
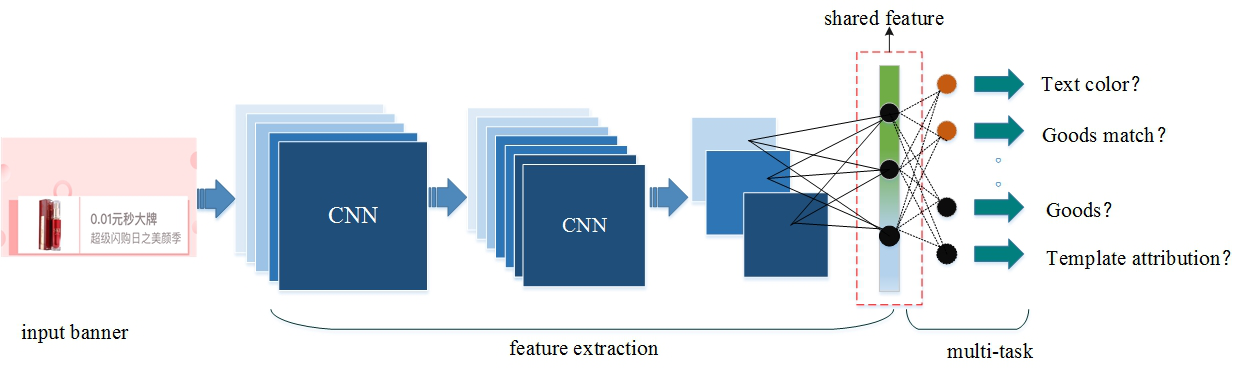
 起点课堂会员权益
起点课堂会员权益几个应届毕业生,如何实现阿里鹿班?

引用黄渤在接受采访时说的一句话:这个时代不会阻止你自己闪耀,但你也覆盖不了任何人的光辉。
一、一张海报的“痛”
1. 大量的需求,繁重的设计工作,设计师叫苦不迭
熟悉电商行业的朋友应该知道,无论是PC端还是移动端,电商网站中充满了各类活动信息,促销期间这样的情况更甚。
618期间,千变banner在苏宁易购客户端顶部广告区首次亮相,超过4000万张的算法合成banner得到曝光,以1个设计师30分钟设计一张banner图的速度计算,就算是100个设计师24小时不眠不休,也需要持续干超过22年!
2. 资源位有限,流量被头部玩家鲸吞,中小商户发展受限
以苏宁易购移动端顶部Banner区为例:共计8张的资源位面对亿万级的用户,实在显得力不从心。
以千人一面(即每个用户看到的内容一致)的逻辑进行展示,实际上也是对用户的粗暴运营,对流量资源的浪费。全面推广千人千面,保证每个用户享受定制级别的活动展示,无疑是打破僵局的关键。
无论对用户还是商户,这是个双赢的局面,因为是个性化推荐,中小商户也得到了更多曝光机会。
3. 部分商户设计资源不足,期待一键生成海报创意的工具
企业经营需要考量成本,一些小型商户往往受制于成本问题,设计资源跟不上业务发展的需求。傻瓜式生成海报创意的工具成为这类用户的最大诉求,简单输入利益点文案和主推商品,一键产出结果,直接下载或简单微调便能投放。
4. 组建“千变”项目团队,开干!
随着人工智能领域的发展和图像算法的生产阶段研究,AI海报设计不是天方夜谭。在组建团队中,可以说是机缘巧合,6个应届毕业生扛起了大旗。
整个项目团队包括产品经理1人、视觉设计师1人、前端开发1人、服务端开发2人、图像算法1人,无一例外,全部是刚加入苏宁未满1年的应届毕业生。这样的项目对团队来说,既是机会也是挑战。
底层商品图数据处理,机器生成图片的美观度,算法打分模型的建立都成为团队不得不攻克的难题。
二、让机器先学会模仿
我们将一张banner海报拆分成两类关键信息:图像信息与内容信息。
为保证图像信息多变,我们沿用设计师手工绘制一张banner的流程,将图像进行了图层拆分,并通过不同图层间的组合来实现素材的复用和高度可变性。
其中,图像信息包含:背景层、背景装饰层、蒙层、商品装饰层;内容信息包含:商品主图、利益点标题、logo、行动词。

1. 引入尺寸、模板概念
尺寸概念很好理解,每张banner图都有其固定的尺寸,以下列举苏宁易购线上常用的尺寸,这也是千变系统一期上线后的主要服务对象。
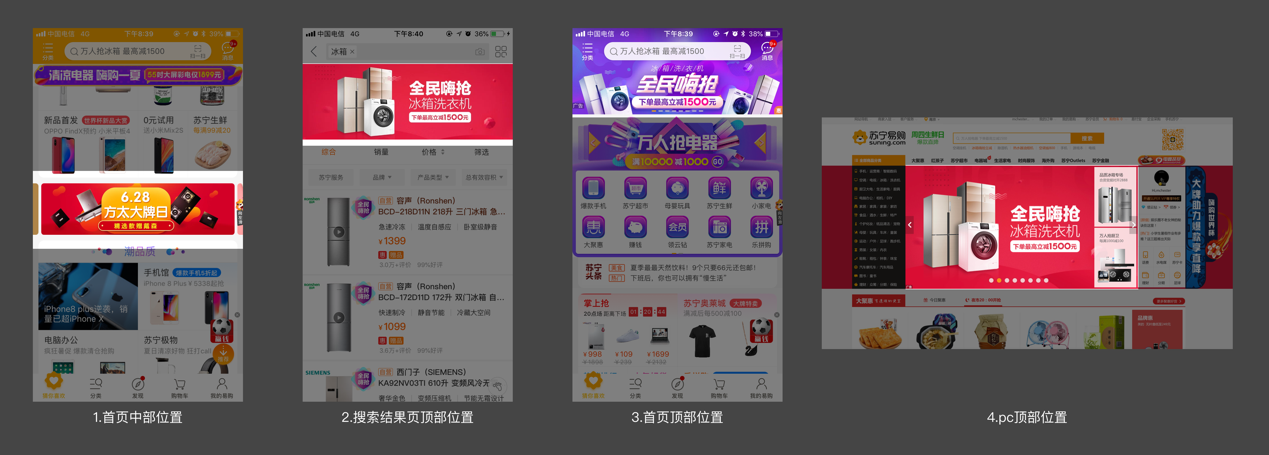
为保证每个内容信息元素出现在合适的位置,我们引入了一个关键概念:模板。
在模板中,我们规定了诸如商品图主体的尺寸大小及坐标位置,通过强规则的干预保证最终的banner图在线上应用中不会出现错位的问题。

至此,我们已经完成了内容信息元素嵌入图像信息的工作。简单来说,banner图合成的流程是通畅的。基于线上实际场景的应用,往往banner要配合节日氛围造势,恰当的风格成为吸引点击的重要组成因素。
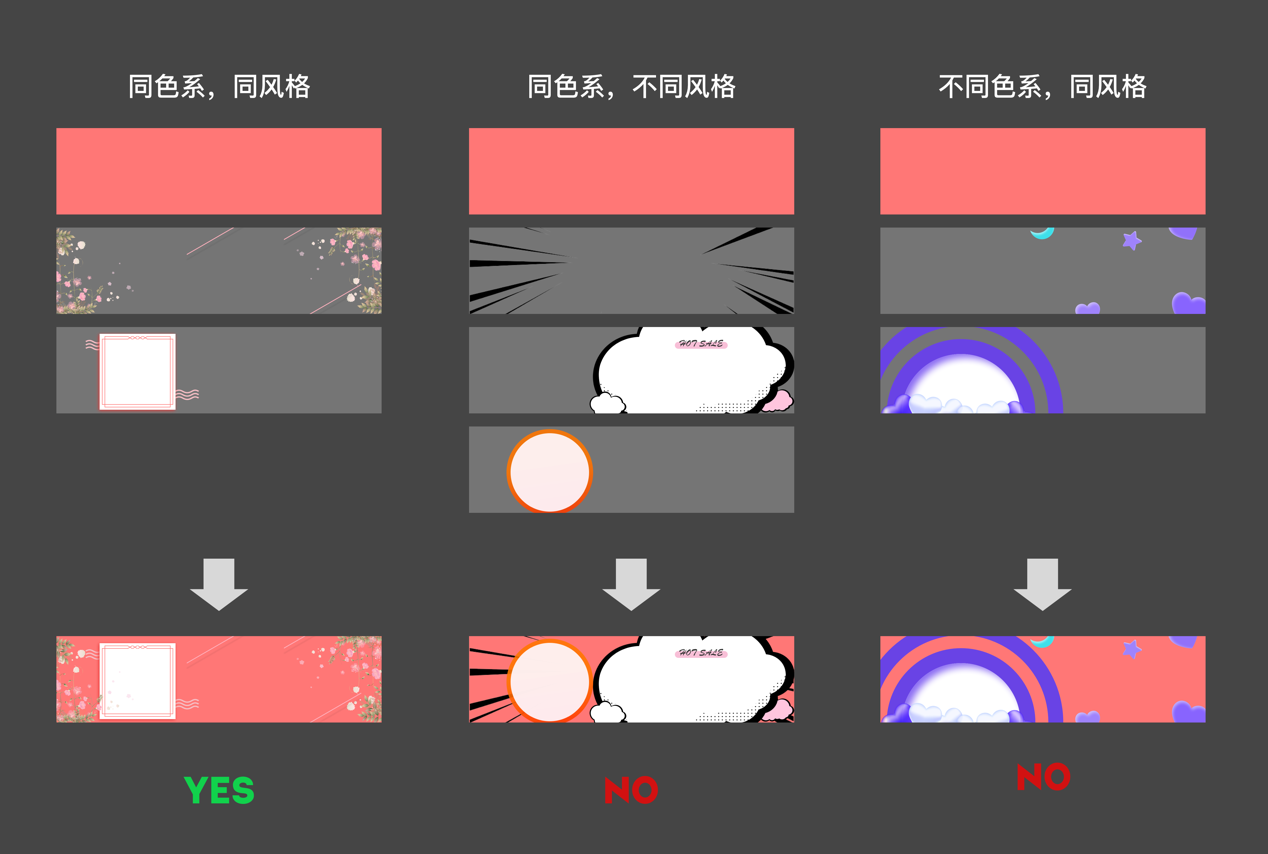
2. 建立风格库,配合促销氛围
风格库是“千变”系统中,保障banner视觉氛围协调的重要功能。
苏宁易购是全品类的电商平台,不同品类的商品适合用不同颜色和风格的皮肤来展示,且苏宁易购全年有多次大促和品牌日,为了皮肤能够适配首页的大促氛围,因此需要风格库来支撑。

其次,风格库对皮肤的合成也起到决定性作用,同一风格库内同一个色系下的皮肤合成后的效果较好,风格和色系都会对合成的皮肤数据产生影响。
三、算法理解人类审美
图像图层间基于强规则的融合解决了线上应用的美观性问题,可实际上机器并未吸收海量数据来进行自我调节。设计师的规则输入始终是有限的,没人能穷举BadCase的集合。如何让机器持续不断地吸收最新审美要求并转换为优质banner图,成为困扰团队的难题。
基于线上banner图CTR数据分析,我们提出了一个概念:算法不用理解如何创造美,只需复刻用户审美。
当用户基数够大,群体的点击欲望表达了banner图的吸引力。我们通过用户点击行为、购买行为记录优质banner图的特征值,并将此特征值应用到更新的banner图中,通过A/B测试的思路灰度投放验证数据表现。如此循环,不断更新规则库中的特征值信息,实际上,将用户喜好反哺图像算法,是保持算法优化闭环的重要一步。

四、图像算法攻克的难题
1. 基于深度学习的智能抠图算法
为了实现对推荐商品图的精细化分割,苏宁图像标注团队对商品图像进行了大量的像素级别的标注,并构建基于深度学习的深度卷积神经网络结构,进行训练来建立商品图的分割算法模型,同时对分割结果进行优化,提高分割商品图质量。
(1)采用Dilated Convolution空洞卷积
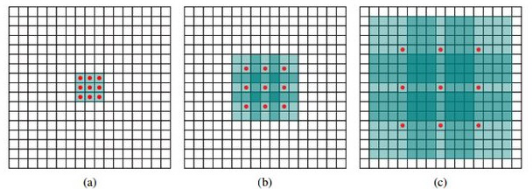
传统的CNN网络结构中大多采用pooling池化来达到降维的目的,这就会导致经过池化后的特征层上像素尺寸比较低,即使通过上采样的操作,例如:FCN就是先进行pooling减小图像尺寸,再进行upsampling扩大原图像尺寸,这样不断重复减小扩大的过程就导致了featuremap上精度的损失。
因此我们构建的分割网络中采用空洞卷积的做法是:去掉池化层,同时在卷积操作后进行如图所示的操作,从而可以扩大感受野,再对提取到的featuremap操作来实现更加精确的商品图像分割。
(2)全连接条件随机场精修商品图边缘
在分割网络的前端运用的深度卷积神经网络,该网络可以很好的预测是否有商品,以及商品在图像中的大致位置区域,但并不能准确的定位到商品图像的边界,同样会导致分割的边缘不精细。
故在我们分割网络的后端加入了全连接的条件随机场(conditional random field,CRF)对神经网络预测的结果进行优化。CRF模型中将图像中每个像素点所属的类别表示成一个变量,然后再考虑任意两个变量之间的联系。
对应的能量函数为:
![]()
其中,是一元项,表示像素对应的语义类别,二元项就是描述像素点与像素点之间的关系,基于两个像素点的实际距离和颜色信息来判断,越相似的像素得到相同的标签,所以这样CRF能够使图片尽量在边界处分割,最后通过不断的优化该能量函数达到理想的分割效果。
(3)分割图像抗锯齿
即使利用“像素级”的分割方法能够很好的将商品主图抠出来,但同时带来的副作用就是在商品图的边缘存在锯齿,严重影响banner的展示效果。故在分割网络之后,我们又加入了抗锯齿的算法。
提取分割后商品图像的alpha通道,获取图像边缘,并按照边缘锯齿的形状,分成16种pattern如下图所示:
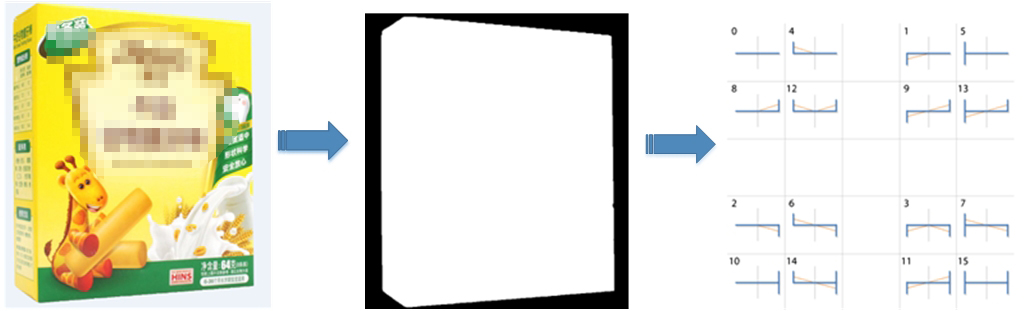
根据不同的锯齿模式重新计算边缘区域的像素值,如下右图所示,图像边缘过渡就显得十分平滑,从而达到消除锯齿的目的。

2. 基于多任务学习的图像评估模型
(1)多任务学习
在建立评估模型的初期,我们也尝试了多种方案,例如:建立一个学习任务的评估网络,仅针对商品图与底版匹配是否合理的。实际的训练过程中,我们发现这一个单任务的网络很快就收敛,且测试也出现过拟合。
后期调整训练的网络结构增加卷积层层数,问题仍未得到改善,故考虑到单任务学习的局限性,尝试从多任务学习角度来建立banner评估模型。
多任务学习可以学到多个任务的共享表示,这个共享表示具有较强的抽象能力,能够适应多个不同但相关的目标,通常可以使主任务获得更好的泛化能力。
在banner评估的维度上,并没有主次任务之分,每一个任务相对于其他任务来说都可以看成是一个主任务。多个相关任务放在一起学习,有相关的部分,但也有不相关的部分。当学习一个任务时,与该任务不相关的部分,在学习过程中相当于是噪声,可以提高学习的泛化效果。
(2)banner评估网络的结构简介
参考inception v3网络结构的设计思路,我们在网络中特征提取阶段中利用两个一维的1×3和3×1的卷积核,取代3×3的卷积核。这样网络层数进一步加深,同时一个卷积核拆分成两个卷积核,可以增加网络的非线性。
网络中加入Batch Normalization层,BN 是一种非常有效的正则化方法,能够有效的加快网络训练速度,同时收敛后的分类准确率也可以得到大幅提高。BN 在用于神经网络某层时,会对每一个 mini-batch 数据的内部进行标准化(normalization)处理,使输出规范化到 N(0,1) 的正态分布。
在模型的训练过程中,我们增加学习率以适用BN规范化后的数据,去除Dropout并减小L2正则(BN已经起到正则化的作用)。
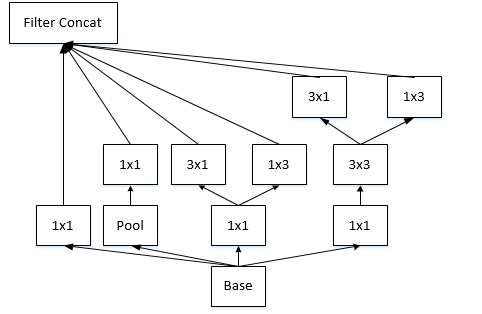
评估网络的损失函数采用SoftMaxWithLoss,同时对应的网络中增加Slice layer,将input的label标签进行拆分,从而实现对banner中每一个评分项进行评估输出。
五、自动着色的探索
虽然基于强规则,已经解决了图像图层间的融合问题,但由于图层其实是一张张手绘的,并不是真正意义上的算法创作。所以我们就想利用设计师的手稿进行自动上色,来真正的做到“千人千面”、“千物千面”。



从上图两组初步的自动上色结果可以看到,整体来看智能上色这个方案还是可行的。但是在一些细节装饰的边缘部分还没能到达高分辨率的要求。同时,在一些浅层的纹理层,算法的上色效果不是特别明显,智能着色的方案探索将成为千变项目团队下一个重要研究课题。
六、服务端的实现逻辑
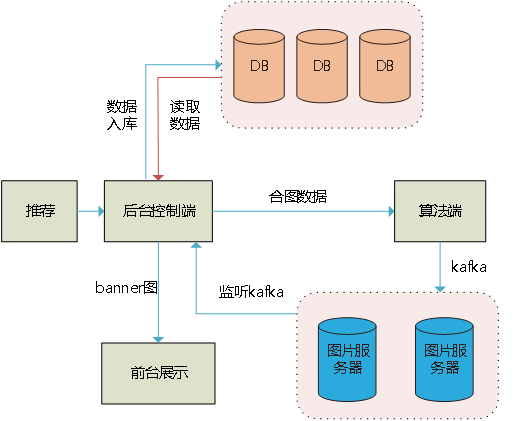
1. 千变系统的分工与协作
合成banner图的工作由算法侧负责,而千变后台负责管理合成这些banner图片所需要的材料数据。千变服务端一则为设计师提供操作页面,可以上传模板,风格等信息。
二则从苏宁推荐系统获取相关信息,根据会员编码,可以获取到该会员用户的偏好商品。在合成banner图片的过程中,将合成信息传递给算法端,由算法端负责完成合成。千变后台通过http与算法端建立连接,并完成数据的传输。
2. 系统间的数据传输
同一组元素,在算法端也会生成不同的banner图片,千变采用的方案是算法将合成的多张banner图存储到苏宁图片服务器,而后台管理系统从图片服务器上获取相应的banner图。
这中间与图片服务器的交互,我们所采用的方法是通过中间件kafka完成,算法作为服务方向图片服务器存储合成的banner图,而后台通过kafka监听异步获取图片服务器上的banner图。算法端在合成时即回传执行信息到后台管理系统,此时后台即可处理其他相关事宜,不再等待合成图片完成从而消耗时间资源。
在获取到图片后,即可传递给前台展示系统,从而完成整个banner图片的生成、管理和展示的工作。
整个过程的流程架构设计如下图所示:采用此异步处理的方式,我们在海量数据处理的同时,实现了banner图片的离线合成与在线更新。在离线时,即可生成多种banner图片存储到图片服务器,而在在线展示的过程中实时根据需求更新展示图片。
3. 高并发问题解决方案
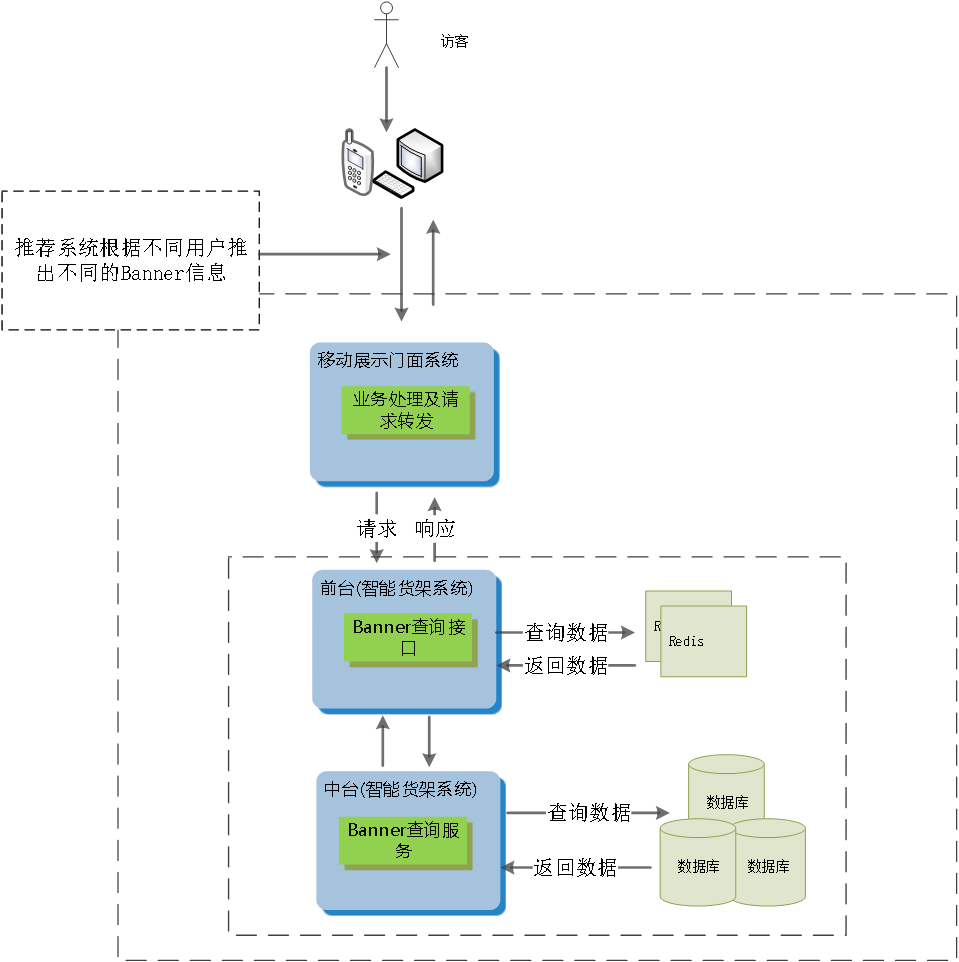
那么我们是怎么解决高并发的用户请求呢?
当用户访问是,首先会通过我们的移动展示门面系统,整理从推荐获取到的用户相关信息,再利用NGINX快速处理高并发的特性,分发子请求到智能货架系统去获取Banner图,同时用到REDIS缓存技术,以缩短响应时间。
采用这样的设计流程,可以快速(响应时间毫秒级)、准确(返回的是用户最近浏览或用户偏好相关)地给用户展示出多种多样的Banner图。
整体流程架构图如下图:
七、我们的初心:千变之路
未来产品架构图:

AI设计平台的出现是早已积攒的痛点在人工智能时代的必然产物,解放设计师人力,提高流量价值的挖掘深度,人工智能使得我们的时间得以投入到更加具有创造性的工作当中去。
AI设计平台不是要取代设计师,而是让设计师的工作变得更加纯粹,更加回归“设计”本身。千变项目组致力于打造极致的AI设计体验,将AI设计的便利带到集团八大产业、开放至商户、品牌商及万千达人用户!
文末彩蛋
送上苏宁千变系统实景录制视频~(请忽略背景中pk需求的画外音QAQ)
传送门:https://v.qq.com/x/page/j07349177ds.html?ptag=2_6.2.2.17134_copy
欢迎各行交流!
本文由 @Jade 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Pexels,基于 CC0 协议









请问可以将您的文章转载到Great-PM公众号上吗? 😉
可以,记得标注作者来源。可以加我vx详谈
阿里鹿班,苏宁做出来的?
苏宁的AI智能设计平台叫千变
这个工具对外开放吗 🙄
努力中,期待和大家的见面!
恐怖的科技力量啊
感谢支持~