
 起点课堂会员权益
起点课堂会员权益个性化场景推荐并不神秘,带你读懂推荐计算模型
许多产品里都设置了推荐模型系统,比如结合推荐模型,购物平台可能会更知道用户更想要什么,从而让相关产品出现在用户浏览首页。那么,推荐模型是如何“起效”和“运转”的?个性化推荐,又有哪些存在意义?本篇文章里,作者便发表了他的看法,一起来看。

一款应用软件或系统设计,为了更好地迎合市场用户,一定逃离不了对用户的推荐模型,而推荐的目的是为了更好地解决用户痛点,触达用户目标,从而达到用户的留存,提高用户与产品之间的粘度,比如在日常购物场景中,打开同一款购物应用可能会遇到若干种情形:
- 和好友同时打开app后发现,为什么两个人首页各个频道入口的图片以及文字不一致?
- 为什么同样搜索相同关键词,你和好友竟然出现不一样的商品列表?
- 为什么我刚刚浏览了裤子以后,首页各个频道的展现变了?
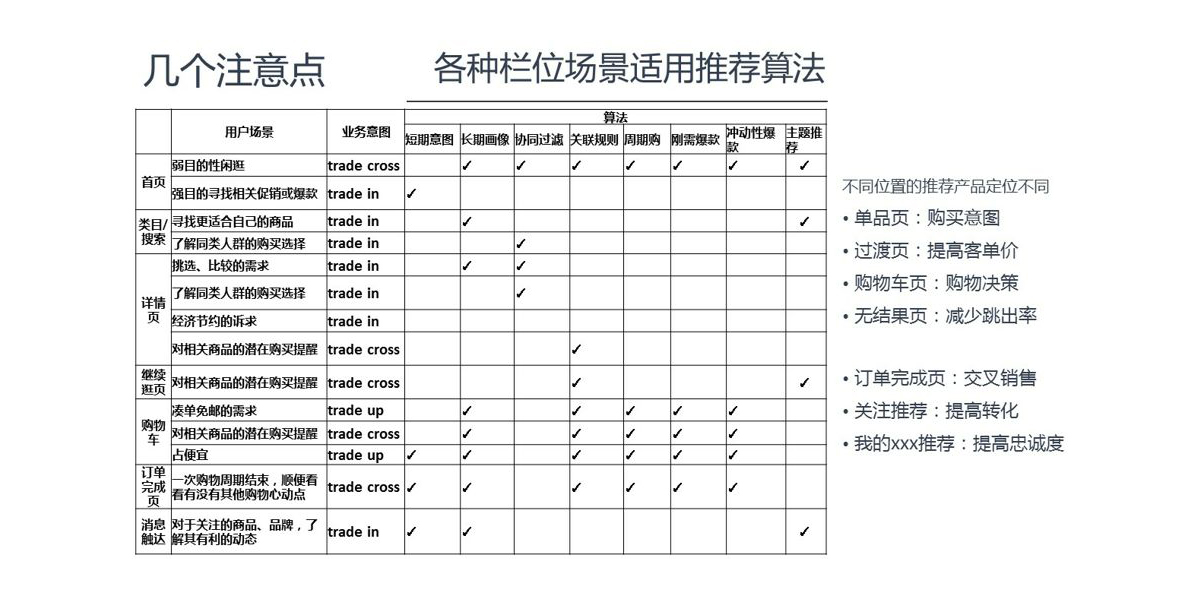
一、购物平台是如何知道我需要什么?
- 是如何知道我喜欢什么并且可能想要买什么的?
- 为什么它能做到每个人都不一样?
- 为什么它要这么做?
从这里会产生一个机器人模型学习概念,机器学习就是将主体换为机器,并且它通过某种途径来获取知识或者技能的过程,并应用于未来的生活工作,人获取知识的外化载体是书本、音频、视频等,传输通道是人的感官,处理中心是大脑,而对应于机器外化载体也同样可以有以上各类信息源,并且使用各类外放设备收集信息,处理中心是CPU与存储共同维护。
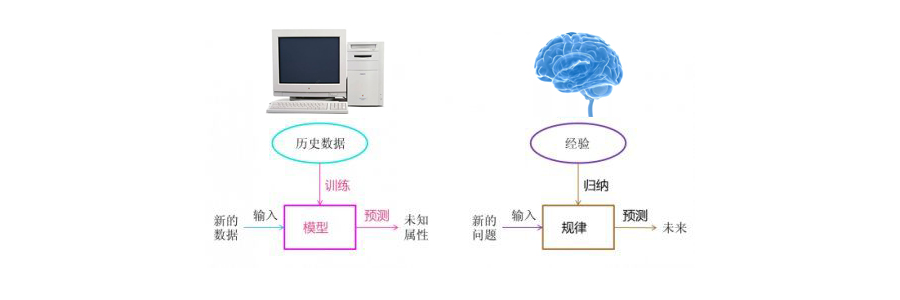
一个是演绎法,一个是归纳法,这两种方法分别对应人工智能中的两种系统:专家系统和机器学习系统。
所谓演绎法,是从已知的规则和事实出发,推导新的规则、新的事实,这对应于专家系统。
专家系统也是早期的人工智能系统,它也称为规则系统,找一组某个领域的专家,如医学领域的专家,他们会将自己的知识或经验总结成某一条条规则、事实,例如某个人体温超过37度、流鼻涕、流眼泪,那么他就是感冒,这是一条规则。
当这些专家将自己的知识、经验输入到系统中,这个系统便开始运行,每遇到一些新情况,会将之变为一条条事实。当将事实输入到专家系统时,专家会根据规则或事实进行推导、梳理,并得到最终结论,这便是专家系统。
而归纳法是从现有样本数据中不断地观察、归纳、总结出规律和事实,对应机器学习系统或统计学习系统,侧重于统计学习,从大量的样本中统计、挖掘、发现潜在的规律和事实。
二、机器学习过程数据维度
可以大致推算出购物app为什么能够知道你喜欢什么,是基于一个假设条件的:一个人历史的购物行为及偏好,会在未来的行为中也有迹可循。
所以利用机器学习我们通过用户历史交互数据(特征包括:谁在什么时间买了什么东西,这个东西的名字叫什么,什么颜色,价格多少等等)。 比较有用的可以对未来推荐有指导意义的特征包括:
1)购买力
一个平时只买100元左右牛仔裤的用户,未来短期内买10000元和10元的裤子的概率远远低于买100左右或者200左右的概率,所以推荐的时候会更优先给你看到100-200左右的裤子。
2)性别
平时在淘宝上只买男性或男女通用商品的用户,未来短期内买女性商品概率远远低于男性和男女通用商品的概率。
3)年龄
一个一直购买20-25岁左右服饰的用户,未来短期内购买其它年龄段的概率远远小于20-25岁年龄段的概率。
三、为什么能够做到每个人不一样?
根据学习逻辑归类,如果在机器学习阶段考虑一些跟人相关的因素(特征),那这个因素的不同值就会影响结果输出。
比如我们现在根据用户对他购物的商品的评分数据,来预测一个他从未买过的商品的评分,背后影响用户评分的因素可能包括以下几个:价格,售前/后,物流,商家主营类目是否和用户购买的类目相同,其它用户的评分(如果其他用户评分高则一定程度上代表了这个商品的好坏)等等。
比如物流和价格这类因素(特征),如果和用户这个特征做交叉后,其实会有非常迥异的权重值,而这一切是每个用户的购买力和用户体验耐受力等不同带来的。所以如果你考虑了用户的特征则这就会影响每个人的推荐结果不一样。
四、个性化推荐的核心使命
可以打破80%的用户只买20%的商品的规律,更好地降低长尾商品的比例,因为在电商产品中,在非个性化的商品展示过程中,往往爆款商品拥有更多的流量,这样其实不能很好的照顾到高质量长尾用户和高质量长尾商品。
举个例子,在淘宝的某个频道,有很多裤子,A裤子100元近5天的销量可能1w件,B裤子1000元近5天的销量是100件,在不考虑其它因素的情况下,非个性化模型(或运营排序)一般会偏向于A裤子在B裤子前面,但是如果这个用户在平台历史购物行为都是集中在高价格商品(名牌包包等),则如果你个性化的考虑每个人的这个偏好,那么有可能B裤子就在前面了,而且用户可能真的更喜欢B裤子。
1. 流量均衡曝光
在APP或网站有限的商品曝光机会下,为每个展现的商品争取最大的点击/成交等,因为用户在平台上的时间是有限的,如果能在海量的商品中,为用户找到他感兴趣的商品,那么平台将在这有限的流量资源下收获更大的价值。
举个例子,有可能用户在某个频道下,看了A,然后看了B,再看了C,最终买了D,并且ABCD这四个商品都是有一定关系的商品,那么平台能否在一开始在我看完A以后就帮我找到C,并在A下面推荐D商品。在最大限度挖掘用户购物需求的情况下,最大限度缩短用户购物的时间。
2. 提升极速流畅的购物体验
可以给用户创造极致的用户体验,极致的用户体验是用户信任依赖平台,在每次购物过程中,希望平台能够帮助其快速,准确地找到其想要的商品,其中包括了基于用户历史兴趣的再延伸,也有基于用户角色的行为探索。
比如用户每隔25-30天会购买尿不湿,未来平台是否能够在23-33之间快速捕捉用户购买尿不湿的需求;再比如用户在平台上第一次浏览电脑,我基于用户的其它购物行为(比如用户之前在平台上经常买20-25岁的衣服,并且大部分邮寄的地址为大学宿舍),是否平台可以在接下来的浏览中为用户呈现适合学生族高性价的电脑。
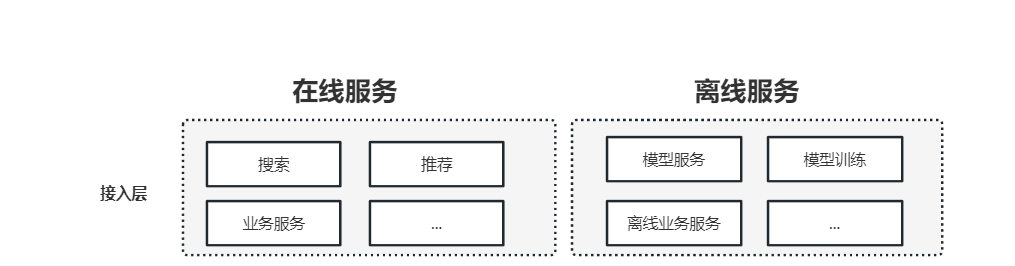
稳定的流量与稳定的交互、比例可以保证数据的稠密性,单用户和单商品有足够的数据可以完成机器学习,并且保证一定的置信度;当有新用户(新商品)加入系统时,由于系统中缺乏用户(商品)历史反馈信息,所以完全无法推断用户的偏好,也就无法做出预测,信息匹配量级差异过大。
在人机交互过程中不断拓展用户行为模型,补充足够的产品信息库,根据不同人群浏览行为进行精准推荐与展示,实现把不同价格产品根据不同的流量池分布给需要的用户,这个过程可以称为从广泛匹配到精准匹配,使购物的推荐运算模型得到个性化的具象呈现。
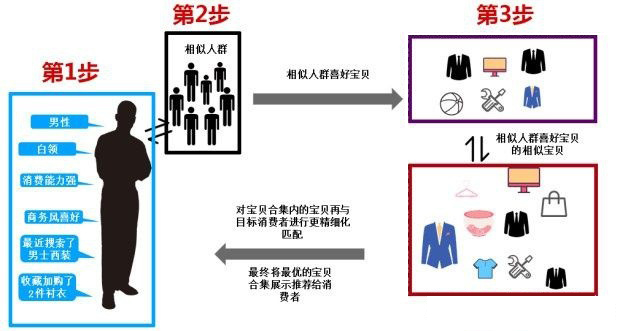
也俗称千人千面的搜索个性化,千人千面并不神秘,只不过是统计学的应用,
简单的来说,展现在用户面前的是产品合集,从用户到产品展示合集分四步曲。
第一步:用户进入产品应用,产品立即识别用户的标签,这些标签叫做抽样条件。
第二步:根据该用户标签找到相似人群,这叫做根据条件抽样。
第三步:根据相似人群找到他们共同喜欢的产品,叫做对比样品共性。
第四步:在系统所有同类型的产品中,找到与样品库相似的产品,形成产品合集,这些产品合集会展示在该用户的面前,相似度越高,权重越高,排名越靠前。
专栏作家
小镊子,人人都是产品经理专栏作家。养成挖掘性的思考习惯、综合、市场、运营、技术、设计、数据、擅长跨境电商,综合电商与商业模型。
本文原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


