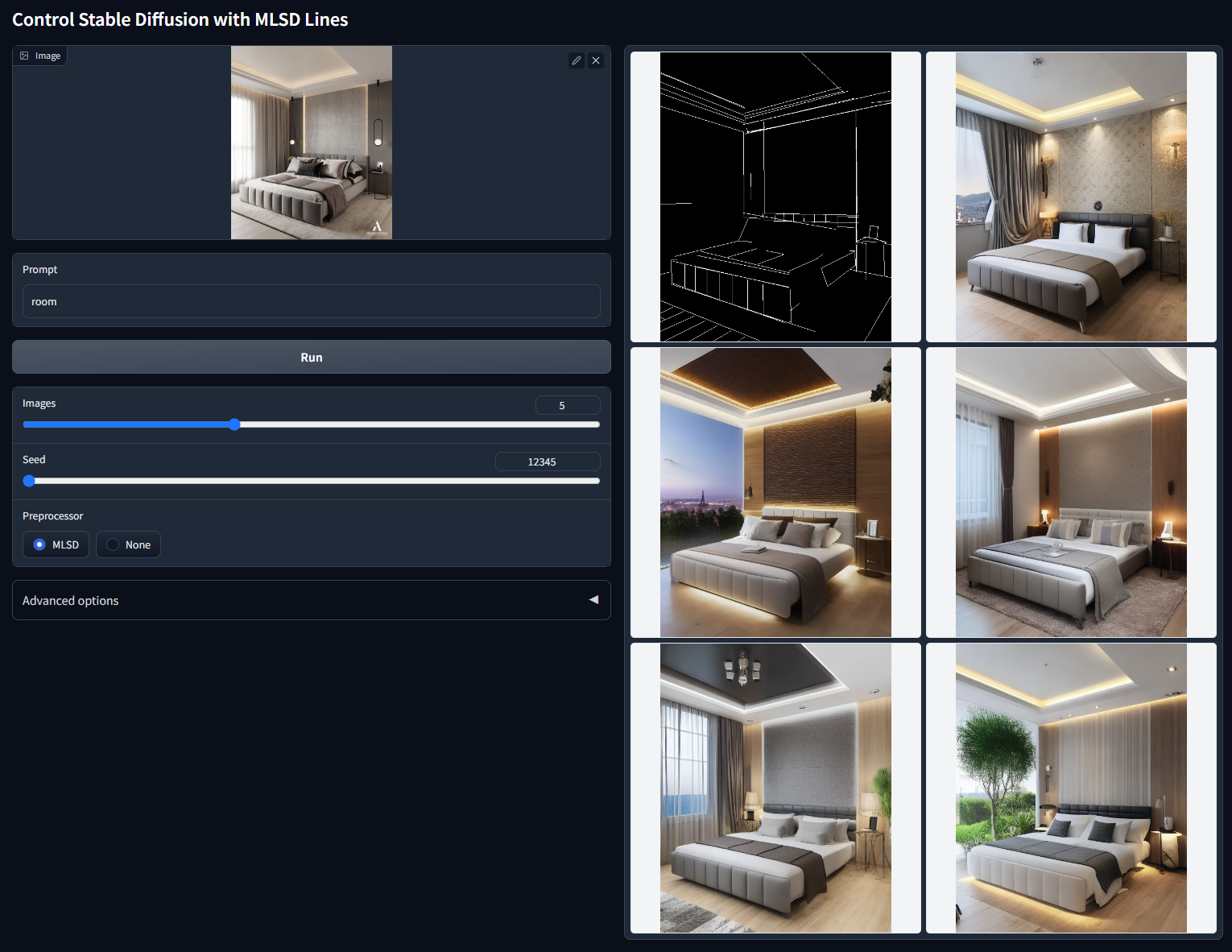
带 M-LSD一般用于建筑。
带 Scribble、fake_Scribble一般用于涂鸦。
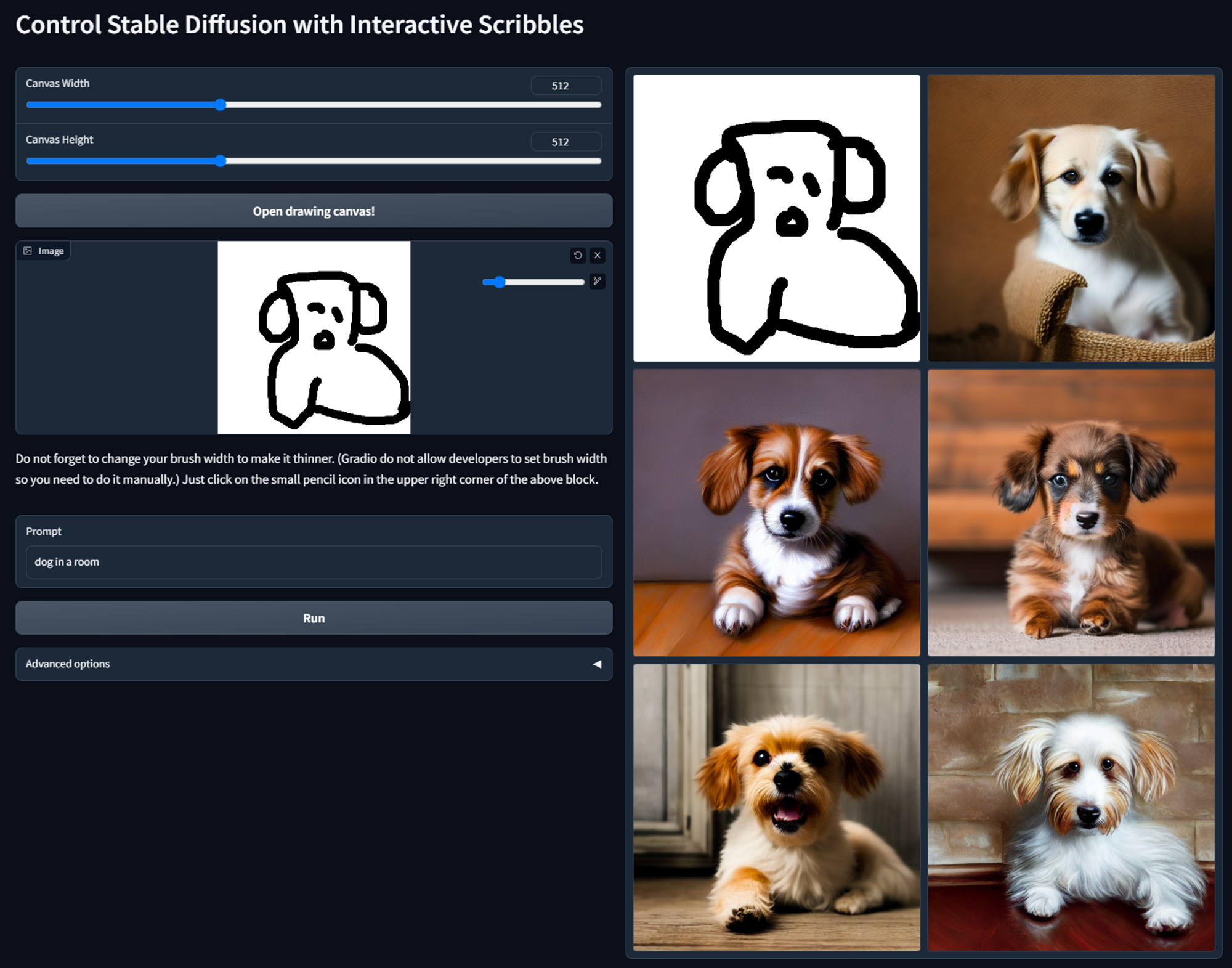
带 Depth一般用于轮廓比如人物(常用)。
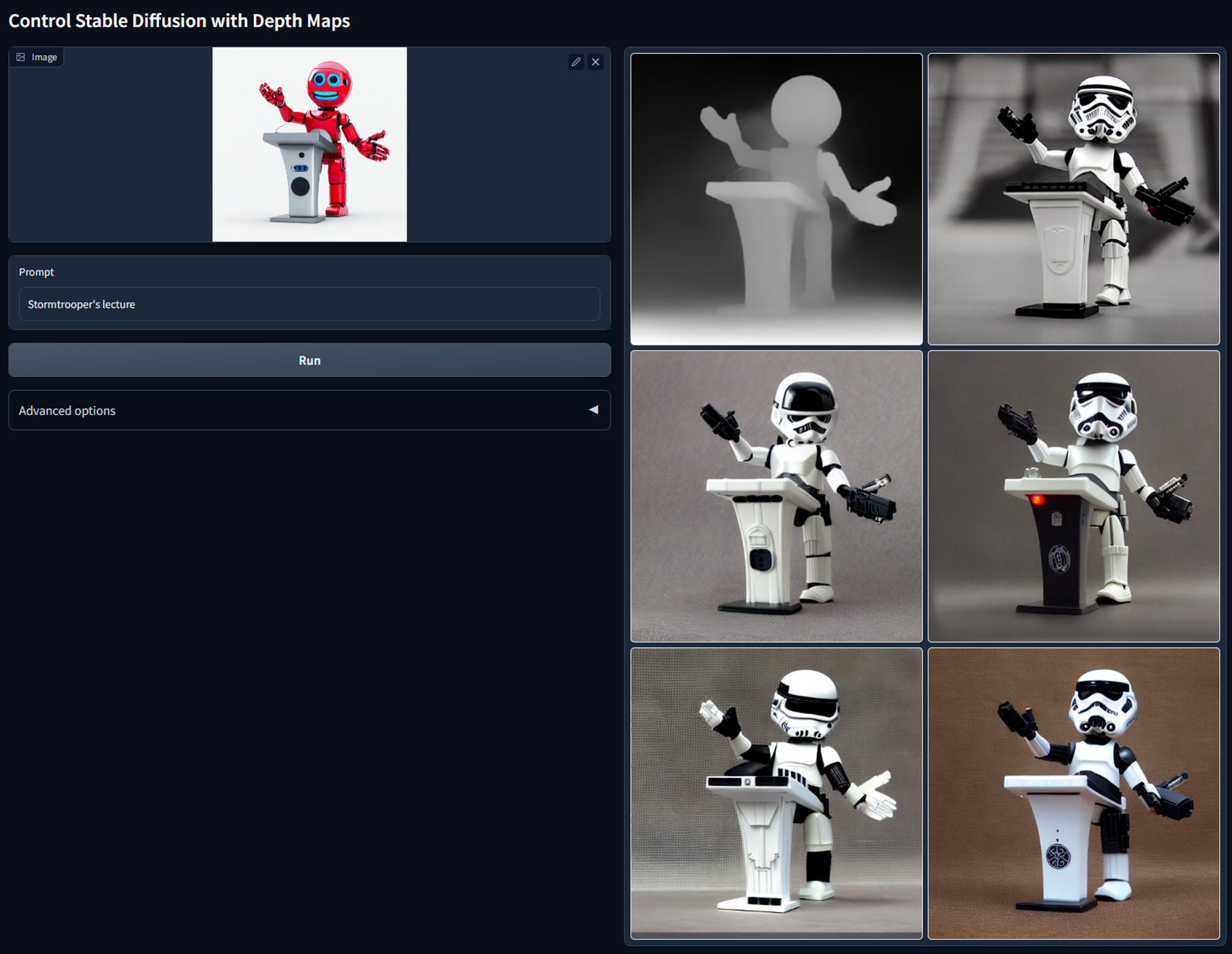
带 Normal一般用于物体细节,它是法线贴图图像,会一定程度上保留物体内部的细节,比如衬衫褶皱。
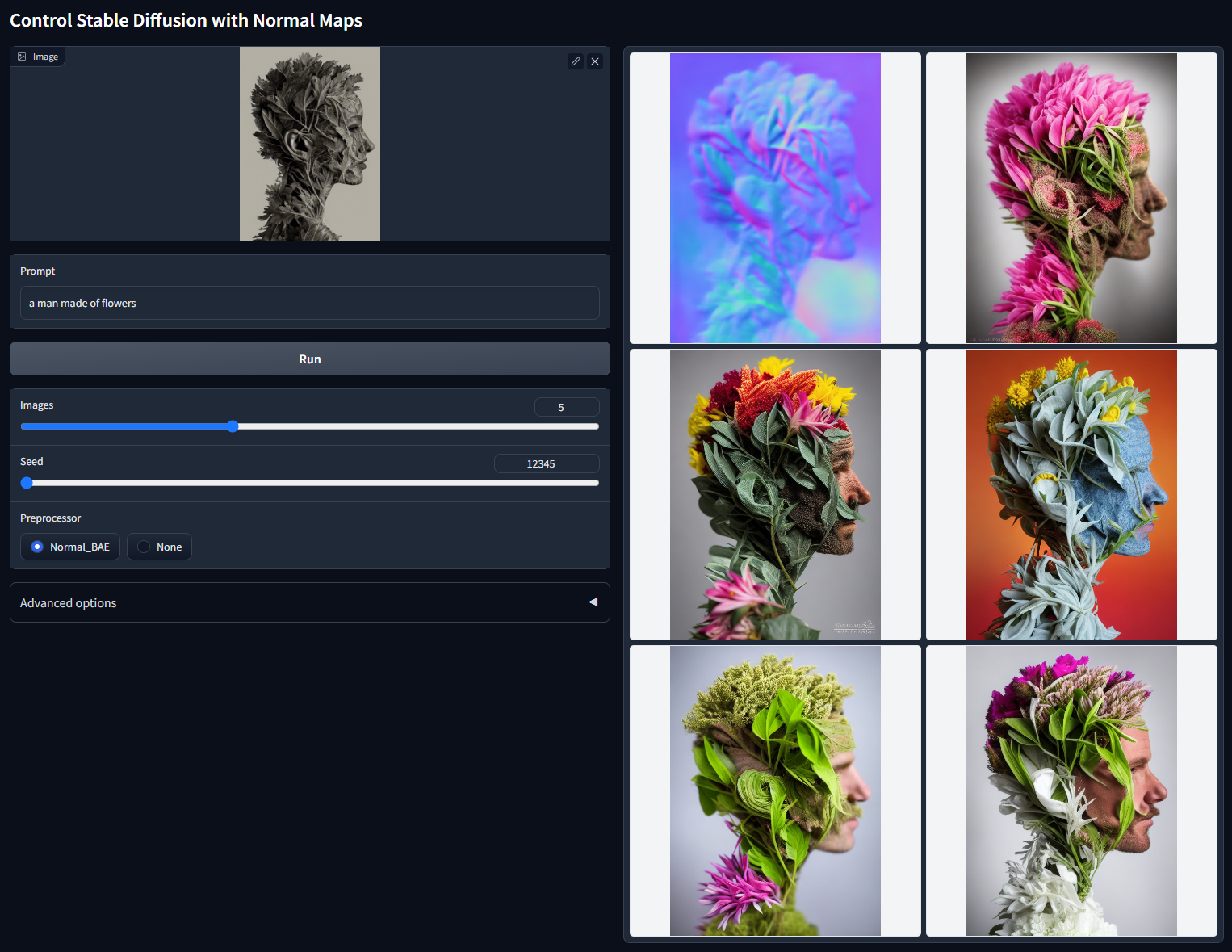
带Lineart一般用于粗略的线条。
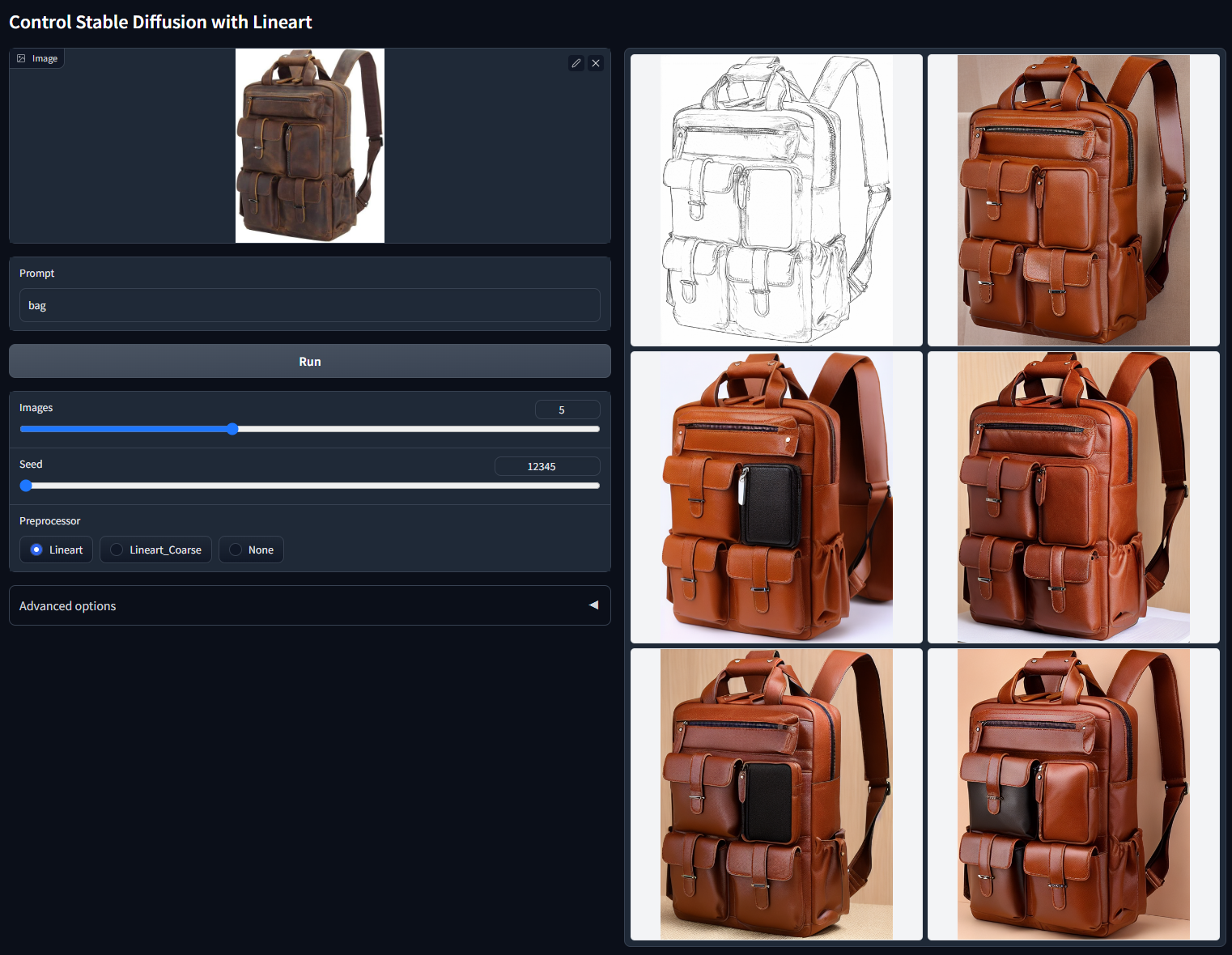
带Shuffle一般用于重新组织图像,随机洗牌图像来稳定扩散重构图像。
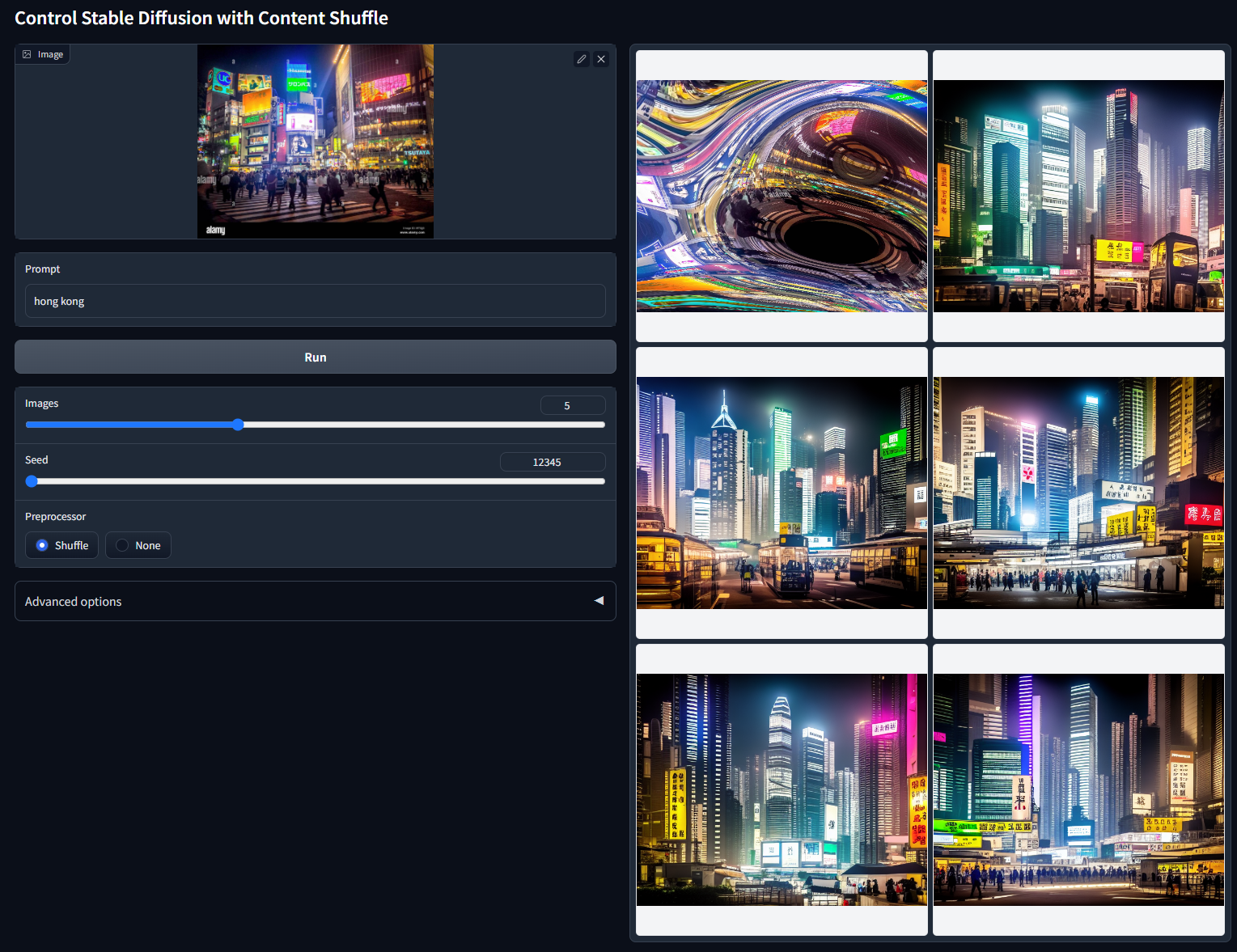
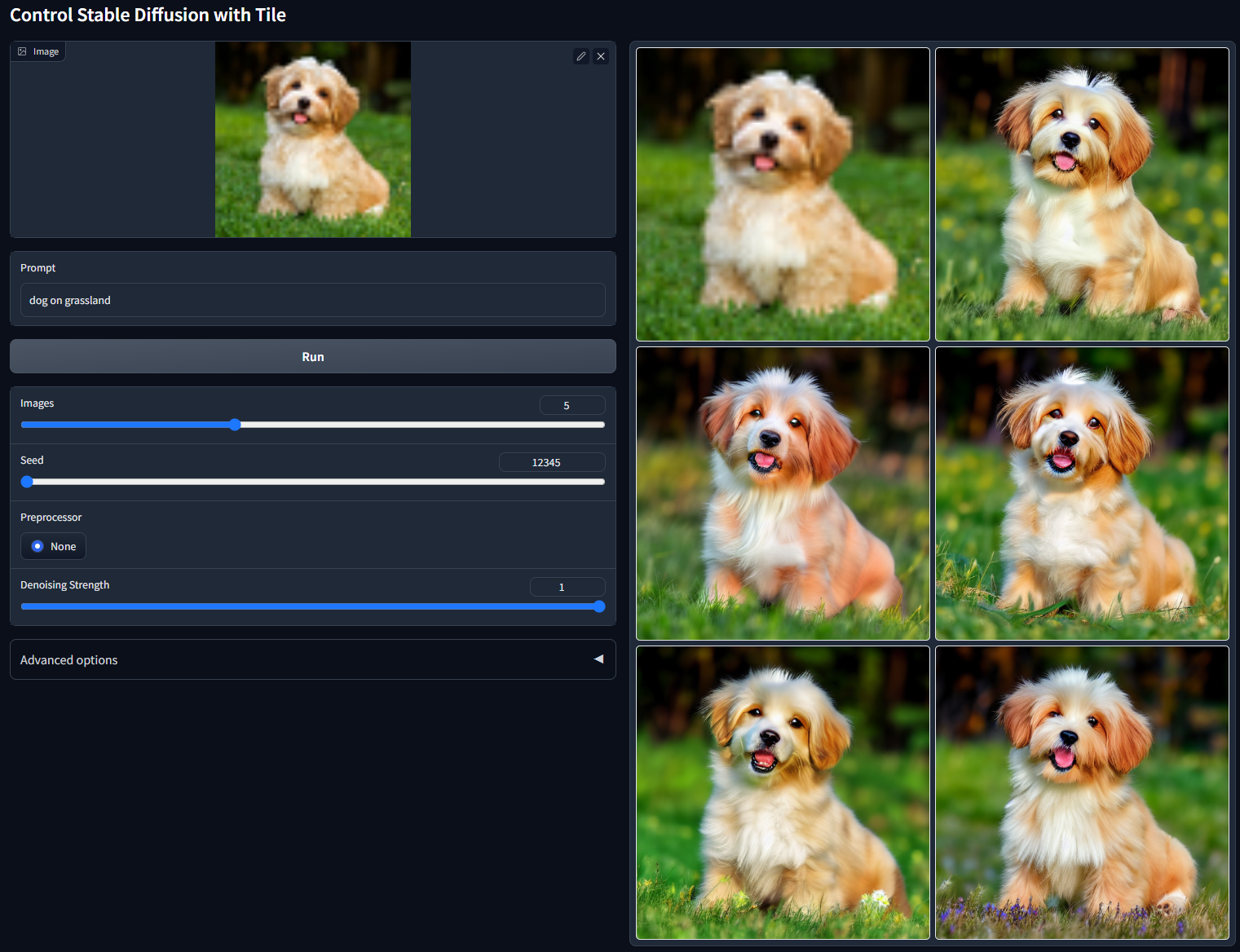
带Tile一般用于修复模糊图像/补充细节。
3. outpainting
在SD绘图中16:9和9:16比例生成的效果图出现多头,解决方法是:
第一步先1:1比例生成,第二步是outpainting功能实现扩展。
preprocessor: inpaint_only+lama
model: control_v11p_sd15_inpaint_fp16 [be8bc0ed]
resize mode: Resize and Fill
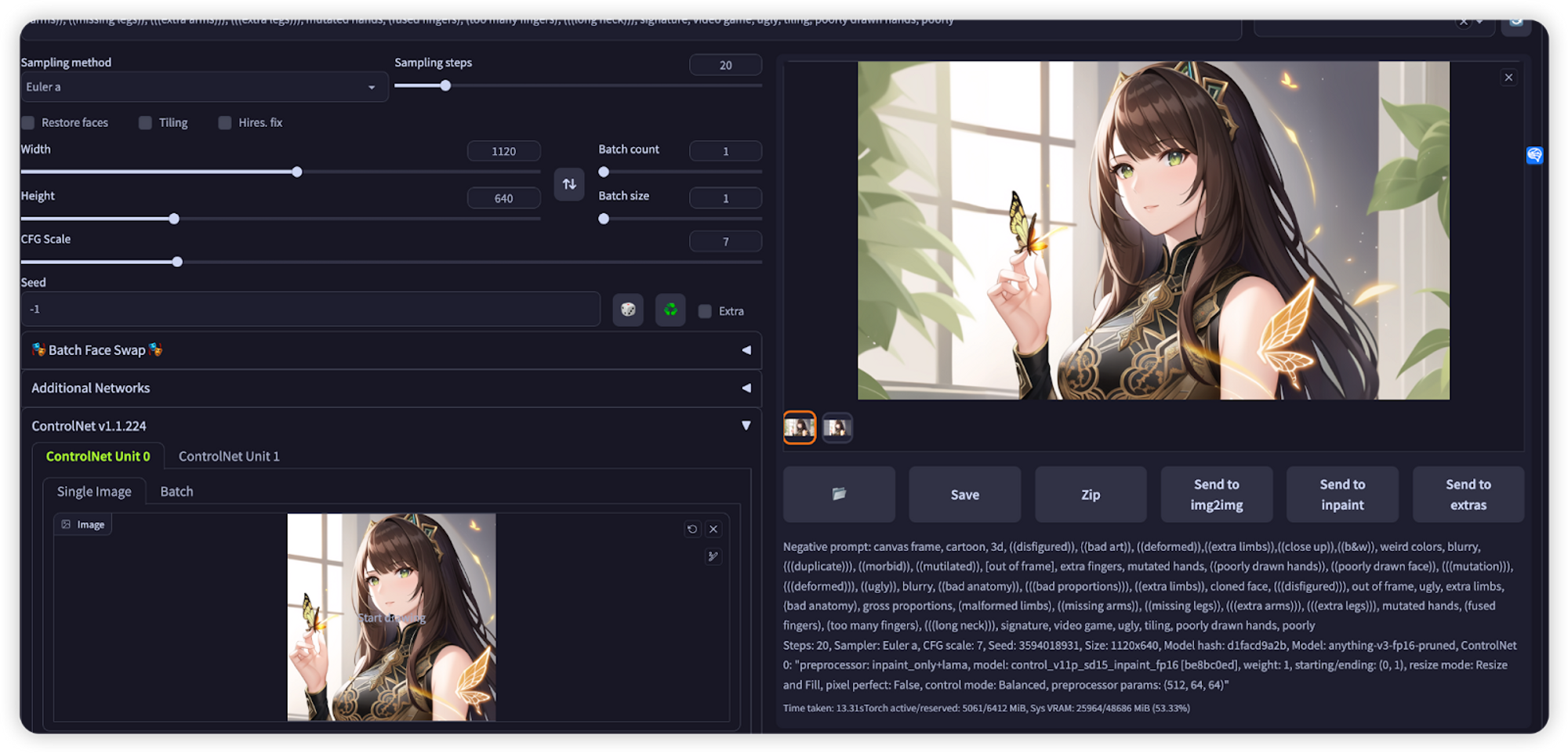
4. inpainting
在controlnet区域放上需要进行局部调整的图片,点击inapint预设,在需要调整的图片上进行涂抹,并在描述区域写上你的预期效果。
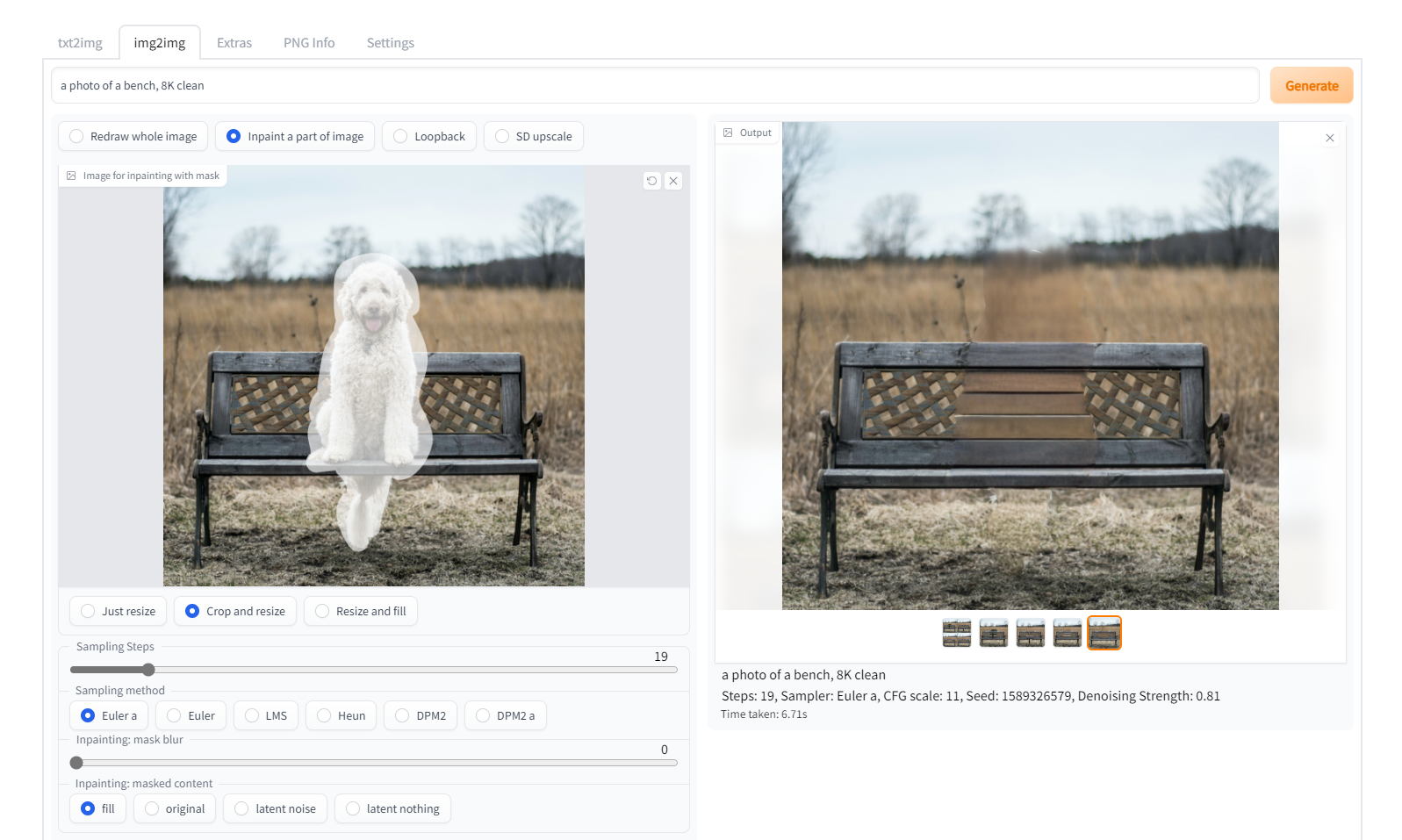

左:有缺陷的原始图像。右:面部和手臂通过修复固定
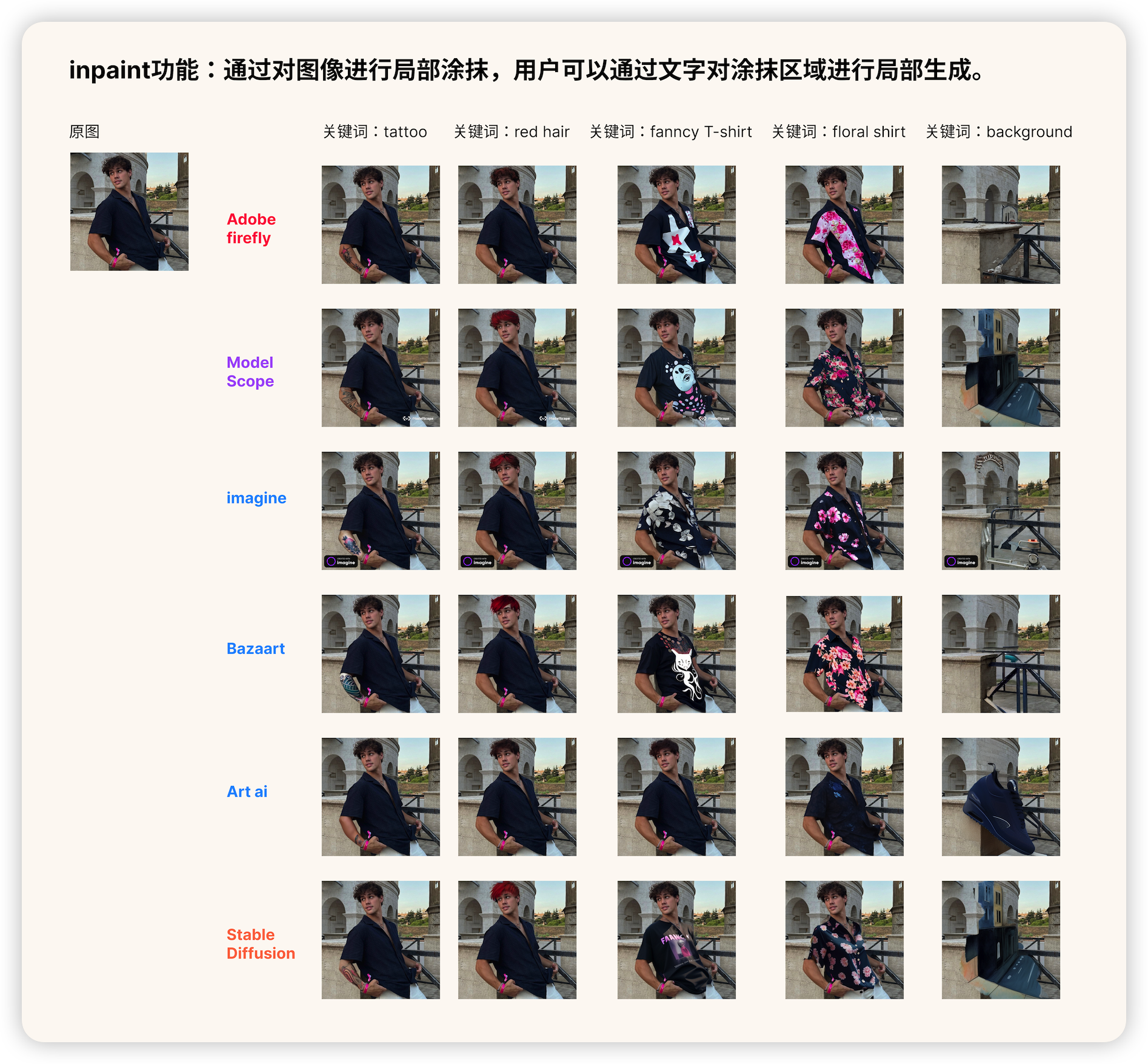
5. 对比了不同产品Inpaint功能
Firefly-Generative fill、Imagine-Inpainting和ModelScope-Inpaint相比,前两者对头发和人物消除的处理更自然。试了一下Stable Diffusion对于衣服替换以及人物消除处理上,文本和图像的实现不理想。
Firefly-Generative fill地址:
https://firefly.adobe.com/generate/inpaint
Imagine-Inpainting地址:
https://play.google.com/store/apps/details?id=com.vyroai.aiart
ModelScope-Inpaint地址:
https://modelscope.cn/models/damo/cv_stable-diffusion-v2_image-inpainting_base/summary
6. Weight(230719)
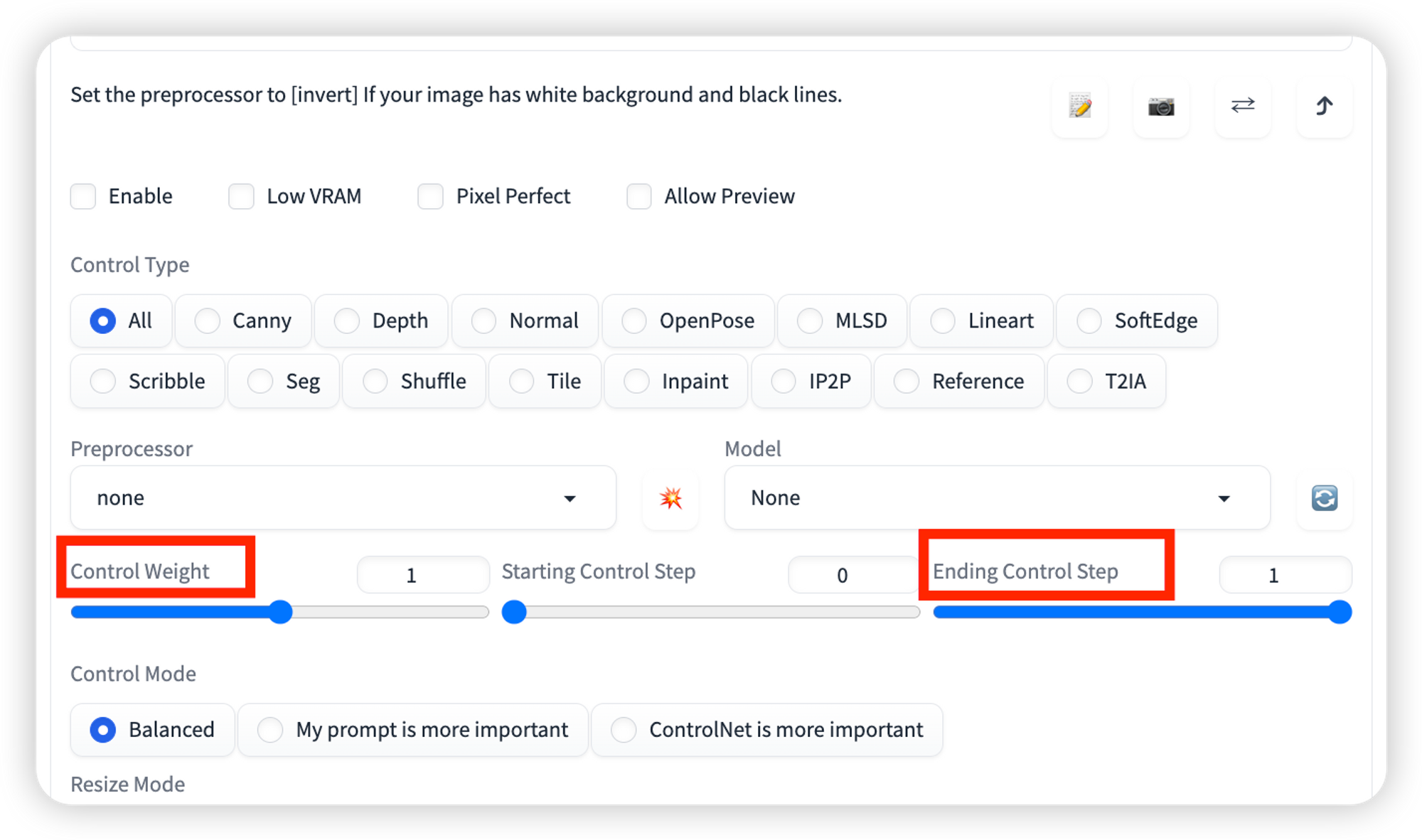
Control Weight:相对于提示给予控制图的强调程度。它类似于提示中的关键字权重,但适用于控制图。对于二维码、文字相关建议数值调整为0.4-0.65。这里数值越大,图案就会越明显,但相对的,文字和图片的融合度也会越差。可以自己多试,比较复杂的文字为了出效果可以调高点,简单的图案可以调低点。
Ending Control Step这个参数建议0.6-0.75,代表着ControlNet什么时候停止介入,**数值越大后面留给模型处理融合的时间就越少,文字融合度就会变差,**数值越小模型介入过早就会破坏已有的结构导致看不清文字。也得多尝试,跟你图案的复杂程度也有关系。
*文字光效或者将二维码合成在衣服上的图最近火遍即刻,看了ControlNet的应用,具体可以见微信公众号。
https://mp.weixin.qq.com/s/rvpU4XhToldoec_bABeXJw
7. Resize Mode
在t2t的controlnet模块/i2i模块,有几个选项可以调整图像大小:
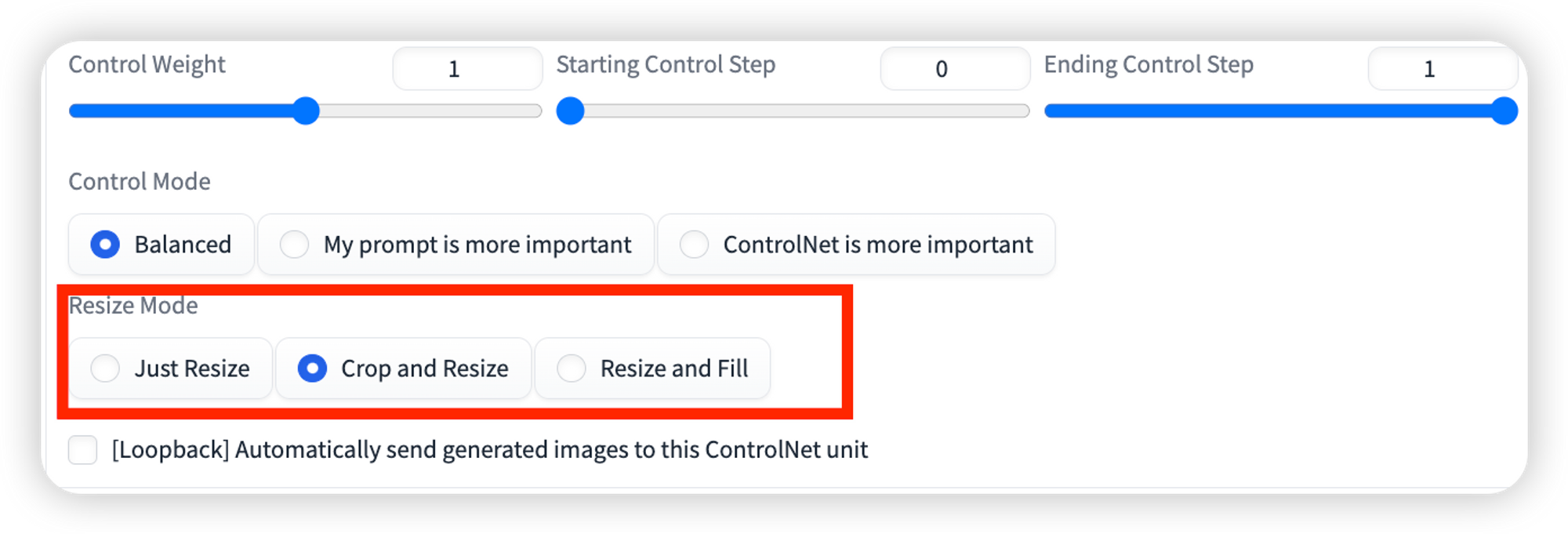
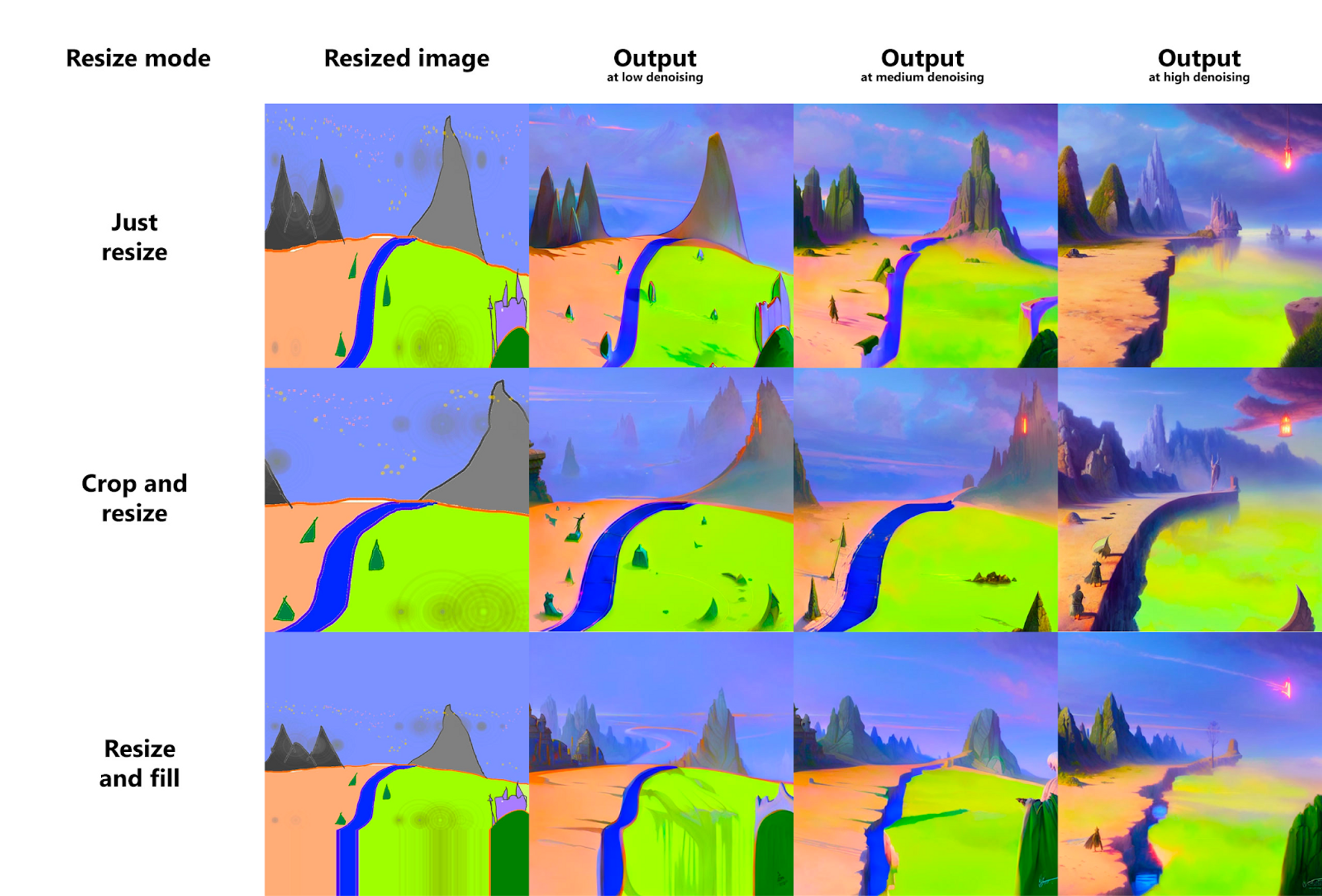
- Just resize 只需调整大小 – 只需将源图像调整为目标分辨率,导致宽高比不正确
- Crop and resize (*常用)裁剪和调整大小 – 调整源图像保留纵横比的大小,以便整个目标分辨率被它占据,并裁剪突出的部分
- Resize and fill 调整大小和填充 – 调整源图像保留纵横比的大小,使其完全适合目标分辨率,并按源图像中的行/列填充空白区域
8. Preview another result
查看预处理结果:
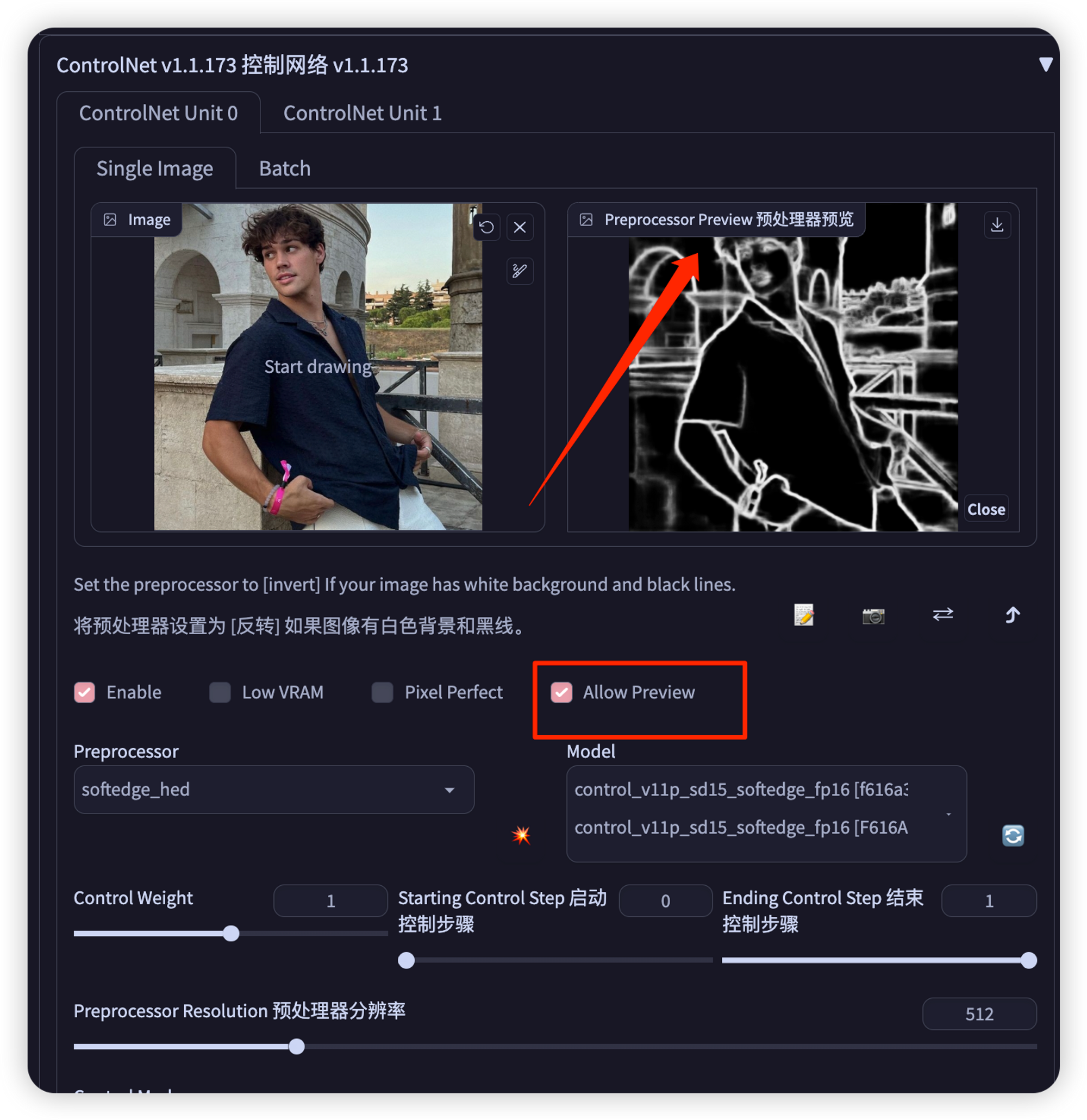
三、script小技巧操作
1. Script-X/Y/Z plot(选择自己想要对比的变量)
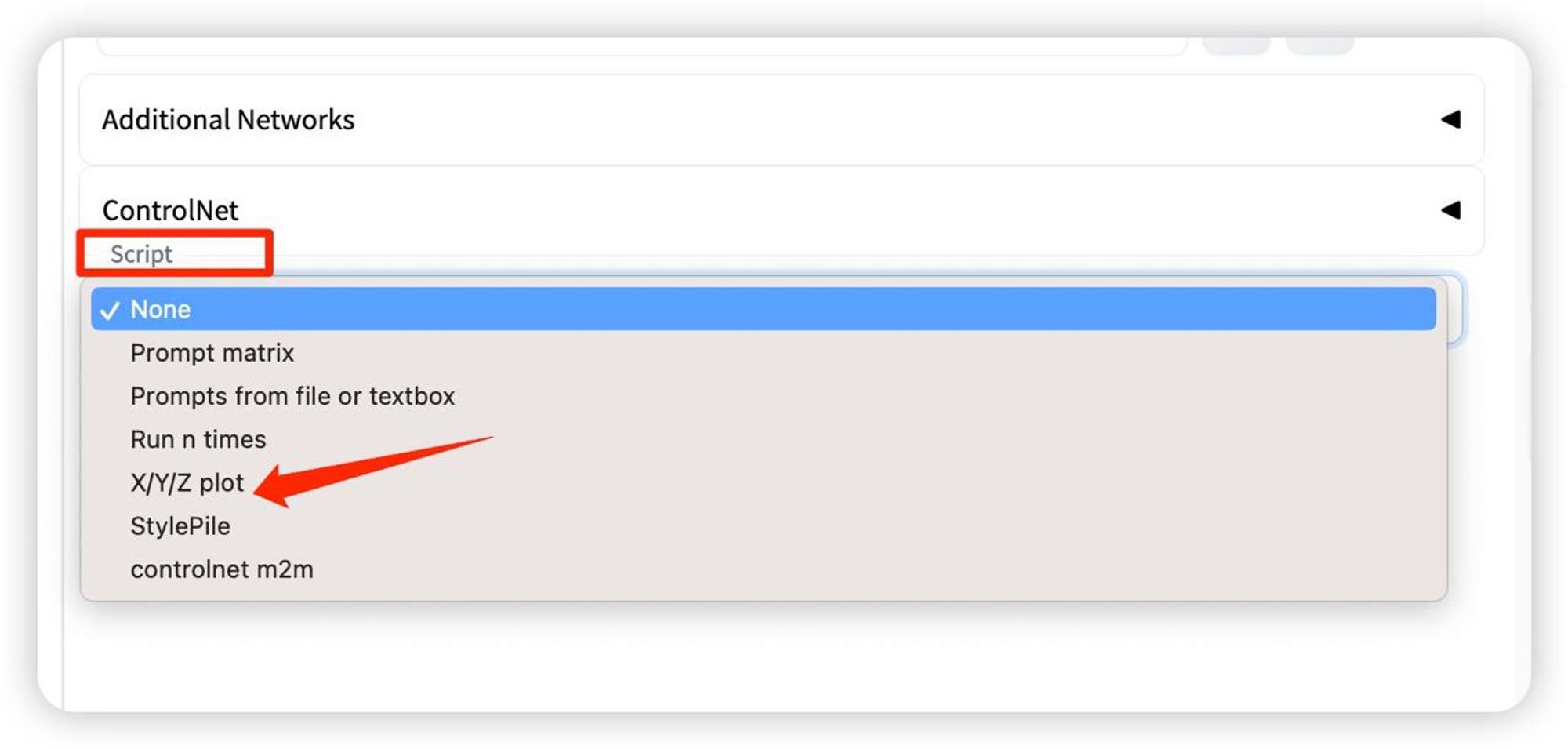
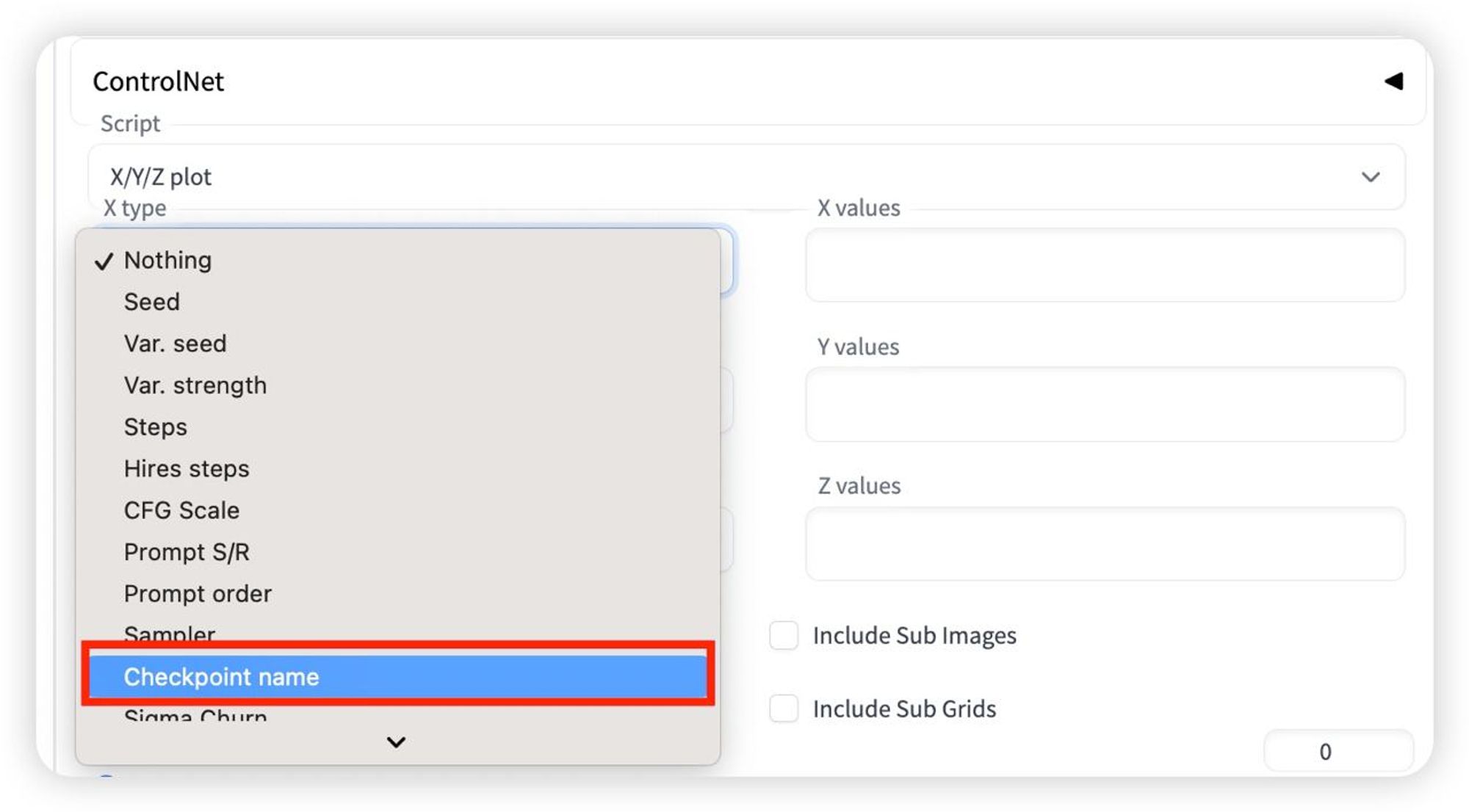
点击checkpoint-再点击右侧黄色书本选择想要对比的大模型
对比lora权重可以选择Prompt S/R(search/replace)比如我要切换不同同个风格的不同lora
eg:1girl, smile, brown hair, hair ornament, upper body, flower, looking back, hair flower, from behind, lips, illustration Tranquil beach waves and palm trees, Margo Selby, knitted tapestry,(sks),masterpiece, best quality, highly detailed, 8k lora:KnittedPattern-000008:0.68
Prompt S/R – 000008,000009,000010,000011
四、通过Chatgpt提高工作效率
可以这么问:
use Deliberate_deliberate_v2 model, create some prompt to make awesome anime style image

五、最后
很喜欢王建硕老师说的「不要把研究AI新闻当成研究AI」,如果有时间可以从最简单的prompt开始学起,真正在业务中去实践,比如效果图光线太暗、背景太花等,这是「需求驱动」的意义,最终需要磨很多次才能有好的呈现。
毕竟AI对不同词语理解能力是不同的,最重要的是好奇心和持续的练习。
原作者: Joma Tech;原文来自视频:A recap of ChatGPT | tech news - by Joma Tech
本文由 @吴恬煊 翻译发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


