
 起点课堂会员权益
起点课堂会员权益实测完豆包图片生成Agent,我拆解了它的设计亮点和技术实现逻辑
豆包图片生成Agent的beta模式测试揭示了其在降低AI绘图门槛和提升用户体验方面的显著进步。文章将深入探讨这款产品的设计亮点和技术实现逻辑,分析其如何通过优化提示词和任务规划,使得用户能够轻松生成高质量图像作品。

前两天豆包图像生成开了beta模式(CreationAgent),推到我了我就点进去体验了一番,测完我在群里跟大家感慨这个功能真是太强了,豆包对C端用户的理解能力只能说:🐂🍺。
简单来说,豆包通过任务规划及提示词优化,大幅降低了AI绘图的专业门槛,让普通人能一句话画出高质量作品。
这是一个非常棒的C端功能,因此我决定写篇文章来细拆一下,主要聚焦在两个维度上:
1. 用户体验维度:这个产品有哪些设计非常棒的地方
2. 技术实现维度:从AI设计角度来看它是如何实现的
那我们先从第一个维度开始,我们聚焦在用户体验维度,看看这个产品设计好在哪。
我测了很多案例,然后总结了三个我体验下来觉得比较核心的点:
1. 一句简单描述就能出高质量作品,不需要再去苦想提示词
2. 一次对话可以支持生成1到20张的图片,批量出图又快又省事
3. 上下文理解能力非常强,动动嘴就能轻松修图
补充知识:豆包和即梦画图的模型底座是一样的,可能会有微调差异,但整体底层是一样的;所以我们直接用豆包和即梦进行提示词对比,来帮助大家更好的理解差异。
那我们先从第一点开始说起:一句简单描述就能出高质量作品,不需要再去苦想提示词
我自己也是个绘画小白,你让我写绘画提示词,比如说弄个五一出去玩的,我最多最多写:要五一了准备去北京玩。
在复杂我真是写不出来了,没那个水平。
但用这种提示词去即梦生成效果就很一般;于是豆包直接让模型理解用户的需求,再去单独写提示词,生成效果就比原始的描述好了很多。
要五一了准备去北京玩。(左即梦、右豆包)


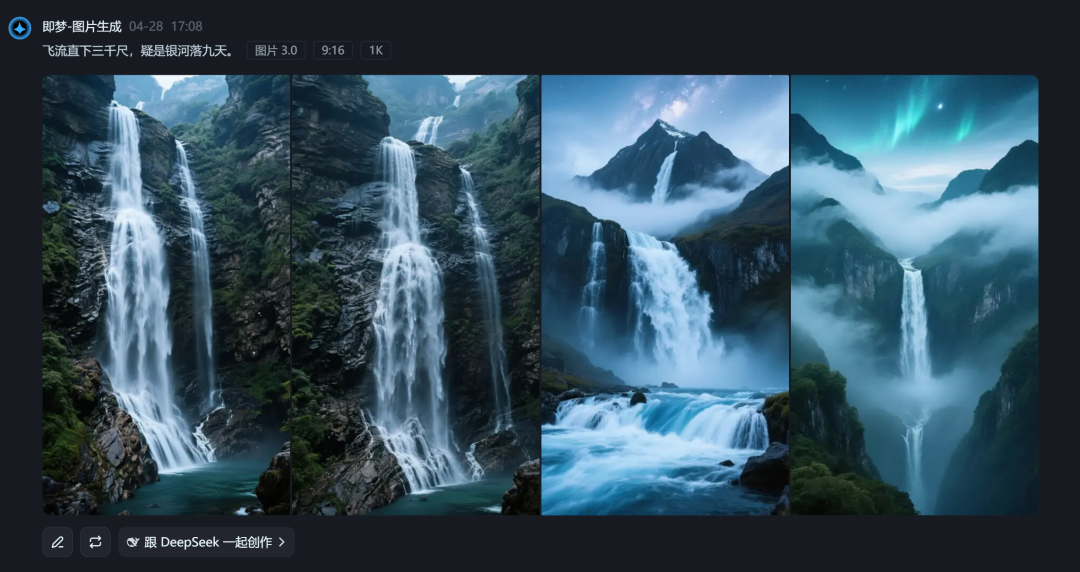
飞流直下三千尺,疑是银河落九天。(左即梦、右豆包)

小鸡打鸣太阳升起来了。(左即梦、右豆包)
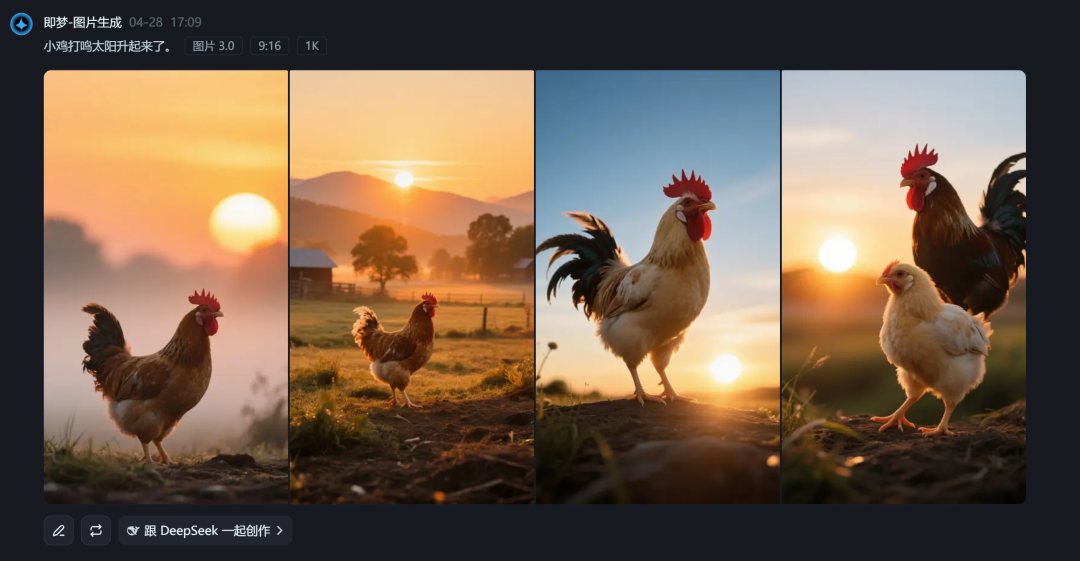
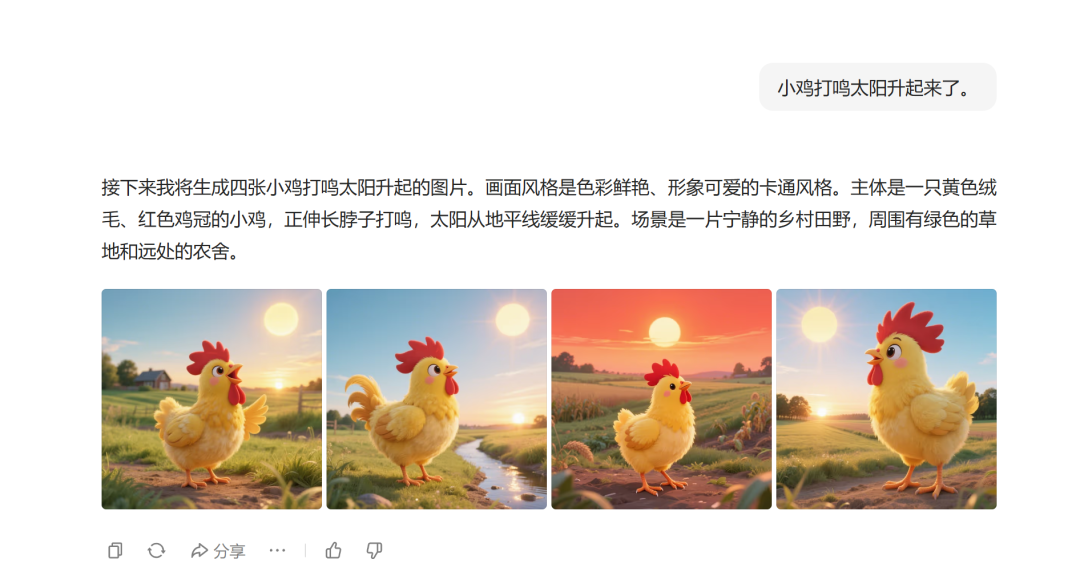
我抽了几个我能日常想到的描述用词,很明显简单的话描述还是豆包更出彩一点。长文本我也测了一下,基本上区别不大吧,看这两组图长得多像就知道了。
一头巨大的鲸鱼高高跃出湛蓝的水面,溅起晶莹的水花。阳光洒在鲸鱼身上,闪耀着金色的光芒,天空中飘着几朵洁白的云朵,与蓝色的大海相互映衬。整体呈现出清新写实的风格,画面力求精致细腻,光影效果出色,构图专业,具有高品质视觉效果。(左即梦、右豆包)

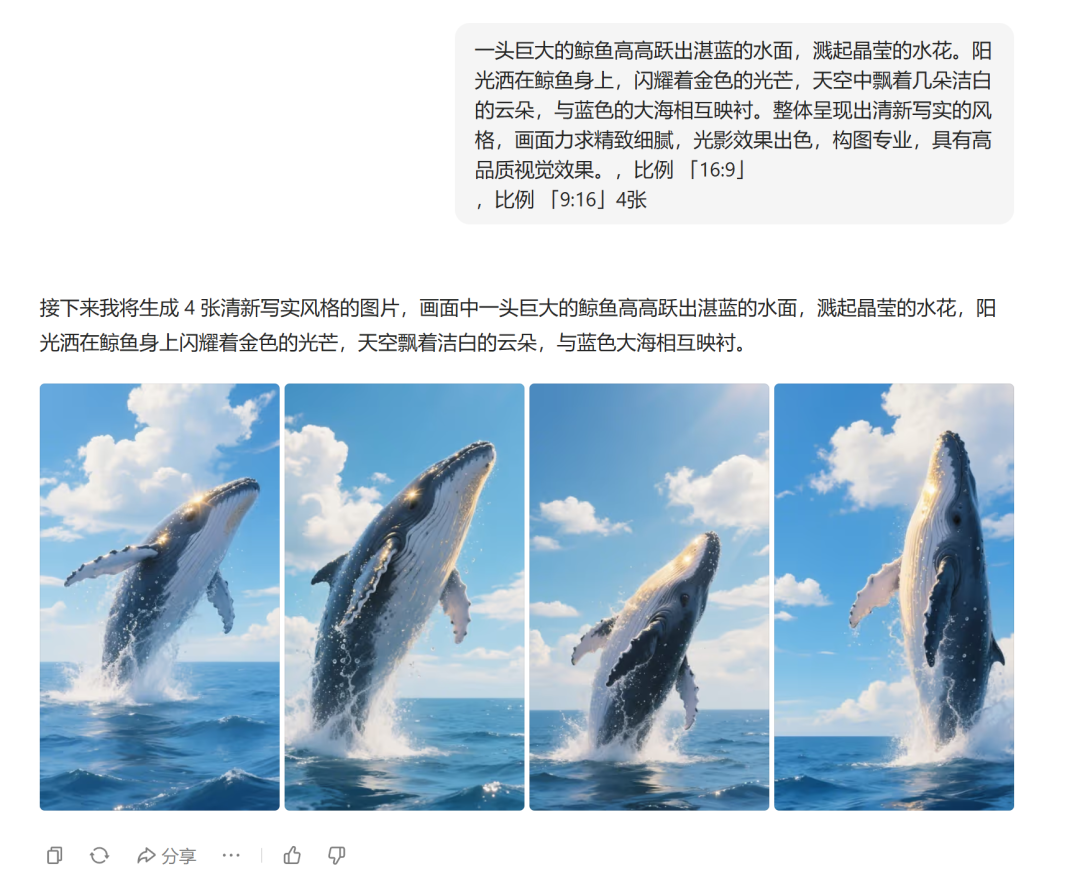
对于普通用户来说,豆包通过提示词优化,极大降低了创作门槛。
接下来我们来说第二点:一次对话可以支持生成1到20张的图片,批量出图又快又省事。
这次图像生成支持多图片、多尺寸来进行生成。
以我的狗子头像为例,我可以让它一次性生成10个表情包,然后再加上文字,特别可爱;比之前一个一个生成要省事好多,而且这些表情包的一致性也很不错。


除了批量出图外,豆包还支持一键生成不同尺寸的图。
如果你在生成的时候不知道什么尺寸好看,可以告诉豆包你需要多个不同尺寸的,然后生成了自己挑选。


接下来我们来说第三点:上下文理解能力非常强,动动嘴就能轻松修图
基于模型的上下文理解能力,豆包能够在多次历史对话中找到你说的那张图,然后进行调整。
还以上边我画的狗子表情包为例,这次我们让它给第七张表情弄的凶一点、第五张再激动一点、最后一张再可爱一点,豆包都能精准的抓到对哪一张做什么变更。

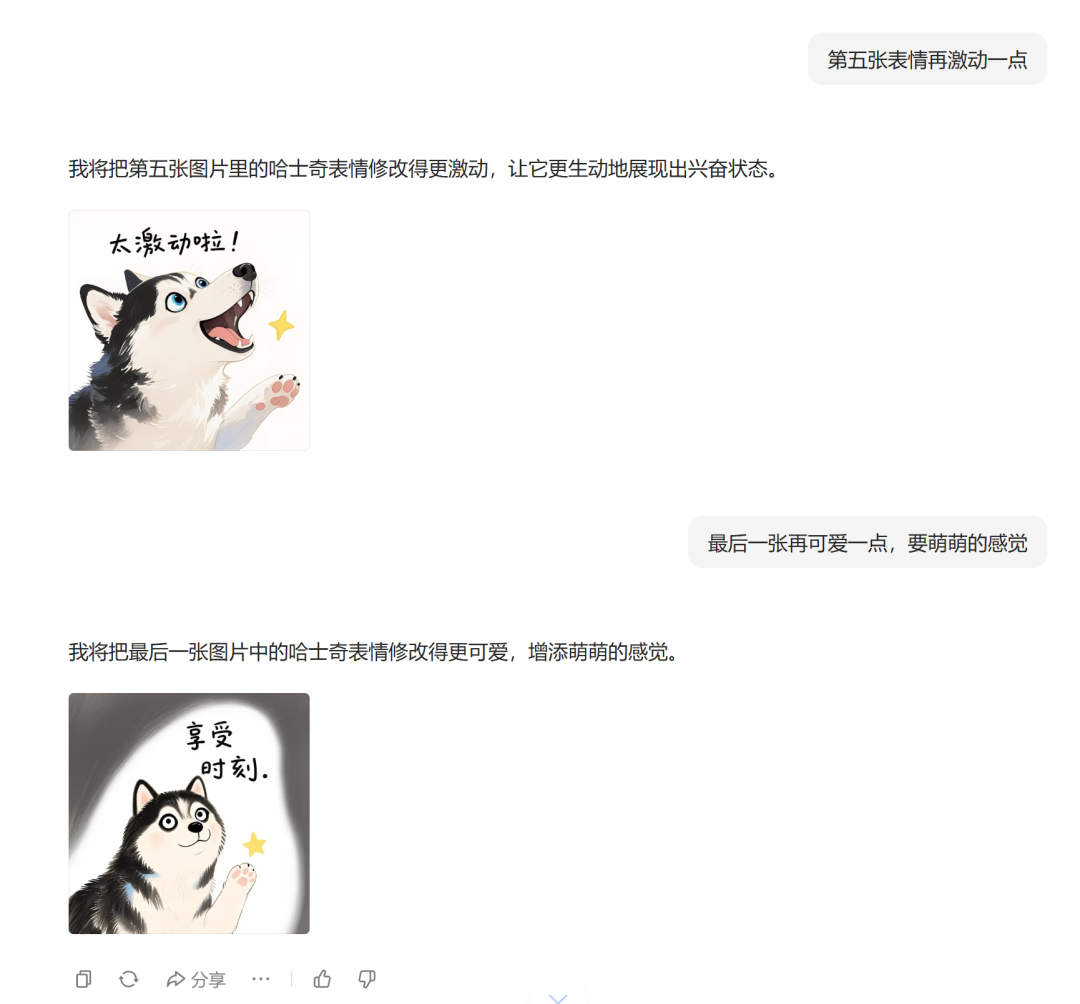
再让它给狗子做成科技版的头像,可以进行多轮对话的调整,效果非常棒。

测试了几轮下来,感觉这个修图的体验感觉跟4o很接近了。
到此用户体验维度的三点说完了。
它们加一起,构成了我刚开始对豆包图像的判断:
豆包通过任务规划及提示词优化,大幅降低了AI绘图的专业门槛,让普通人能一句话画出高质量作品。
对于用户来说,我不在乎你的产品参数有多强,我就希望简单能出高质量结果,谁能做到我就去用谁;模型侧是这样、产品侧也是这样。
谁简单效果还好,用户就会投票给它。
接下来我们来讲技术实现维度,我们来看看豆包图像从AI设计角度来看它是如何实现的。
接下来的拆解只包含正向工作流,各种异常值我就不考虑了,不在此次拆解范围内。
我们就以这个狗子表情包来做案例给大家分析,豆包图像从产品设计上是如何实现的。
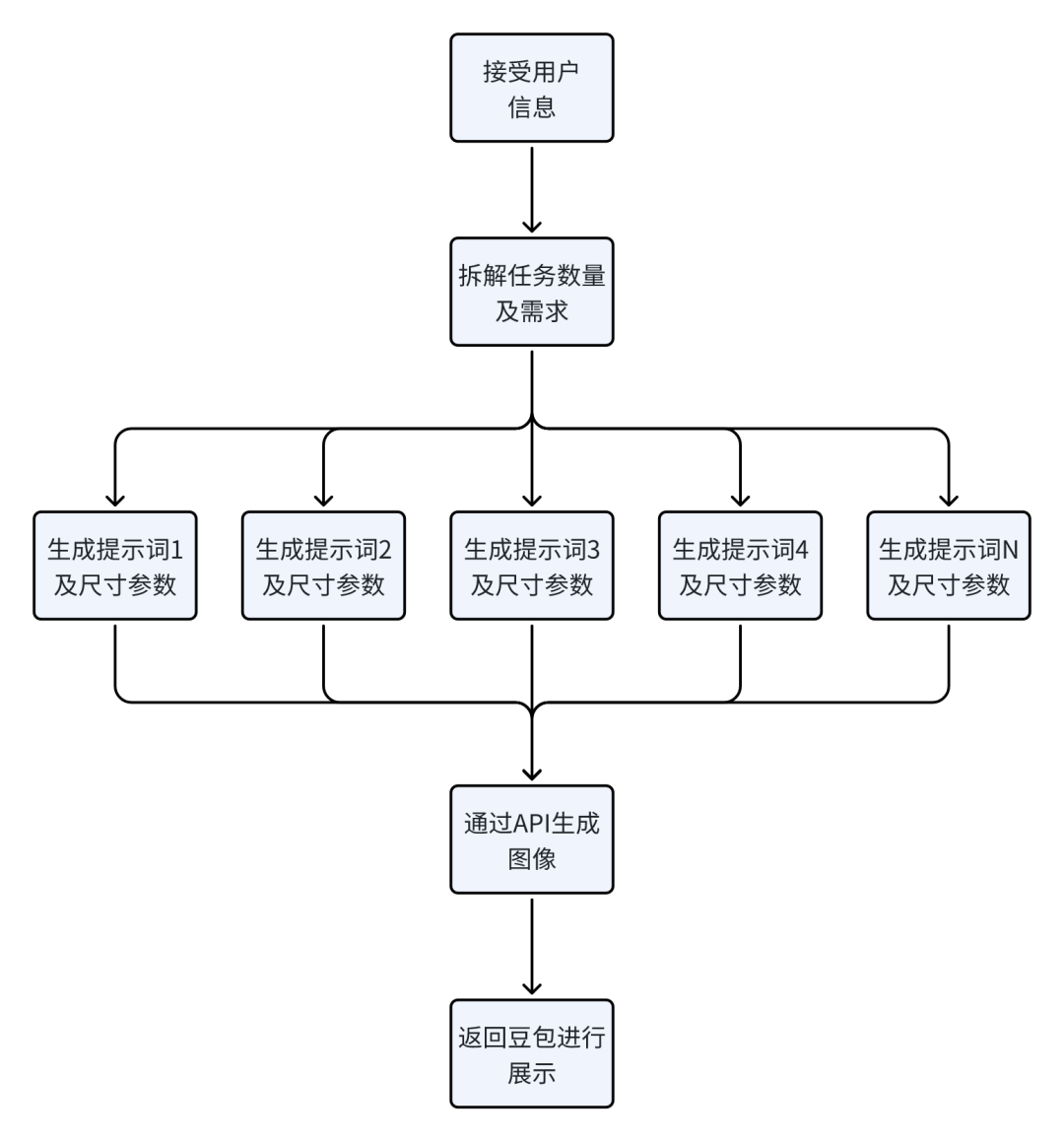
当我告诉豆包让它基于这个狗子头像来生成10个表情包,它会先去做一轮任务拆解,梳理清楚用户到底要做什么事情,需要生成几个图片。
在这个环节梳理完后,它会生成指令去发给作图的API(垫图应该是即梦2.0pro,不垫图是3.0)
为了方便大家理解,我就把json代码都改成中文的了类型:
图片生成数量:10
提示词1:
画面采用清新可爱的水彩画风格,背景为简洁白色。主体是一只毛色黑白相间、眼神明亮、嘴角带微笑的哈士奇,右前爪旁有黄色星星图案。哈士奇呈现开心张嘴吐舌的表情,表情生动,色彩柔和,笔触轻快,营造活泼有趣氛围,1:1(1:1是尺寸信息)
提示词2:
画面采用清新可爱的水彩画风格,背景为简洁白色。主体是一只毛色黑白相间、眼神明亮、嘴角带微笑的哈士奇,右前爪旁有黄色星星图案。哈士奇呈现开心张嘴吐舌的表情,表情生动,色彩柔和,笔触轻快,营造活泼有趣氛围,1:1
等待api返回图片后,豆包就展示到前端,这样我们就看到了第一组的狗子表情包了。
第一次没有文字,我就又通过指令加了一次文字,但这个流程区别不大我们就不单独拆了,我们来说这个上下文流程中,豆包是怎么精准识别到每一个图片的。
这里的难点在于图片的顺序,到底要抽哪一张图片。
所以推测豆包在返回前端的时候每一个图像应该都做了单独的处理,会给图片标注对应的顺序,方便后续模型去快速理解用户说的是那一张图。
可能的队列展示情况如下:01:url链接…02:url链接…03:url链接…
基于图像的队列,在跟豆包说具体的张数的时候它能够很清晰的找到那一张,然后进行基于图片的微调;微调流程和我们上边画的图一样,就不细提了。
这里比较难的点就是上下文传入的工程要怎么处理,简单做法就是打满上下文的token,复杂一点就是上下文每一段做索引,后续让模型自己调用;不过这块应该是延续之前模型的处理能力,目前测试下来十几轮还是有不错的稳定性。
这是垫图版本的,没有垫图比如说一句话指令会有什么区别呢?
比如说这个躺平表情包的制作,目前测试看起来拆解流程都是一样的,没有垫图调用的应该是即梦3.0画的,如果垫图了应该走的是即梦2.0pro或者内部微调的3.0模型。

抽象出来的正向的工作流差不多这些,异常的我们就不拆解了,那些细节边界条件比正向要花更多的时间。
用户体验维度和技术实现维度我们都分析完了,在最后我分享一下对C端AI产品设计思路的思考~
用户其实不在乎你是不是AI产品,更关键的是他的需求你到底有没有解决掉。
你能解决用户的需求,你就是日活高留存高的好产品,你解决不了你宣传再多的AI,也是体验一次用户就放弃。
解决问题的思路从pc互联网、移动互联网、AI从来都没变过,无非就看哪个团队愿意去一线认真研究用户的问题是什么、认真听用户的反馈、认真去解决问题。
AI也不是高高在上,它本来就在人间。
本文由人人都是产品经理作者【云舒】,微信公众号:【云舒的AI实践笔记】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自豆包官网截图






- 目前还没评论,等你发挥!


