
 起点课堂会员权益
起点课堂会员权益评分算法(1):用户评分
从《社交网络》到豆瓣评分,这些都是用户评分的表现。文章介绍了用户评分算法的体系,并以豆瓣评分为例,展开了详细说明,包含贝叶斯公式和威尔逊区间法,与大家分享。

开一个新的系列:评分算法,先讲用户评分。
从下图的电影《社交网络》开始讲起,玻璃上的公式是ELO排名算法,可以将比较打分的结果量化为分数,为女生打分,这种算法目前主要应用在对战类游戏的排序中。这个算法我们不展开讲,感兴趣的朋友可以去网络搜相关资料。
我先给评分算法一个简单的定义:评分算法就是通过对已有数据进行计算,量化评估某一类主体,从而实现对这一类主体的评价、考核和管理。在前面提到的例子中,被打分的主题就是大学女生的相貌,数据就是用户的打分。
在当前互联网中,产品连接着用户、商品、内容、服务、服务者,每一类主体都有着大量数据,评分方便其他角色对这些主体进行统一评估。与此同时,配送员、司机、教师、客服、销售这样的角色已经实现了自动化的分配,利用评分将这些角色的表现量化和可视化,也有利于对这些角色进行有效管理。
早上打车上班,如果你给司机一个评价,这个评价会被计入司机的服务分,影响司机师傅的派单和收入。中午打算点个外卖,你翻开了美团,看着商家评分,最终选择了你的外卖。晚上打算看个电影,翻看豆瓣电影评分,选择了一款评分不错的电影。作为消费者,评分无时不刻不在影响我们的消费选择,而我们的评分也成为了商业公司内部评分体系的一个数据源。
消费的评分体系相对比较简单,只涉及用户评价这一单一数据源,而内部评分体系需要考虑更多因素。本期先聊消费者评分,以豆瓣评分为例。
基于用户评价的排序策略,会面临不同内容的评分人数差距过大的问题。比如图书A有100个人打分,平均分是4.5分,图书B有5个人打分,平均分是4.6分,而同时全站平均分是3.0分,那么我们应该怎么给用户推荐呢?第一种思路是可以针对数据量少的打分,做一定程度的降权,如用下面较为简单的置信度降权函数:
rank=N/(N+X)·score
其中N为评分的数量,score为原始的评分值,X为可调节的参数。将X设为5时,函数为
rank=N/(N+5)·score
经过降权后,图书A的得分是4.29,图书B的得分是2.3,图书A的得分相对比较合理,但图书B远低于原始评分4.6,也低于全站平均分,可见这种方法对数据量小的内容有很大的抑制。用贝叶斯平均法便可避免这一问题,也就是第二种思路。
贝叶斯公式是统计学中的一个基本工具,可以作为很多策略设计的依据。还是用这个例子介绍其原理,即当一个内容还没有或者只有少量评分的时候,可以先认为这个内容的评分和大部分内容的平均评分差不多,只有当对这个内容的评分越来越多的时候,才能得到这个内容的评分。通用的贝叶斯平均公式如下,其中average表示全站平均分。
rank=X/(N+X)·average+N/(N+X)·score
依然假设X为5,全站平均分为3.0,那么图书A的得分是4.42,图书B的得分就是3.8。图书B的得分比置信度降权法高,且高于全站平均分,相对更加合理。
在有些场景下,如果希望评价少的内容出现在后面,则置信度降权法比贝叶斯平均法更适用;而希望给评分少的内容足够曝光时,贝叶斯平均法就比置信度降权法更适用。
当然,以上的调整方法看起来缺乏一些数学上的严谨性,那么有没有更严谨的算法呢?答案是肯定的。我个人觉得比较可靠的情况下是使用威尔逊区间法。
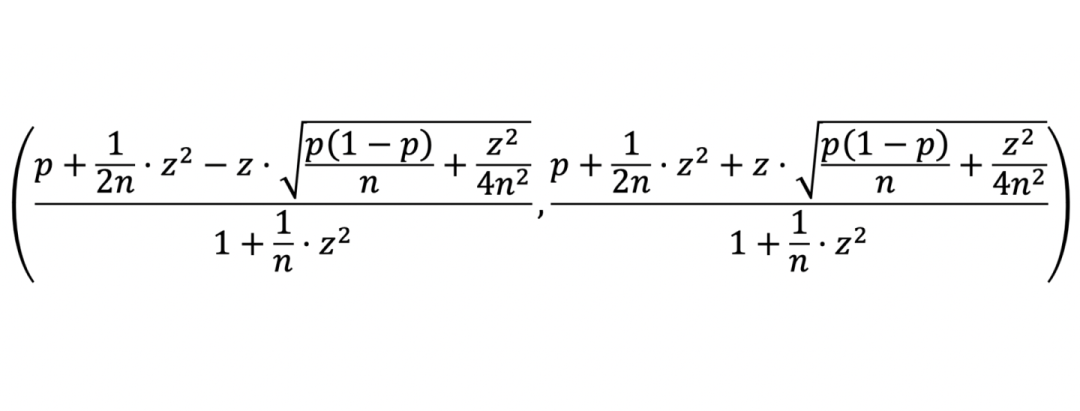
威尔逊区间可以在给定置信度的情况下,给出打分概率的置信区间。一般使用情况下,威尔逊区间适用于零一变量。比如用户是否点击视频、图片、广告,p就是用户点击概率,n是统计的数据量,z是给定置信度参数,常用的几个值,90%置信度下z=1.64,95%置信度下z=1.96,99%置信度下z=2.58,其他的都可以查表。在打分场景下,需要做的事情是将打分均值归一化为p值,比如平均分时3.5,满分5分,那么就是3.5/5=0.7。同时n取打分人数,z已经是置信度参数。
威尔逊区间法的好处是多样的。首先是统计上的合理性,无论数据量大小,都有一致的数学表达式。其次是在区间的上下界都有其业务意义。
在数据量较小的情况下,数据均值一定是不准的,对于业务而言,某些场景他们需要的是数据的上界,某些场景他们需要的是数据的下界。
比如,在排序策略中,当我们希望给长尾内容更多流量的时候,可以使用上界,当我们希望突出热门内容时,可以使用下界。
比如,在广告策略中,当我们希望关闭CPA过高的广告时,我们应该用下界,当我们希望关闭点击率更低的广告时,应该用点击率的上界。因为我们需要给新的广告更多的试探空间。
当然威尔逊区间算法的本质是提供了一个将大数据量内容和小数据量内容一起对照的方法,应用范围也不止于此,而“小数据下不置信”是大量策略系统的共同问题。
本期内容到此结束,下一期我们聊评分算法的另一个场景,服务分。
#专栏作家#
潘一鸣,公众号:产品逻辑之美,人人都是产品经理专栏作家。毕业于清华大学,畅销书《产品逻辑之美》作者;先后在多家互联网公司从事产品经理工作,有很多复杂系统的构建实践经验。
本文原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议










有个疑问,初始无数据的情况下,是手动设定打分还是依照算法?
公式没有看懂
您好,请教一下如何给填报情况评分
KPI1:填报数量大于150为达标,大于200为优秀;
KPI2:填报数量大于60为达标,大于80为优秀;
KPI3:填报数量大于20%为达标,大于25%为优秀;
最后统计填报情况并对填报机构评分排序
作为一个统计学专业的毕业生,11年过去了,全忘了 ➡