
 起点课堂会员权益
起点课堂会员权益项目复盘:如何避开从0~1构建AB Test过程中的坑(下)
编辑导语:在上篇文章中,作者为我们罗列了AB实验中的几个典型问题,并且解答了如何合理的划分人群?如何判断结果是否可信?本篇文章中,作者又讲解了AB的衡量指标以及AA组、AABB组的问题。

接上次的《项目复盘:如何避开从0~1构建AB Test过程中的坑(上)》,这次给大家重点梳理下AA实验。
以前做B端产品时对数据不敏感,现在在C端做产品时,数据分析的能力就显得很重要,你说还有什么能比ABTest的数据支撑你大步向前走的信心呢,当然也没有什么比虚假数据或混淆了数据一样能快速的结束你的产品迭代甚至带来严重后果,所以如何能给自己更多一些信心?
答案是:AA Test
一、AB实验的概念
先再讲下AB实验的概念,在互联网的A/B Test里面, 我们将线上的流量随机地分到版本A和版本B,收集用户在两个版本中的行为数据, 然后对这些数据进行分析,产生量化的结果,最后基于这些量化的结果来形成数据驱动的决策。
下图是一个简单的A/B Test的流程示意图:
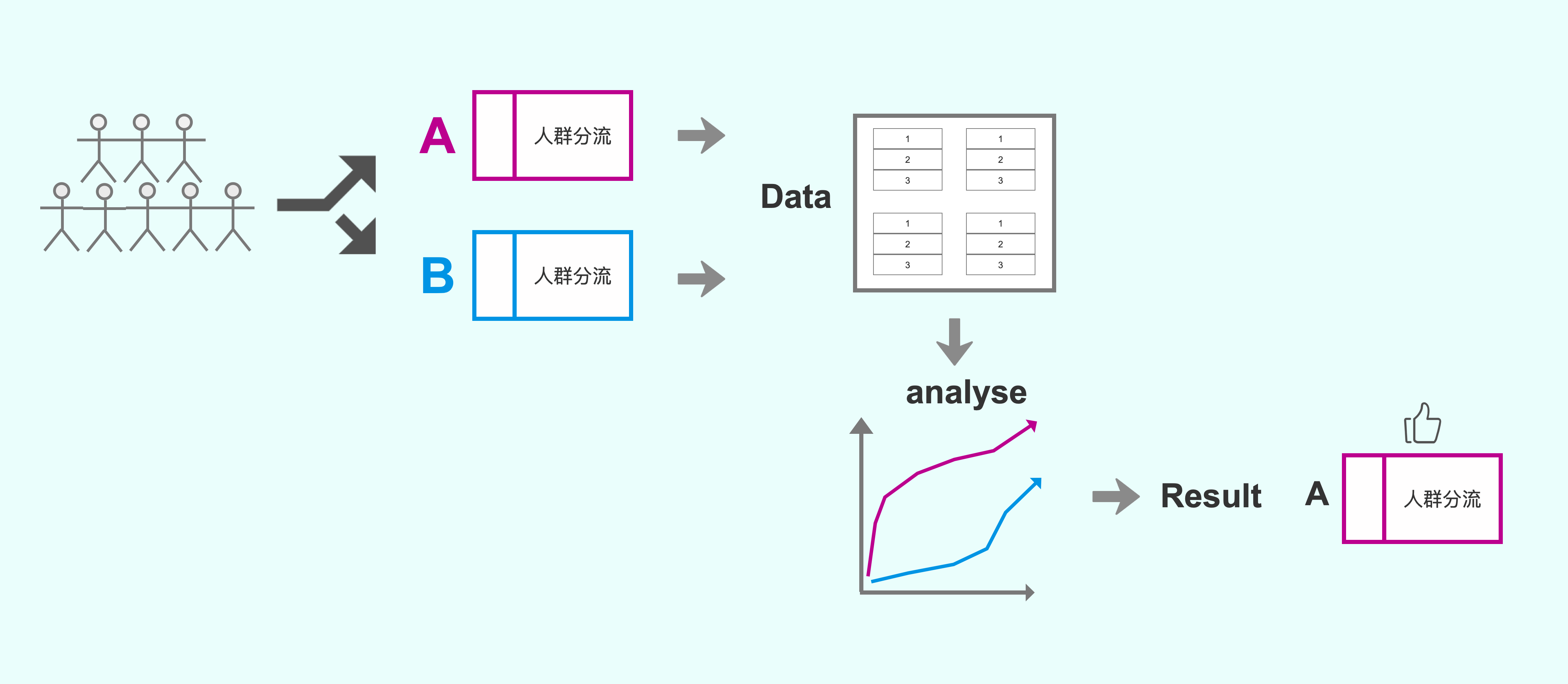
(Axure手绘粗糙版AB核心流程示意图)
实际上,A/B Test方向的大咖Ron Kohavi也说过: “拿到A/B Test的数据容易, 拿到可信的A/B Test的数据很难”,原因就是A/B Test里面的坑很多。
接上次文章,本次主要讲下上次遗漏的最后一个问题,即AA实验以及AABB实验:
- 我怎么划分人群,是随机划分还是依照什么规则能确保人群划分的合理?(AB实验里的分流逻辑);
- 实验结果出来了,我怎么判断这个结果可信不可信(AB实验里的显著性差异);
- 实验结果出来了,实验组数据好,我怎么判断是不是真的好(AB实验里的第一类错误);
- 实验结果出来了,实验组数据差,我怎么判断是不是真的差(AB实验里的第二类错误);
- 实验结果出来了,好多个维度数据,我怎么衡量实验结果(AB实验里的衡量指标);
- 实验结果出来了,但是一组AB实验我总觉得不靠谱(AB实验的AB组,称为AA组以及AABB组)。
二、AA实验的概念
在AA Test里,流量会被随机的分配到两个或多个版本里,只不过这两个版本都是版本A(实验组和对照组配置一模一样),所以你也可以理解为AA Test是AB Test的一种特殊形式。
注意图中的差异,箭头所表示的地方!
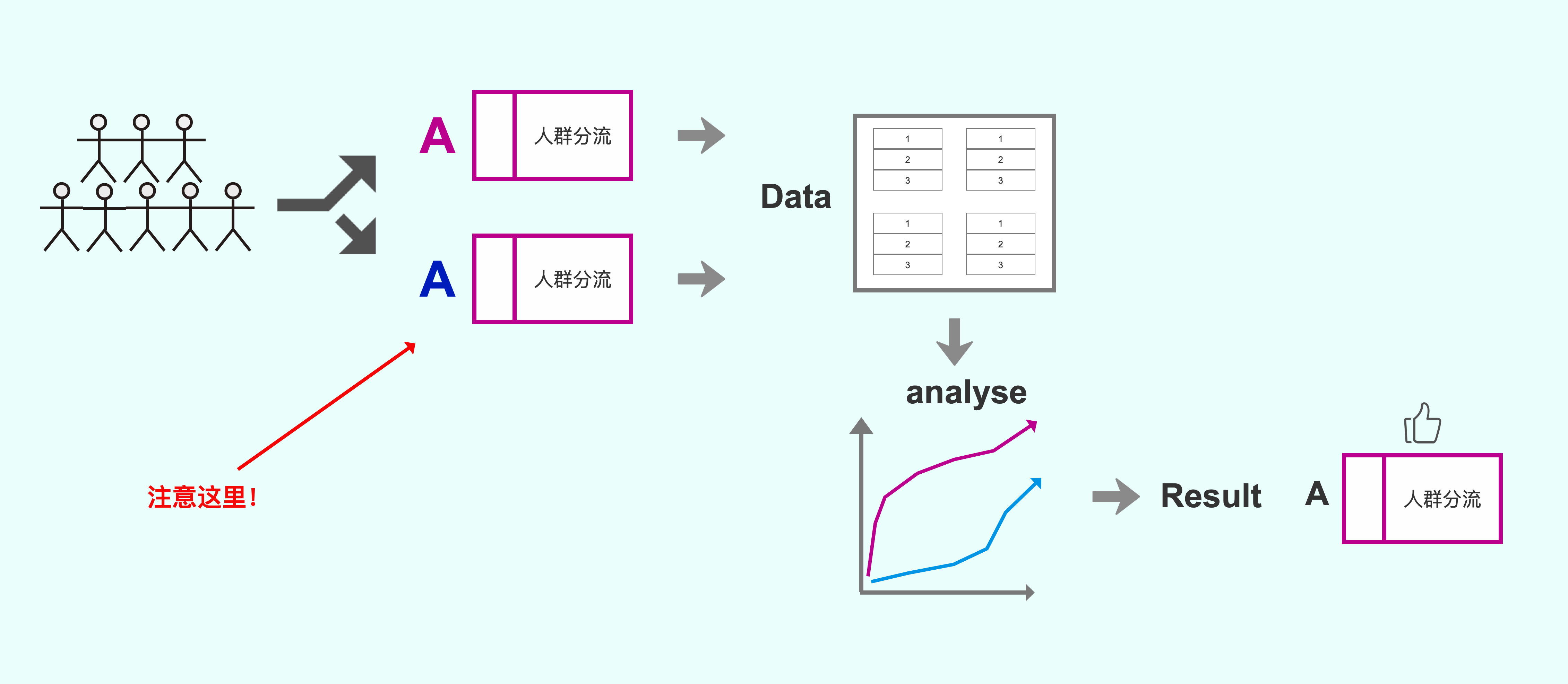
(箭头所示为AA实验区别于AB实验的地方示意图)
在AA实验里,从概念上我们知道实验版本之间是没有差异的(类比下,在AB实验里我们是不知道实验版本之间的指标是否有差异的)。
所以在AA实验中我们是可以排除实验版本之间的差异带来的影响的,可以把这部分影响归结为随机噪声或其他干扰因素(类比下,在AB实验里我们是没有很强有力的版本区分开实验版本间的差异和其他可能带来干扰的因素的),一般用来辅助观察指标在产品不做改变时的偏差范围。
AA实验是实验组和对照组配置一样,衡量产品不做改变时的自然偏差范围,如果这个偏差范围很大,说明AB实验的结果可能也不是很可信。
先回到AB实验的逻辑:
在概率和统计学上我们是可以判断出版本之间指标的差异可以归因为A版本和B版本的差异(注意实际实验里的概率大小),不过在实际实验中,我们会遇到多种问题,甚至可能导致结论是错误的,一般情况下问题可以归结为三点:
- 流量分配有问题(不均匀/特质不明显等等)
- 埋点和数据回流有问题(埋点漏埋、少埋、多埋等或数据传参链路bug)
- 统计计算和推理不科学(计算错误或推理逻辑未遵循AB实验逻辑推理)
而AATest实验中的产品版本都是一样的,这样保证相同的目的就是为了验证上述的埋点、分流、实验统计的正确性,确保实验的可信。
换句话说,如果实验的流量分配、埋点数据、统计分析都是正确的,那么AA空转的结果理论上肯定是一样的,这样就可以理解,如果AA空转的实验结果不同,那么上述三个里肯定有一项存在问题。
所以可以看出,在AB实验里,做一个纯净对照组AATest的重要性。
三、AA实验怎么做
AB实验的步骤大家参考上篇文章《项目复盘:如何避开从0~1构建AB Test过程中的坑(上)》应该都知道怎么操作了吧?
AA实验就是把AB的步骤复制一下,只不过在操作版本时保证一致就可以了。
四、AABB实验是啥
说实话,如果已经做了AB实验和AA实验,没有必要做AABB实验了。
AB和AA实验的误差把控都需要用概率和统计把控,如果AB和AA的结果不相信,你有什么理由相信一个误差更大的AABB实验呢?也就是一个4开组的实验。
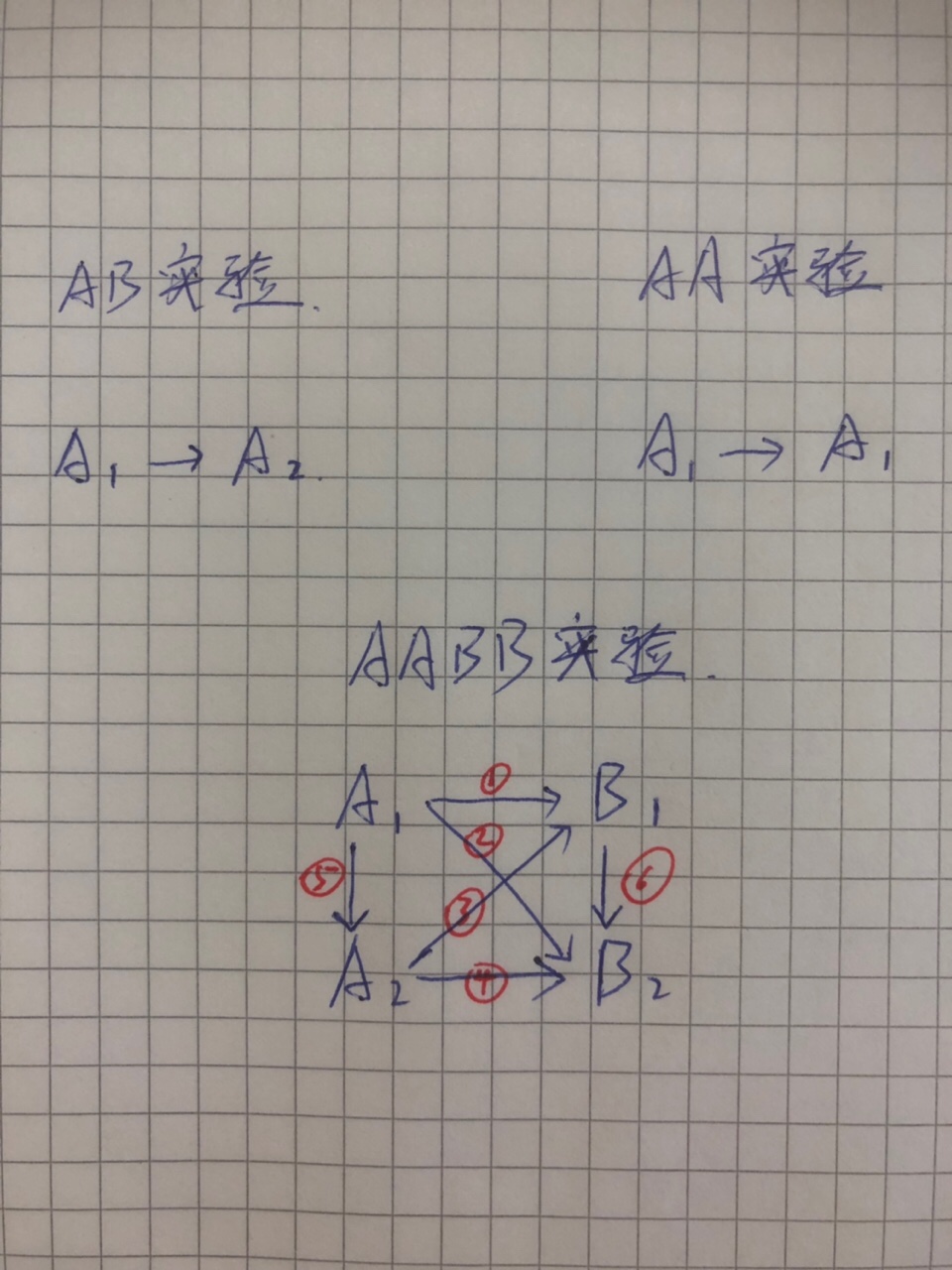
(手绘AABB实验示意图,原谅我的拙笔,起码不侵权 哈哈……)
所以由上图可以看出,原本的单独实验单一对比情况下存在的单一误差,如果做4开的AABB实验,变成了6组,假设各组对比结果相互独立,至少一组犯错的概率为:P(wrong)= [ 1 -(1-0.05)^6 ] =0.265,远大于0.05(传说中的P值)。
所以多来几次抽样实验的话,只能增加犯错的概率,因此不是很建议在来一个4开的AABB实验。
五、结语
AATest实验成功的是ABTest成功运行的前提。
根据大部分AB实验的经验, A/A Test经常发现的问题是数据方面的问题, 工程方面比如分流的问题比较少见,因为目前很多分流算法都已经相对成熟。
此外实验系统,埋点和数据回流,以及指标计算都是动态变化的,因此A/A Test应该持续的运行,所以建议有需要AB实验的小伙伴,可以考虑将AA实验作为长期运行、对比的一项任务,任重而道远。
作者:楠神,公众号《音波楠神》
本文由 @楠神 原创发布于人人都是产品经理,未经作者许可,禁止转载
题图来自 Unsplash,基于 CC0 协议










写得特别棒,对AA实验有深一步的了解,感谢作者,这里有个问题请教下:
方案1:先跑AA`实验验证AA`无显著差异后,再跑AB实验
方案2:直接跑AA`B实验3开进行,即观察AA`显著性,也观察AB的显著性
方案1和方案2,建议跑哪一套呢,其中有何区别? 期待您的回复,谢谢
你好,感谢认可。
一般为了避免流量浪费,同时真正推进项目时会遇到时间紧迫性,所以一般会直接跑AB,来看P值或power值,毕竟如果这俩个值分别是很小和百分比很大,大概率AB实验结果就是靠谱的,这个时候极小概率会出现偏差;只有当P值和power值的结果不足以支撑你去决策AB实验结果是否可信时,且要分辨出结果是否是受到自然波动的影响时,加一个AA空转实验去佐证。
当然,严谨且全面的AB实验,是可以一并投入开始跑的。