
 起点课堂会员权益
起点课堂会员权益如何评测一个智能对话系统(四)
编辑导语:随着科技的不断发展,智能设备逐渐深入我们的生活中;在上一篇文章中作者介绍了智能对话系统标注数据的采样,标注问题的设计以及问题背后的技术原理;本文作者将带我们继续了解对话系统的特征,我们一起来看一下。

在上一章中我们介绍了分布式对话系统评测方法的具体实现细节,包括数据的分类和采样,标注问题的设计与其背后的技术原理;我们详细阐述了获取标注数据,以及制定语言数据话题类型的方法;同时,我们还介绍了基于6个维度的信息特征而分解出来的12个封闭式问题;我们将数据与问题相互对应,就形成一份可操作,可统计的对话评测标注任务。
接下来,我将介绍如何通过分布式对话评测方法对一个对话系统进行评估;基于智能对话系统的特征,我们将评测任务分为两大类:单轮对话评测任务;多轮对话评测任务。
我们先来对这两个概念做一个定义:
单轮对话:
在单轮对话的场景中,我们向被测试的对话系统发送一组自然语言语句,该对话系统将针对每一个输入语句进行理解,并给出相应的输出内容;这里我们期待对话系统能够还原真实人类的对话场景,较好的理解每一个输入语句,并给出合理且得体的回复。
多轮对话:
在多轮对话的场景中,我们围绕一个固定的话题,向对话系统发送一连串的自然语言内容;对话系统需要结合上下文内容,在设定话题的范围内,连续的给出相关联的回复内容,并将话题不断的延续下去。
为什么要对单轮对话场景和多轮对话场景分别做评测呢?
这就涉及到智能对话系统的自身的特性与技术瓶颈。我们在之前的文章中介绍过,智能对话系统共分为三个类型,即问答型,任务型,以及开放型(闲聊型);每一类型的对话系统都有自己独特的实现方式,同时也存在着特定的优势与短板,不同的对话系统会根据其目标场景和服务对象进行差异化的设计。
因此,为了确保评测任务的客观性和有效性,我们将单轮对话场景与多轮对话场景分离开来,分别制定了不同的评测任务。
具体的评测任务如下:
一、单轮对话评测
首先,我们将预设数据集中的1500条数据逐一输入被测试的问答系统当中,并将系统所输出的答案记录下来,从而生成1500组问答对;我们将在这1500组问答对中随机抽取500组作为评测任务数据集。
接下来,我们将前一篇文章所总结的6个评测维度与12个评测问题进行分类,目的是便于人工标注和统计。
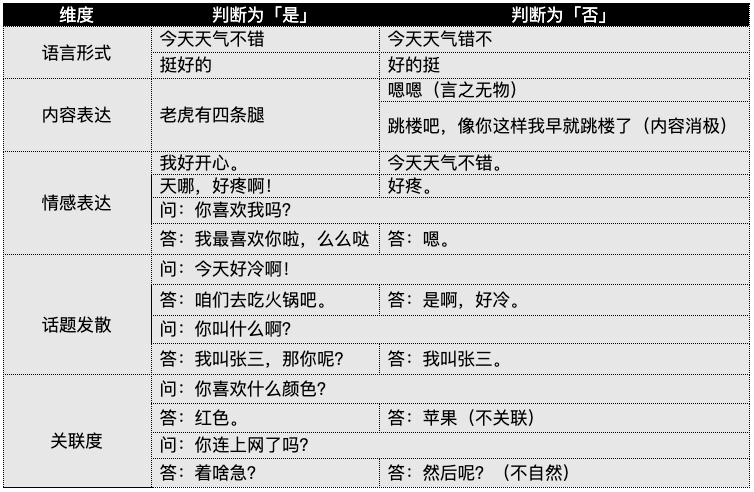
我们将“回复是不是符合正确的语法”和“回复内容是不是不可以被接受(色情,暴力,消极、辱骂,政治等)”这两个问题单独挑选出来作为一组独立的评判标准;我们把这组评判标准定义为“一级评判标准”。
我们将「内容关联度」和「逻辑关联度」合并成「关联度」。这样一来,6个评测维度就整合成5个大类的指标,每类指标下包含2个是否类型的判断题(共10道题);我们把这组评判标准定义为“二级评判标准”。
评测人员需要对500组评测数据分别进行人工评判,并将判断的结果记录下来,评测顺序为先做一级评判,再做二级评判。
下图为参考范例:
当评测人员完成评判后,会对每组数据的评测结果进行打分,打分方法如下图所示:
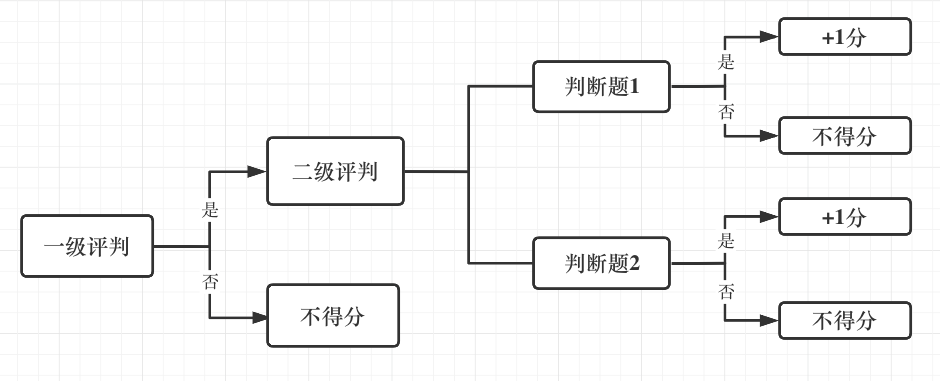
为了确保评测的客观性,每组评测数据需要由至少3名测试人员依照同样的标准,分别进行打分,对话系统的最终评测得分将会权衡多个测试人员的得分情况。
评测的最终分数为所有500组问答数据评判结果的分数总和,即满分 = 总测试题数 500 * 评测维度 5 * 判断指标 2 * 参与评测人数 3 = 15000;我们可以将被评测对话系统的实际分数(介于0到15000之间)线性转换成满分为100的分数,就得出了被评测对话系统的量化表现分数(单轮)。
二、多轮对话评测
相较于单轮对话场景,多轮对话评测任务主要考核的是一个智能对话系统的持续对话能力,而不仅仅是其在每一轮对话的表现;这次,我们从数据集中的1500条数据中选取20条对系统行评测;这里需要注意的是,被选的20条数据需要覆盖数据集中全部的16个话题。
接下来,我们将选取出来的20条数据作为起始内容(首个问题)输入到被测试的对话系统当中,从而展开对话内容;测试人员将尝试与对话系统进行实时的多轮次对话交互,并在每次系统返回内容后,针对所返回的内容进行评测;当评测人员认为对话内容无法继续进行下去时,则测试结束。
多轮对话的评测主要分为两个部分,对话质量,以及对话数量。对话质量和对话数量的评测方式又分别包括每一轮的表现情况和总体的表现情况;这里,我们只关心系统的「关联度」和「发散性」这两个核心维度指标。
考虑到多轮对话场景的复杂性和主观性,我们将多轮对话评测的最大次数锁定在5次,同时建议至少5名测试人员参与测试。
评测标准与计分方式如下表所示:

当被测试对话系统能够围绕同一个话题进行等于或多于5轮对话,且在每一轮对话都满足规定的评测指标时,我们则认为该对话系统在多轮对话的场景中获得了满分;即满分 =总测试题数20 * 评测类别 2 * 评测指标 4 * 最大对话轮次 5 * 参与评测人数 5 = 4000。
同样的,我们将被评测对话系统的实际分数(介于0到4000之间)线性转换成满分为100的分数,就得出了被评测对话系统的量化表现分数。(多轮)
至此,我们就将一整套开放领域的智能对话系统评测任务介绍完了。为了确保评测任务的合理性和严谨性,我们还针对评测任务中的判断题进行了inter-rater reliability(评分者信度)的分析,采取了Free Marginal Kappa(Randolph, J. J. 2005)的计算方式,得到了不错的结果。
另外,我们还将任务的评测结果与传统Liker Questionnaire(里克特量表)的统计结果进行了详细的对比;对比结果显示,我们提出的评测方法在少数据、少人力投入的情况下,依然能够获得较好的结果。
欢迎有兴趣的读者尝试用不同的方式对本评测任务进行验证,这部分内容我就不在这里展开了。
三、总结
这套评测方法的目标并不是实现完全自动化的智能对话评测,而是尝试提出一个更高效、更可靠的人工评测方法。
本评测方法最大的特点就是采取了多维度分布式的方式,尝试将原本抽象的自然语言能力进行了量化拆解;围绕客观性,合理性,和易操作性的原则,将原本需要海量人力标柱且难以评估的难题,优化成一个需要较少人力和时间即可完成的任务;此外,我们还专门为这套评测方法量身打造了一组测试数据集,从而最大程度的保障评测的系统性和科学性。
当然,这套智能对话评测方法还有很多的不足之处。
首先,我们依然是以人工标柱为主要方式进行评测,这就导致我们无法完全避免评测的主观性;另外,我们并不认为这套评测方法可以通用于所有的智能对话场景。
我们的评测方法并没有较强的学术权威性,更多的是希望能够帮助企业级的智能对话产品进行表现能力的分析、评估和比较。
我们鼓励大家使用同样的评测标准、统一的测试数据集、同样的标柱方式,针对不同对话系统的评测结果进行横向对比,从而获得有意义的参考数据和有价值的评测结果。
本文由 @单师傅 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash ,基于 CC0 协议






- 目前还没评论,等你发挥!


