
 起点课堂会员权益
起点课堂会员权益量化研究工具的“平民化”:一个产品经理的开源实践思考
金融从业者正陷入工具困境:昂贵专业软件与简陋免费平台间的断层,让研究效率大打折扣。FactorHub以开源量化平台破局,用工业化流水线思维重构研究流程,将AI编程与社区共创融入产品基因。本文揭秘如何通过四大核心支柱与三层架构设计,打造真正降低门槛却不失专业深度的研究工具,展现产品经理在技术现实与理想之间的关键抉择。

凌晨两点,我盯着屏幕上的三份文档发愣。
左边是某国产量化平台的报价单——年费32万,功能模块还要额外付费。
中间是Excel表格,里面是从五个不同数据源导出的股票信息,格式各异,需要手动清洗。
右边是实习生提交的因子分析报告,结论只有一行:“IC值0.05,建议进一步观察。”
那一刻,我意识到一个残酷的事实:我们金融从业者,正在被自己使用的工具“反向驯化”。
工具本应放大我们的能力,现在却成了我们能力的瓶颈。
我是一个在金融行业做了八年产品经理的人。每天的工作,就是设计能解决实际问题的产品。而FactorHub这个项目,始于一个朴素的产品经理直觉:
如果工具成了阻碍,那就重新设计工具。
一、被忽视的“工具断层”
先讲三个真实场景。
场景一:成本断层
一家小型私募的研究员,月薪两万。他需要使用的专业量化软件,年费三十万。公司不会给他买,他只能自己想办法——在聚宽、优矿这些免费平台上反复横跳,数据不完整、功能受限、计算慢。
场景二:能力断层
一个金融专业的研究生,懂CAPM模型,懂因子投资理论。但他不会写Python,不会处理数据格式,不会调API。他的知识停留在教科书上,无法落地。
场景三:流程断层
一个资深研究员,上午用Wind导出数据,中午用Python清洗,下午用聚宽计算因子,晚上用Excel画图。一天时间,80%花在“搬运数据”上,20%才是真正的“研究”。
这三个场景,指向同一个问题:量化研究工具市场,存在严重的“断层”。
一端是功能强大但价格昂贵的专业软件,另一端是免费但功能简陋的在线平台。中间,是一片巨大的空白——足够专业、足够易用、足够便宜的工具,几乎不存在。
而这片空白,恰好是大多数量化研究者所在的位置。
二、FactorHub的产品定位:做“断层”的填补者
作为产品经理,我的第一反应是:这个“断层”有没有商业价值?
当然有。但我不想做另一个收费软件。
我想做的是更底层的事:重新定义量化研究工具的产品形态。
FactorHub的核心定位,不是“又一个量化软件”,而是“量化研究的工业化流水线”。
什么意思?
传统的研究流程,是手工作坊模式——研究员既是设计师,又是工人,还要自己制造工具。
FactorHub想做的,是把“制造工具”的活接过来,让研究员只需要做一件事:思考和研究。
这不是简化,这是分工。
就像工业革命把工匠从繁琐的体力劳动中解放出来一样,FactorHub想把研究者从繁琐的“数据处理劳动”中解放出来。
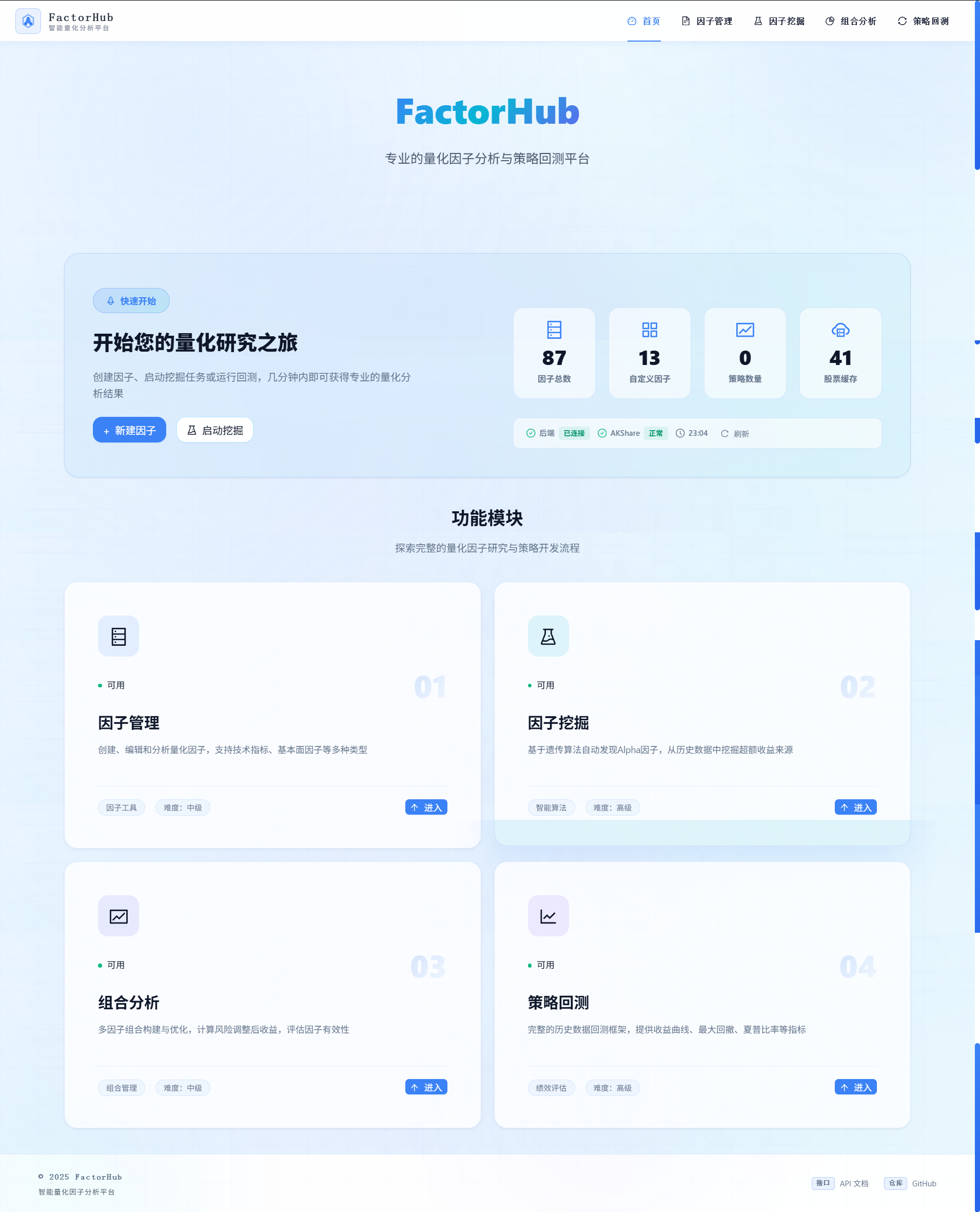
基于这个理念,FactorHub现在已经发展成一个完整的现代化量化因子分析平台,专为中国A股市场设计。它的核心价值体现在四个支柱:
- 完整因子生命周期管理——从因子创建、验证、分析到部署的全流程支持
- 科学的因子评估体系——IC/IR分析、单调性检验、换手率分析等专业指标
- 智能因子挖掘——基于遗传算法的自动因子挖掘,发现阿尔法信号
- 专业回测引擎——支持多因子组合、策略对比、性能归因分析
三、产品设计的三个底层原则
设计FactorHub时,我脑子里有三个挥之不去的问题:
第一个问题:谁才是真正的用户?
不是公司采购部门,不是技术负责人,而是每天坐在电脑前做研究的那个人。
他可能是个刚入行的研究员,可能是个独立投资者,可能是个金融专业的学生。他的共同点是:懂金融,但未必精通编程;有时间做研究,但不想把时间浪费在工具上。
所以,FactorHub的第一个设计原则:用户门槛必须低到可以忽略不计。
你不会写Python?没问题。我们有预设的因子库,点一下就能计算。
你不懂数据格式?没问题。我们支持各种常见的数据源,自动转换。
你只想看结果?没问题。一键生成可交互的报告,所有图表都能拖拽、缩放、下载。
第二个问题:什么是真正的“专业”?
很多人误以为,“专业”等于“复杂”。一个工具按钮越多、参数越复杂,就显得越专业。
我不这么认为。
真正的专业,是把复杂的事情简单化,同时不损失深度。
FactorHub的计算引擎,底层用了复杂的金融计量模型。但用户看到的,只是一个清晰的图表,和一句人话解释:“这个因子在过去三年表现稳定,但在市场大幅波动时可能会失效。”
这才是真正的专业——不是把用户绕晕,而是帮用户看清。
第三个问题:开源的边界在哪里?
这是我思考最多的问题。
作为产品经理,我知道开源意味着什么——放弃直接的商业收益,换取更快的迭代、更广的传播、更深的信任。
但为什么还要做?
因为量化研究的本质,是科学。
科学需要可复现、可验证、可质疑。一个闭源的、不透明的工具,无论计算结果多么“漂亮”,都缺乏科学的基础。
FactorHub选择开源,不是情怀,而是产品设计的必然选择。
- 只有开源,用户才能相信你的计算结果没有被“优化”。
- 只有开源,开发者才能理解你的设计思路,提出改进建议。
- 只有开源,这个工具才能真正成为“社区的产品”,而不是“某个人的产品”。
四、具体实现:一个产品经理的技术妥协
很多人以为,产品经理就是提需求,技术实现交给工程师。
但在FactorHub这个项目里,我既是产品经理,也是主要的开发者。这让我必须面对一个现实:产品理想和技术现实之间,永远存在妥协。
妥协一:架构设计的三层分离
我想让系统足够灵活,能够应对未来的功能扩展。技术实现上,我采用了经典的三层架构:
- 前端层:React + TypeScript + Ant Design + ECharts,提供现代交互体验
- API层:FastAPI,提供高性能的REST接口
- 业务逻辑层:因子服务、分析服务、回测服务、挖掘服务,各司其职
- 数据层:轻量级SQLite + 免费的akshare数据源 + 缓存机制
这种分层虽然增加了开发复杂度,但保证了系统的可维护性和可扩展性。
妥协二:数据源的“适配器模式”
我想支持所有的数据源——akshare、Tushare、Wind、聚宽,甚至用户自己的本地数据库。
但技术上,每个数据源的API都不一样,格式千差万别。
妥协方案是:设计一个“适配器层”。
我们定义了一套标准的数据格式。所有的外部数据源,都通过适配器转换成这套格式。这样,上层的计算逻辑可以完全统一,不受数据源影响。
代价是:每个新的数据源,都需要写一个新的适配器。
妥协三:实时交互的“分级加载”
我想实现实时的、可拖拽的交互式图表。用户拖动时间轴,图表要即时更新。
但技术上,大量历史数据的实时渲染是个性能黑洞。
妥协方案是:分级加载。
首次加载只显示概要图表,用户点击“查看详情”时,再加载详细数据。虽然牺牲了一点“即时性”,但保证了整体性能。
特别要提的是:大模型编程改变了游戏规则
作为一个产品经理,我的编码能力有限。但大模型改变了这一点。
在FactorHub的开发过程中,我大量使用了AI编程。当需要实现一个复杂的因子计算逻辑时,我不再需要逐行编写代码,而是用自然语言描述需求:
“我需要一个函数,计算股票的20日波动率因子,公式是过去20日收益率的标准差除以均值,要处理缺失值和异常值。”
十秒钟后,AI给出了完整的代码实现,还加了注释。
这让我能够专注于业务逻辑的设计,而不是陷入编码细节。我的角色从“需求转述者”变成了“架构设计师”,从“等待交付者”变成了“即时实现者”。
这不是“让AI写代码”,这是“让AI把我的业务理解翻译成代码”。
这些妥协,看似是技术问题,实则是产品体验问题。
用户不关心你用了什么技术,他只关心:用起来顺不顺手,结果准不准确,速度快不快。
五、开源之后:产品如何演进?
开源一个项目,最难的不是写代码,而是建立和维护社区。
作为产品经理,我把FactorHub的GitHub仓库,当成一个“开放的产品实验室”。
- 每一个Issue,都是用户反馈。
- 每一个Pull Request,都是功能提案。
- 每一个Star,都是对产品方向的投票。
这种模式,和传统的闭源产品开发完全不同。没有明确的产品路线图,没有固定的开发周期,没有自上而下的需求管理。
有的,是无数个分散的、自发的、基于真实需求的改进建议。
有时候,这会带来混乱。一个用户想要支持美股数据,另一个用户想要增加机器学习因子,第三个用户想要优化移动端显示。
作为“产品负责人”,我的角色不再是“决策者”,而是“协调者”。
我需要判断哪些需求是普遍需求,哪些技术方案更优,哪些改进应该优先。
这很难,但很值得。
因为一个由真实用户驱动的产品,比任何产品经理闭门造车设计出来的产品,都更接近用户真实需求。
六、一些可能没什么用的产品思考
最后,分享几点零散的思考。这些思考不一定对,但都是我真实的想法。
第一,工具的价值,不在于它有多“强大”,而在于它被多少人“用起来”。
一个功能再强大的软件,如果只有少数人用,它的社会价值就有限。
FactorHub的目标,不是成为“最专业”的量化工具,而是成为“最多人用”的量化工具。
第二,降低门槛,不等于降低标准。
很多人担心,把工具做得太简单,会吸引“不专业”的用户,产生“不专业”的结果。
我的看法是:专业与否,是用户的问题,不是工具的问题。
工具的责任,是提供准确的计算、清晰的呈现。至于用户如何使用这些结果,那是用户的事。
第三,大模型编程不是替代,是“能力扩展”。
大模型没有替代我的思考,它只是把我的思考更快地变成代码。这就像有了计算器,数学家并没有失业——他们只是把时间从繁琐的计算中解放出来,去思考更深刻的数学问题。
第四,开源是一种“信任前置”。
在闭源模式下,用户要先付费,才能验证工具是否可信。
在开源模式下,用户可以先验证工具是否可信,再决定是否使用(或付费)。
这种“信任前置”,表面上增加了开发者的压力(代码要经得起审视),实际上降低了用户的决策成本。
第五,产品经理的终极价值,不是设计功能,而是定义问题。
FactorHub这个项目,最大的价值可能不在于它的代码,而在于它提出的问题:
- 为什么量化研究一定要这么难?
- 为什么工具一定要这么贵?
- 为什么开源不能成为一种可行的商业模式?
这些问题,比任何具体功能都重要。
写在最后
做产品经理这么多年,我有一个顽固的信念:
好的产品,应该让复杂的事情变简单,让昂贵的事情变便宜,让少数人的特权变多数人的权利。
FactorHub这个项目,就是我对这个信念的一次实践。
它不完美,有很多问题。数据源不够全,计算性能不够快,界面不够美观。
但它在尝试回答一个问题:我们能不能用开源+大模型的方式,重新设计量化研究的工具链?
我不知道答案。
但我知道,这个问题值得问。
如果你也是一个产品经理,也在思考工具、效率、开源、AI编程这些问题,欢迎来GitHub看看FactorHub的代码,或者直接和我聊聊。
我们可以一起,把这个问题问得更好。
项目地址: https://github.com/cn-vhql/FactorHub
(任何关于产品、量化、开源、AI编程的讨论,都欢迎在评论区或GitHub进行。)
本文由 @红岸小兵 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!


