
 起点课堂会员权益
起点课堂会员权益大数据时代:数据仓库搭建之路
数据仓库是所有产品的数据中心,公司体系下的所有产品产生的所有数据最终都流向数据仓库,可以说数据仓库不产生数据,也不消费数据,只是数据的搬运工。

记得很久以前曾有一位前辈和我说过:“进来的数据是垃圾数据,出去也是垃圾数据”。
在实际环境中,往往我们一条业务线会由多个不同的系统支撑组成(例如:很多电商后端业务线都区分为库存系统、售后系统、采购系统、CRM系统等)。这些系统由于本身设计的缺陷或业务流程变更等问题,所产生的数据往往都是有缺失、冗余的,如果直接使用这些数据去进行数据分析,那最后分析出来的结论多半也不正确。
因此需要有个数据产品来对数据进行整合加工,而数据仓库就是这样一款产品。
要想了解怎么搭建数据仓库,首先需要明白数据仓库的作用:
- 存储数据
- 校准数据
- 整合数据
- 输出数据
基于以上几点,需要将数据分层次管理,每一层分工合作,对数据进行不同程度的处理,如同工厂里的流水线一般,从而确保数据的生命性、生态性。
大数据体系整体架构
数据仓库并不是独立存在的一个个体,而是与整个大数据体系融为一体的——换句话说,数据仓库就像人的心脏,人只有心脏而没有其他器官是无法单独存活下来的。
大数据体系架构如图所示:
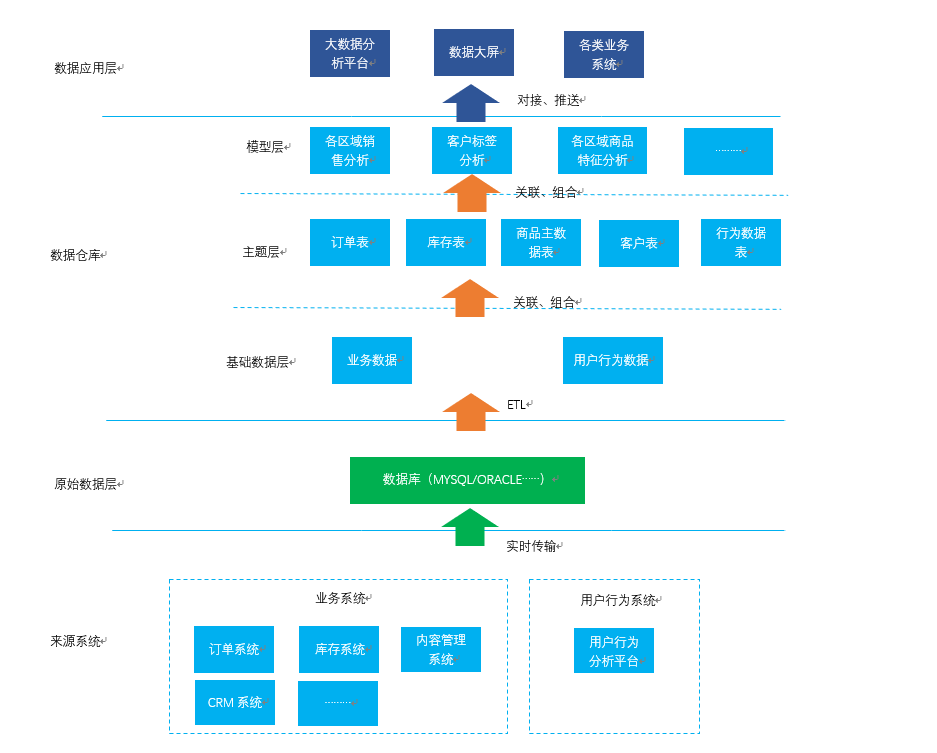
来源系统
数据的来源系统,可以理解为数据的收集系统。
如图所示为基于电商业务下的大数据体系,因此数据大体可分为业务数据和用户行为数据,其来源系统更多是与电商业务相关的后端订单、库存等业务系统以及前端商城带来的用户行为数据。
原始数据层
顾名思义,即存放从来源系统过来的原始数据,所谓原始数据——即未经过任何加工处理的数据。
这一层次咋看之下有点多余,但实际上是有所考量的:
1)将数据仓库与业务系统分隔开
数据仓库的数据,实时性要求不高,而准确性、清洁型必须较高,因此清洗的脚本繁多。如果每条数据都实时传送到数据仓库的话,那脚本执行的频率将非常高,所占用的系统资源也随之增加。
2)分担业务系统的报表任务
总所周知,搭建大数据体系架构所使用的硬件资源是相对较高的,而业务系统往往只是支撑业务持续开展,从性能上往往无法支撑大数据量报表的导出。因此,原始数据层可以承载此项功能,业务系统数据传输的实时性也保证了从原始数据层导出的数据符合业务人员对报表实时性的需要。
数据仓库
一般来说,数据仓库可区分为三层:基础数据层、主题层、模型层
基础数据层
原始数据层以天为时间周期,将每天的数据传输到数据仓库,数据仓库通过ETL(抽取、转化、加载)的方式,将数据按照设定的数据表格式存储好,形成基础数据层的数据。
何谓ETL呢?
ETL即:Extra、Transfer、Load——简单来说,即数据清洗。先将数据抽取出来,将冗余数据,错误数据,有歧义的数据按照既定的规则进行删减、填充、修改,再填充入已设定好的表结构的数据库表中。
举个栗子:
从订单系统过来的订单数据上,客户名称多种多样,相同一个客户,有大写的名称、小写的名称、有些订单甚至没有客户的相关信息(这当然是业务系统本身的历史遗留问题导致的)。此时,作为数据产品经理必须要了解这些数据的“坑”,并且和对应业务系统的产品经理共同商讨如何处理这批数据,确定好清洗逻辑(例如:所有名称统一转化为小写,如果客户名称、地址、电话号码都是同一个的,归为同一个客户),程序猿们根据数据产品经理的清洗规则写好脚本进行清洗。
主题层
数据清洗就像打扫卫生一样,将不要的东西扔掉,将破旧的东西擦拭干净,但并不代表数据是完整的。
主题层的构建相对复杂,搭建的规则主要是看未来的需要以及产品经理对业务的理解。
举个栗子:
题主所在的公司是一家大型零售分销公司,因此往往有一张订单卖给零售商,零售商再下一张订单给零售店,零售单再下一张订单给终端用户。此时,每一级订单是断层,且来源于不同的系统的,因此每一级订单的表结构完全不同。
这样导致的结果是:无法从全链条上看到每一个商品在渠道中的流转,也无法实时跟踪到每个商品的具体转化效率。所以,需要把每一级的订单按照主题分门别类(一级订单、二级订单、三级订单),并且建立一种关联关系,使这三者能串联起来,形成一整个渠道流程。
模型层
数据来到模型层,也就意味着他们最终要成为“炮弹”,发射到数据分析平台了,因此模型层的最主要作用是:将主题数据组合成数据分析模型。
假设我们需要在数据分析平台上体现出“不同商品在不同区域不同客户的热销情况”,那在模型层就需要以订单表作为最基础的表,关联上区域表、客户表、商品表,关联出一个以区域+商品+客户特征维度划分的明细数据。每个区域每个商品每个客户对应一行销售数据,根据这份数据汇总出一个按区域+商品+客户特征的模型,输出到数据分析平台,展示出不同区域,不同商品的客户特征是怎样的。
需要注意的是:模型层的数据都是呈现出星状结构和高度索引化的。
因为在大数据平台上,数据与数据之间往往是需要存在关联的,运营人员看到商品在不同区域上的销量分布,往往也想进一步看到在不同区域上的商品有什么特征,客户有什么特征,这些都需要和区域强关联起来的。
数据应用层
数据应用层严格意义上不属于大数据架构,因为它除了会涉及各式各样的数据分析平台,还会涉及到业务系统。
数据反哺
上文提到过,业务系统对于数据仓库而言更多是作为数据收集工具,但同时业务系统也存在着数据的需求,我把这样的过程称为数据反哺。
往往支撑公司业务开展下去的业务系统不止一个,很可能是有多个,而各式各样的业务系统之间也需要数据交互。例如:一般电商公司会有一套前端商家平台,也会一套后端的管理平台,这两套平台使用的往往不是同一套SKU,因此需要将后端SKU同步到前端来进行mapping。
那么为什么不能直接让这两套系统直接进行数据交互呢?
因为数据已经不再干净,需要数据仓库进行清洗过后,将冗余的数据去除后方可推送至前端商家平台。
分析模型输出
数据仓库的数据,最终除了会流向业务系统以外,更多的会流向各大数据应用系统,即:数据大屏,大数据分析平台等
此时的数据,已经过层层清洗加工、模型搭建,形成一个个炮弹,通过接口的形式推送至各大数据平台。对于这些数据分析、数据展示平台而言,更多的只需要考虑如何直观展示数据即可。
总结
数据仓库不产生数据,也不消费数据,如果把数据比作是水的话,可以将它理解成矿泉水厂商:负责将水抽取上来->排污->打包->运送。说来容易,做来难,其中辛酸与难度只有数据产品经理能理解。
本文由 @Leo 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议









感谢~
谢谢分享,思路清晰了很多
直观解答疑惑了
感谢楼主,非常有帮助
学习了,可以加v学习吗
学习了
辛苦,谢谢分享,感觉挺有用
感谢
先收藏,再细看。 感谢LEO