
 起点课堂会员权益
起点课堂会员权益数据的征服:读《大数据时代》

谷歌有一个名为“谷歌流感趋势”的工具,它通过跟踪搜索词相关数据来判断全美地区的流感情况(比如患者会搜索流感两个字)。近日,这个工具发出警告,全美的流感已经进入“紧张”级别。它对于健康服务产业和流行病专家来说是非常有用的,因为它的时效性极强,能够很好地帮助到疾病暴发的跟踪和处理。事实也证明,通过海量搜索词的跟踪获得的趋势报告是很有说服力的,仅波士顿地区,就有700例流感得到确认,该地区目前已宣布进入公共健康紧急状态。
这个工具工作的原理大致是这样的:设计人员置入了一些关键词(比如温度计、流感症状、肌肉疼痛、胸闷等),只要用户输入这些关键词,系统就会展开跟踪分析,创建地区流感图表和流感地图。谷歌多次把测试结果(蓝线)与美国疾病控制和预防中心的报告(黄线)做比对,从下图可知,两者结论存在很大相关性:
但它比线下收集的报告强在“时效性”上,因为患者只要一旦自觉有流感症状,在搜索和去医院就诊这两件事上,前者通常是他首先会去做的。就医很麻烦而且价格不菲,如果能自己通过搜索来寻找到一些自我救助的方案,人们就会第一时间使用搜索引擎。故而,还存在一种可能是,医院或官方收集到的病例只能说明一小部分重病患者,轻度患者是不会去医院而成为它们的样本的。
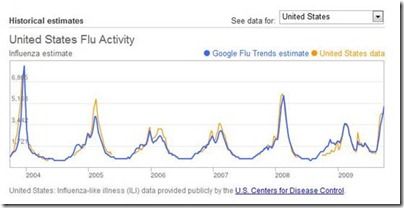
这就是一个典型的“大数据”的应用例子,舍恩伯格的这本《大数据时代》受到了广泛的赞誉,他本人也因此书被视为大数据领域中的领军人物。大数据起源于数据的充裕,舍恩伯格在他的另外一本书《删除》中,提到了这些源头。
1、信息的数字化,使得所有信息都可以得到一个完美的副本;2、存储器越来越廉价,大规模存储这些数字信息成本极低;3、易于提取:数据库技术的完善使得这些存储的信息能够被轻易按照一定的条件搜索出来;4、全球性覆盖,网络是无国界的,a地的数字信息可以让远在天边的b地调用。
当我们掌握有大量的数据后,便可以开始进行所谓“大数据”的操作。大数据在舍恩伯格看来,一共具有三个特征:
全样而非抽样,效率而非精确,相关而非因果。
第一个特征非常好理解。在过去,由于缺乏获取全体样本的手段,人们发明了“随机调研数据”的方法。理论上,抽取样本越随机,就越能代表整体样本。但问题是获取一个随机样本代价极高,而且很费时。人口调查就是典型一例,一个稍大一点的国家甚至做不到每年都发布一次人口调查,因为随机调研实在是太耗时耗力了。
但有了云计算和数据库以后,获取足够大的样本数据乃至全体数据,就变得非常容易了。谷歌可以提供谷歌流感趋势的原因就在于它几乎覆盖了7成以上的北美搜索市场,而在这些数据中,已经完全没有必要去抽样调查这些数据:数据仓库,所有的记录都在那里躺着等待人们的挖掘和分析。
第二点其实建立在第一点的基础上。过去使用抽样的方法,就需要在具体运算上非常精确,因为所谓“差之毫厘便失之千里”。设想一下,在一个总样本为1亿人口随机抽取1000人,如果在1000人上的运算出现错误的话,那么放大到1亿中会有多大的偏差。但全样本时,有多少偏差就是多少偏差而不会被放大。诺维格,谷歌人工智能专家,在他的论文中写道:大数据基础上的简单算法比小数据基础上的复杂算法更加有效。
数据分析并非目的就是数据分析,而是有其它用途,故而时效性也非常重要。精确的计算是以时间消耗为代价的,但在小数据时代,追求精确是为了避免放大的偏差而不得已为之。但在样本=总体的大数据时代,“快速获得一个大概的轮廓和发展脉络,就要比严格的精确性要重要得多”。
第三个特征则非常有趣。相关性表明变量A和变量B有关,或者说A变量的变化和B变量的变化之间存在一定的正比(或反比)关系。但相关性并不一定是因果关系(A未必是B的因)。
亚马逊的推荐算法非常有名,它能够根据消费记录来告诉用户你可能会喜欢什么,这些消费记录有可能是别人的,也有可能是该用户历史上的。但它不能说出你为什么会喜欢的原因。难道大家都喜欢购买A和B,就一定等于你买了A之后的果就是买B吗?未必,但的确需要承认,相关性很高或者说,概率很大。
舍恩伯格认为,大数据时代只需要知道是什么,而无需知道为什么,就像亚马逊推荐算法一样,知道喜欢A的人很可能喜欢B但却不知道其中的原因。这本书的译者天才教授周涛则有不同的看法,他认为,“放弃对因果性的追求,就是放弃了人类凌驾于计算机之上的智力优势,是人类自身的放纵和堕落”。
这个争议在我看来,双方讨论的可能不是一回事。舍恩伯格在这本书中完全不像他在《删除》一书中表现得那么有人文关怀,这是一本纯商业的书籍,商业本来就是以结果为导向的。但周涛谈论的却和“人工智能”有关。
吴军在他的《数学之美》中曾经提到,人工智能领域曾经走过一个很大的弯路,即人们总是试图让计算机理解人类的指令注意,是理解,不是知道。但折腾了很多年,发现计算机的理解力实在白痴得比三岁小孩还要弱。最终人工智能放弃了这条途径,而改为数据传输和匹配。举个例子说,你在进行语音输入的时候,事实上计算机完全不知道你在说什么(或者说,完全不理解你的意思),但不妨碍它能够准确地把你说的话尽可能地用字符表达出来。苹果的Siri是很神奇,但它其实并不懂你的意思,而只是你的语音数据和它的后台数据一次匹配而已。
因果关系涉及到“理解”这个范畴,而不是简单的知道或匹配。舍恩伯格所谓放弃因果而寻求相关,是因为他本来就是写本商业书,要具体指导商业运作的,周涛所谓不可放弃因果,因为他是一名学者,并不完全站在赚钱这个角度上。换而言之,周涛看的是长远的未来,舍恩伯格讨论的是眼下。
在可以看到的未来中,可能计算机掌握不了三岁小孩的理解力,计算机和人类之间的象棋比赛,一个在思考,一个在做数据匹配,两者虽然都在下棋,路径却全然不同。
人类可以暂时不用过于担心计算机来统治人类,因果关系这种理解,还是掌握在人类手中的。
大数据时代是信息社会运作的必然结果,而借由它,人类的信息社会更上一个台阶。农业社会人们以土地为核心资源,工业时代转为能源,信息社会则将变更为数据。谁掌握数据,以及数据分析方法,谁就将在这个大数据时代胜出,无论是商业组织,还是国家文明。






- 目前还没评论,等你发挥!


