
 起点课堂会员权益
起点课堂会员权益分析了豌豆荚 7 万款 App,全是万万没想到
使用 Scrapy 爬取豌豆荚全网 70000+ App,并进行探索性分析。若对数据抓取部分不感兴趣,可以直接下拉到数据分析部分。

一、分析背景
之前我们使用了 Scrapy 爬取并分析了酷安网 6000+ App,为什么这篇文章又在讲抓 App 呢?
因为我喜欢折腾 App,哈哈。当然,主要是因为下面这几点:
第一、之前抓取的网页很简单
在抓取酷安网时,我们使用 for 循环,遍历了几百页就完成了所有内容的抓取,非常简单,但现实往往不会这么 easy,有时我们要抓的内容会比较庞大,比如抓取整个网站的数据,为了增强爬虫技能,所以本文选择了「豌豆荚」这个网站。
目标是: 爬取该网站所有分类下的 App 信息并下载 App 图标,数量在 70,000 左右,比酷安升了一个数量级。
第二、再次练习使用强大的 Scrapy 框架
之前只是初步地使用了 Scrapy 进行抓取,还没有充分领会到 Scrapy 有多么牛逼,所以本文尝试深入使用 Scrapy,增加随机 UserAgent、代理 IP 和图片下载等设置。
第三、对比一下酷安和豌豆荚两个网站
相信很多人都在使用豌豆荚下载 App,我则使用酷安较多,所以也想比较一下这两个网站的 App 特点。
话不多说,下面开始抓取流程。
1. 分析目标
首先,我们先来了解一下要抓取的豌豆荚网页是什么样的,可以看到该网站上的 App 分成了很多类,包括:「应用播放」、「系统工具」等,一共有 14 个大类别,每个大类下又细分了多个小类,例如,影音播放下包括:「视频」、「直播」等。
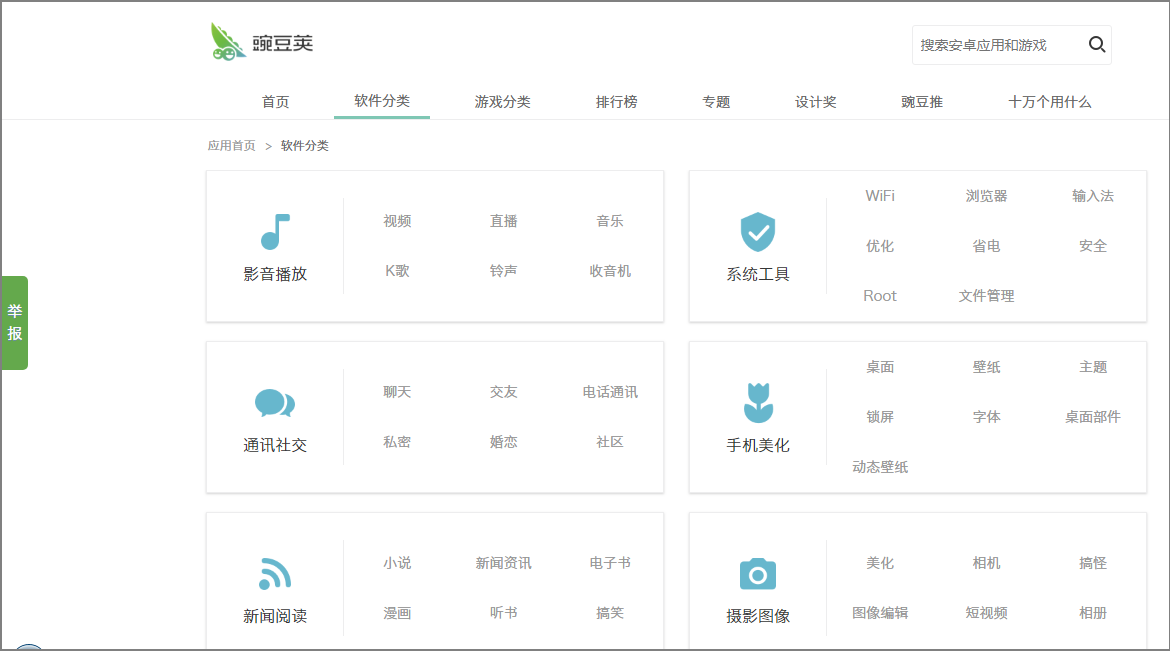
点击「视频」进入第二级子类页面,可以看到每款 App 的部分信息,包括:图标、名称、安装数量、体积、评论等。
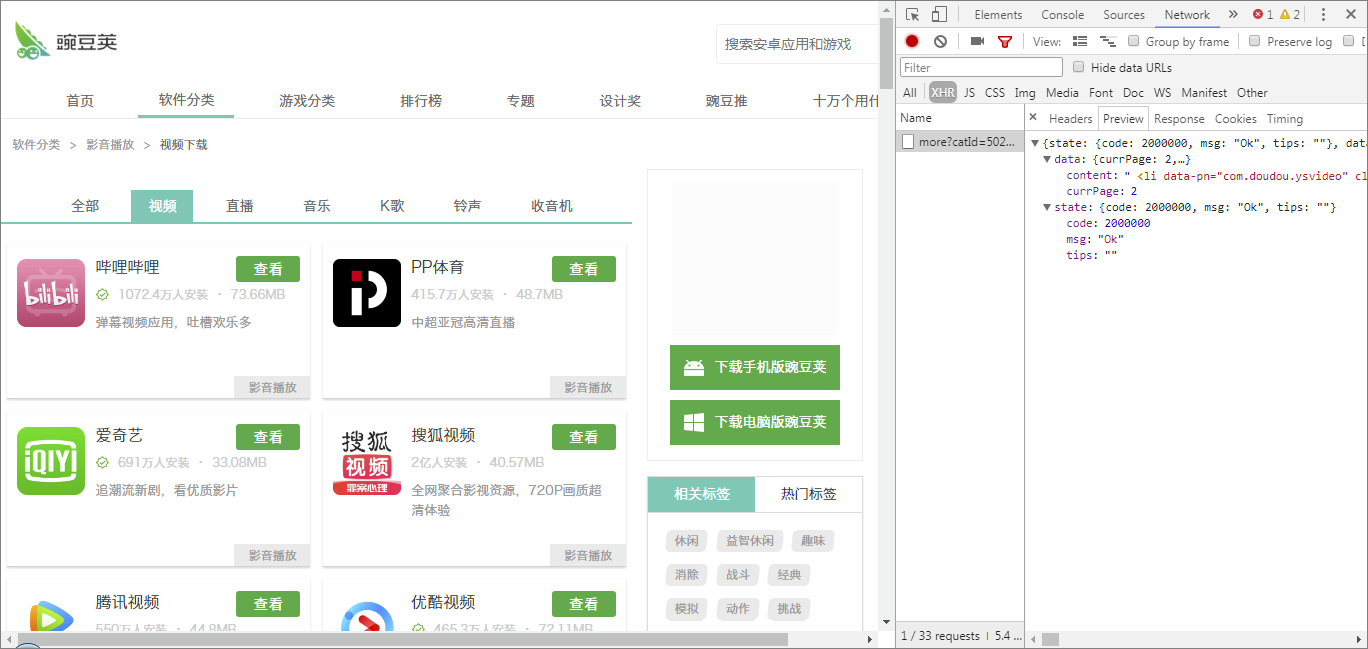
接着,我们可以再进入第三级页面,也就是每款 App 的详情页,可以看到多了下载数、好评率、评论数这几样参数,抓取思路和第二级页面大同小异,同时为了减小网站压力,所以 App 详情页就不抓取了。
所以,这是一个分类多级页面的抓取问题,依次抓取每一个大类下的全部子类数据。
学会了这种抓取思路,很多网站我们都可以去抓,比如很多人爱爬的「豆瓣电影」也是这样的结构。
2. 分析内容
数据抓取完成后,本文主要是对分类型数据的进行简单的探索性分析,包括这么几个方面:
- 下载量最多 / 最少的 App 总排名;
- 下载量最多 / 最少的 App 分类 / 子分类排名;
- App 下载量区间分布;
- App 名称重名的有多少;
- 和酷安 App 进行对比。
3. 分析工具
- Python
- Scrapy
- MongoDB
- Pyecharts
- Matplotlib
二、数据抓取
1. 网站分析
我们刚才已经初步对网站进行了分析,大致思路可以分为两步,首先是提取所有子类的 URL 链接,然后分别抓取每个 URL 下的 App 信息就行了。
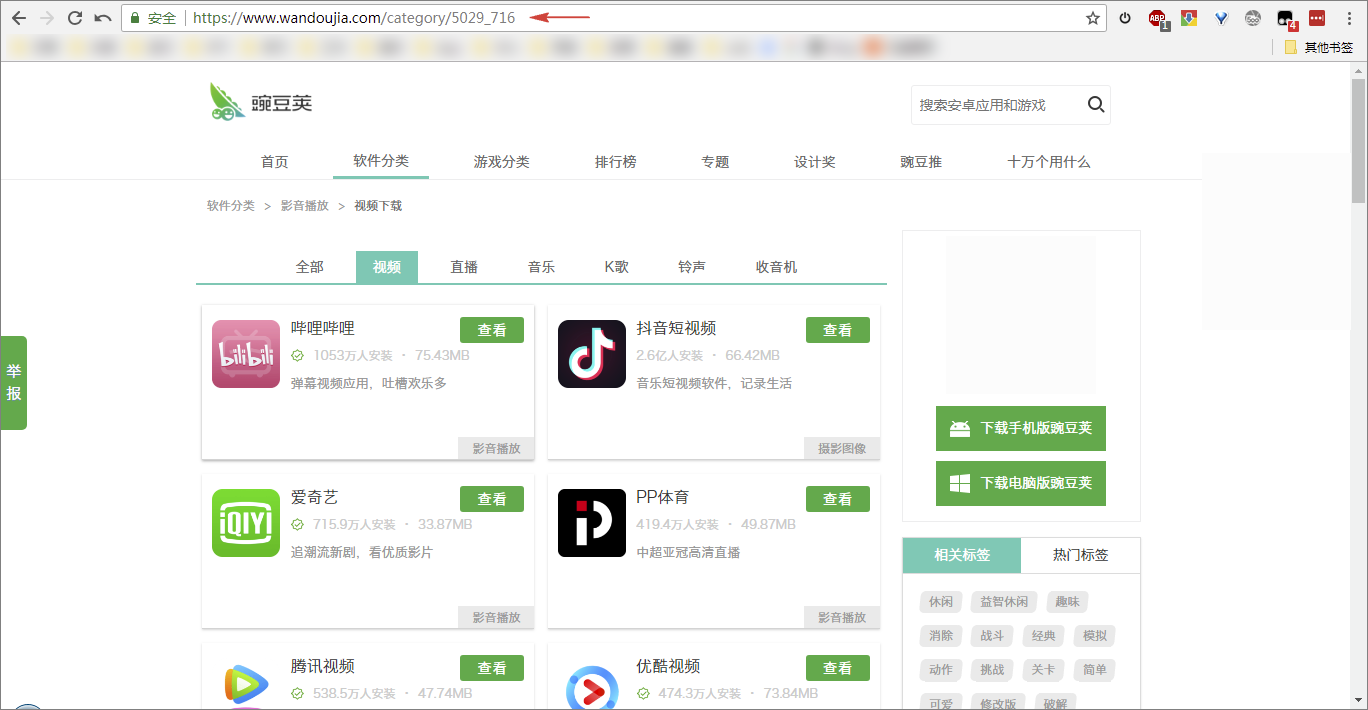
可以看到,子类的 URL 是由两个数字构成,前面的数字表示分类编号,后面的数字表示子分类编号,得到了这两个编号,就可以抓取该分类下的所有 App 信息,那么怎么获取这两个数值代码呢?
回到分类页面,定位查看信息,可以看到分类信息都包裹在每个 li 节点中,子分类 URL 则又在子节点 a 的 href 属性中,大分类一共有 14 个,子分类一共有 88 个。
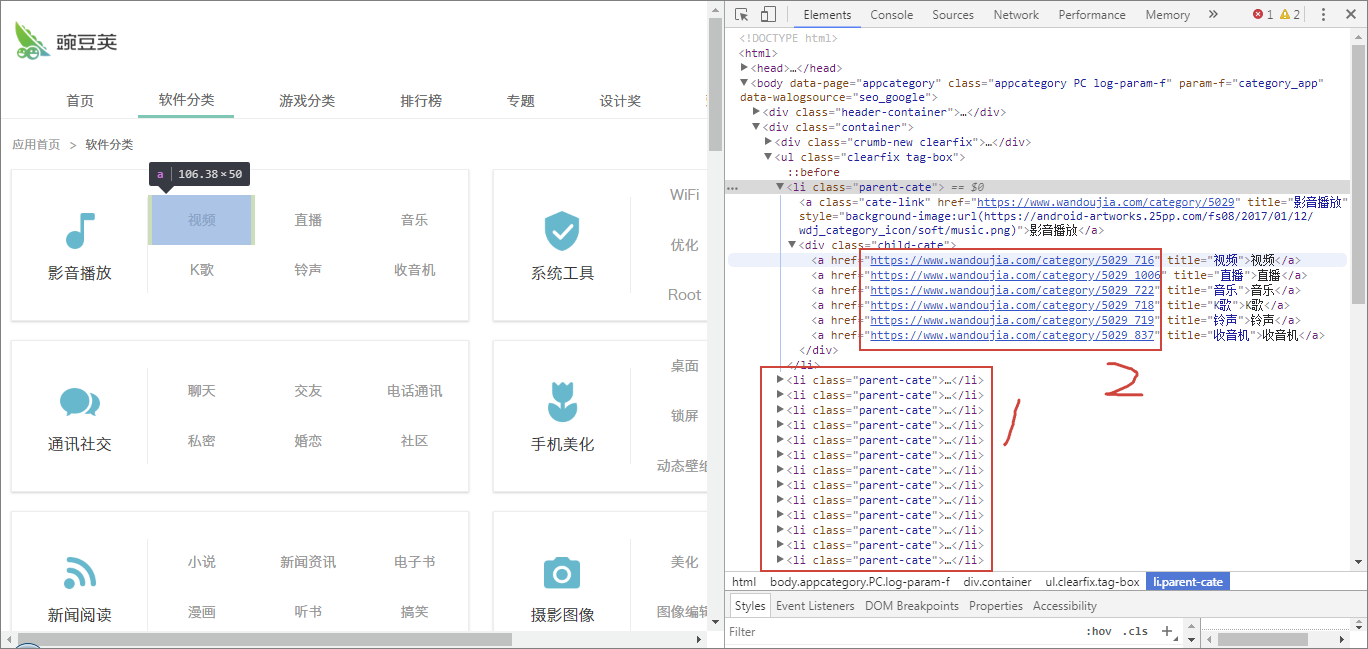
到这儿,思路就很清晰了,我们可以用 CSS 提取出全部子分类的 URL,然后分别抓取所需信息即可。
另外还需注意一点,该网站的 首页信息是静态加载的,从第 2 页开始是采用了 Ajax 动态加载,URL 不同,需要分别进行解析提取。
2. Scrapy抓取
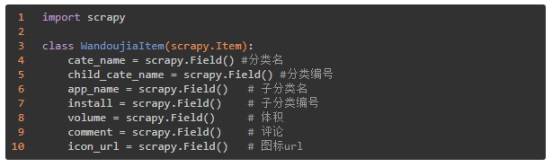
我们要爬取两部分内容,一是 APP 的数据信息,包括前面所说的:名称、安装数量、体积、评论等;二是下载每款 App 的图标,分文件夹进行存放。
由于该网站有一定的反爬措施,所以我们需要添加随机 UA 和代理 IP,关于这两个知识点,我此前单独写了两篇文章进行铺垫,传送门:
这里随机 UA 使用 **scrapy-fake-useragent **库,一行代码就能搞定,代理 IP 直接上阿布云付费代理,几块钱搞定简单省事。
下面,就直接上代码了:
(1)items.py
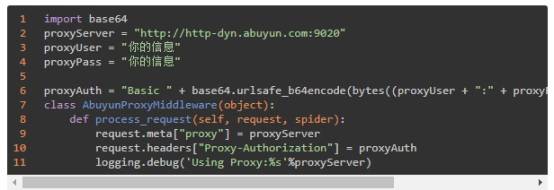
(2)middles.py
中间件主要用于设置代理 IP。
(3).py
该文件用于存储数据到 MongoDB 和下载图标到分类文件夹中。
存储到 MongoDB:
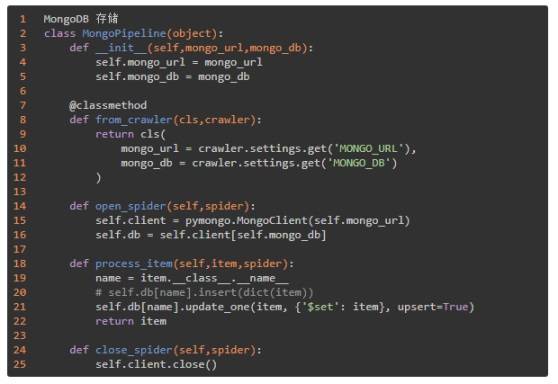
按文件夹下载图标:
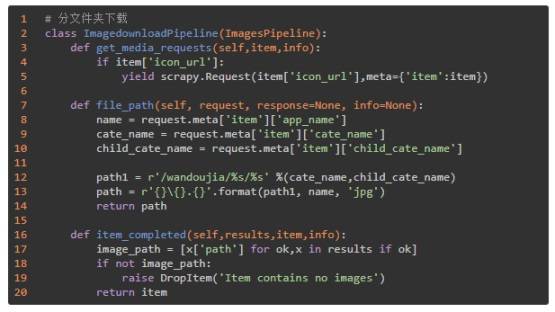
(4)settings.py
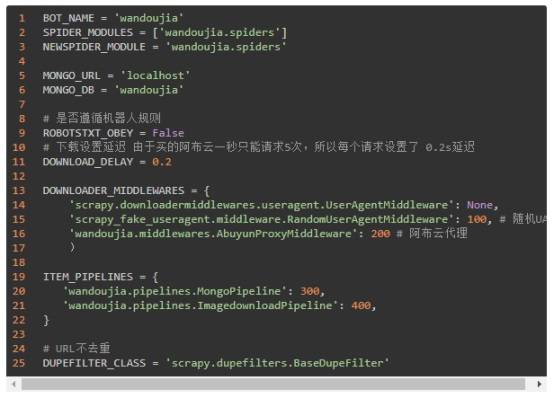
(5)wandou.py
主程序这里列出关键的部分:
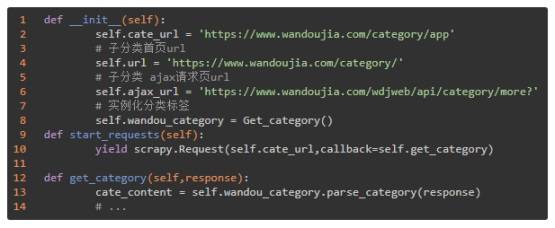
这里,首先定义几个 URL,包括:分类页面、子分类首页、子分类 AJAX 页,也就是第 2 页开始的 URL,然后又定义了一个类 Get_category() 专门用于提取全部的子分类 URL,稍后我们将展开该类的代码。
程序从 start_requests 开始运行,解析首页获得响应,调用 get_category() 方法,然后使用 Get_category() 类中的 parse_category() 方法提取出所有 URL,具体代码如下:
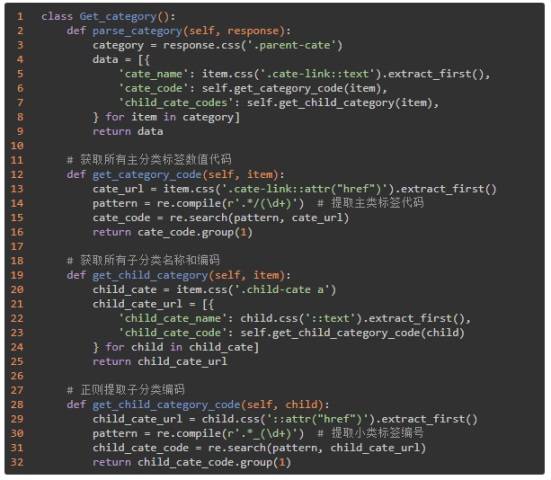
这里,除了分类名称 cate_name 可以很方便地直接提取出来,分类编码和子分类的子分类的名称和编码,我们使用了 get_category_code() 等三个方法进行提取。提取方法使用了 CSS 和正则表达式,比较简单。
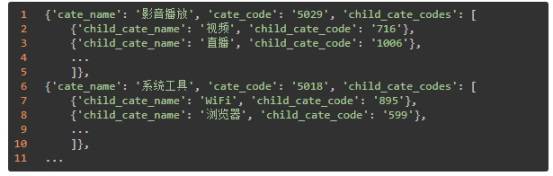
最终提取的分类名称和编码结果如下,利用这些编码,我们就可以构造 URL 请求开始提取每个子分类下的 App 信息了。
接着前面的 get_category() 继续往下写,提取 App 的信息:
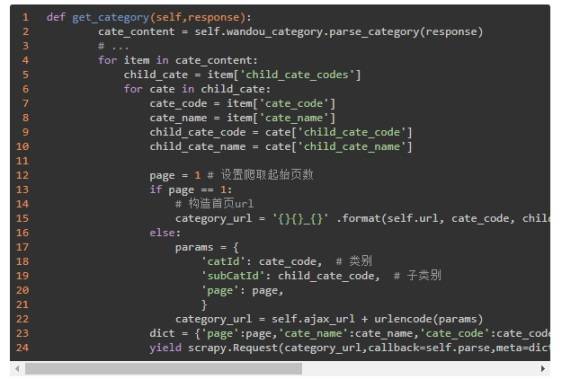
这里,依次提取出全部的分类名称和编码,用于构造请求的 URL。由于首页的 URL 和第 2 页开始的 URL 形式不同,所以使用了 if 语句分别进行构造。接下来,请求该 URL 然后调用 self.parse() 方法进行解析,这里使用了 meta 参数用于传递相关参数。
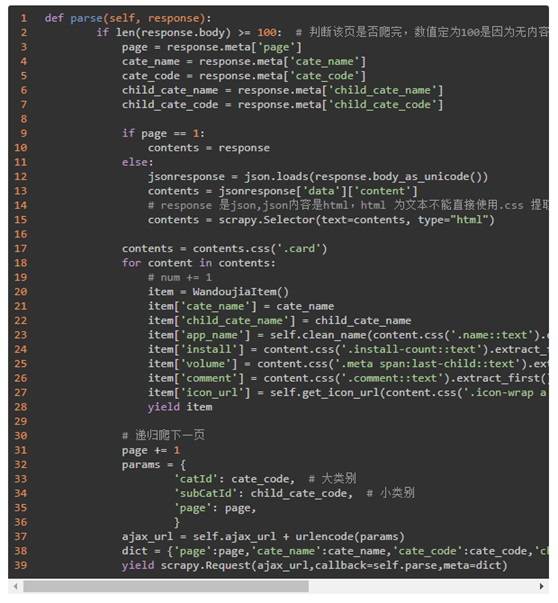
最后,parse() 方法用来解析提取最终我们需要的 App 名称、安装量等信息,解析完成一页后,page 进行递增,然后重复调用 parse() 方法循环解析,直到解析完全部分类的最后一页。
最终,几个小时后,我们就可以完成全部 App 信息的抓取,我这里得到 73,755 条信息和 72,150 个图标,两个数值不一样是因为有些 App 只有信息没有图标。
图标下载:
下面将对提取的信息,进行的数据分析。
三、数据分析
1. 总体情况
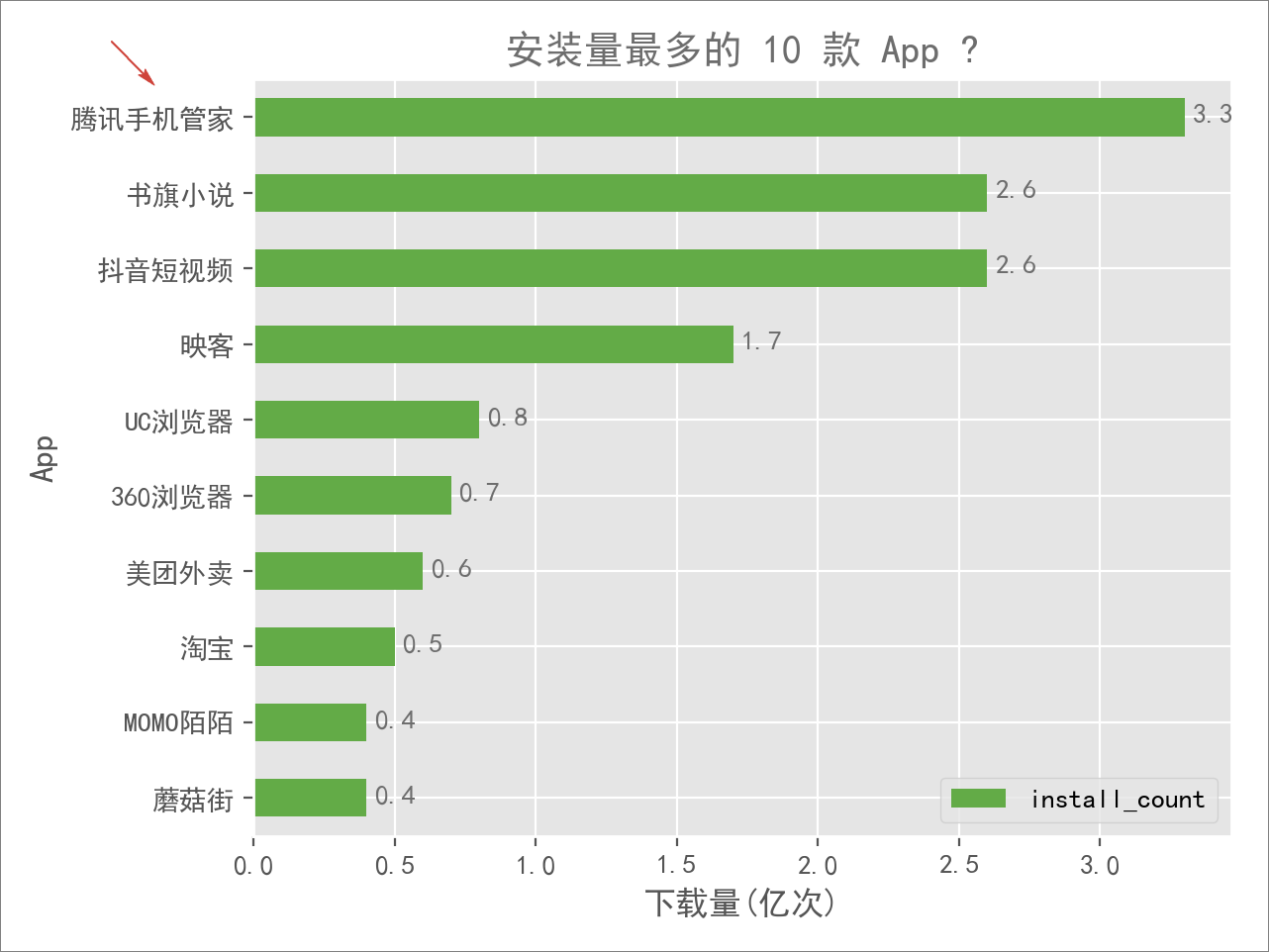
首先来看一下 App 的安装量情况,毕竟 70000 多款 App,自然很感兴趣 哪些 App 使用地最多,哪些又使用地最少。
代码实现如下:
看了上图,有两个「没想到」:
- 排名第一的居然是一款手机管理软件对豌豆荚网上的这个第一名感到意外,一是,好奇大家都那么爱手机清理或者怕中毒么?毕竟,我自己的手机都「裸奔」了好些年;二是,第一名居然不是鹅厂的其他产品,比入「微信」或者「QQ」。
- 榜单放眼望去,以为会出现的没有出现,没有想到的却出现了前十名中,居然出现了书旗小说、印客这些比较少听过的名字,而国民 App 微信、支付宝等,甚至都没有出现在这个榜单中。
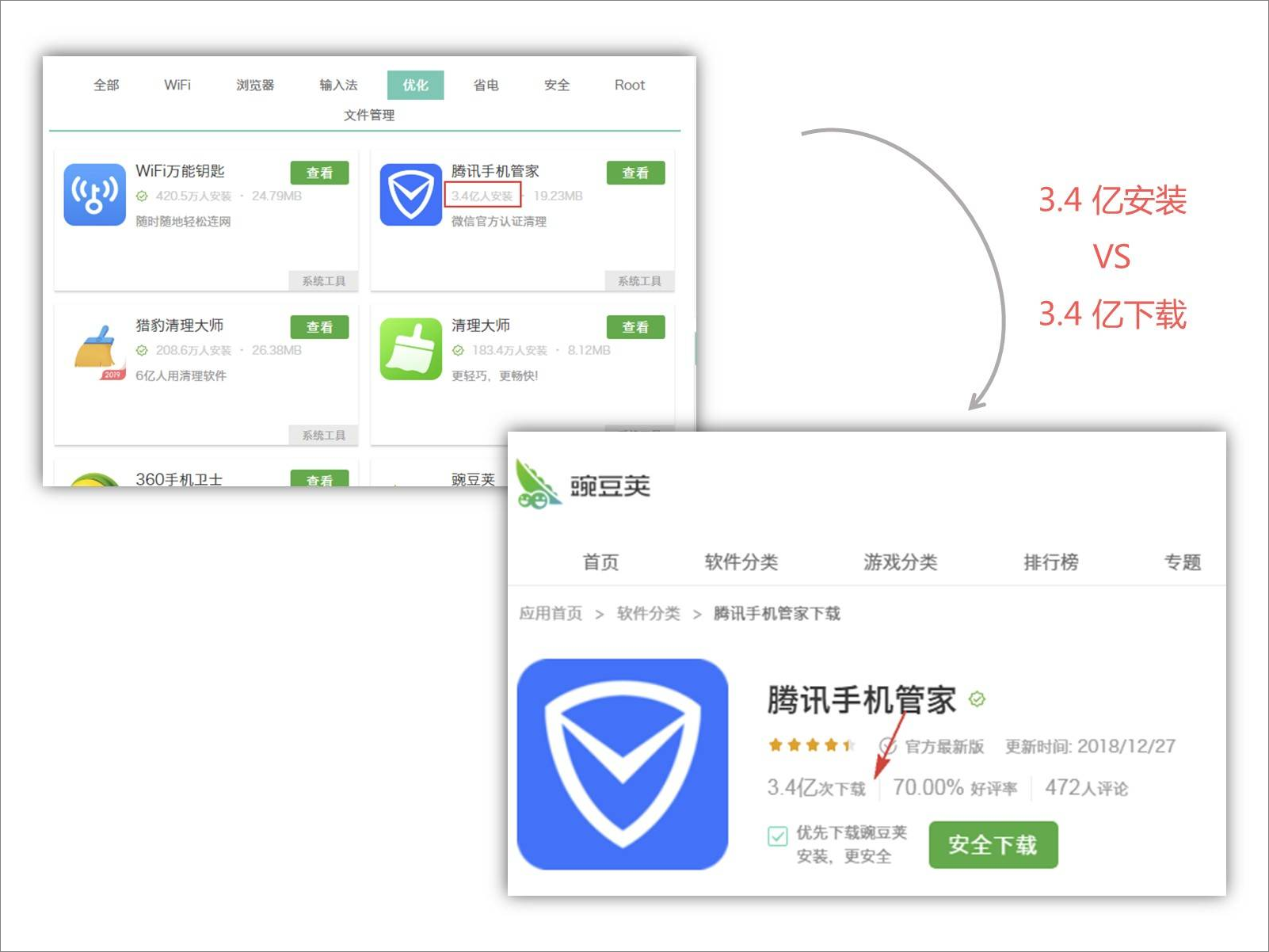
带着疑问和好奇,分别找到了「腾讯手机管家」和「微信」两款 App 的主页:
腾讯手机管家下载和安装量:
微信下载和安装量:
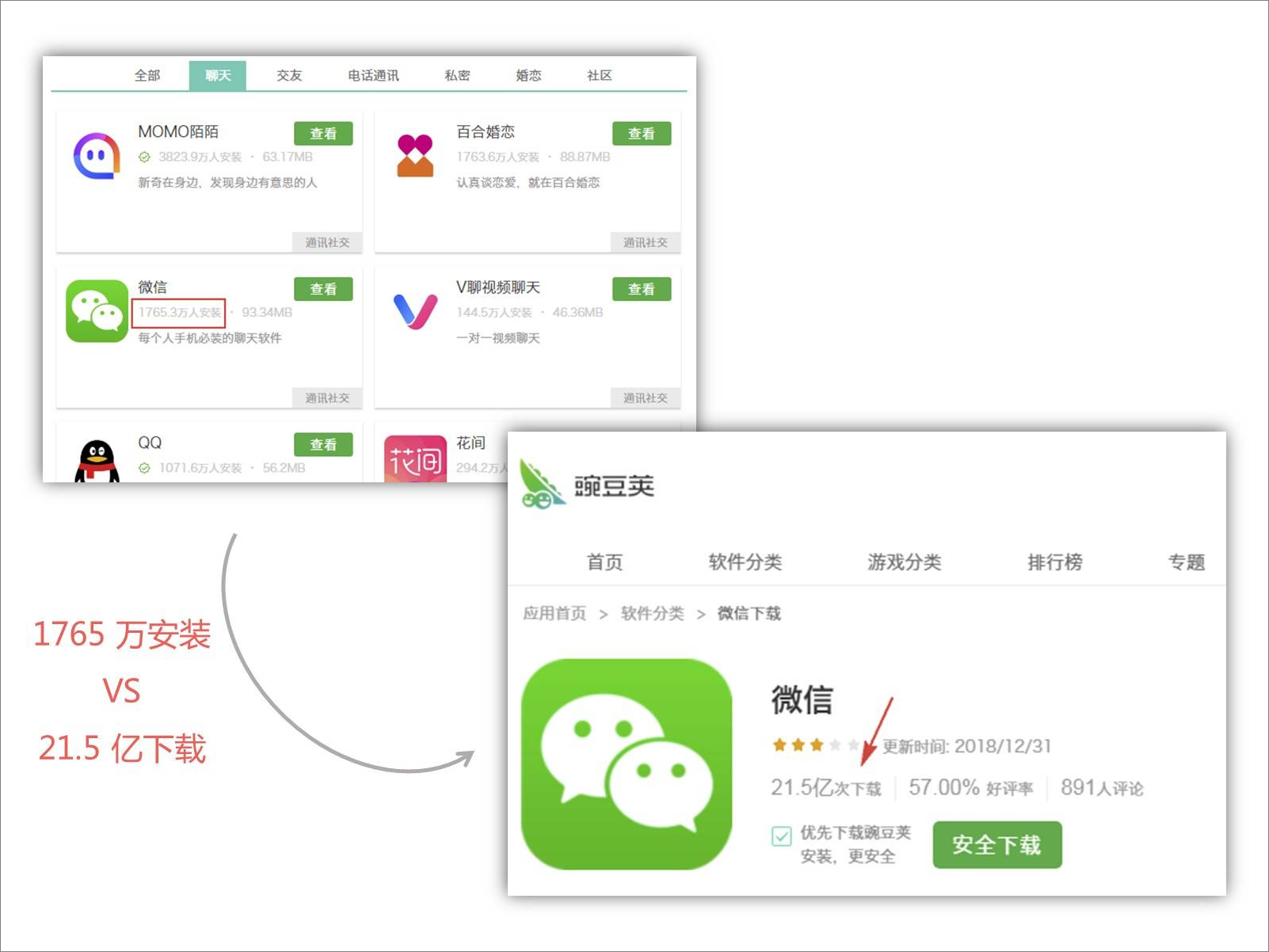
这是什么情况?
腾讯管家 3 亿多的下载量等同于安装量,而微信 20 多亿的下载量,只有区区一千多万的安装量,两组数据对比,大致反映了两个问题:
- 要么是腾讯管家的下载量实际并没有那么多?
- 要么是微信的下载量写少了?
不管是哪个问题,都反映了一个问题:该网站做得不够走心啊。
为了证明这个观点,将前十名的安装量和下载量都作了对比,发现很多 App 的安装量都和下载量是一样的,也就是说:这些 App 的实际下载量并没有那么多,而如果这样的话,那么这份榜单就有很大水分了。
难道,辛辛苦苦爬了那么久,就得到这样的结果?
不死心,接着再看看安装量最少的 App 是什么情况,这里找出了其中最少的 10 款:
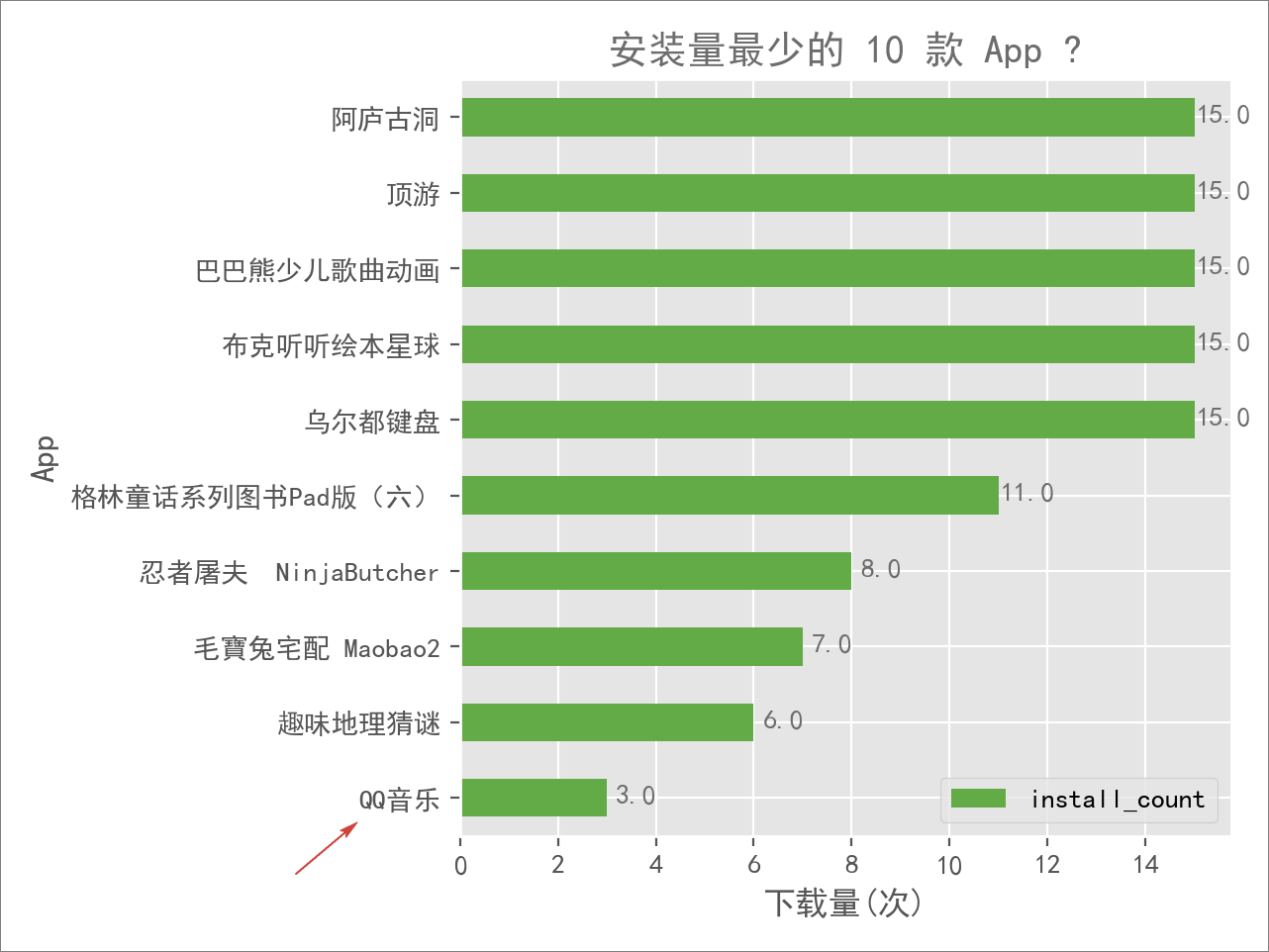
扫了一眼,更加没想到了:「QQ 音乐」竟然是倒数第一,竟然只有 3 次安装量!
确定这和刚刚上市、市值千亿的 QQ 音乐是同一款产品?
再次核实了一下:
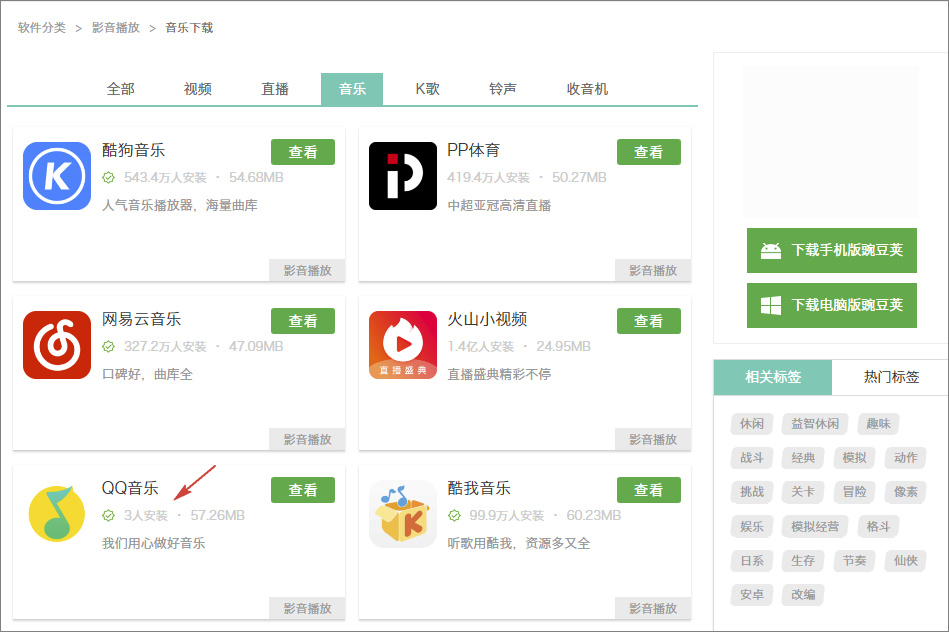
没有看错,是写着 3人安装!
这是已经不走心到什么程度了? 这个安装量,鹅厂还能「用心做好音乐」?
说实话,到这儿已经不想再往下分析下去了,担心爬扒出更多没想到的东西,不过辛苦爬了这么久,还是再往下看看吧。
看了首尾,我们再看看整体,了解一下全部 App 的安装数量分布,这里去除了有很大水分的前十名 App。
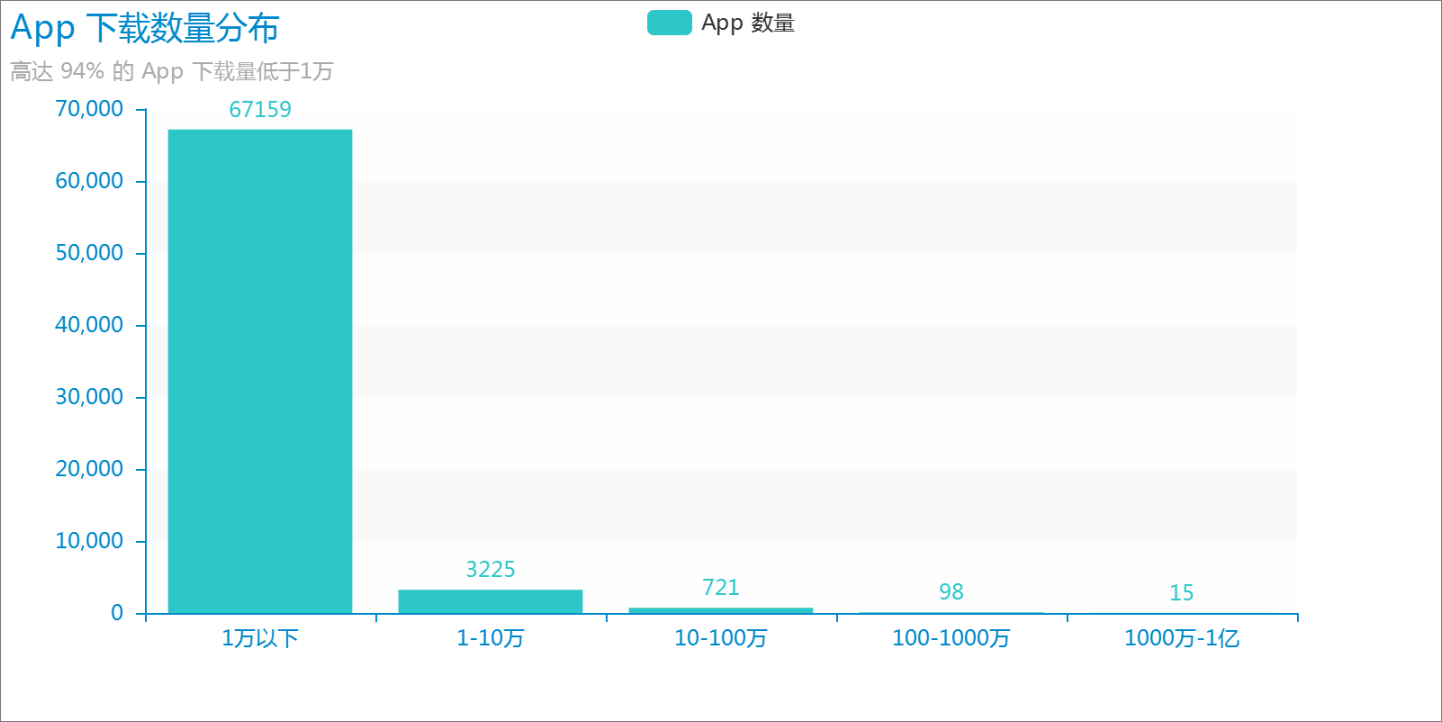
很惊讶地发现,竟然有 多达 67,195 款,占总数的 94% 的 App 的安装量不足 1万!
如果这个网站的所有数据都是真的话,那么上面排名第一的手机管家,它 一款就差不多抵得上这 6 万多款 App 的安装量了!
对于多数 App 开发者,只能说:**现实很残酷,辛苦开发出来的 App,用户不超过 1万人的可能性高达近 95% **。
代码实现如下:
2. 分类情况
下面,我们来看看各分类下 App 情况,不再看安装量,而看数量,以排出干扰。
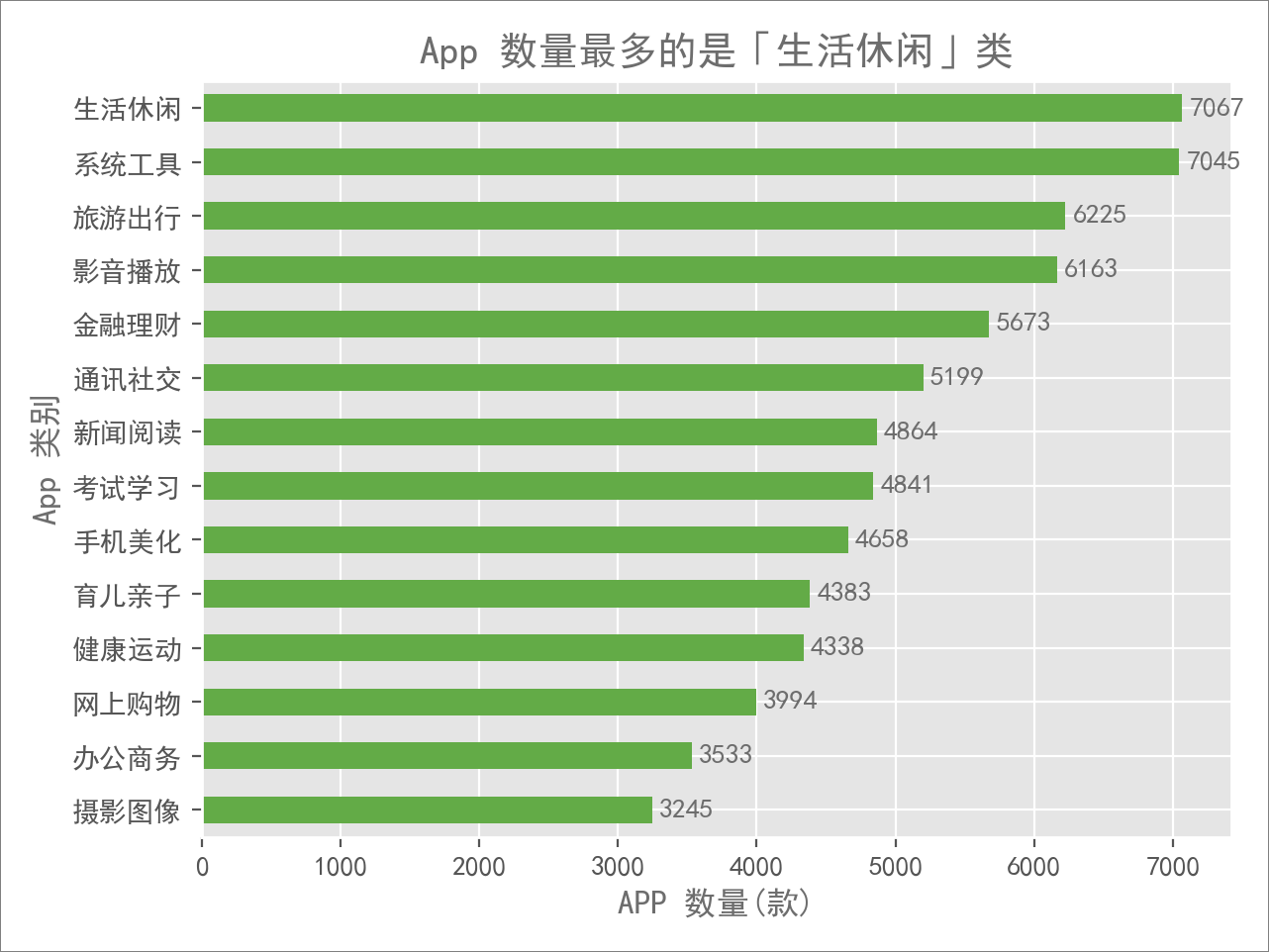
可以看到 14 个大分类中,每个分类的 App 数量差距都不大,数量最多的「生活休闲」是「摄影图像」的两倍多一点。
接着,我们进一步看看 88 个子分类的 App 数量情况,筛选出数量最多和最少的 10 个子类:
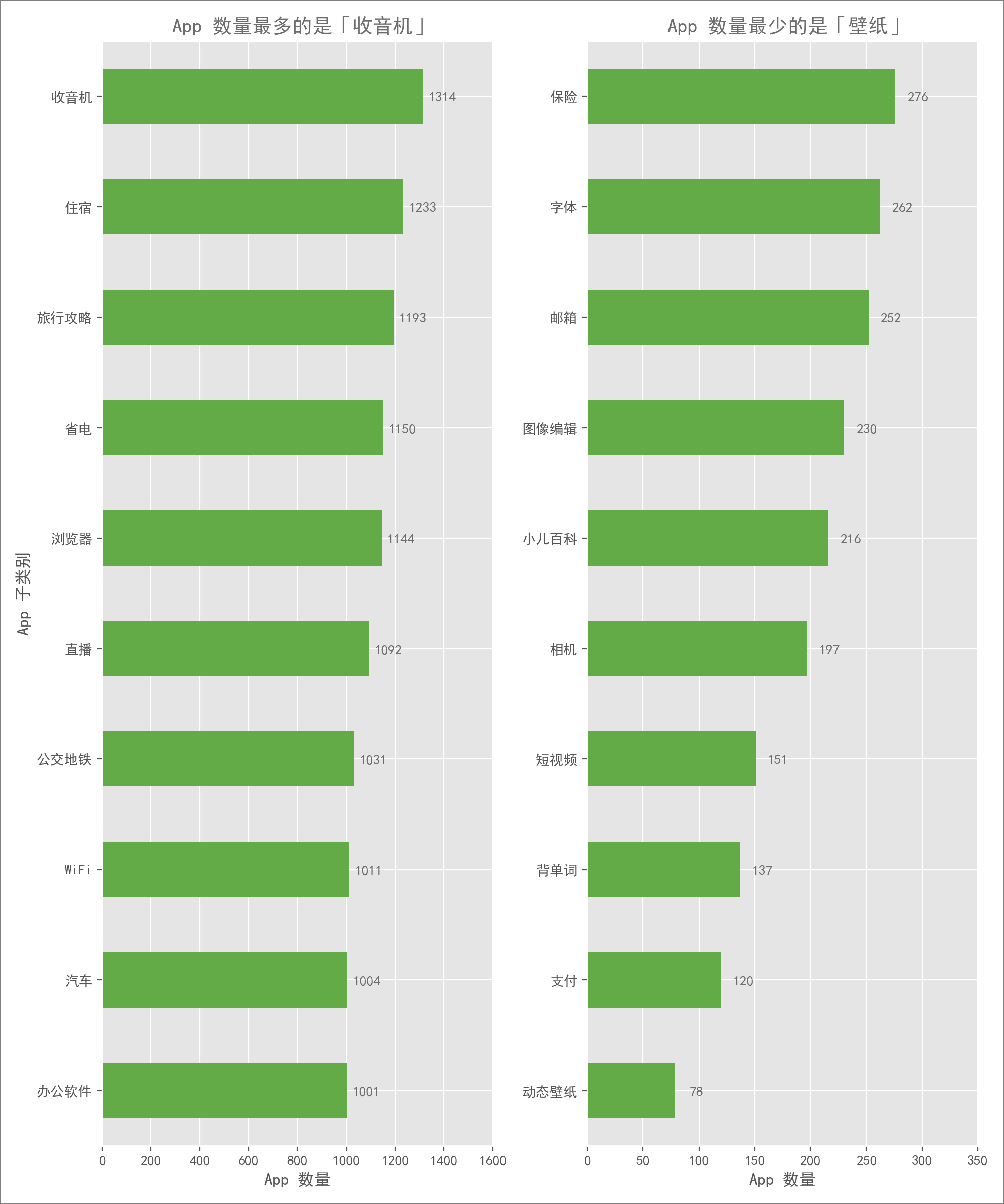
可以发现两点有意思的现象:
- 「收音机」类别 App 数量最多,达到 1,300 多款这个很意外,当下收音机完全可以说是个老古董了,居然还有那么人去开发。
- App 子类数量差距较大最多的「收音机」是最少的「动态壁纸」近 20 倍,如果我是一个 App 开发者,那我更愿意去尝试开发些小众类的 App,竞争小一点,比如:「背单词」、「小儿百科」这些。
看完了总体和分类情况,突然想到一个问题:这么多 App,有没有重名的呢?
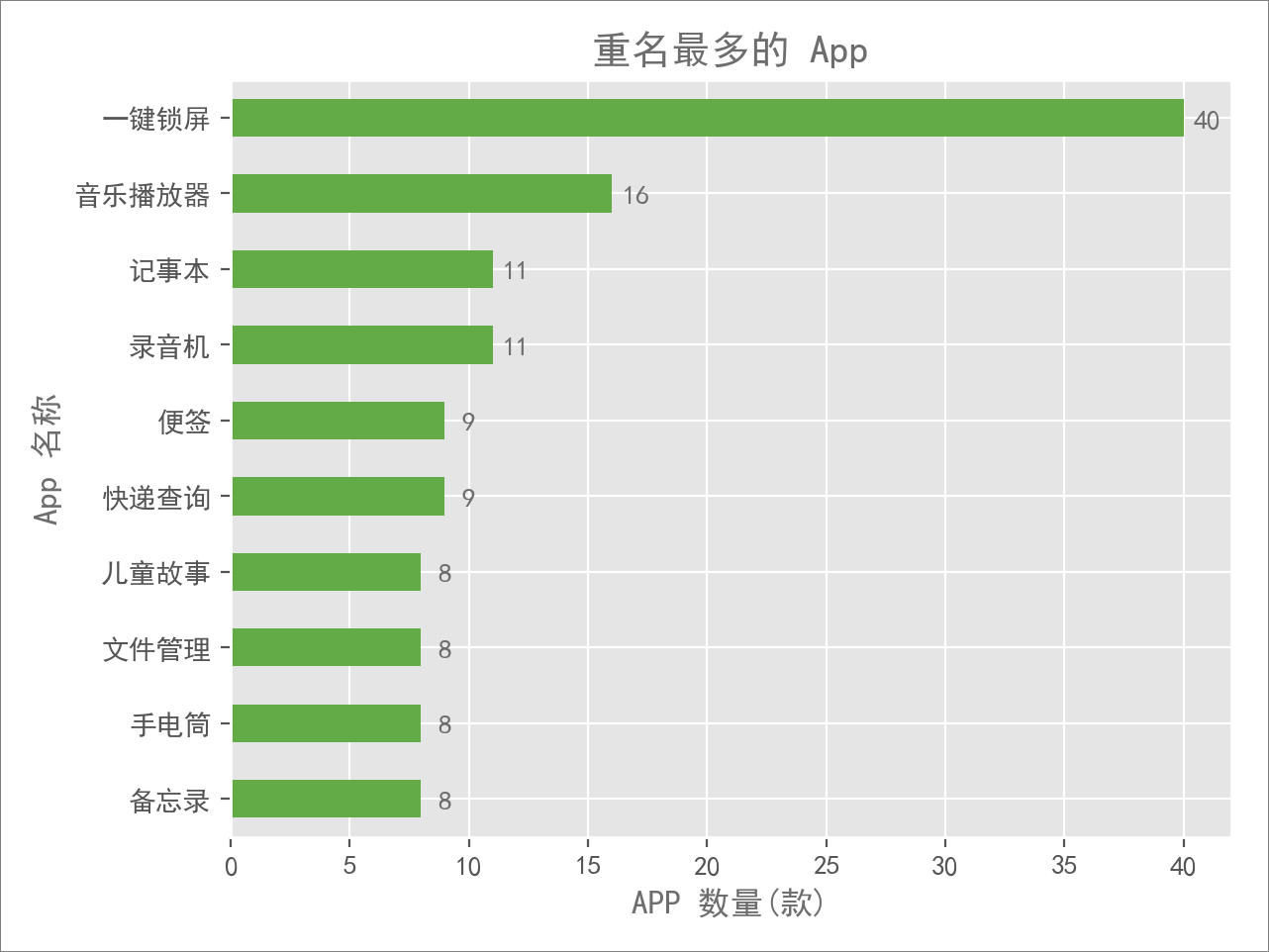
惊奇地发现,叫「一键锁屏」的 App 多达 40 款,这个功能 App 很难再想出别的名字了么?现在很多手机都支持触控锁屏了,比一键锁屏操作更加方便。
接下来,我们简单对比下豌豆荚和酷安两个网站的 App 情况。
3. 对比酷安
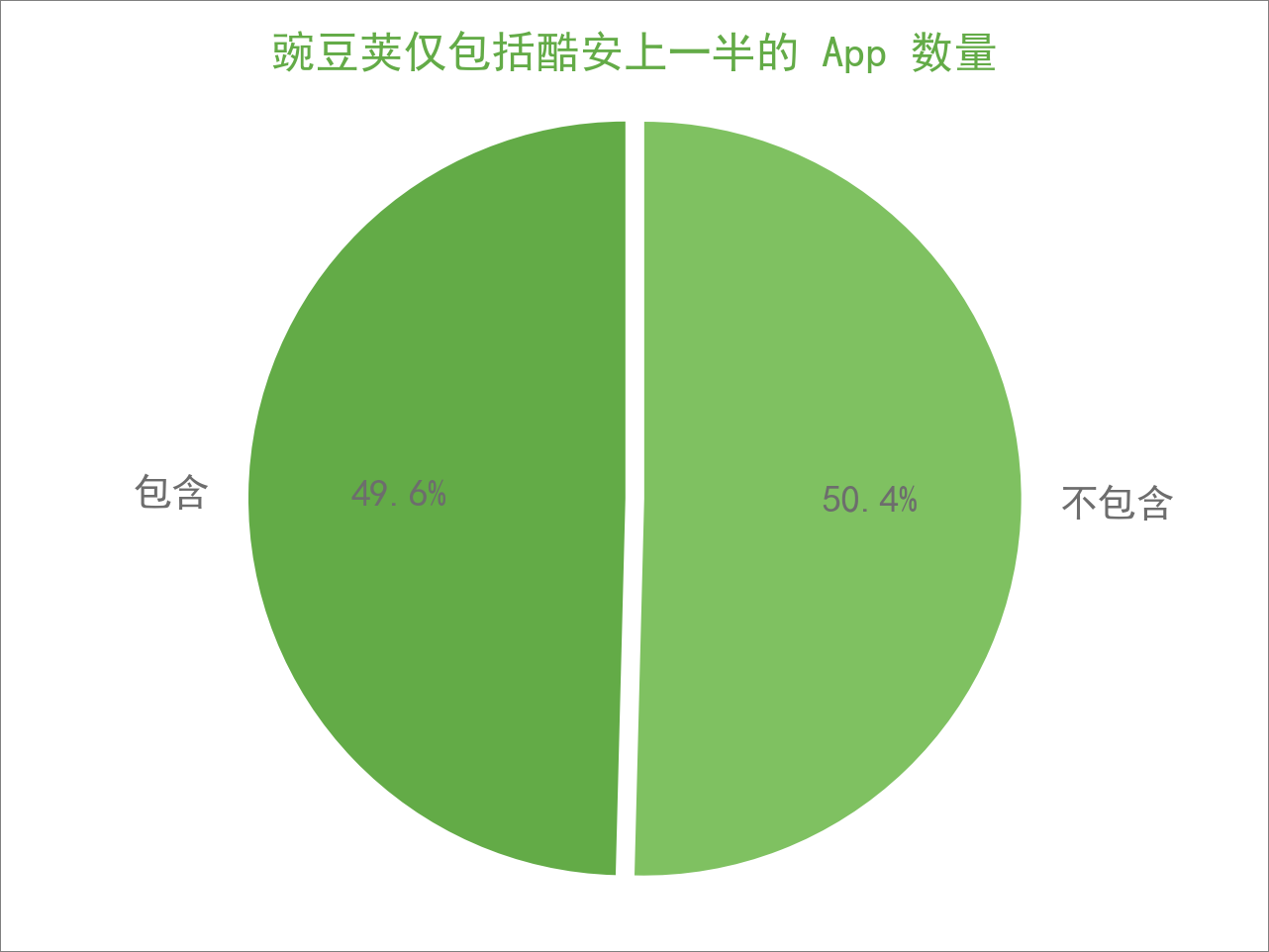
二者最直观的一个区别是在 App 数量上,豌豆荚拥有绝对的优势,达到了酷安的十倍之多,那么我们自然感兴趣:豌豆荚是否包括了酷安上所有的 App ?
如果是,「你有的我都有,你没有的我也有」,那么酷安就没什么优势了。统计之后,发现豌豆荚 仅包括了 3,018 款,也就是一半左右,剩下的另一半则没有包括。
这里面固然存在两个平台上 App 名称不一致的现象,但更有理由相信酷安很多小众的精品 App 是独有的,豌豆荚并没有。
代码实现如下:
接下来,我们看看所包含的 App 当中,在两个平台上的下载量是怎么样的:
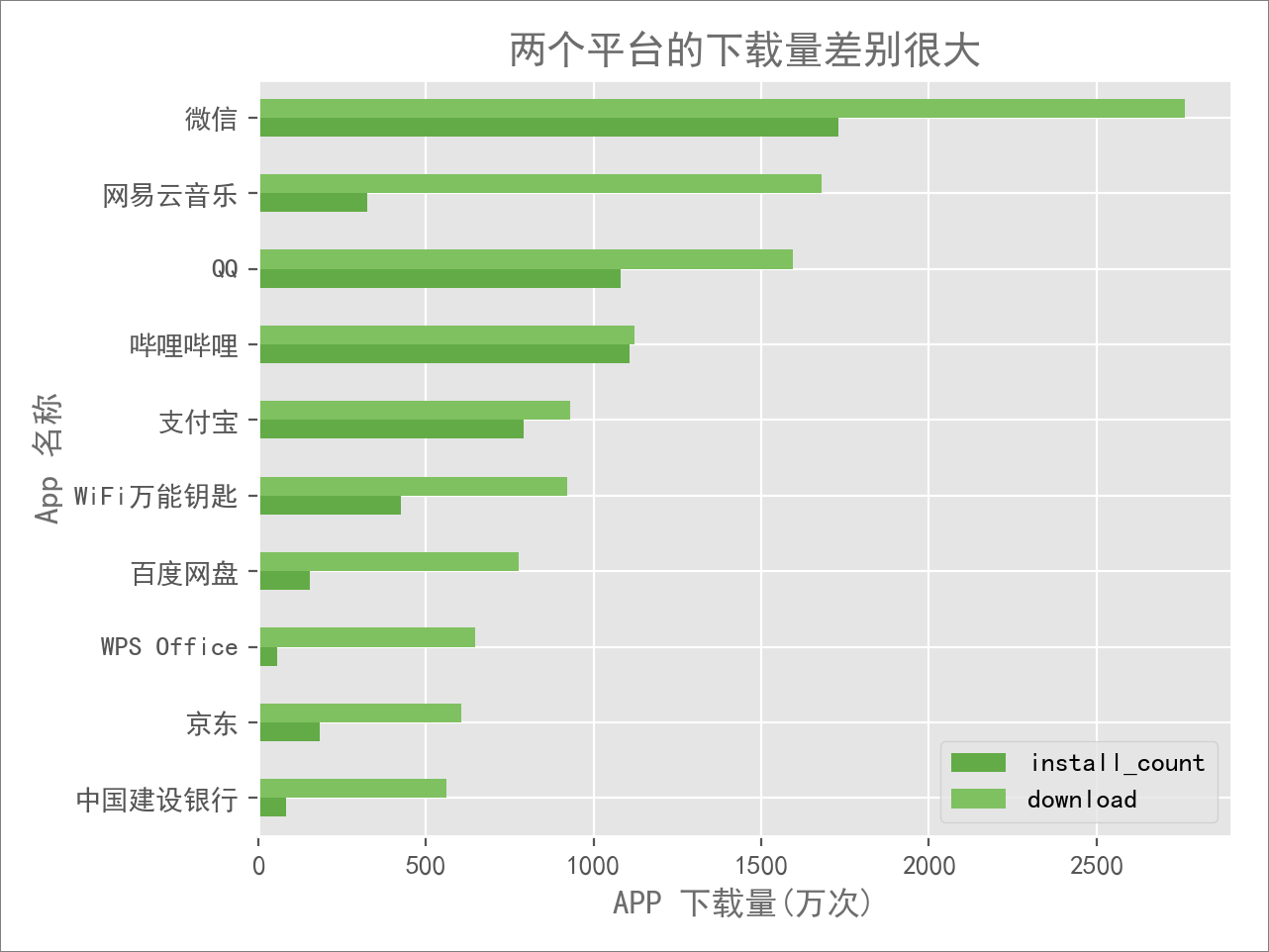
可以看到,两个平台上 App 下载数量差距还是很明显。
最后,我面再看看豌豆荚上没有包括哪些APP:
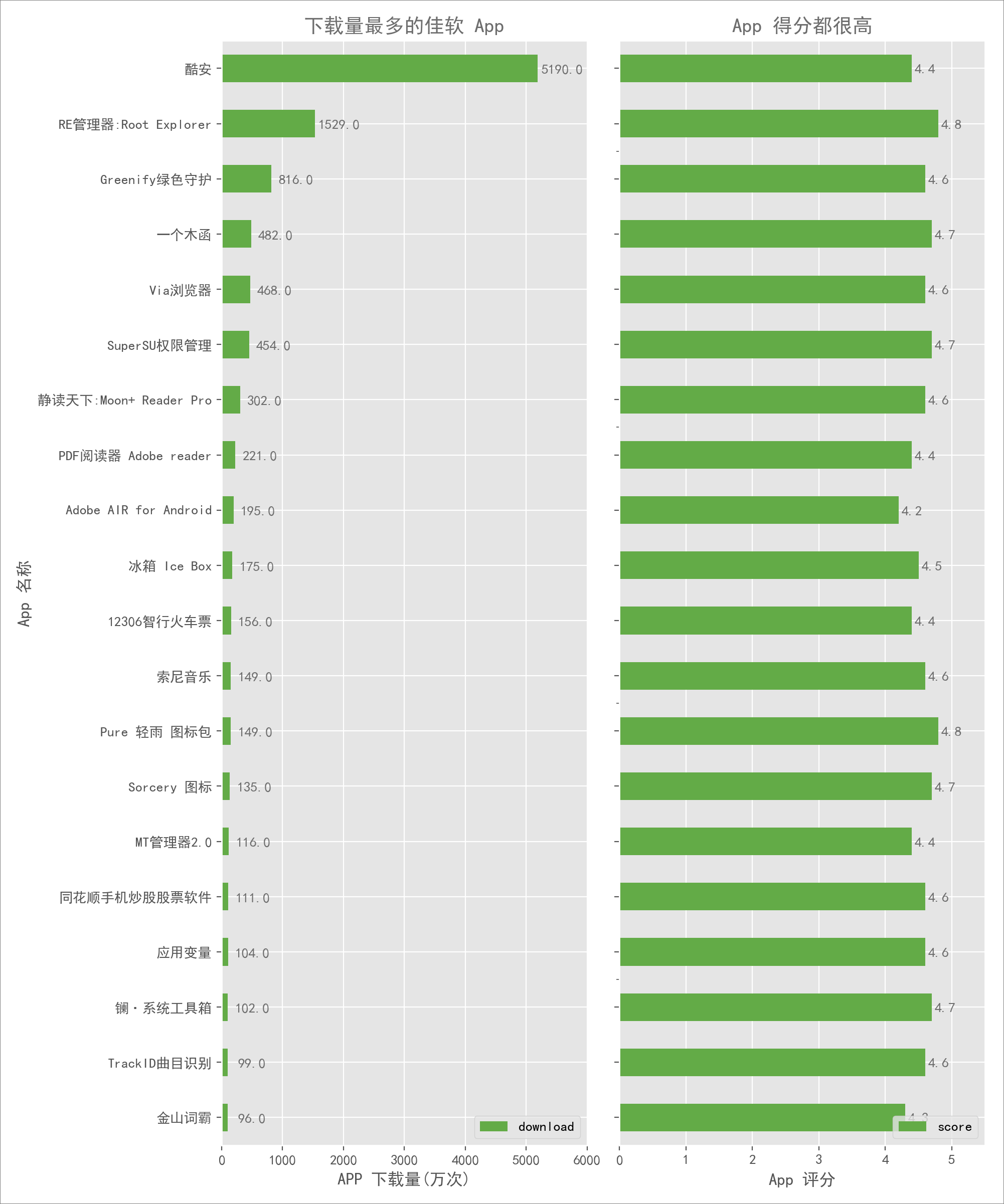
可以看到很多神器都没有包括,比如:RE、绿色守护、一个木函等等。豌豆荚和酷安的对比就到这里,如果用一句话来总结,我可能会说:豌豆荚太牛逼了, App 数量是酷安的十倍,所以我选酷安。
以上,就是利用 Scrapy 爬取分类多级页面的抓取和分析的一次实战。
作者:高级农民工,公众号:第2大脑
本文由 @高级农民工 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议
















技术型产品经理啊
酷安机佬前来留言
机佬666
你说的神器,我曾用过re,另外一个没听说过,我只从华为市场下app
酷安谁用谁知道