
 起点课堂会员权益
起点课堂会员权益语音交互:从语音唤醒(KWS)聊起
编辑导语:随着手机的逐渐智能化,越来越多的手机只要听到指令就会帮助主人完成一些任务,这就是语音唤醒功能。本文作者围绕语音唤醒功能,从其应用有哪些、工作原理是什么、怎样训练一个唤醒模型、如何测试等方面展开了详细地讨论。

“Hi siri”、“天猫精灵”、“小爱同学”,我们生活中常常会叫到这些名字,让她们来帮我们完成一些指令,这个过程就像叫某人帮你做某事的感觉。
而这个叫名字的过程,就是我们今天要聊的语音唤醒。
一、什么是语音唤醒
语音交互前,设备需要先被唤醒,从休眠状态进入工作状态,才能正常的处理用户的指令。
把设备从休眠状态叫醒到工作状态就叫唤醒,我们常见的有触摸唤醒(锁屏键),定时唤醒(闹钟),被动唤醒(电话)等,而语音唤醒就是——通过语音的方式将设备从休眠状态切换到工作状态。
语音唤醒(keyword spotting):在连续语流中实时检测出说话人特定片段。
可能有长得好看的同学就要问了,我让他一直保持工作状态不可以吗?
工作状态的设备会一直处理自己收到的音频信息,把不是和自己说话的声音也当作有效信息处理,就会导致乱搭话的情况。而语音唤醒就成功的避开了这个问题,在只有用户叫名字的时候工作,其他时间休眠。
其实到底是否需要语音唤醒这个能力,也是看场景的,有些廉价的玩具,就是通过按住按钮进行语音交互的。
二、语音唤醒的应用有哪些
语音唤醒目前的应用范围比较窄,主要是应用在语音交互的设备上面,用来解决不方便触摸,但是又需要交互的场景。
生活中应用的最好,就应该是智能音箱了,每个品牌的智能音箱都有自己的名字,我们通过音箱的名字唤醒她,和她进行交互,控制家电。
其次就是手机,目前大部分手机都配有手机助手,从苹果最早的siri到现在的“小爱同学”,让我们实现了即使不触碰手机,也可以实现一些操作。
还有一些服务类型的机器人,也会用到语音唤醒。
不过一般机器人会采用多模态的唤醒能力,他会结合语音唤醒、人脸唤醒、触摸唤醒、人体唤醒等多个维度的信息,在合适的时候进入工作状态。

三、语音唤醒的工作原理是什么
语音唤醒能力主要依赖于语音唤醒模型(下称“唤醒模型”),是整个语音唤醒核心。
唤醒模型主要负责在听到唤醒词后马上切换为工作状态,所以必须要实时监测,才能做到听到后及时反馈。由于需要实时响应,以及唤醒模型对算力要求不高等方面原因,一般唤醒模型是做在本地的(区别于云端的ASR识别)。
这就是我们即使没有联网,你叫“小爱同学”,她也会答应你的原因。
唤醒模型的算法经过了三个阶段的发展:
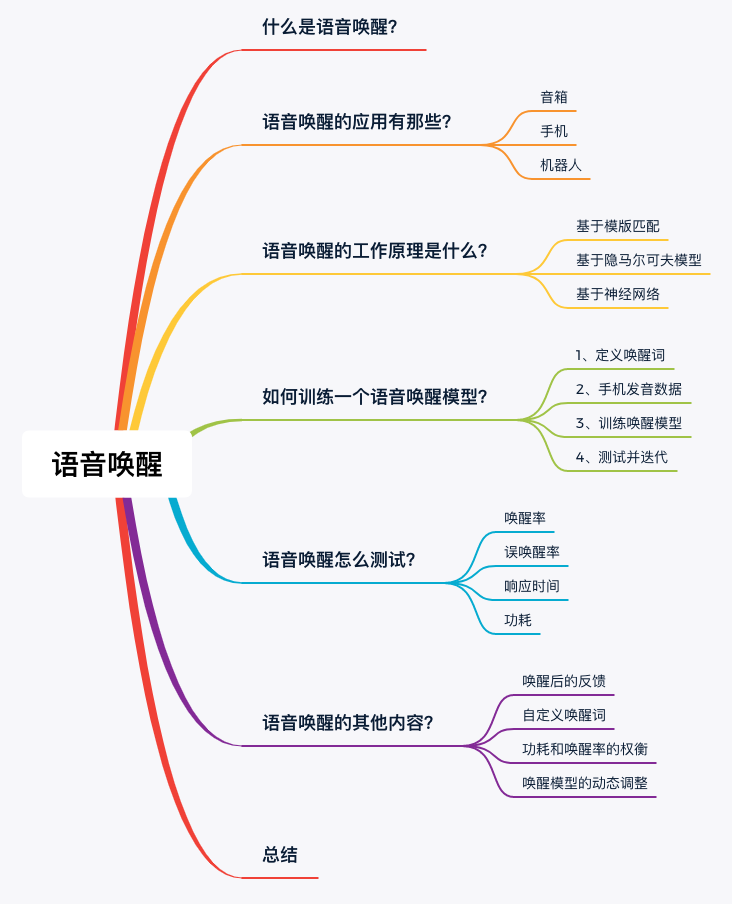
1. 基于模板匹配
用模板匹配的方法来做唤醒模型,一般会把唤醒词转换成特征序列,作为标准模板。
然后再把输入的语音转换成同样的格式,使用DTW (dynamic time warping)等方法,计算当前音频是否和模版匹配,匹配则唤醒,不匹配则继续休眠。
简单理解就是找到唤醒词的特征,根据特征制定触发条件,然后判断音频内容是否满足触发条件。
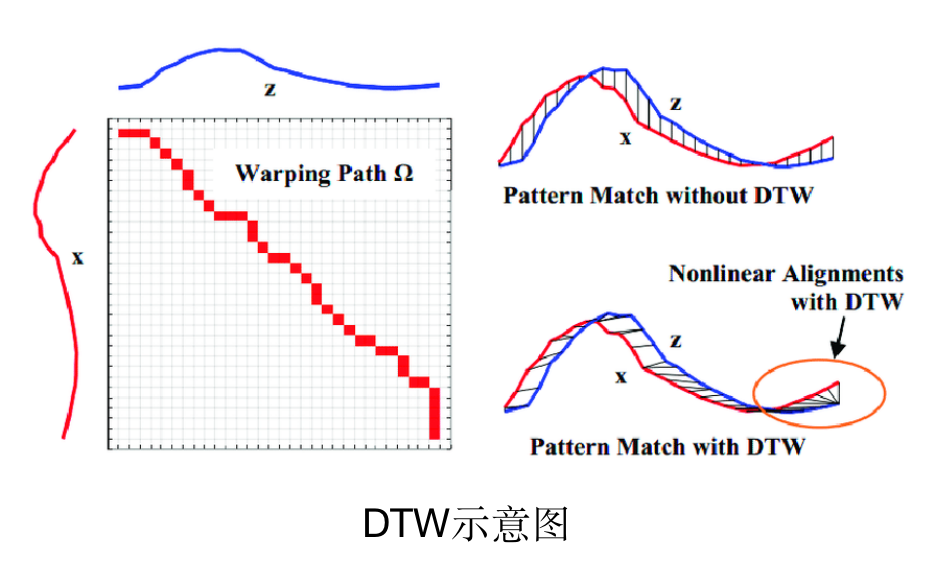
2. 基于隐马尔可夫模型
用隐马尔可夫模型来做唤醒模型,一般会为唤醒词和其他声音分别建立一个模型,然后将输入的信号(会对音频信息进行切割处理)分别传入两个模型进行打分,最后对比两个模型的分值,决定是该唤醒,还是保持休眠。
简单理解就是分别对唤醒词和非唤醒词作了一个模型,根据两个模型的结果对比,决定是否唤醒。
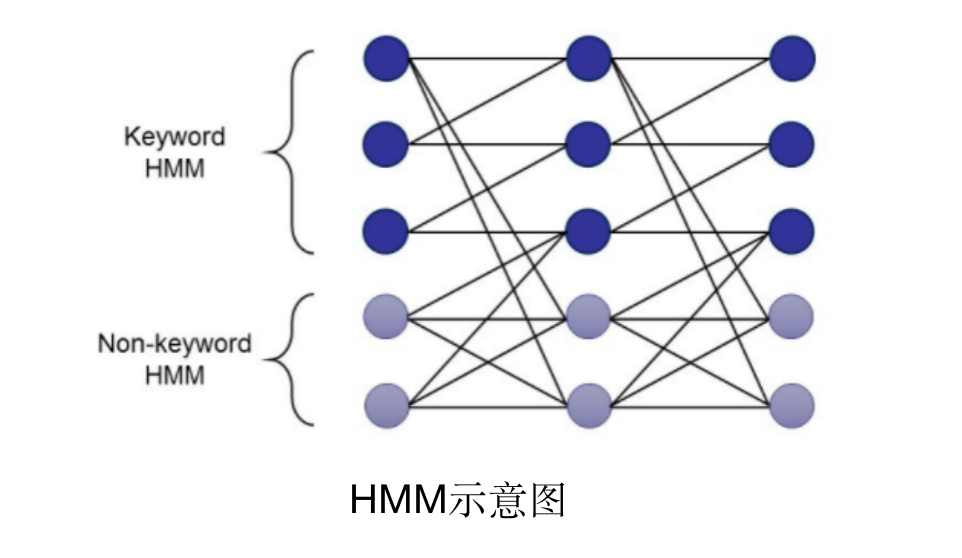
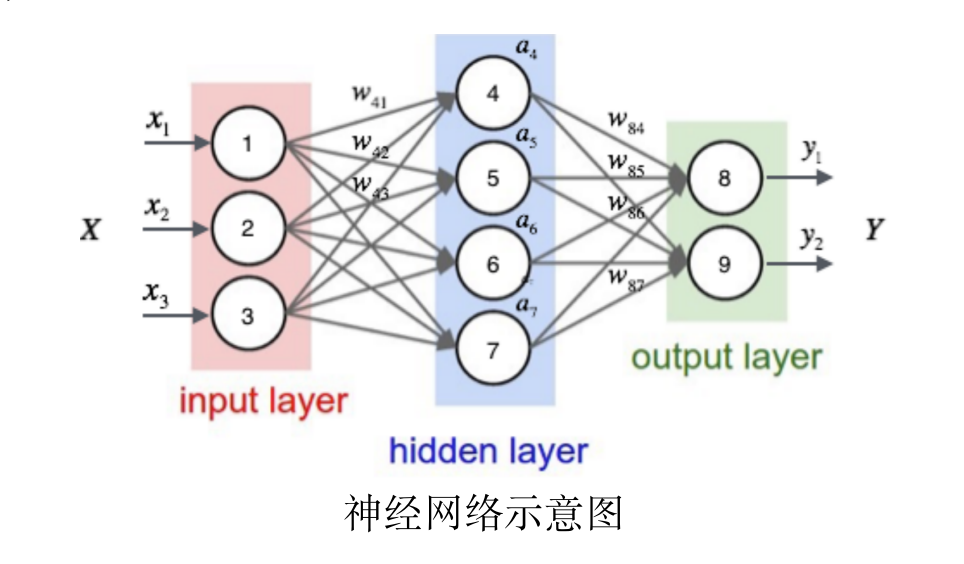
3. 基于神经网络
用神经网络来做唤醒模型,可以分为多种:
- 有将模版匹配中的特征提取,改为神经网络作为特征提取器;
- 也有在隐马尔可夫模型中,某个步骤使用神经网络模型的;
- 还有基于端到端的神经网络方案。
凡是用到神经网络原理的,都可以说是基于神经网络的方案。
其实唤醒模型工作原理很简单,就是一直在等一个信号,等到这个信号就切换到工作状态,只是判断信号的内部逻辑不同而已。
四、如何训练一个唤醒模型
一般训练语音唤醒模型大概需要四个步骤,包括:
1. 定义唤醒词
首先我们需要定义一个唤醒词:
定义唤醒词也是有讲究的,一般会定义3-4个音节的词语作为唤醒词。像我们常见的“天猫精灵”、“小爱同学”、“小度小度”,全部都是4个音节,由于汉语的发音和音节的关系,你也可以简单的把音节理解为字数。
唤醒词字数越少,越容易误触发;字数越多,越不容易记忆——这也是一般定义在4个字的原因。
另外这3-4个字要避开一些常见的发音,避免和其他发音出现竞合,要不然会频繁的误唤醒。
一般唤醒词会做这样一个处理,就是唤醒词中的连续3个字也可以唤醒,比如你喊“小爱同”,同样可以唤醒你的小爱同学。这是为了提高容错率所做设定的规则。
2. 收集发音数据
然后就需要收集这个唤醒词的发音,理论上来说发音人越多、发音场景越丰富,训练的唤醒效果越好。
一般按照发音人数和声音时长进行统计,不同的算法模型对于时长的依赖不一样。基于端到端神经网络的模型,一个体验良好的唤醒词可能需要千人千时,就是一千个人的一千个小时。
收集唤醒词发音的时候,一定要注意发音的清晰程度,有时候甚至要把相近的音也放到训练模型中,防止用户发音问题导致无法进行唤醒。
如果用户群体庞大,甚至考虑该唤醒词在各种方言下的发音。
3. 训练唤醒模型
数据都准备好了,就到了训练模型的阶段了,这里常见的算法有:
- 基于模板匹配的KWS
- 基于马尔可夫模型的KWS
- 基于神经网络的方案
这三种方案对比如下:
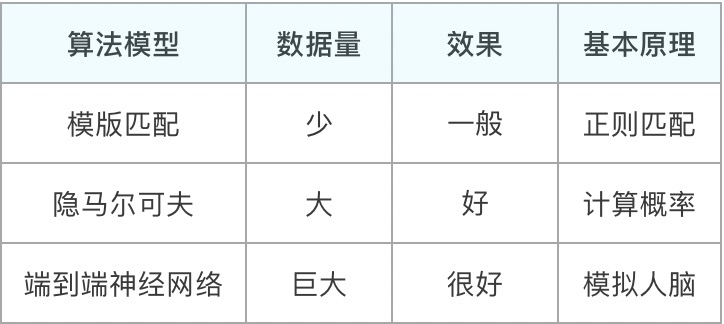
4. 测试并迭代
最后就是测试并上线,一般分为性能测试和效果测试,性能测试主要包括响应时间、功耗、并发等,这个一般交给工程师来解决。
产品会更关注效果测试,具体的效果测试我们会考虑唤醒率、误唤醒率这两个指标,后面的测试环节我们会详细测试的流程和指标。
产品上线后,我们就可以收集用户的唤醒数据,唤醒词的音频数据就会源源不断。我们需要做的就是对这些唤醒音频进行标注、收集badcase,然后不断的进行训练,再上线,就是这么一个标注、训练、上线的循环过程。
直到边际成本越来越高的时候,一个好用的唤醒模型就形成了。
五、语音唤醒怎么测试
语音唤醒测试最好是可以模拟用户实际的使用场景进行测试,因为不同环境可能实现的效果不一样。比如:常见各个厂商说自己的唤醒率99%,很可能就是在一个安静的实验室环境测试的,这样的数字没有任何意义。
这里说到的场景主要包括以下几点:周围噪音环境、说话人声音响度、以及说话距离等。
测试的条件约束好,我们就要关心测试的指标了,一般测试指标如下:
1. 唤醒率
唤醒词被唤醒的概率,唤醒率越高,效果越好,常用百分比表示。
在模拟用户使用的场景下,多人多次测试,重复的叫唤醒词,被成功唤醒的比就是唤醒率。唤醒率在不同环境下,不同音量唤醒下,差别是非常大的。
用25dB的唤醒词测试,在安静场景下,3米内都可以达到95%以上的唤醒率,在65-75dB噪音场景下(日常交谈的音量),3米内的唤醒率能够达到90%以上就不错了。
所以看到各家唤醒率指标的时候,我们要意识到是在什么环境下测试的。
2. 误唤醒率
非唤醒词被唤醒的概率,误唤醒率越高,效果越不好,常用24小时被误唤醒多少次表示。
在模拟用户使用的场景下,多人多次测试,随意叫一些非唤醒词内容,被成功唤醒的比就是误唤醒率。
如果误唤醒率高,就可能出现你在和别人说话,智能音箱突然插嘴的情况。

3. 响应时间
用户说完唤醒词后,到设备给出反馈的时间差,越快越好。
纯语音唤醒的响应时间基本都在0.5秒以内,加上语音识别的响应时间就会比较长,我们下章再讨论。
4. 功耗
唤醒系统的耗电情况,对于电池供电的设备,越低越好。
一般插电使用的音箱还好,对功耗的要求不是很严格。但是像手机、儿童玩具等产品,由于是电池供电,对功耗的要求较高。
siri是iphone4s就有的语音助手,但直到iphone6s的时候,才允许不接电源下直接通过语音唤醒siri,当时就是考虑功耗的原因。
六、语音唤醒的其他内容
1. 唤醒后的反馈
我们通过唤醒词唤醒设备后,需要一个及时的反馈,来提醒我们唤醒成功,这就要考验产品的设计功力了。
一般会有两个可感知的层面上进行提示,一个是听觉方面,一个是视觉方面(暂不考虑震动)。
听觉方面的反馈,又分为两种:
- 一种是语言回复
- 一种是声音提示
语音回复一般常见的有“在的”、“嗯嗯”、“来了”等,都是一些简短的回复,表示已经听到。这几句TTS的内容需要仔细打磨,反复调试,才能达到一个理想的效果,建议不要超过1秒。
声音提示往往是在语音回复之后,提示用户可以进行语音交互了,一般都是一个简短的音效,之后就开始收音了。
视觉方面的反馈,也可以分为两种:
- 一种是灯效反馈
- 一种是屏幕反馈
灯效反馈常见于智能音箱的产品上面,他们没有屏幕,但是也需要在视觉上提示用户,一般不同颜色的灯效,表示机器不同的状态,是有明确的产品定义的。
屏幕反馈可以做的事情就比较多了,可以根据自己产品的需求,设计提示的强度,是弹出浮窗,还是弹出页面,根据不同的应用场景来设计,这里就不展开讨论了。
还有一种情况,中间是不需要反馈的,比如“天猫精灵,打开灯”这样一气呵成的唤醒+交互,我们只需要执行相应的指令,并给出最后执行结果的反馈即可。

2. 自定义唤醒词
随着语音交互的普及,逐渐衍生出一些个性化的需求,大家开始给自己的设备起一个专属的名字,这就是自定义唤醒词。
自定义唤醒词一般会打包成一个输入框提供给用户,用户只需要在框内按照我们的提示填写内容即可,在这里我们可能需要注意以下几点:
- 唤醒词要有明确的字数限制,比如3-6个字;
- 需要检测填写的唤醒词是否含有多音字,并进行提示,或支持注音修改;
- 是否替换默认唤醒词,有时需要新加的唤醒词替代默认唤醒词,有时可能是并存的;
- 自定义唤醒词的质量要高,就是前面说过的,相邻的音节要规避,音节要清晰。
3. 功耗和唤醒率的权衡
还有一个技术上面的问题,就是唤醒的效果要在功耗之间达到一个平衡。
一般在电池供电的产品上,需要有专门控制语音唤醒的独立硬件,来平衡效果和功耗,达到一个相对理想的水平。
4. 唤醒模型的动态调整
之前就听说过亚马逊音箱半夜被周围噪音误唤醒,然后给一些莫名其妙的回复。想想晚上睡着了,然后音箱突然自言自语,想想就比较恐怖。
为了应对这种问题,我们可以动态调整音箱的唤醒阈值,比如正常的阈值是0.9以上进行唤醒,那么晚上可以根据应用场景,设置为0.8以上唤醒,具体还要看场景和模型的效果。

七、总结
整个过程需要先定义唤醒词,再根据实际场景选择模型,收集数据,最后上线迭代。
随着产品的用户越来越多,训练数据越来越大,整个唤醒模型进入一个正向循环,再考虑支持自定义唤醒词的能力。
语音唤醒作为语音交互的前置步骤,主要负责判断什么时候切换为工作状态,什么时候保持休眠状态,而这个判断依据就是语音信息。
本文由 @我叫人人 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议










技术转的产品吗?作者大人
你好,能加个微信交流吗
我说的方言它能听懂?
哈哈哈哈,兄嘚那儿的人呀
😒
优秀
😀😀谢谢
有公众号吗
没有呢,就是把一些工作经验输出,再总结