
 起点课堂会员权益
起点课堂会员权益融资2000万、OpenAI亲自下场合作,AI营销赛道值得关注的一匹黑马出现了
2000万美元融资的Minerva正在颠覆营销数据的使用方式。这款AI营销平台通过Agentic Data Engineer和Agentic Data Scientist两大核心系统,让营销人员只需用自然语言下达指令,就能在24小时内完成从数据清洗到预测建模的全流程。本文深度解析这个将金融数据处理方法论迁移到营销领域的产品如何解决行业核心痛点。

还在为等待数据团队出报表而烦恼吗?想象一下,你是一家消费品牌的营销负责人,你只需要用自然语言问一句:”找出未来 30 天内最可能下单的用户”,系统就自动生成了一个预测模型,直接给你一份可以投放的用户名单。不需要等数据工程师清洗数据,不需要等数据科学家跑模型,不需要等分析师出报告。这不是科幻场景,而是刚刚完成 2000 万美元融资的 Minerva 正在实现的现实。
2026 年 6 月 9 日,Minerva 正式公开上线了他们的 AI 营销平台,同时宣布完成了这轮融资。投资方名单相当亮眼:The General Partnership、8VC、Lingotto Innovation、Topology Ventures,还有 NBA 官方投资部门 NBA Investments。与此同时,他们还公布了与 OpenAI 的深度合作关系,直接调用 GPT-5.5 这样的前沿大模型来驱动平台的核心能力。这套组合拳背后,是他们对一个问题的坚定判断:消费者营销的核心瓶颈,从来不是缺少数据,而是无法真正用好数据。
营销人每天面对的真实困境
我接触过不少做消费者营销的团队,他们的烦恼几乎都一样:数据有,但用不上。
一家中等规模的消费品牌,可能同时有电商平台的用户行为数据、CRM 里的客户记录、广告平台的点击数据、线下门店的购买记录。这些数据分散在不同系统里,格式不统一,字段定义也不一样。想把它们整合起来做一个像样的用户分析,光是数据清洗和字段对齐,就得让数据工程师花上好几周。等数据整理好了,市场可能早就变了,那个分析结论的参考价值也打了折扣。
这是现代营销最核心的矛盾:品牌手里有大量第一方数据,但这些数据的价值被碎片化和处理成本给死死锁住了。营销团队不缺数据,缺的是把数据变成可行动洞察的速度和能力。大量本来可以变成精准投放决策的机会,就这样白白流失了。
更深层的问题是人力结构。在很多公司里,营销部门、数据团队和技术团队之间存在天然的协作摩擦。营销人有想法,但不懂数据;数据工程师懂技术,但不理解业务逻辑;分析师能出报告,但速度跟不上市场节奏。这种结构性摩擦,让大量潜在的营销价值永远停留在”还在对接中”的状态。Minerva 的创始人们把这个问题看得非常清楚,这也是他们决定创业的起点。
他们为什么是做这件事的合适团队
Minerva 的三位联合创始人 Jackson Engles、Daniel Saedi 和 Matthew Joseph 在伯克利认识,毕业后分别进入了 Lazard、Bridgewater 和 Citadel 工作。这个背景值得细想。
Saedi 和 Joseph 在金融机构工作期间,长期使用替代数据做量化交易。他们亲身经历了消费者数据的商业价值有多高,也亲眼见证了把碎片化、不一致的数据集变成可靠洞察有多难。这段经历给了他们一个独特视角:消费者数据不是没价值,而是大多数公司根本没有能力把它用好。他们创立 Minerva,本质上是在把金融行业处理替代数据的方法论,迁移到消费者营销领域。
我觉得这个创业背景很关键。很多 AI 营销工具的创始人来自营销或产品背景,对用户需求了解得很深,但对数据工程和模型构建的理解相对有限。Minerva 的团队恰好相反,他们从数据和模型出发去解决营销问题。这种视角差异,正是他们能把数据工程和数据科学这两件最难的事情做成 AI agent 产品的核心原因。他们知道问题真正卡在哪里,所以解法才有针对性。
团队的 AI 技术积累也不弱。他们和 OpenAI 建立了深度合作关系,OpenAI 方面不只是提供模型 API,而是直接参与了 Agentic Data Engineer 和 Agentic Data Scientist 这两个核心系统的研发。OpenAI 的研究员表示,Minerva 做的工作在推动前沿模型在数据工程和数据科学挑战上的能力边界。这种合作深度,远不是普通的商业采购关系。
Minerva 到底在做什么
Minerva 的平台围绕两个核心 AI agent 系统构建:Agentic Data Engineer 和 Agentic Data Scientist。听起来有点技术感,但我来说说它们实际在做什么。
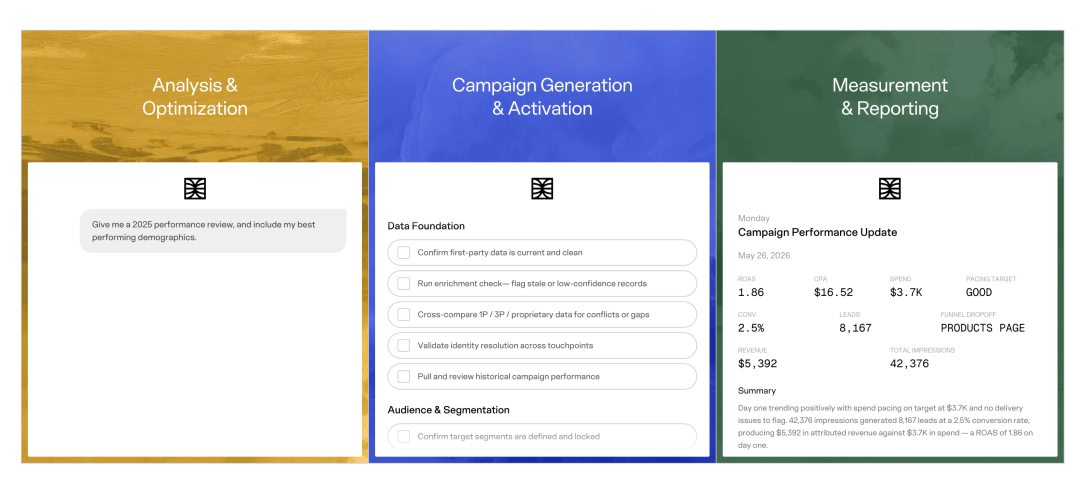
Agentic Data Engineer 负责的是数据整合这件最脏最累的活。它会自动分析品牌第一方数据的结构,识别各个字段的含义,编写数据转换的 SQL 语句,然后验证输出结果是否正确。过去这些工作需要有经验的数据工程师花上好几周时间手动完成——理解数据结构、写转换逻辑、排查错误、反复验证。Minerva 的 agent 把这个周期压缩到了几个小时。他们明确承诺:从接入平台到开始使用核心功能,只需要 24 小时。
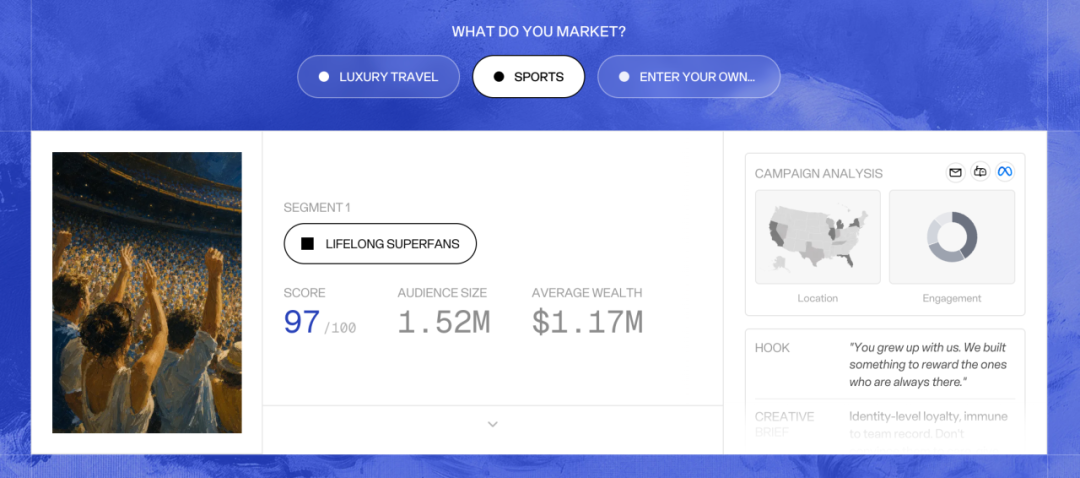
Agentic Data Scientist 更有趣。它让完全没有机器学习背景的营销人,可以用自然语言来创建和部署预测模型。你可以直接输入:”找出在未来 30 天内可能预订豪华房产的用户。” 系统就会自动生成、验证并部署一个预测模型,输出一份可以直接用于投放的用户名单。不需要懂 Python,不需要懂算法,就像在跟一个资深数据科学家直接对话,说清楚你要什么,结果自然出来。
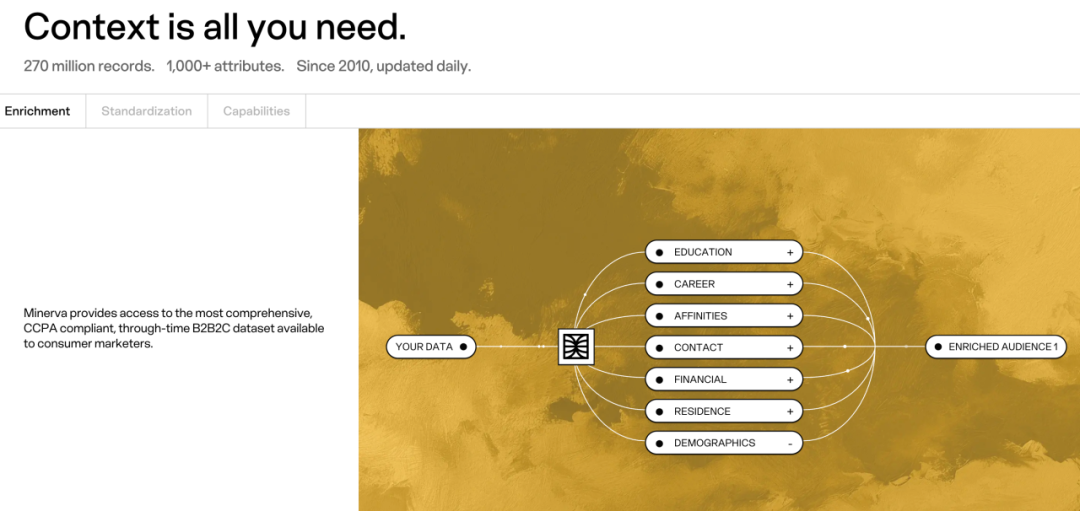
数据整合和建模之外,Minerva 还会用他们自己的专有身份图谱进一步丰富这些数据。这个图谱包含超过 1000 个维度的属性,覆盖人口统计、财务状况、房产情况、兴趣偏好和联系方式等信息。他们用的都是公开数据或经过用户授权的数据,严格遵循 CCPA 隐私法规和 SOC2 安全框架,同时明确承诺不同品牌的数据绝对不混合处理。
整个平台的逻辑是一条完整的链路:先让数据变干净、变统一,再用第三方数据丰富它,然后让 AI agent 在这个基础上做分析、建模、创建投放受众、优化活动,最后自动生成详细的绩效报告。营销人只需要设定目标,剩下的交给 agent 执行。Minerva 把这个转变概括得很准确:从”提供工作流”转向”提供结果”。
数据有了,结果怎么样
有人会问,这些 AI agent 真的有用吗?我看了他们早期客户的数据,结果确实很亮眼。
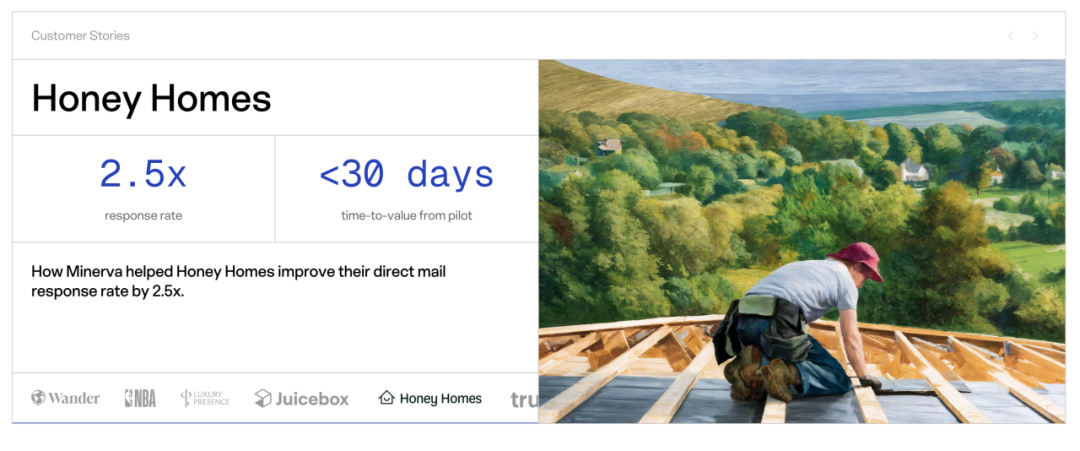
在付费媒体方面,Minerva 帮助品牌把广告投资回报率提升了 3.4 倍。在直邮营销方面,营销合格线索的创建效率提升了 2.5 倍。这两个数字放在任何一个营销团队面前,都会引起高度重视。
他们的早期客户名单也很说明问题:NBA、Trust & Will、Wander、Luxury Presence、Juicebox。这些都是在各自细分市场里有影响力的品牌。特别值得关注的是 NBA,他们不只是客户,还是 Minerva 的投资方。Minerva 在帮助 NBA 识别如何加深球迷互动方面做了专门工作。当一个客户愿意同时投钱进来,通常意味着他们真的看到了实质性价值,而不只是在试用一个产品。
Wander 的 CMO Kyle Tibbits 说了一句话让我印象很深,他说 Minerva 从根本上改变了他思考如何建立营销团队的方式。这种评价不是在说某个功能有多好用,而是在说整个团队的组织方式发生了变化。这是一个比较高维的认可了——不是”这个工具帮我省了时间”,而是”我对营销这件事的理解变了”。
还有 Spendflo 的联合创始人兼 CTO Ajay Vardhan 也提到,Adopt 让他们更快进入市场,同时完全控制了 AI 的行为,并且不需要重建任何已有系统,直接适配现有基础设施。这个反馈指向了一个很重要的产品价值:不制造新的技术负担。对于已经有一堆工具要管理的营销团队来说,这一点非常关键。
为什么是 2026 年,为什么是现在
Minerva 在公告里提到了三个他们认为在 2026 年同时成熟的条件,我觉得这个判断非常有洞察力,值得仔细拆解。
第一个条件,是前沿大模型终于有能力协调复杂的多步骤工作流。这不是一件小事。过去两三年,大模型发展很快,但真正能够可靠地执行涉及多工具、多步骤的复杂任务,是最近才开始变得稳定可信的。Minerva 与 OpenAI 合作用 GPT-5.5 驱动他们的核心 agent,这不是随便选个合作伙伴贴个 AI 标签,而是在赌一个技术临界点——前沿模型的能力已经到了可以真正完成数据工程和数据科学任务的程度,而不只是给出一个看起来合理但实际不可靠的输出。
第二个条件,是消费品牌积累的第一方数据越来越多,但真正能用好这些数据的能力严重滞后。这个现象我相信很多人都有感受。品牌每天都在产生大量用户数据,但大部分数据就静静地躺在数据库里,既没有被系统分析,也没有被充分利用。数据量和数据洞察之间存在一个越来越大的鸿沟,而这个鸿沟的核心不是数据不够,是处理数据的成本太高、速度太慢。品牌反而因为数据太多而感到窒息。
第三个条件,是 CFO 们对营销支出的 ROI 要求越来越严格。经济环境的压力让每一分营销预算都必须说清楚贡献了什么价值。这直接催生了营销团队对更精准、更可量化工具的强烈需求。Minerva 的整个产品逻辑——从数据整合到预测建模到活动报告——都在服务这个诉求:让每一笔营销支出都能被测量、被优化。
这三个条件同时成立,形成了一个稀有的机会窗口。我认为 Minerva 的时机判断是准确的。他们在 2023 年开始构建基础,用三年时间打磨出核心能力,在条件成熟的 2026 年公开上线。这个节奏本身就说明了创始团队对这件事的理解深度。
这个赛道的真实竞争格局
当然,Minerva 进入的不是一个空白市场。他们面对的竞争对手包括 Segment、mParticle、Hightouch、Simon Data 这些已经在客户数据平台领域深耕多年的玩家。这些公司帮助很多企业建立了数据收集、整合和激活的基础设施,在市场上有稳固的客户关系和技术积累。
Minerva 的差异化主张在于,他们不只是帮你存数据、传数据,而是用 AI agent 直接替你做完数据工程和数据科学的工作。如果说传统 CDP 给了你一个干净的数据仓库,Minerva 还额外给了你一个全天候在线的数据团队,而且几乎不需要持续的人工干预。这个定位如果真的能在生产环境中兑现,它竞争的维度是部署速度和运营成本,而不只是数据连接能力。
不过我也看到一个真实的挑战,那就是大多数企业已经有了某种 CDP 或数据激活工具。Minerva 必须证明它能和现有系统良好共存,或者在某些场景下完全替代它们,而不是在客户的技术栈里制造新的碎片化。这对于企业级销售来说,是一道必须过的坎。
在数据所有权、指标定义、模型可解释性这些深层问题上,一旦 AI agent 在生成数据转换逻辑和预测模型,谁来确保它的准确性?当模型出现漂移或者表现衰退时,怎么及时发现和修正?这些问题在他们现在的产品材料里还没有看到特别详细的说明。但这些会是企业客户在深度使用时必然会追问的问题,也是他们在规模化过程中需要正面回答的挑战。

我对这件事最深的感受
我一直认为,AI 在营销领域的真正价值,不是帮你写几篇广告文案,而是接管营销运营中那些大量重复的、技术性的底层工作。数据清洗、特征工程、模型训练、报表生成——这些工作占据了数据团队大量时间,但本身不创造战略价值,它们只是让战略决策成为可能的基础。而目前,这些基础工作消耗的资源,远远超过大多数公司愿意承认的程度。
Minerva 做的事,就是把这个基础工作交给 AI agent 来承担。这让营销团队可以真正把时间和精力放在更需要人类判断的事情上:理解品牌的核心用户是谁,为什么他们选择这个品牌,怎么在关键时刻和用户建立真正的情感连接,以及如何在越来越嘈杂的信息环境里讲一个更清晰、更有力的品牌故事。这些才是真正难被自动化的事,也是真正值得营销人花心思的地方。
Minerva 的投资方 Phin Barnes 说了一句话,我觉得是目前我听到的对 AI agent 竞争逻辑最清晰的表达:”AI agent 是上下文饥渴的,谁能为某个领域构建好正确的上下文,谁就赢得那个领域。” 营销的核心是理解消费者,而理解消费者的前提是能把所有关于消费者的信息整合成 AI 真正能推理的结构化知识。这才是 Minerva 真正在构建的东西,不只是一套营销工具,而是消费者理解的基础设施层。
这个方向,我认为是对的。在接下来几年里,AI agent 的能力还会持续提升,但如果没有高质量的消费者上下文作为输入,再强的模型也产生不了真正有价值的营销洞察。而构建这个上下文层,是一件需要时间积累、需要大量行业理解的事。这是 Minerva 目前在做的最难的事,也是护城河最深的事。等到更多品牌在 Minerva 的平台上跑了足够长的时间,他们的 agent 对这些品牌的用户理解会越来越深,这种积累效应会让他们越来越难以被替代。这才是这件事真正让人兴奋的地方。
本文由人人都是产品经理作者【深思圈】,微信公众号:【深思圈】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。









Minerva的差异化定位确实聪明,直接从数据工程和数据科学两大痛点切入,而不是做另一个CDP。但企业级客户对模型可解释性和异常检测的要求很高,目前产品材料里对这些深层风险的说明还不够。另一个隐患是数据安全承诺——不同品牌数据绝对不混合,但Agentic Data Engineer要分析数据结构,这个边界怎么守住,需要更透明的技术说明。