
 起点课堂会员权益
起点课堂会员权益知乎的另一面:如何用数据管理内容

【导读】知乎已经走过了4个年头,在互联网的世界里,知乎已经成为无可争议的高质量社区,但在经历了高速发展之后,如何管理,筛选,呈现这些大量的信息(数据)成为一个难题,事实上无论对于哪一个社区而言,数据的管理本身就是一个巨大的挑战。下面是知乎联合创始人在七牛大会上的关于知乎数据方面的演讲,稍作删减。
大家好,我是知乎的李申申。首先,我想对主办方说一声:谢邀!感谢你们搭建这样一个专业的平台,让大家有机会聚在一起认真讨论数据这个话题。
说实话,在接到大会邀请的时候,我第一反应想到了这句话。
Big data is like teenage sex: everyone talks about it, nobody really knows how to do it, everyone thinks everyone else is doing it, so everyone claims they are doing it…- Dan Ariely .
如同Dan Ariely所说,知乎也像是众多面对大数据很懵懂的「年轻人」之一;我们虽然也在做大数据相关的一些事情,但其实比较粗浅。我听说今天在座的各位有不少都是知乎的用户,对知乎有一些兴趣,那我就借这个机会跟大家分享一下知乎数据方面的一些工作。
简单进入正题,我们先来看看知乎的基本数据情况。
今天的知乎
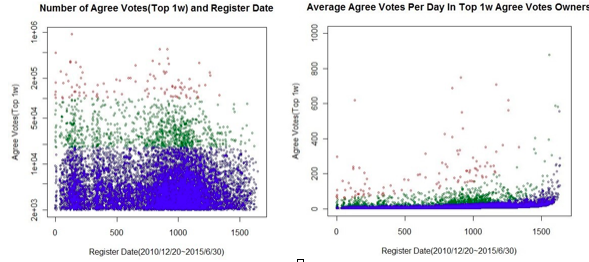
截至2015年7月,知乎社区已拥有2900万注册用户,月UV1.1亿,月累积页面浏览量达3亿。现在知乎全站已累计产生约620万个问题,以及近2000万个回答。用户总回答4,129,244,445字数,是大不列颠百科全书的近100倍,鹿鼎记的2580倍。 除了以上比较基础的数据,一些其他方面的数字也在以令我们比较欣喜的速度发展着。我们截取了知乎开放注册以来,获得一千个以上赞同的回答和千字以上的回答两个数据,看一下它们的增长情况。可以看到,这两项数据都是保持了一个比较平稳的增长趋势的。再看一下,这些用户日均获赞的数量。 首先,必须说明的是:我们并非完全将这两项指标作为有价值回答的判断标准,但是当用户愿意静下心来花时间撰写长文回答的时候,至少他的态度是认真的,也符合知乎所倡导的讨论理念。另一方面,知乎上的千赞代表了1000位知乎用户对此回答的认同和接纳。除开2月份等过年过节的时期数据会略低些,其他时间,这一数据增速基本都保持在 10% 左右。 同样基于话题这个维度,我们随机抽取几个话题看最近的用户讨论趋势。 这里展示的是心理学、互联网、经济以及天津爆炸这几个话题。 值得注意的一点在于,在天津爆炸事件席卷几乎所有社交和舆论平台,非常聚焦地引起爆炸性的关注时,知乎站内的其他专业话题讨论依然在持续进行。同时, 由于天津事件后续的各讨论环节中有不少涉及心理学的疑问,因此,知乎站内心理学的话题热度也被带动着略有上扬。 综合看,现在的知乎更像是个广场,各类较为热点的时事讨论好像是广场中央的喷泉,吸引了游客和大众的关注目光。而与此同时,在广场四周也有着各色酒吧、咖啡馆和茶馆等,各自汇聚了城市的居民们与知己倾心交谈。 有不少知乎用户曾有疑虑,是否只有早期的用户们才较为认同知乎的社区理念,又或是只有老用户们容易收获赞同和关注?其实并不尽然。 让我们一起看看以下几组数据截图,横轴为时间变化,我们截取了2010年12月20日知乎内测以来到2015年6月30日赞同数前10000的用户,根据他们的注册时间和赞同数作图,以及日均的赞数增长量。大家可以看到这些点分布的比较散,说明增长情况比较均匀。 可以看出:即使在2015年才刚加入知乎的人也有非常大的机会被关注和认可。这也说明,这些新用户也有认真讨论、获得有价值信息交换的渴望,这些用户也是非常认同知乎的社区理念的。可以通用的秘诀在于:只要坚持不断地在自己擅长的领域参与讨论、输出信息就能得到更多人的认可。 前面几张图,我们已经了解了知乎的百花齐放的话题和持续贡献的优质用户。下面我们来看看知乎信息生产方式,为了更聚焦的展示这个问题, 我们选取了近期的天津爆炸事件作为事例。 从发展方式来看,热点话题与其他话题相比,并没有不同。但是由于其新闻性,这类话题的发展更具有爆发性, 用户的行为更为集中。因此,也更方便我们来做这样一个展示。 首先,一批用户针对问题进行关注、回答,产生了基础的优质内容,然后,其他用户的自发邀请、关注、收藏、感谢、投票、评论等社交行为,使得这些内容获得了更广泛的传播和关注,覆盖的人群不断扩大。 在知乎,社交行为催生了优质内容的生产与传播,而优质内容又引发了下一轮新的社交行为。 用户在知乎上的行为是多维度的;既包括比较轻的浏览阅读,又包括重一些的赞同、反对,还有更重的提问回答(这里的重和轻是根据用户操作成本来界定的)。我们可以根据这些行为做用户的特征分析,这也是各个互联网服务都会做的常规工作,只是基于各自不同的服务特点,所要分析的特征、采用的算法及其效果各有不同。知乎除了有大量的用户行为数据,还有非常多的文本信息,基于行为和文本,我们对用户的兴趣和擅长能有更准确的识别。 现实社会中,我们对于某些领域的知识掌握是很深入的,但其他的一些领域就未必了。个人精力是有限的,没有人能够全知到成为所有领域的专家,这种情况是可以被映射到知乎上的。不同的用户在不同的话题领域下,他们的专业性是不同的,我们需要掌握这种不同,给每个人,在每个话题下计算一个权重。计算的分值最主要的依据还是那些你在知乎上的回答,当然,我们也会加入一些其他考量因素,包括其他专业人士对你的背书,你的专业背景,等等。 这是知乎非常基础的数据设施,但这个数值计算的量级是不小的(百万回答用户 十万话题,是千亿级别的数量计算),知乎对于权重判定每周都会进行全量的计算,也一直在调整优化中。 我们对答案排序算法进行优化,目的是让好的答案更靠前。随着用户量不断增加,早期最简单的答案排序规则出现了问题:一些答案友情赞同比较多,让专业性不足的答案被推到靠前的位置。我们想到了给赞同票加权重的方法,基于每个人在话题下的专业权重来计算,排序得到优化,能让大部分优质答案可以排到前面。 虽然针对权重计算的优化仍然在持续进行,我们还是遇到了一些算法上的瓶颈。 当问题下有多个发布较早的回答获得高票时,新的回答即使质量很高,也很难在问题页上获得足够的曝光,难以积累更多赞同票,一些误导性、煽动性的高票内容,即使同时也有很多反对票,仍然排在认真、严谨但票数相对较少的优质回答前面。 这些问题在专业领域内对参与讨论的用户造成的伤害尤其明显。这绝不是我们希望看到的。于是,我们又设计了新的排序算法。 新排序算法的思想是,如果把一个回答展示给很多人看并让他们投票,内容质量不同的回答会得到不同比例的赞同和反对票数,最终得到一个反映内容质量的得分。当投票的人比较少时,可以根据已经获得的票数估计这个回答的质量得分,投票的人越多则估计结果越接近真实得分。如果新一个回答获得了 1 票赞同 0 票反对,也就是说参与投票的用户 100% 都选了赞同,但是因为数量太少,所以得分也不会太高。如果一小段时间后这个回答获得了 20 次赞同 1 次反对,那么基于新算法,我们就有较强的信心把它排在另一个有 50 次赞同 20 次反对的回答前面。原因是我们预测当这个回答同样获得 50 次赞同时,它获得的反对数应该会小于 20。 威尔逊得分算法最好的特性就是,即使前一步我们错了,现在这个新回答排到了前面,获得了更多展示,在它得到更多投票后,算法便会自我修正,基于更多的投票数据更准确地计算得分,从而让排序最终能够真实地反映内容的质量。 我们的新算法年初发布之后,得到知乎站内的用户热烈反馈,也算是做知乎这样产品的好处吧,很多专业的讨论涌现出来,为我们下一步优化提供了很好的想法。 首页的内容会主要考虑这几方面: 1、内容本身的话题领域要跟用户有关,是用户感兴趣的,一个对汽车不感兴趣的用户,即便给他推送最优质的汽车内容,他也会觉得无趣。 2、知乎是一个社交网络,用户的社交行为会产生影响,用户的行为会带来关注他的人首页的变化。 3时间因素,一些内容及时出现在你面前,可以让它的价值更大 知乎的首页有一套专用的数据收集和处理机制,可以记录用户在首页的所有重要动作,比如,如果某条内容出现在用户浏览器窗口或手机屏幕的可见范围内,就会记录一次。 以及…… 知乎还有一些其他的数据优化,我举几个例子做简单介绍。 1.邀请回答 稍微熟悉知乎的用户,应该知道谢邀这个词,这个产品功能是为每一个问题找到合适的回答者,推荐给用户。我们采取一种算法模型预测某个用户回答某问题的可能性和回答质量。有 90% 的邀请是通过这种推荐结果发出的,剩下 10% 是用户主动搜索产生的 每周知乎精选邮件(eDM) 针对每个用户做了个性化的计算,通过不断的算法优化,我们已经做到了30%的打开率和14%的点击率。 2.问题聚类 众所周知想对问题的文本进行聚类,最先想到的是通过文本语义匹配,通过复杂的词袋模型(如传统的plsa,LDA,新的word2vec等)对问题文本进行向量化,这样通过语义将相关问题聚类起来。 知乎站内拥有庞大的用户浏览数据,如果将这些浏览数据通过简单地算法(如协同过滤)建立一个模型同样也能达到很好地效果。 知乎每天的问答浏览量能够达到千万级别,这样就意味着输入给算法的user-item的边数每天能够达到千万以上,近3个月的浏览数据就可以达到10亿条边。在知乎的数据平台上需要近一小时的时间来建立模型,从聚类的结果中可以看出,即使不使用任何文本相关的分析,单靠用户浏览的行为分析就可以很好地对问题进行聚类。 这也印证了一点:大数据基础上的简单算法比小数据基础上的复杂算法更加有效。 本文来源于:虎嗅网知乎大V和知乎小白
知乎信息如何生产,以及如何流动?
如何用大数据做用户兴趣识别?
答案排序:如何更好的呈现?
首页Feed的自我修养:内容的个性化推荐





- 目前还没评论,等你发挥!


