
 起点课堂会员权益
起点课堂会员权益人工智能技术落地:情感分析概述
从自然语言处理技术的角度来看,情感分析的任务是从评论的文本中提取出评论的实体,以及评论者对该实体所表达的情感倾向,自然语言所有的核心技术问题。因此,情感分析被认为是一个自然语言处理的子任务。

情感分析概述
与其他的人工智能技术相比,情感分析(Sentiment Analysis)显得有些特殊,因为其他的领域都是根据客观的数据来进行分析和预测,但情感分析则带有强烈的个人主观因素。情感分析的目标是从文本中分析出人们对于实体及其属性所表达的情感倾向以及观点,这项技术最早的研究始于2003年Nasukawa和Yi两位学者的关于商品评论的论文。
随着推特等社交媒体以及电商平台的发展而产生大量带有观点的内容,给情感分析提供了所需的数据基础。时至今日,情感识别已经在多个领域被广泛的应用。
例如:
- 在商品零售领域,用户的评价对于零售商和生产商都是非常重要的反馈信息,通过对海量用户的评价进行情感分析,可以量化用户对产品及其竞品的褒贬程度,从而了解用户对于产品的诉求以及自己产品与竞品的对比优劣。
- 在社会舆情领域,通过分析大众对于社会热点事件的点评可以有效的掌握舆论的走向。
- 在企业舆情方面,利用情感分析可以快速了解社会对企业的评价,为企业的战略规划提供决策依据,提升企业在市场中的竞争力。
- 在金融交易领域,分析交易者对于股票及其他金融衍生品的态度,为行情交易提供辅助依据。
目前,绝大多数的人工智能开放平台都具备情感分析的能力,如图所示:是玻森中文语义开放平台的情感分析功能演示,可以看出除了通用领域的情感分析外,还有汽车、厨具、餐饮、新闻和微博几个特定领域的分析。

玻森中文语义开放平台的情感分析示例
那么到底什么是情感分析呢?
从自然语言处理技术的角度来看,情感分析的任务是从评论的文本中提取出评论的实体,以及评论者对该实体所表达的情感倾向,自然语言所有的核心技术问题,例如:词汇语义,指代消解,此役小气,信息抽取,语义分析等都会在情感分析中用到。
因此,情感分析被认为是一个自然语言处理的子任务,我们可以将人们对于某个实体目标的情感统一用一个五元组的格式来表示:(e,a,s,h,t)
- e表示情感分析的目标实体,可以是一个具体的实例,也可以是一个类,但必须是唯一的对象。
- a表示实体e中一个观点具体评价的属性。
- s表示对实体e的a属性的观点中所包含的情感,通常来讲会分为正向褒义、负向贬义和中性三种分类。也可以通过回归算法转化为1星到5星的评价等级。
- h是情感观点的持有者,有可能是评价者本人,也有可能是其他人。
- t是观点发布的时间。
以图为例,e是指某餐厅,a为该餐厅的性价比属性,s是对该餐厅的性价比表示了褒义的评价,h为发表评论者本人,t是19年7月27日。所以这条评论的情感分析可以表示为五元组(某餐厅,性价比,正向褒义,评论者,19年7月27日)。

用户对某餐厅的评价
情感分析根据处理文本颗粒度的不同,大致可以分为三个级别的任务,分别是篇章级、句子级和属性级。
我们分别来看一下:
1. 篇章级情感分析
篇章级情感分析的目标是判断整篇文档表达的是褒义还是贬义的情感,例如一篇书评,或者对某一个热点时事新闻发表的评论,只要待分析的文本超过了一句话的范畴,即可视为是篇章级的情感分析。
对于篇章级的情感分析而言有一个前提假设,那就是全篇章所表达的观点仅针对一个单独的实体e,且只包含一个观点持有者h的观点。
这种做法将整个文档视为一个整体,不对篇章中包含的具体实体和实体属性进行研究,使得篇章级的情感分析在实际应用中比较局限,无法对一段文本中的多个实体进行单独分析,对于文本中多个观点持有者的观点也无法辨别。
例如评价的文本是:“我觉得这款手机很棒。”
评价者表达的是对手机整体的褒义评价,但如果是:“我觉得这款手机拍照功能很不错,但信号不是很好”这样的句子,在同一个评论中出现了褒义词又出现了贬义词,篇章级的分析是无法分辨出来的,只能将其作为一个整体进行分析。
不过好在有很多的场景是不需要区分观点评价的实体和观点持有者,例如:在商品评论的情感分析中,可以默认评论的对象是被评论的商品,评论的观点持有者也是评论者本人。
当然,这个也需要看被评论的商品具体是什么东西,如果是亲子旅游这样的旅游服务,那么评论中就很有可能包含一个以上的观点持有者。 在实际工作中,篇章级的情感分析无法满足我们对于评价更细致,如果需要对评论进行更精确,更细致的分析,我们需要拆分篇章中的每一句话,这就是句子级的情感分析研究的问题。
2. 句子级情感分析
与篇章级的情感分析类似,句子级的情感分析任务是判断一个句子表达的是褒义还是贬义的情感,虽然颗粒度到了句子层级,但是句子级分析与篇章级存在同样的前提假设是,那就是一个句子只表达了一个观点和一种情感,并且只有一个观点持有人。
如果一个句子中包含了两种以上的评价或多个观点持有人的观点,句子级的分析是无法分辨的。好在现实生活中,绝大多数的句子都只表达了一种情感。
既然句子级的情感分析在局限性上与篇章级是一样的,那么进行句子级的情感分析意义何在呢?
关于这个问题,需要先解释一下语言学上主观句与客观句的分别。在我们日常用语当中,根据语句中是否带有说话人的主观情感可以将句子分为主观句和客观句,例如:“我喜欢这款新手机。”就是一个主观句,表达了说话人内心的情感或观点,而:“这个APP昨天更新了新功能。”则是一个客观句,陈述的是一个客观事实性信息,并不包含说话人内心的主观情感。
通过分辨一个句子是否是主观句,可以帮助我们过滤掉一部分不含情感的句子,让数据处理更有效率。
但是在实操过程中,我们会发现这样的分类方法似乎并不是特别准确,因为一个主观句也可能没有表达任何的情感信息,知识表达了期望或者猜测。例如:“我觉得他现在已经在回家的路上了。”这句话是一个主观句,表达了说话人的猜测,但是并没有表达出任何的情感。
而客观句也有可能包含情感信息,表明说话者并不希望这个事实发生,例如:“昨天刚买的新车就被人刮花了。”这句话是一个客观句,但结合常识我们会发现,这句话中其实是包含了说话人的负面情感。
所以,仅仅对句子进行主客观的分类还不足以达到对数据进行过滤的要求,我们需要的是对句子是否含有情感信息进行分类。如果一个句子直接表达或隐含了情感信息,则认为这个句子是含有情感观点的,对于不含情感观点的句子则可以进行过滤。
目前对于句子是否含有情感信息的分类技术大多都是采用有监督的学习算法,这种方法需要大量的人工标注数据,基于句子特征来对句子进行分类。
总之,我们可以将句子级的情感分析分成两步:
- 第一步是判断待分析的句子是否含有观点信息;
- 第二步则是针对这些含有观点信息的句子进行情感分析,发现其中情感的倾向性,判断是褒义还是贬义。
关于分析情感倾向性的方法与篇章级类似,依然是可以采用监督学习或根据情感词词典的方法来处理,我们会在后续的小节详细讲解。句子级的情感分析相较于篇章级而言,颗粒度更加细分,但同样只能判断整体的情感,忽略了对于被评价实体的属性,同时它也无法判断比较型的情感观点。
例如:“A产品的用户体验比B产品好多了。”对于这样一句话中表达了多个情感的句子,我们不能将其简单的归类为褒义或贬义的情感,而是需要更进一步的细化颗粒度,对评价实体的属性进行抽取,并将属性与相关实体之间进行关联,这就是属性级情感分析。
3. 属性级情感分析
上文介绍的篇章级和句子级的情感分析,都无法确切的知道评价者喜欢和不喜欢的具体是什么东西,同时也无法区分对某一个被评价实体的A属性持褒义倾向,对B属性却持贬义倾向的情况。但在实际的语言表达中,一个句子中可能包含了多个不同情感倾向的观点。
例如:“我喜欢这家餐厅的装修风格,但菜的味道却很一般。”类似于这样的句子,很难通过篇章级和句子级的情感分析了解到对象的属性层面。
为了在句子级分析的基础上更加细化,我们需要从文本中发现或抽取评价的对象主体信息,并根据文本的上下文判断评价者针对每一个属性所表达的是褒义还是贬义的情感,这种就称之为属性级的情感分析。
属性级的情感分析关注的是被评价实体及其属性,包括评价者以及评价时间,目标是挖掘与发现评论在实体及其属性上的观点信息,使之能够生成有关目标实体及其属性完整的五元组观点摘要。
具体到技术层面来看,属性级的情感分析可以分为以下6个步骤:
- 实体抽取和消解:抽取文档中所有涉及到实体的表达语句,并使用聚类方法将同一个实体的表达聚为一类,每一类都对应唯一的一个实体。
- 属性抽取和消解:抽取文档中所有实体的属性,并把这些属性进行聚类,每个属性类别对应对象实体唯一的一个属性。
- 观点持有者抽取和消解:抽取文档中观点的持有者,并将持有者进行聚类,每个观点持有者类别对应唯一的一个观点持有者。
- 时间抽取和标准化:抽取每个观点的发布时间,并把不同时间的格式进行标准化。
- 属性的情感分类和回归:对具体的属性进行情感分析,判断它是褒义、贬义还是中性情感,或者通过回归算法给属性赋予一个数值化的情感得分,例如1至5分。
- 生成观点五元组:使用任务1-6的结果构造文档中所有观点的五元组。
关于文本中的实体抽取和指代消解问题,我们已经在知识图谱的相关章节中做了介绍,这里就不再赘述。针对篇章级、句子级、属性级这三种类型的情感分析任务,人们做了大量的研究并提出了很多分类的方法,这些方法大致可以分为基于词典和基于机器学习两种,下面我们进行详细的讲解。
基于词典的情感分析
做情感分析离不开情感词,情感词是承载情感信息最基本的单元,除了基本的词之外,一些包含了情感含义的短语和成语我们也将其统称为情感词。基于情感词典的情感分析方法,主要是基于一个包含了已标注的情感词和短语的词典,在这个词典中包括了情感词的情感倾向以及情感强度,一般将褒义的情感标注为正数,贬义的情感标注为负数。
具体的步骤如图所示,首先将待分析的文本先进行分词,并对分词后的结果做去除停用词和无用词等文本数据的预处理。然后将分词的结果与情感词典中的词进行匹配,并根据词典标注的情感分对文本进行加法计算,最终的计算结果如果为正则是褒义情感,如果为负则是贬义情感,如果为0或情感倾向不明显的得分则为中性情感或无情感。

基于词典的情感分析流程
情感词典是整个分析流程的核心,情感词标注数据的好坏直接决定了情感分类的结果,在这方面可以直接采用已有的开源情感词典。例如:BosonNLP基于微博、新闻、论坛等数据来源构建的情感词典,知网(Hownet)情感词典,台湾大学简体中文情感极性词典(NTSUSD),snownlp框架的词典等,同时还可以使用哈工大整理的同义词词林拓展词典作为辅助,通过这个词典可以找到情感词的同义词,拓展情感词典的范围。
当然,我们也可以根据业务的需要来自己训练情感词典,目前主流的情感词词典有三种构建方法:人工方法、基于字典的方法和基于语料库的方法。
对于情感词的情感赋值,最简单的方法是将所有的褒义情感词赋值为+1,贬义的情感词赋值为-1,最后进行相加得出情感分析的结果。但是这种赋值方式显然不符合实际的需求,在实际的语言表达中,存在着非常多的表达方式可以改变情感的强度,最典型的就是程度副词。
程度副词分为两种:
一种是可以加强情感词原本的情感,这种称之为情感加强词,例如“很好”相较于“好”的情感程度会更强烈,“非常好”又比“很好”更强。另外一种是情感减弱词,例如“没那么好”虽然也是褒义倾向,但情感强度相较于“好”会弱很多。如果出现了增强词,则需要在原来的赋值基础上增加情感得分,如果出现了减弱词则需要减少相应的情感得分。
另一种需要注意的情况是否定词,否定词的出现一般会改变情感词原本的情感倾向,变为相反的情感,例如“不好”就是在“好”前面加上了否定词“不”,使之变成了贬义词。
早期的研究会将否定词搭配的情感词直接取相反数,即如果“好”的情感倾向是+1,那么“不好”的情感倾向就是-1。但是这种简单粗暴的规则无法对应上真实的表达情感,例如“太好”是一个比“好”褒义倾向更强的词,如果“好”的值为+1,那么“太好”可以赋值为+3,加上否定词的“不太好”变成-3则显然有点过于贬义了,将其赋值为-1或者-0.5可能更合适。
基于这种情况,我们可以对否定词也添加上程度的赋值而不是简单的取相反数,对于表达强烈否定的词例如“不那么”赋值为±4。当遇到与褒义词的组合时褒义词则取负数,与贬义词的组合则取正数,例如贬义词“难听”的赋值是-3,加上否定词变成“不那么难听”的情感得分就会是(-3+4=1)。
第三种需要注意的情况是条件词,如果一个条件词出现在句子中,则这个句子很可能不适合用来做情感分析,例如“如果我明天可以去旅行,那么我一定会非常开心。”,在这句话中有明显的褒义情感词,但是因为存在条件词“如果”,使得这个句子的并没有表达观点持有者的真实情感,而是一种假设。
除了条件句之外,还有一种语言表达也是需要在数据预处理阶段进行排除的,那就是疑问句。
例如“这个餐厅真的有你说的那么好吗?”,虽然句子中出现了很强烈的褒义情感词“那么好”,但依然不能将它分类为褒义句。疑问句通常会有固定的结尾词,例如“……吗?”或者“……么?”,但是也有的疑问句会省略掉结尾词,直接使用标点符号“?”,例如“你今天是不是不开心?”,这个句子中含有否定词和褒义词组成的“不开心”,但不能将其分类为贬义情感。
最后一种需要注意的情况是转折词,典型词是“但是”,出现在转折词之前的情感倾向通常与转折词之后的情感倾向相反,例如:“我上次在这家酒店的住宿体验非常好,但是这次却让我很失望。”在这个转折句中,转折词之前的“非常好”是一个很强的褒义词,但真实的情感表达却是转折词之后的“很失望”,最终应该将其分类为贬义情感。
当然,也存在出现了转折词,但语句本身的情感并没有发生改变的情况,例如“你这次考试比上次有了很大的进步,但是我觉得你可以做得更好”,这里的转折词没有转折含义,而是一种递进含义。
在实际操作中,我们所以需要先判断转折句真实的情感表达到底是哪个,才能进行正确的分析计算。
构建情感词典是一件比较耗费人工的事情,除了上述需要注意的问题外,还存在精准度不高,新词和网络用语难以快速收录进词典等问题,同时基于词典的分析方法也存在很多的局限性。
例如一个句子可能出现了情感词,但并没有表达情感。或者一个句子不含任何情感词,但却蕴含了说话人的情感。以及部分情感词的含义会随着上下文语境的变化而变化的问题,例如“精明”这个词可以作为褒义词夸奖他人,也可以作为贬义词批评他人。
尽管目前存在诸多问题,但基于字典的情感分析方法也有着不可取代的优势,那就是这种分析方法通用性较强,大多数情况下无需特别的领域数据标注就可以分析文本所表达的情感,对于通用领域的情感分析可以将其作为首选的方案。
基于机器学习的情感识别
我们在机器学习算法的章节介绍过很多分类算法,例如逻辑回归、朴素贝叶斯、KNN等,这些算法都可以用于情感识别。
具体的做法与机器学习一样需要分为两个步骤:第一步是根据训练数据构建算法模型;第二步是将测试数据输入到算法模型中输出对应的结果,接下来做具体的讲解。
首先,我们需要准备一些训练用的文本数据,并人工给这些数据做好情感分类的标注。通常的做法下:如果是褒义和贬义的两分类,则褒义标注为1,贬义标注为0,如果是褒义、贬义和中性三分类,则褒义标注为1,中性标注为0,贬义标注为-1。
在这一环节中如果用纯人工方法来进行标注,可能会因为个人主观因素对标注的结果造成一定影响,为了避免人的因素带来的影响,也为了提高标注的效率,有一些其他取巧的方法来对数据进行自动标注。
比如:在电商领域中,商品的评论除了文本数据之外通常还会带有一个5星的等级评分,我们可以根据用户的5星评分作为标注依据,如果是1-2星则标注为贬义,如果是3星标注为中性,4-5星标注为褒义。
又比如:在社区领域中,很多社区会对帖子有赞和踩的功能,这一数据也可以作为情感标注的参考依据。
第二步是将标注好情感倾向的文本进行分词,并进行数据的预处理,前文已经对分词有了很多的介绍,这里就不再过多的赘述。
第三步是从分词的结果中标注出具备情感特征的词,这里特别说一下,如果是对情感进行分类,可以参考情感词典进行标注,也可以采用TF-IDF算法自动抽取出文档的特征词进行标注。如果分析的是某个特定领域的,还需要标注出特定领域的词,例如做商品评价的情感分析,需要标注出商品名称,品类名称,属性名称等。
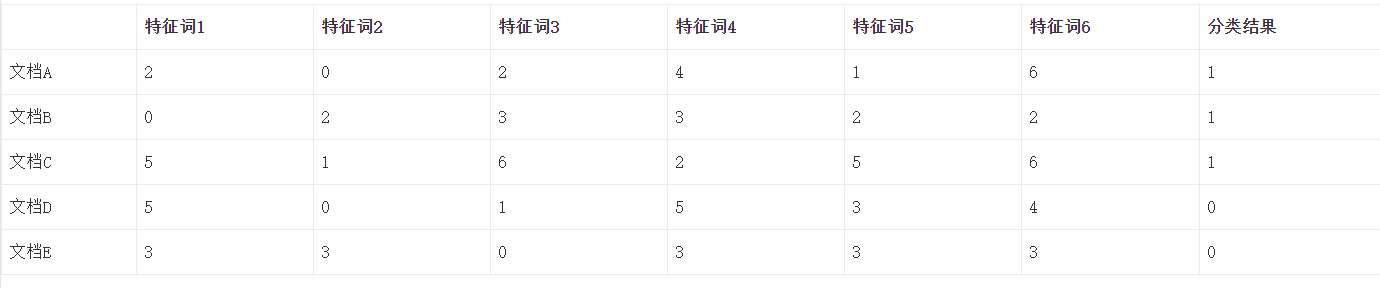
第四步根据分词统计词频构建词袋模型,形成特征词矩阵,如表所示。在这一步可以根据业务需要给每个特征词赋予权重,并通过词频乘以权重得到特征词分数。
最后一步就是根据分类算法,将特征词矩阵作为输入数据,得到最终的分类模型。
当训练好分类模型之后,就可以对测试集进行分类了,具体的流程与建模流程类似,先对测试的文本数据进行分词并做数据预处理,然后根据特征词矩阵抽取测试文本的特征词构建词袋矩阵,并将词袋矩阵的词频数据作为输入数据代入之前训练好的模型进行分类,得到分类的结果。
采用基于机器学习的方法进行情感分析有以下几个不足之处:
- 第一是每一个应用领域之间的语言描述差异导致了训练得到的分类模型不能应用与其他的领域,需要单独构建。
- 第二是最终的分类效果取决于训练文本的选择以及正确的情感标注,而人对于情感的理解带有主观性,如果标注出现偏差就会对最终的结果产生影响。
除了基于词典和基于机器学习的方法,也有一些学者将两者结合起来使用,弥补两种方法的缺点,比单独采用一种方法的分类效果要更好。
另外,也有学者尝试使用基于LSTM等深度学习的方法对情感进行分析,相信在未来,情感分析会应用在更多的产品中,帮助我们更好的理解用户需求,提升用户使用智能产品的体验。
情感识别的困难与挑战
随着深度神经网络等算法的应用,情感分析的研究方向已经有了非常大的进展,但依然存在着一些难题是目前尚未解决的,在实操过程中需特别注意以下几种类型数据:
(1)颜文字、emoji和表情包
互联网上的交流不仅仅只是通过单纯的文字来进行,大量的情感表达是通过颜文字或表情包来实现的,例如经典的表示笑脸的颜文字“:D”,这类文本表达无法与上下文形成联系,所以很难判断他们评价的实体对象是什么。
不过好在这类数据本身就代表了非常强烈的情感倾向,在篇章级和句子级的颗粒度对情感进行分析,我们可以将特定的颜文字作为一种特殊的词组构建成情感字典,并人工进行情感分的赋值,对于emoji表情也可以将标准的emoji编码编入情感字典。而对于表情包的识别则是一个计算机视觉的问题,目前还没有学者在这个领域方向展开研究。
(2)讽刺句
讽刺语句是一种比较特殊的情感表达语句,讽刺语句的语言组织形式从字面上来看可能是褒义,但实际的含义却是贬义,或者字面是贬义但实际却是褒义。
例如:“太棒了!这家外卖治好了我多年的便秘!”
讽刺句在情感分析中是非常难以处理的,因为要分辨这类语句的含义,通常来讲需要结合常识或者是相关的背景知识才可以了解,仅仅通过上下文是无法正确解读讽刺句的含义的。在对商品的评价语中,讽刺句并不常见,但在舆论或社会新闻的评价中,讽刺句则比较常见,识别出讽刺句是情感分析分析方向的一个研究难点。
(3)比较句
比较语句也是一种特殊的情感表达句,例如:“我觉得这件衣服很适合我,但我更喜欢那一件。”
这类比较语句中通常存在着两个以上的实体或属性,如果只是在句子级的颗粒度下可以辨别出这句话是含有褒义的情感,但在属性级的颗粒度下,以情感五元组来定义的情感无法将一个实体作为另一个实体的属性来进行判断,很难分辨观点持有者到底是在对哪一个实体或属性表达情感。而这类语句在商品的评论中有非常常见,需要特别注意。
(4)情绪分类
目前对于情感的分析依然处于初级阶段,仅仅只是对情感做了褒义、贬义、中性三种划分,但现实生活中的情绪远远不止这三种类型,例如:在心理学领域中,著名的心理学家罗伯特·普拉切克(Robert Plutchik)提出的情绪轮包含了8种基本情绪,并且每种情绪又划分了不同的情绪强度等级,8种情绪还可以相互结合形成更多的情绪,如图所示。

普拉切克的情绪轮
情绪轮在用户体验设计上被广泛的应用,很多情感化设计都是基于情绪轮进行的。但是在人工智能领域,将情绪进行多分类比情感分析的三分类任务要难得多,目前大多数分类方法的结果准确性都不到50%。
这是因为情绪本身包含了太多的类别,而且不同的类别之间又可能具有相似性,一个情绪词在不同的语境下有可能表达的是不同的情绪类别,算法很难对其进行分类。即使是人工对文本进行情绪类别标注也往往效果不佳,因为情绪是非常主观性的,不同的人对不同的文本可能产生不同的理解,这使得人工标注情绪类比的过程异常困难。
如何让机器可以理解真实的情绪,目前还是一个未能攻克的难题。
本文由 @黄瀚星 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


