
 起点课堂会员权益
起点课堂会员权益AI 产品经理的必修课:构建自动化评估体系
LLM 产品研发中调 Prompt 常出现 “按下葫芦浮起瓢” 的问题,而靠 “凭感觉测” 的体感测试,因大模型的非确定性和 Prompt 的高度耦合性,根本无法保障模型效果。本文直击这一痛点,详解 AI 产品自动化评估体系的从 0 到 1 搭建方法,包括构建黄金数据集、设计评估指标、引入 LLM-as-a-Judge 三大核心步骤,还阐述了产品经理在评估体系中的核心价值与进阶工作,指出这套体系是告别玄学调优、构建 AI PM 认知护城河的关键,更是 AI 产品科学迭代的基础。

你有没有过这种经历:你为了修复 Case A,调整了一句 Prompt,结果 Case A 修好了,原本完美的 Case B、C、D 却突然崩了?这种按下葫芦浮起瓢的“打地鼠”游戏,在过去两年的 LLM 产品研发中,简直是我的噩梦。
在传统软件开发里,改一行代码,有单元测试(Unit Test)兜底;但在 AI 开发里,很多人还在靠“Vibe Check”——也就是俗称的“凭感觉测”。随便问几个问题,看着挺像回事,就觉得稳了。
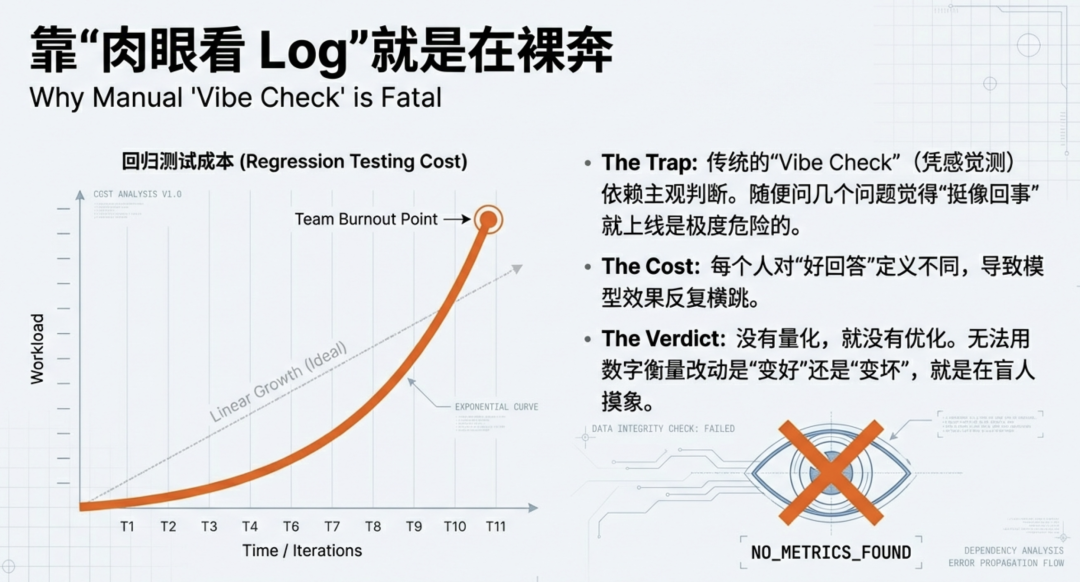
朋友们,这是在裸奔。
今天我想和大家聊点硬核的:如何告别玄学调优,构建一套属于 AI 产品的自动化评估体系。 这不仅是技术问题,更是 AI 产品经理必须建立的认知护城河。
01 为什么“体感测试”会害死人?
做 AI 产品久了,你会发现大模型有一个极其讨厌的特性:非确定性。
以前做 App,你点击按钮 A,它必然跳转页面 B。但在 LLM 里,你输入同样的 Prompt,早上的回答和晚上的回答可能就不一样。
更可怕的是,Prompt 是一个高度耦合的混沌系统。你为了让它在“写周报”场景下更严肃一点,加了一句指令,结果它在“写情书”场景下也变得像个教导主任。
靠人工测试是测不过来的。我曾经带过一个客服机器人项目,初期我们靠三个实习生每天肉眼看 Log。后来随着 Prompt 版本迭代,回归测试的工作量呈指数级上升。实习生累到离职,而由于每个人对“好回答”的定义不同(主观性太强),导致我们的模型效果在几个版本间反复横跳。
那时我意识到:没有量化,就没有优化。 如果无法用数字衡量你的 Prompt 改动是“变好”还是“变坏”,那你就是在盲人摸象。
02 从 0 到 1:搭建你的评估体系
很多人一听到评估,觉得那是算法工程师的事。大错特错。
定义什么是“好结果”,是产品经理的核心天职。 算法关注的是 Loss 值的下降,而 PM 关注的是用户体验的交付。
构建一个最基础的自动化 Eval 体系,其实只需要三步。
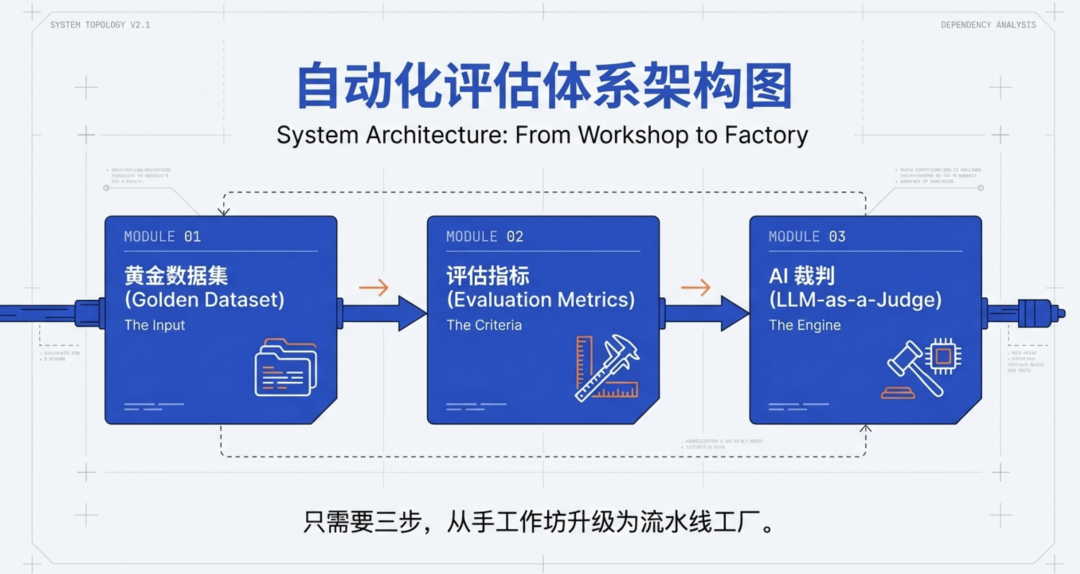
第一步:构建“黄金数据集”
这是所有评估的基石。很多团队做不好评估,是因为手里根本没有“真题集”。
不需要上来就搞几万条数据,那是大厂基建组的事。作为业务 PM,你只需要准备 50-100 条最具代表性的 Case。
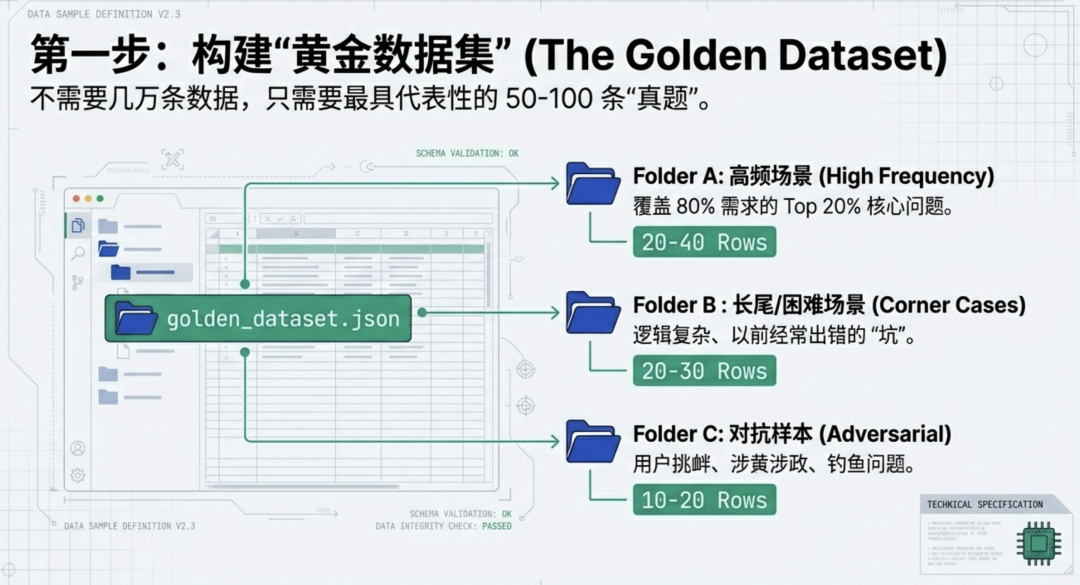
这些 Case 应该包含:
- 高频场景: 用户最常问的 20% 的问题。
- 长尾/困难场景: 以前经常出错的、这就逻辑复杂的坑。
- 对抗样本: 用户故意挑衅、涉黄涉政的钓鱼问题。
关键在于标准答案的制定。
对于提取类任务(比如从简历里提取电话号码),标准答案是唯一的。
对于生成类任务(比如写一首诗),标准答案可能是一个“参考范文”,或者是一组“必须包含的要点”。
第二步:设计评估指标
有了题,怎么打分?这里分为两类指标:

1. 确定性指标
这部分好做,写代码正则匹配就行。
- 格式合规率: 要求输出 JSON,它有没有输出 Markdown?
- 拒识率: 遇到敏感词,是否触发了兜底话术?
- 包含率: 比如要求必须包含“由于系统维护”这几个字,它漏没漏?
2. 模糊性指标
这部分是 AI PM 最头疼的。回答“准确吗?”、语气“友好吗?”、逻辑“通顺吗?”
以前这些只能靠人看,但现在,我们有了魔法:LLM-as-a-Judge(用大模型当裁判)。
第三步:引入 LLM-as-a-Judge
这是目前硅谷最主流的实战流派。既然人看太慢,为什么不让 GPT-5 来帮我们看?
简单来说,就是写一段专门的 Prompt,告诉 GPT-5:“你是一个严格的考官,请根据【问题】、【模型回答】和【参考答案】,给【模型回答】打分(1-5分),并给出理由。”

很多人质疑:用 AI 测 AI,这不是套娃吗?准吗?
根据我的实测,在复杂的语义理解场景下,GPT-5 作为裁判的判决结果,与人类专家的一致性通常能达到 80%-90% 以上。
更重要的是,它快,而且不知疲倦。
你可以配置这样的自动化流:
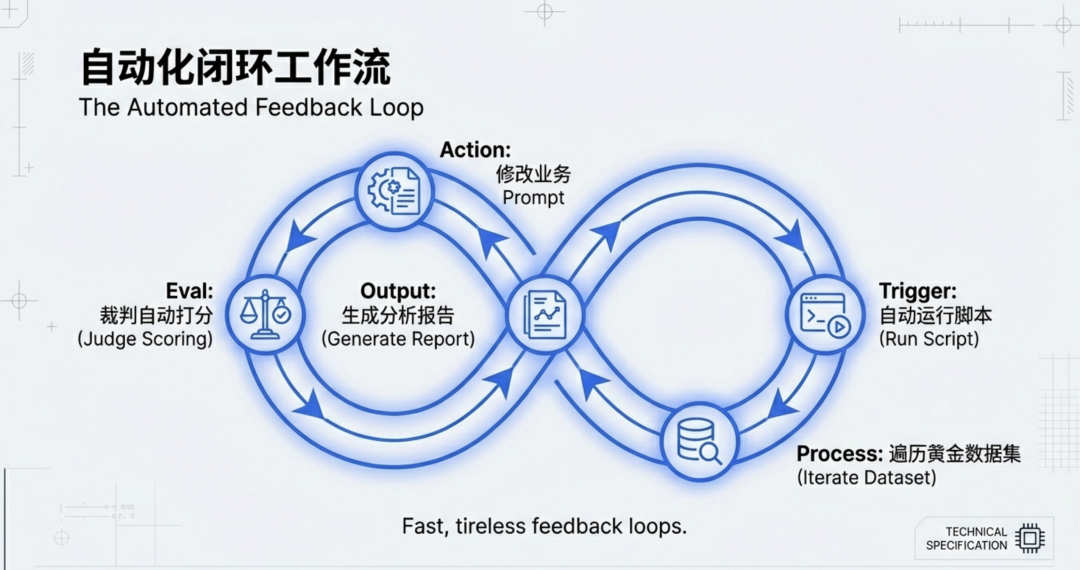
- 修改了业务 Prompt。
- 脚本自动跑一遍那 100 条黄金数据集。
- GPT-5 裁判自动打分。
03 进阶:PM 如何在评估中发挥价值?
搭建了系统(通常可以使用 LangSmith, Promptfoo 等工具,或者让研发写个简单的 Python 脚本),PM 的工作才刚刚开始。
1. 维护“裁判的价值观”
LLM-as-a-Judge 最难的地方在于,你需要把脑子里的“好标准”显性化。

如果你发现裁判打分和你心里想的不一样,通常不是裁判傻,而是你没把标准定义清楚。
你需要不断调试 Judge Prompt,比如明确告诉它:“只要没有提到退货政策,无论语气多好,都只能给 1 分。”
这个过程,本质上是在通过 prompt 将业务规则代码化。
2. 关注 Bad Case 的这一公里
自动化评分不是为了看一个总分自嗨的。评估跑完后,生成的“错题本”才是金矿。

PM 每天的工作重点,应该从“想新功能”,转移到“分析错题”上来。
- 是 Prompt 指令不清晰?
- 是 RAG 检索到的上下文(Context)是错的?
- 还是模型本身的能力天花板?
针对每一类错误,制定针对性的优化策略。这才是 AI 产品迭代的闭环。
04 写在最后
在 AI 时代,产品经理的门槛变了吗?
有人说变低了,因为不用画复杂的原型图了,对着聊天框就能设计产品。
我觉得是变高了。因为我们失去了“确定性”这个拐杖。
评估体系让我们敢于重构 Prompt,因为我们知道有测试网兜底;让我们敢于尝试更便宜的小模型,因为我们能监控效果的折损率;也让我们面对老板及客户的质疑时,能拿出冷冰冰但有说服力的数据,而不是苍白的“我觉得挺好”。
从今天开始,哪怕先在 Excel 里整理出 20 条黄金 Case,也是构建你职业护城河的第一步。
在这个狂奔的时代,“慢”,有时候就是“快”。
本文由人人都是产品经理作者【骆齐】,微信公众号:【骆齐】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


