
 起点课堂会员权益
起点课堂会员权益小白产品必看的推荐系统四步指南!
编辑导语:互联网使得信息传播从传统的纸媒到如今去中心化的UGC方式。当海量的信息进行分发时,作为产品设计者,我们需要考虑的问题是如何做好内容分发系统。今日头条为我们提供的一个方向——算法推荐。那么,作为一个新产品,该如何从0到1完成一个推荐系统,作者总结了四步,与你分享。

互联网使信息传播从传统的中心化纸媒逐渐变成了去中心的UGC方式。在这个时代每个人都可以是信息生产者,可以是信息传播者,更是信息消费者。
而当海量被生产,信息发生过载时,我们应该如何分发和消费内容。张一鸣和他的今日头条给了我们一个方案-算法推荐。而如何做好算法推荐,也被看做产品里最具挑战的事情。
那作为一个新产品,应该如何从0到1完成一个推荐系统?我分为以下四步为大家讲解:
一、产品属性分析
首先你要明白的是,并非所有产品都需要做推荐系统,不同产品的推荐策略也并非一致,毕竟每个算法工程师都是移动的金库(= =),优秀的推荐系统需要的成本也是相当高。
了解你的产品属性和用户需求是最重要的一步。普遍认为用户和资源量大的产品更需要个性化推荐,如淘宝、抖音、新浪新闻等这些信息分发型产品,而微信、WPS这类工具型产品却鲜少需要做推荐。我们将产品属性分为用户属性和资源属性:
1. 用户属性
首先我们需要了解产品的用户组成和他们需要什么,比如用户只想用你的软件编辑文档,那你为他推荐再多视频也没用。
2. 资源属性
资源属性是指平台的资源组成,就是你的产品服务都有什么,可以是虚拟产品(文章、短视频、课程等),也可以是实体产品(手机、音响等)。
而当这两者组合起来,当不同的用户需要不同的资源时,这时候我们就需要推荐系统了。
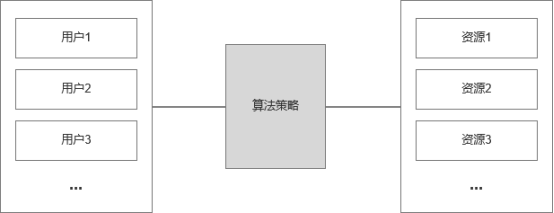
如果你能理解这部分,你也大致能明白为什么大多数工具型产品不需要推荐了。工具型产品为了确保服务深度,大多提供的功能需求都是收敛且聚焦的,多数用户用相同的服务,所以也不存在什么个性化推荐了。
你以为产品属性分析只是让你了解推荐吗?No,其实产品属性分析有着更大的价值,因为它决定了推荐策略的具体目标。比如你是视频网站,那目标也许是提升用户观看时长。那后面的整个算法策略中,都要围绕着观看时长去进行拆分和优化。如果是电商平台,那就要围绕下单量优化推荐策略了,不同的产品属性其应用的推荐策略实际上千差万别。
二、特征工程(标签系统)
接下来让我们更进一步,在开展推荐策略前我们必须打好基础。我们需要了解用户更具体的需求,也需要了解平台都有哪些资源。这样才有可能实现用户和资源的匹配,这个过程我们称之为打标签,实际工作中也称为“特征工程”。
标签类型多种多样,从概念上我们主要分为“用户标签”和“资源标签”两种。
1. 用户标签
一般用户标签包含基本属性、活跃属性和兴趣标签三种:
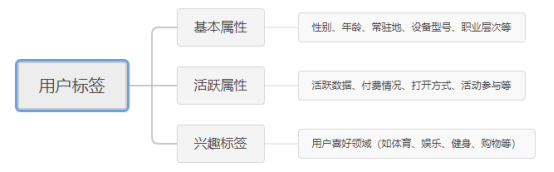
- 基本属性常指“性别”、“年龄”、“常驻地”、“手机设备型号”、“职业层次”等用户自然属性,是用户未使用产品时便客观拥有的基本属性。
- 活跃属性指用户在使用产品时留下的行为数据,根据计算方式,又分为统计类和规则类两种。统计类是指可以直接进行统计计算的数据,如用户活跃天数、累计付费金额、活动参与数等;而规则类标签则指某些相对复杂的标签,需要先针对制定规则模型,再进行计算的数据。比如用户活跃等级(高、中、低),用户参与意愿等都需要提前明确计算规则。用户的活跃数据也常被用来评估用户粘性和周期价值。
- 兴趣标签属于挖掘类标签,一般依赖于资源标签。指用户在浏览具体的内容资源时,将资源本身的标签贴给用户,用户使用行为越多,兴趣标签就越多越精准。并且根据不同行为各标签的分值也不同(比如搜索作为用户主动提出需求,其所占分值会较高),抖音越看越想看就是同理。其根据应用场景又分为短期标签(在线计算,一般为2天内标签)和长期标签(离线计算,指历史累计标签)。
2. 资源标签
指产品内各类资源的标签,分“类别”和“关键词”两种维度。
类别标签是以某种指定规则将资源归类,一般根据资源的复杂度分为2~5级不等,也有平台分级更多。下图是某瓣的类别标签。
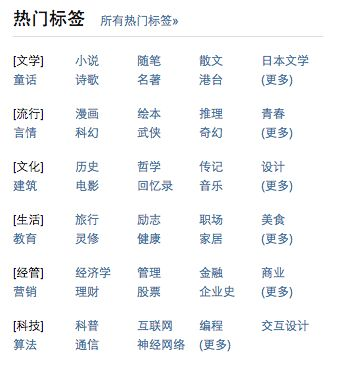
关键词标签则是在类别的基础上更细一层,指具体的标签词。比如用户对政治人物感兴趣时,我们发现其主要体现在“特朗普”这个人名上,那关于特朗普的一些商业信息也可以做适当推荐。
通过特征工程我们会为每个用户和资源都打上大量的标签,然后再引入推荐策略。这两类资源标签一般是通过人工标注和机器学习两种方式来添加。但机器学习需要大量的标注量才能达到一定准确度,所以在产品初期会更依赖于人工标注和词库拓展。到一定数据规模后,再训练机器学习。最后通过持续的机器学习+人工修正,整个特征工程就能达到一定的识别准确度。
三、推荐策略
当我们将用户标签和资源标签采集到后,接下来就是推荐策略的部分,推荐策略一般分为召回和排序两大模块。
1. 推荐系统组成
用户访问产品时,我们优先从资源库中召回符合用户标签的资源,这里通常是千/万的数据量级,然后根据这些资源的标签匹配度、时间等进行排序展示,成熟的产品还会涉及到精排和重排,根据用户对每条资源的使用行为,实时改变后续资源的排序。实际工作中会由工程师将召回和排序封装成一个推荐引擎,然后内部各项环节都有相应的算法人员跟进优化,也就是所谓的模型调参。

2. 召回/排序具体策略
召回和排序是推荐算法中两个相当庞大的工程,涉及方法众多,这里仅和大家简单分享下其中主要的策略组成。
1)召回
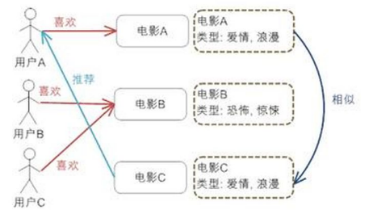
资源库中的资源千千万,但最终给用户展示的只有几十甚至十几条,如果直接对所有物料计算排序不仅成本极高且响应较差。所以我们需要对物料进行初筛,针对性召回用户可能感兴趣的一批候选集。传统的标准召回结构一般是多路召回,主要分为“个性化召回”和“非个性化召回”两大类,个性化召回指针对用户特征进行召回,主要有“兴趣标签召回”、“协同过滤召回”等;非个性化主要指“热门召回”、“冷启动召回”这类统一特征的召回。
实际应用中会根据不同场景,选择上述一种或多种召回策略进行。比如搜索场景下的召回排序,你在淘宝搜索某件商品后,再次访问列表时便会发现该类商品排在首位。而召回的多样性是很重要的,有时候多一路召回策略产生的效果也许会是惊人的,而召回质量也很大程度上决定着推荐系统的上下限。
下图为其中“协同过滤召回”的示意图:
 2)排序
2)排序
一般当候选集达到“千”这个数量级,我们就开始需要排序策略了,一般通过粗排和精排将候选集缩减在“百”级并进行打分,按分值top排序,再根据用户的实时反馈进行重排序,将数据量缩至“十”这个级别进行排序展示。
排序的目标是根据业务目标来不断变化的,最早期由于业务目标简单,需要聚焦的时候,往往会选取⼀个指标来重点优化排序。但随着多路召回策略的增多,到中期就会发现单⼀指标对整体的提升已经非常有限了。这时候我们就需要引入多目标排序来解决这些问题,比如结合时间、兴趣、热点、位置等众多维度的数据进行综合排序,这里应需要注意不同的用户场景其排序侧重点不同,所以需要不同的排序策略来提高精度。比如兴趣流中更注重兴趣标签,热点信息流中更重视互动数据等。
常用的排序算法框架有pointwise、pairwise、listwise三类,下图中x1,x2,… 代表的是训练样本1,2,… 的特征,y1,y2,s1,… 等是训练集的label(目标函数值)。感兴趣的同学可以自行深入了解下,这里不多赘述。

四、模型的持续优化
当围绕人和物建立起一套推荐模型后,工作并没有结束。相反,它才刚刚开始。
多数产品首次上推荐时便需要面对较复杂的策略规则,但因缺少实际数据依托,往往是算法人员凭个人经验和竞品来作参考给出初始模型(比如某feed中初始策略设置热点权重4,时间权重2、兴趣权重2等),所以导致效果也参差不齐。一般需要灰度上线后,拿到实际的用户反馈数据(比如ctr、完播率、下单率等),才能针对模型持续进行调优和完善。
我们针对某个模型进行数据验证时主要分为两步:
- 离线评估:在离线准备好的新数据集和之前模型数据做对比,比如准确率、覆盖率、多样性等多方面,如该模型的综合指标优于线上模型,则可以进入线上实验,这里一般由产品经理把关。
- 线上实验:当评估模型效果较优后,我们需要在线上进行A/B分桶实验。一般实验周期在2周左右,对比实验组和对照组,如实验数据为正向,则推到更多用户量继续监测。如在某个阶段为反向,则返回优化模型策略,反复实验直到逐步推向全量用户。
“没有最好,只有更好”这句话也算是推荐系统的真实写照。算法推荐不像其他功能型需求,它也没有绝对完成的那天。强如头条和抖音的算法体系已如此健全,其每年还是花费大量成本来招聘算法岗。因为随着社会发展,用户习惯和兴趣爱好时刻产生着不同程度的变化。所以让推荐系统保持敏捷,长期持续的监测和策略优化才是整个推荐系统中的常态。
今天的分享到这里就结束了,共分为“产品属性分析”、“特征工程”、“推荐策略”、“模型持续优化”四部分,篇幅有限细节部分就有所忽略,希望大家多包含。路漫漫其修远兮,相信随着互联网信息网络的发展,更加完备更有想象力的推荐算法也会不断地涌现和繁荣!
本文由 @许木 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。









好文章,小白能看懂
干货满满!感谢作者大大的分享,要把这篇文章收藏起来好好看!
感谢支持~