
 起点课堂会员权益
起点课堂会员权益【入门科普】必了解的 20 个 AI 术语解析(下)
AI领域的基础概念和相关技术有很多,这篇文章里,作者就深入浅出地介绍了相应的内容,感兴趣的同学们,不妨来看一下。

本文专为非技术背景的AI爱好者设计,旨在深入浅出地介绍AI的基础概念和关键技术,带您一步步解锁AI技术的奥秘。建议先阅读【入门科普】必了解的 20 个 AI术语解析(上)再阅读本文。
十一、生成对抗网络
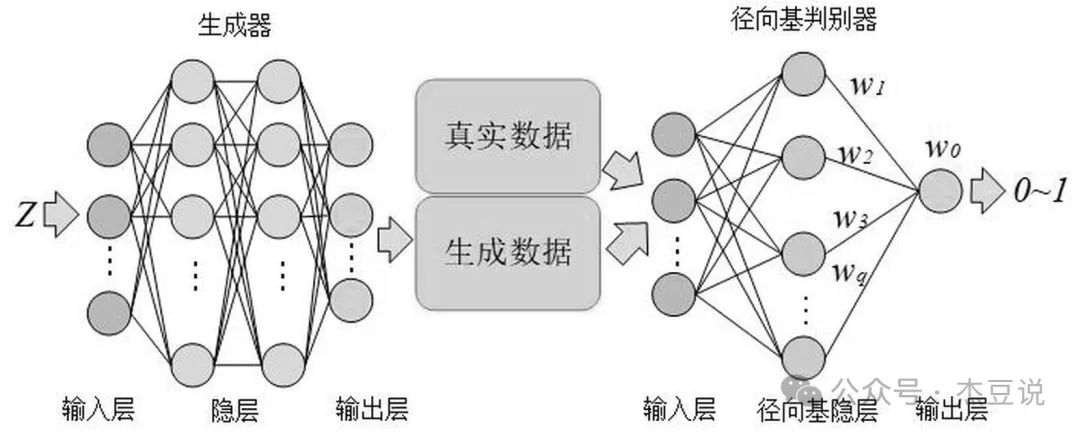
想象一下有两位艺术家:一位是伪造者,另一位是鉴赏家。伪造者试图创作出看起来像真正艺术品的作品,而鉴赏家则试图区分出哪些是真正的艺术品,哪些是伪造的。他们不断地相互学习会使得伪造者变得越来越擅长创作逼真的作品,而鉴赏家则变得越来越擅长识别真伪。
生成对抗网络GAN由两部分组成:一个是生成器(伪造者)和一个是判别器(鉴赏家)。
十二、强化学习
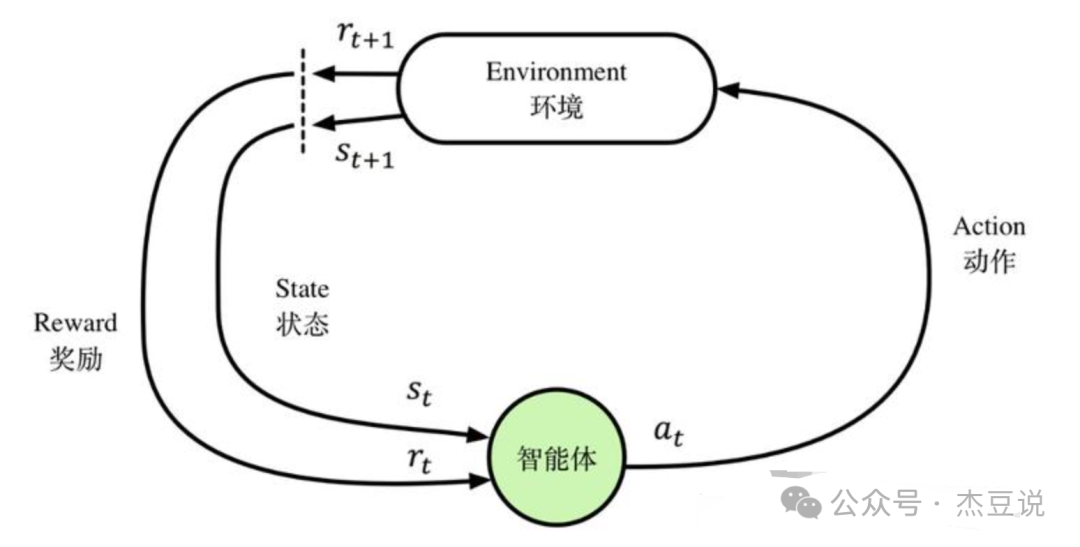
如果说对抗网络是真假孙悟空之间的1对1的斗智斗勇,目标是战胜对方,那么强化学习就是1对多的一路斩妖除魔,设定一个去西天的目标,取经队伍总会去想办法在真实环境中排除万难,那些牛魔王、火焰山、蜘蛛精、女儿国等等都是在环境中遇到的不同的挫折,磨炼的是取经队伍内在的佛性。
十三、主成分分析
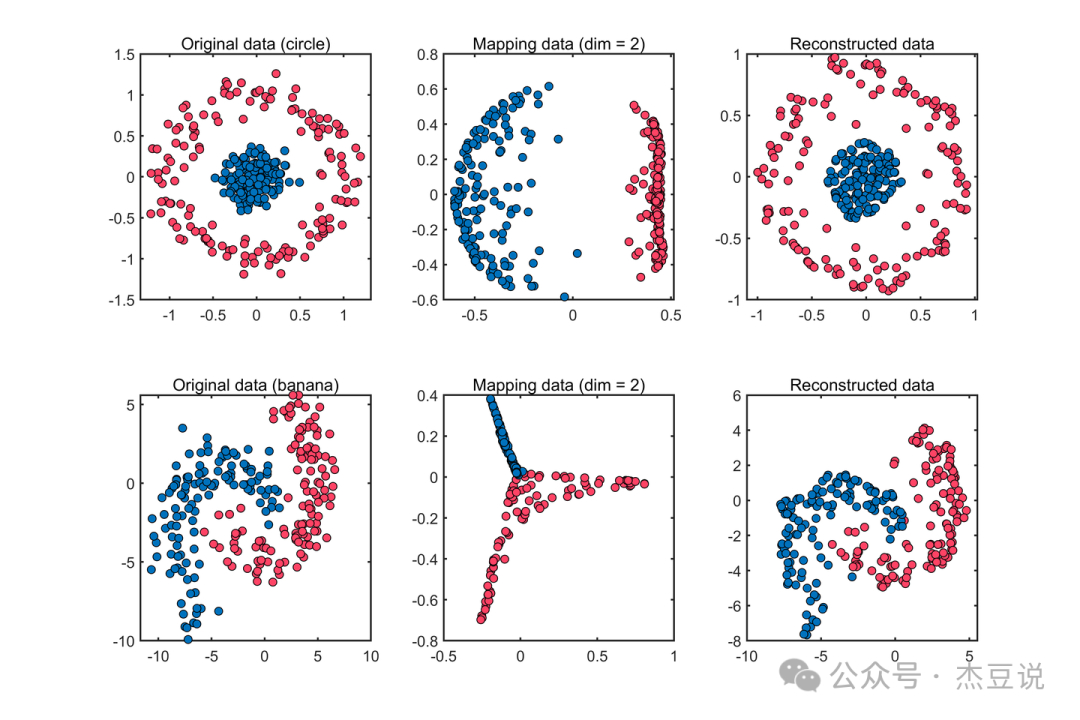
假设你有一个非常杂乱的书桌,上面堆满了各种物品。如果你想用一张照片抓住书桌的“精华”,但又不想让照片显得太杂乱,你可能会选择从一个角度拍摄,这个角度能最好地展示书桌上最重要的几样东西。PCA就是在做类似的事情:它试图找到最能代表整个数据集“精华”的几个方向(主成分),然后用这些方向来简化和描述数据集。
十四、交叉验证
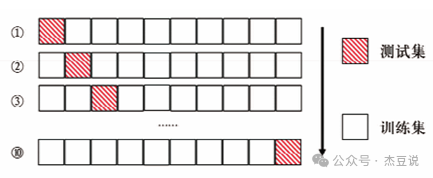
交叉验证是机器学习中的一种评估方法,旨在测试模型对新数据的预测准确性。它通过将数据集分成多个部分来工作。在k-折交叉验证中,整个数据集被分成k个等大小的子集。然后,模型会进行k次训练和测试的循环,每次循环中,选择一个不同的子集作为测试集,而剩余的k-1个子集用作训练集。通过这种方式,每个数据子集都有机会作为测试集使用。完成这k次循环后,通过平均所有循环的测试结果来评估模型的整体性能。
十五、梯度下降
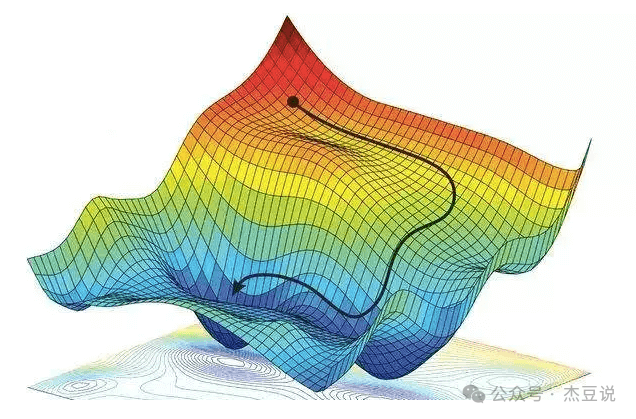
想象你在一座山上,目标是找到山谷的最低点。由于山上浓雾弥漫,你看不清整座山,所以无法直接找到最低点。梯度下降就像是你决定每次都沿着当前位置最陡峭的下坡方向走一步,期望这样可以带你到达山谷的最低点。在机器学习中,梯度下降帮助模型“学习”到最佳参数,即找到能让模型预测误差最小的参数。
十六、迁移学习
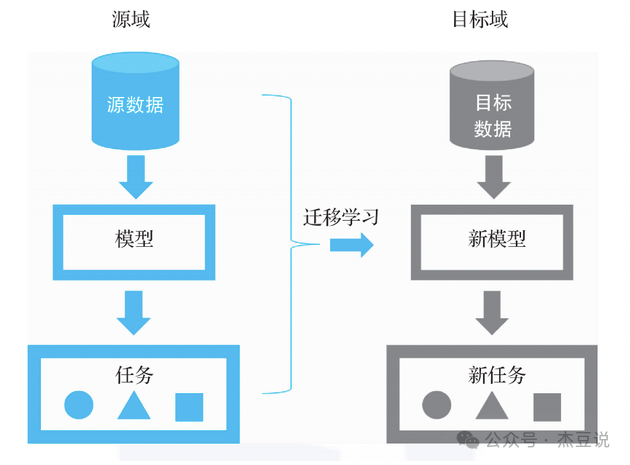
假设你已经是一个钢琴高手,现在你想学习吉他。由于你已经掌握了很多关于音乐的知识,如音阶和节奏,你可以把这些知识应用到新的学习中,这样你学吉他的速度就会更快。在AI中,迁移学习就是这个原理,它让一个已经在一个任务上训练好的模型,用于另一个相关但不同的任务。这样可以节省大量的训练时间和资源。
十七、特征工程
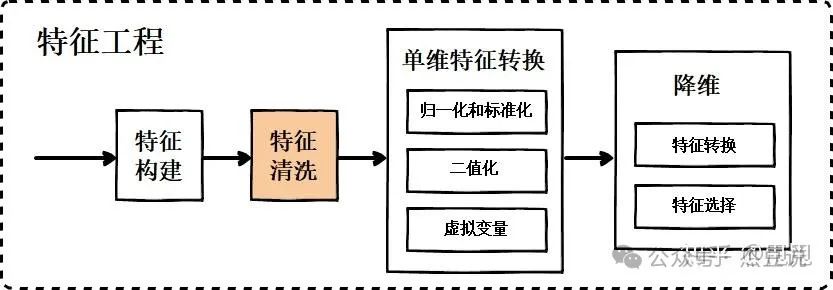
模型的学习能力很大程度上取决于我们给它提供的信息质量。如果信息选得好,模型就能学得快,预测得准;如果信息选得不好,模型就可能学不会,或者学错了。这个过程包括数据预处理、特征选择、特征构造、特征转化、降纬 等等,比如训练一个颜值打分模型,训练数据是一堆照片,那么特征的工程就是提取眼睛、鼻子、嘴巴的位置、构造出新的特征比如面部比例数据、并选择具体哪个面部特征的颜值权重更高 等等。
十八、超参数调优
超参数是在开始训练之前设置的参数,它们不能通过训练过程本身得到。比如决定每次训练模型时输入的数据量的“批大小”、决定每次权重更新幅度的学习率等等。如果把模型训练过程比喻成西天取经的过程,那么超参数调优就是在取经出发前,唐僧从观音或唐太宗那里获得的 通关文牒、锦襕袈裟。

十九、增强检索
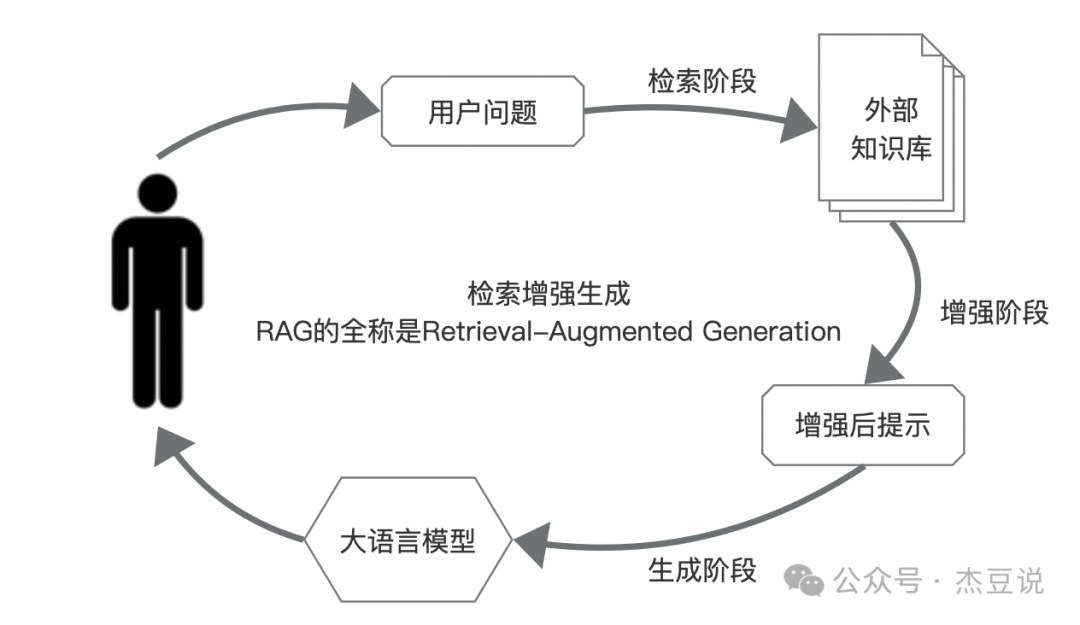
在大语言模型通常会发生“模型幻觉”的问题,就是在处理复杂事物是产生与事实不符甚至完全捏造的信息,就像说人有时候也会说梦话一样胡说八道。增强检索可以缓解这个问题,通过引入外部知识来源来提高回答问题的准确性和丰富性。以一个法律咨询的场景为例,如果用户询问关于最新税法的问题,传统的语言模型可能只能提供基于其训练数据的答案,而这些数据可能不包括最新的税法变化,这是需要增强检索的典型应用场景。
二十、通用人工智能
马斯克在24年4月时说:比人类更聪明的AGI将在两年内实现。通用人工智能是指不需要人为干预而可以自我学习、自我调整从而完全像人类一样可以执行原本只有人可以从事的任务,甚至机器人可以自行进行科学理论探索。这将是地球智能发展的奇点。
本文由 @李文杰 原创发布于人人都是产品经理。未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


