
 起点课堂会员权益
起点课堂会员权益机器学习:基于Knn算法的用户属性判断方案设计
本文作者通过Knn算法进行了一次用户判断预测的流程,文章为作者根据自身经验所做出的总结,希望通过此文能够加深你对Knn算法的认识。

knn算法简介
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。knn的基本思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
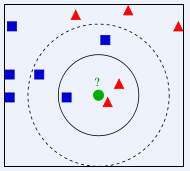
如下图所示,如何判断绿色圆应该属于哪一类,是属于红色三角形还是属于蓝色四方形?
如果K=3,由于红色三角形所占比例为2/3,绿色圆将被判定为属于红色三角形那个类
如果K=5,由于蓝色四方形比例为3/5,因此绿色圆将被判定为属于蓝色四方形类。
由于KNN最邻近分类算法在分类决策时只依据最邻近的一个或者几个样本的类别来决定待分类样本所属的类别,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
因此,k值的选择、距离度量以及分类决策规则是k近邻算法的三个基本要素。
真实业务场景
某公司存在有一些数据样本(500*5矩阵),是关于人群属性的一些特征,希望通过已知数据的特征,推测出部分目标数据的性质,假如特征向量包含:
- 平均每日游戏时长-game time
- 异性朋友数-female friends
- 周末在家时长-stay-in time
- 用户接受类型-attr(attr是目标判断属性,同时也是标记属性)
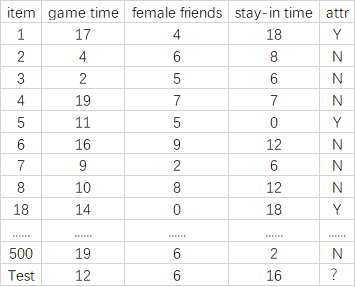
问题:我们需要根据已知的这些属性,判断最后一个样本的属性是“Y”还是“N”
数据特征分析
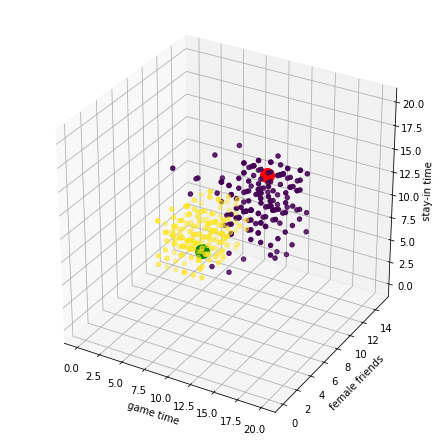
我们所拿到的这批数据是500*5的矩阵,以平均每日游戏时长,异性朋友数,周末在家时长为轴,将不同属性的点用不同颜色区分,利用matplotlib绘制散点图,最终效果如图。
由于这些测试数据在空间的分布非常集中,所以对于需要验证的点(红,绿两点),我们很容易区分出这些点的属性
结合本次的业务场景,我们将通过前三种特征的空间分布,对attr属性进行预测
具体算法
在三维空间中,我们可以直观判断,那在具体的算法实现中,可以考虑使用
n维空间的欧氏距离:
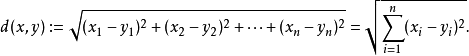
通过以上公式,我们能对多维度数据进行分析,得到目标与各点的距离。
同时,细心的读者肯定考虑到,我们已知的这些特征,存在量级之间的差异,所以我们通常需要通过归一化特征值,对消除不同量级造成的影响。因此,我们选用0-1标准化(0-1 normalization)对原始数据的线性变换。
0-1标准化:
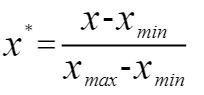
在通过以上两步对数据预处理完成后,我们将所得的距离进行排序,并选取合适的K值对目标数据进行预测。
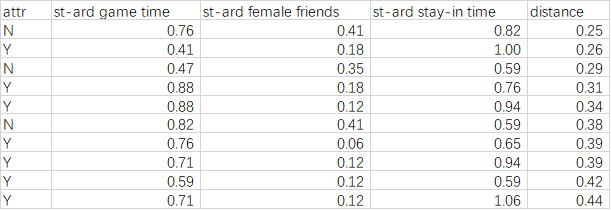
在此选择k=10(仅举例),可以发现,前10项中Y出现的次数最多,因此我们可以认为目标数据的值为Y。
knn算法总结
在数据分析团队确定好数据特征后,对相应数据进行收集及清洗,对各数据特征进行归一化处理(视具体业务场景定,或需特征考虑权重),完成以上流程后,进行以下通用流程:
- 计算测试数据与各个训练数据之间的距离;
- 按照距离的递增关系进行排序;
- 选取距离最小的K个点;
- 确定前K个点所在类别的出现频率;
- 返回前K个点中出现频率最高的类别作为测试数据的预测分类。
最后,我们简单总结一下Knn的适用场景
- 数据已存在标记特征,Knn是监督算法
- 样本数在100k以下,由于算法会对每个目标值进行多维度距离计算,所以样本过大可能超负荷
- 样本非文本,或可转化为数值
以上便是通过Knn算法进行了一次用户判断预测的流程,文中所展示内容均为模拟数据,且选择了其中最简单的判断属性。如文中有遗漏及不足,请各位指出。
本文由 @Dave Fu 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 unsplash,基于 CC0 协议






- 目前还没评论,等你发挥!


