
 起点课堂会员权益
起点课堂会员权益语音交互:先从麦克风阵列聊起
 B端产品经理需要更多地遵循行业的标准和规范,而C端产品经理需要更多地创造行业的新趋势和模式。所以差异很大
B端产品经理需要更多地遵循行业的标准和规范,而C端产品经理需要更多地创造行业的新趋势和模式。所以差异很大随着智能音箱、智能家居等智能硬件的普及,语音交互热度也不断飙升。想要了解语音交互,第一步是了解麦克风阵列,本文从概念、分类、作用几个方面对麦克风阵列展开了说明,与大家分享。

语音交互从亚马逊音箱(Echo)诞生的那一刻,就逐步走进了人们的视野,越来越多的人开始接触到语音交互的设备。从电视里的机器人,到家里的音箱,最后到手上的手机,语音交互变得触手可及。
语音交互的第一步就是拾音,机器人先要有一个耳朵,因为听不到声音就不会有反馈,更谈不上交互了,而麦克风阵列就相当于机器人的耳朵。
一、什么是麦克风阵列?
麦克风相信大家都见过,就是我们常见的话筒,麦克风阵列本质上和话筒没有区别,只是收音的单元比较多而已,基本上超过两个收音孔就可以说是麦克风阵列了。简单理解为一个麦克风就是麦克风,多个麦克风就是麦克风阵列。
麦克风阵列是由一定数目的声学传感器(麦克风)按照一定规则排列的多麦克风系统,对声场的空间特性进行采样并滤波的系统。
麦克风阵列除了看到的麦克风数量以外,还有一系列的前端算法,两者结合的系统才是完整的麦克风阵列。而麦克风阵列也只是完成了物理世界的音频信号处理,想要完成语音识别,还是需要云端的ASR模型,两个系统配合在一起才能得到最好的识别效果。
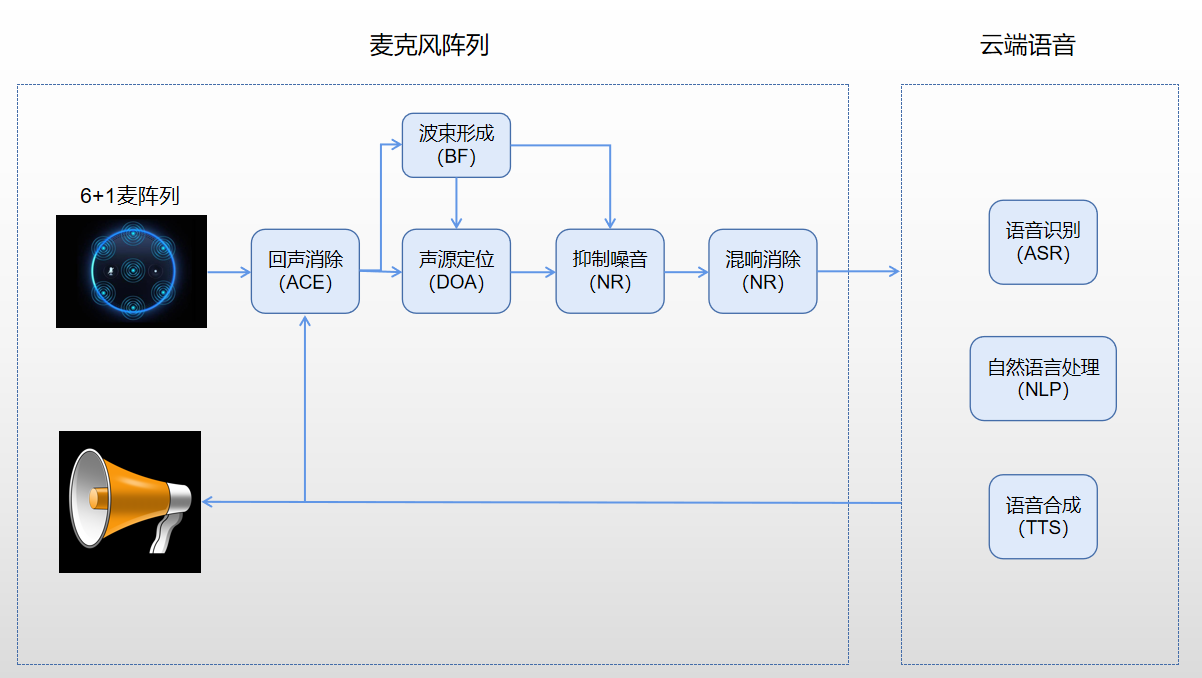
二、麦克风阵列如何分类?
由于前端算法看不见,摸不着,我们对于麦克风阵列的分类,常常参考麦克风的布局和数量。目前常见的分类,基本上以麦克风布局的形状来做区分,参考我们中学课本讲的点线面体,可以将麦克风阵列分为:线性阵列,平面阵列,立体阵列(点就是一个麦克风)。
当然也有根据形状的分类,比如:一字、十字、平面、螺旋、球形及无规则阵列等。这里我们按照点线面体的方法介绍。
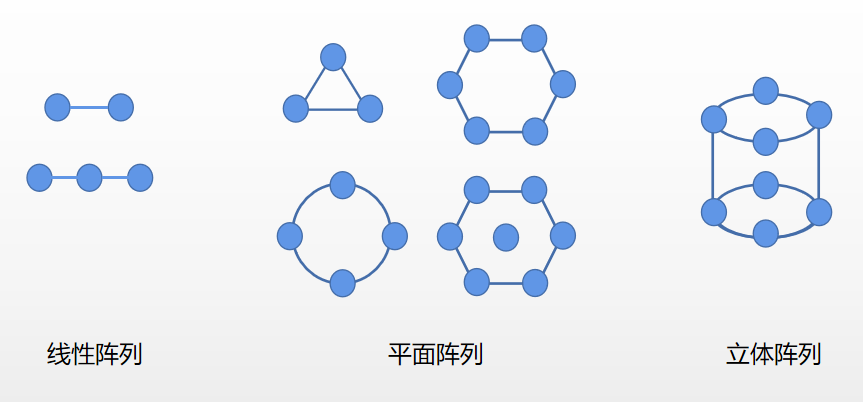
1. 线性阵列
常见的是两个麦克风的组成的线性阵列,目前几乎所有中高端手机和耳机都采用双麦克降噪技术来提升通话效果,也有部分智能音箱采用这种方案。
两个麦克风组成的线性阵列最大的优势就是成本低,相对于多麦克风,功耗也更低。缺点也比较明显,降噪效果有限,就是对于远场景交互的效果并不好。
2. 平面阵列
平面阵列的组合就比较多样化,常见的有4麦阵列和6麦阵列,还有升级的4+1麦阵列和6+1麦阵列,甚至8+1麦阵列。平面阵列常见于智能音箱和语音交互机器人上面。
平面阵列的线性阵列可以实现平面360度等效试音,麦克风个数愈多,空间划分精细度高,远场景识别效果好。缺点就是功耗较高,ID设计复杂。
3. 立体阵列
立体阵列多是球状,或者圆柱体,可以实现真正的全空间360度无损拾音,解决了平面阵高俯仰角信号响应差的问题,效果是最好的,成本也是最高的。但是生活中用的比较少,常见于专业领域。
三、麦克风阵列有什么作用?
前面从硬件的角度介绍了麦克风阵列的分类,接下来结合麦克风阵列前端算法,看看麦克风阵列到底有什么作用?
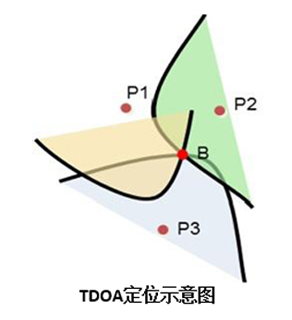
1. 声源定位
人有两个耳朵,可以通过声音判断发声的方向,机器人也同样可以做到。这个功能就是声源定位,通过声音感知人所在的方向,从而实现对目标声源方向的跟踪。这也为后续的波束形成做技术铺垫。
比如机器人场景,我们在机器人左边叫它,机器人听到声音后就会把头转向左边,我们在机器人背后叫它,机器人听到声音后就会转过去,这就是声源定位最典型的应用。通常声源定位会应用在语音唤醒阶段,能够检测一个大致的方向。
常用到的技术是TDOA(Time Difference Of Arrival,到达时间差),简单理解就是通过计算信号到达麦克风之间的时间差,从而计算出声源的位置坐标,需要毫秒级的响应和计算。
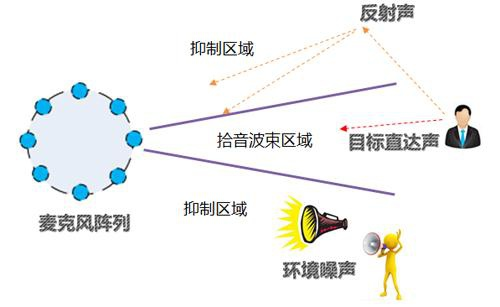
2. 抑制噪音/增强人声
在语音识别中,语音信息中往往夹杂着噪音,常见的有环境噪音和人声干扰,通常不会掩盖正常的语音,只是影响声音的清晰度。麦克风阵列主要通过波束形成技术,来抑制噪音,增强人声。可以理解为只识别某个角度的声音(一般角度可以进行调节),其他角度的声音都会受到抑制,从而实现抑制噪音的目的。反过来也可以增强角度内的人声,就是增强人声。
比如家庭场景,如果我们开着电视和空调在和音箱说话,音箱会以唤醒的它的角度为拾音区域,抑制非该角度的噪音(电视声音和空调噪音)。一般我们根据使用场景去设置拾音角度,使用距离越远,角度越小,常见为60°-120°之间。
抑制噪音能够满足日常家庭的使用场景,但对于强噪音环境的抑制效果并不理想,典型的就是鸡尾酒效音。
3. 回声消除
如果不做特殊处理的话,机器人会识别自己发出来的声音,很有可能就会变成无休止的自问自答,或者拾音错误。回声消除就是为了解决这个问题,消除掉机器自己发出的声音。
比如家庭场景下,你的音箱正在放音乐周杰伦的新歌,但是你想要查一下天气,这个时候你就会说“小X小X,今天天气”。回声消除的目的就是要去掉其中音乐信息而保留你的声音。
其实回声消除可能不太好理解,有时也被称作为“自识别”,即自己识别自己发出的声音。
4. 混响消除
在某些场景,发音会有回音,人能听到的是17米左右距离返回的回音。但是机器的感知要比人敏感的的多,如果不做处理,就会出现一句话叠加识别的情况。混响常指声波在室内传播时,被墙壁、天花板、地板等障碍物形成反射声,并和直达声形成叠加的现象。
比如在演播厅,我们能够感受到较为明显的回音,机器同样能够识别到这些回音。混响消除就是消除之后带来的回音,只识别第一遍的内容。
解决了这些问题,基本上就可以在日常环境下进行一个正常拾音,从而保证整个语音识别的正常。
四、如何选择麦克风阵列?
市面上可选的麦克风阵列方案比较多,国产主要集中在思必驰、云知声、科大讯飞和智声科技等,他们也有从单麦克风到麦克风阵列的全套解决方案,以及前端算法。纵观全球主要是亚马逊和苹果的麦克风阵列硬件,谷歌和微软的前端算法,分别是他们的擅长的地方。

首先从使用场景和ID设计,进行选择。如果是像手机一样拿在手上的近场景交互,产品又追求性价比,那么单麦克风完就能够满足需求;如果是像音箱一样放在家庭中的远场景交互,建议可以选择4麦以上的麦克风阵列,常见的有4+1和6+1两种选择方案;如果是像视频音箱一样站在面前的交互场景,建议选择2-4麦的麦克风阵列,当然条件允许,6麦的,甚至8麦的都是可以的。另外产品的ID设计适合什么类型的麦克风阵列,这个就因人而异了。
其次就是结合产品定位和前端算法,进行选择。如果只需要近场景收音,需求仅限于拾音,建议单麦就可以,成本低,ID设计简单;如果是想要实现类似通话降噪这种效果,2麦的麦克风阵列就可以满足需求,再多价值不大;如果是想要去除大部分噪音,建议使用4个以上的麦克风阵列,还要考虑前端降噪算法的能力,一般大厂效果更加可靠,麦克风阵列的硬件和前端算法的效果要结合ASR识别来一起评估。
还有就是像军工领域,航空航天,这些高端产品,就可以考虑使用分布式阵列了,这个不在我们考虑的范围内了。
最后就是参考成本以及研发速度,进行选择。看了上面这么多介绍,只需要根据自己产品的售价,以及这方面的预算,相信大家都已经清楚该怎么做出选择了。至于研发速度,个人觉得选择成熟的方案是最快捷的方式,如果ID设计不兼容,可能也需要定制,看具体需求。
一般像我们把手机拿到嘴边的语音交互,单个麦克风就够用了,就像有人在你耳旁说悄悄话,一个耳朵就能听清楚。但是在面对远距离,嘈杂环境的语音交互,麦克风阵列相对于单个麦克风有很明显的优势。
五、行业内麦克风阵列介绍
我们盘点一下业内常见的产品在麦克风阵列上的使用情况

通过收集素材,发现小米和天猫的音箱产品线覆盖非常全,其中2麦到6麦的产品都有。其实大部分音箱设备还是采用2麦和6麦的方案,随着前端算法的进步,未来需要的麦克风可能会越来越少。
六、如何测试麦克风阵列?
评价一个麦克风阵列的优劣,除了麦克风阵列的软硬件能力,还需要结合ASR的识别效果一起进行评估,以最终的识别结果为准。
我们后面聊到ASR识别的时候,再聊这部分内容。
七、总结
在语音交互普及的今天,消费级麦克风阵列主要解决远场景交互的语音识别问题,保证真实场景下的语音识别率。
麦克风阵列主要从两方面来实现物理音频的获取,一方面是硬件的麦克风数量和布局,一方面是软前的前端算法。硬件布局越合理,麦克风数量越多,前端算法可以处理的信息越多,识别的效果越好。如果只有1个麦克风,无论前端算法再怎么牛逼,是无法实现声源定位的;如果有2个麦克风阵列,前端算法如果超级牛逼,是可以实现大概的声源定位;如果有6+1麦克风阵列,前端算法就可以轻松的实现声源定位。
麦克风阵列只是语音识别的一部分,其麦克风布局和数量决定下限,前端算法决定上限。
本文由 @我叫人人 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议


















作者好~我觉得您的文章很棒,求加微信沟通呀!
作者你好,我看了你的几篇文章,觉得写的很好很全,可以加个微信交流交流吗
人人兄 留微信交流交流
好的,pony兄,已加