
 起点课堂会员权益
起点课堂会员权益为什么感觉会迎来个假的GPT5
OpenAI 的内讧、对手的追赶、估值的压力,都在把真正的 AGI 推向更远的未来。这篇“正经的八卦”带你透视:什么是假的 GPT-5?为什么它大概率会出现?以及,如果真的 GPT-5 缺席,我们的“无人公司”梦又该靠什么继续?

GPT5看来是要来了。
但我有种不好的预感,我们很可能会迎来个假的GPT5。
(这篇其实是有点正经的八卦…)
什么是真的GPT5呢?
我不知道别的同学怎么预期,我一直的预期是GPT5是通用智能的第一个版本。
那什么又是通用智能呢?
这问题10个人可能有20种回答,我说个我自己的,不太严谨的回答。
通用智能就是一个人造的大脑,这个大脑里面有高一维度的智能和大量的记忆。
然后落到N种情境的时候,很像把一个智商200的博士放到一个公司一样,他可以很快理解具体的情况,并且入门。
放到具体情境则是用提示词,把这个高纬度的智能具象化的过程。
所以通用智能还真就是通用的高维智能,可分析、可推理、可以干任何事,没什么属性,但“智商极高”。不要忘记了物理学家和建筑工人,他们的大脑是基本类似的。
我期待的GPT5是比GPT4再有个数量级的提高,然后啥都能干的通用智能。
(现在的GPT给GPT5配的图,直奔Matrix去了…)
什么是假的GPT5呢?
我们总是可以通过降低上面那个智能的维度,然后让它在单独的领域表现的更好,比如奥数,比如解析蛋白质结构,比如下围棋。
如果我们再降低维度到四则混合运算,那甚至都不用模型,直接写程序就能处理的很好。
GPT这条线的模型是要搞定前者的,这条线下后者更像Agent要搞定的事。但如果拿后者的效果吸引眼球,也不是没用,但属实不是我最初预期的GPT5,就只能说是个假的GPT5。
为什么会这样呢?
看起来OpenAI自从内讧一场后确实伤了元气了。
后面搞一堆追赶者,Antropic、Google DeepMind、Grok等这些还是给OpenAI产生了相当大的压力。最近扎克伯格的一顿操作估计更是雪上加霜。
而对于头部AI大模型公司,它的估值首先是靠预期支撑的,其次才是业绩。
这时候来个假的GPT5倒是符合商业逻辑。
虽然从蛛丝马迹来看,很可能是这样,但我个人真的不希望这样。
因为《无人公司》的大规模铺开需要真的GPT5…
透视AI的几条路线
我们每天总说的AI根本不是一个东西,虽然它们共享很多的基础理论比如神经网络、深度学习、Transformer架构等。
这里面chatGPT路线属于往通用方向发展,而FSD12和AlphaFold则是往专门领域发展。后两者也重要,但显然没有前者重要。
在我们这个时间点,划定边界、专门往某个方向优化可以做的远超人类是被反复证明过的事。
即使是自动驾驶这么复杂的事,看Robotaxi的热度,我怀疑再搞个几年就真彻底像AlphaGo那样远超人类了。
所以现在真有挑战的不是专用,而是通用人工智能。按正常脉络似乎应该是OpenAI通过GPT5来搞定的这事。
通用人工智能一旦往前挪一步,那影响的是全部经济领域,而不是某个领域。
想象下如果基于通用人工智能的Agent去下围棋,并且赢了AlphaGo;去解析蛋白质结构并且赢了AlphaFold,那意味着什么?
不过也许是老天想给人类多点时间适应,所以OpenAI内讧了…..
那还不会不有真的GPT5呢?
我觉得还是会的。
这里估计还是需要点当年OpenAI坐冷板凳的精神,Ilya那公司(Safe Superintelligence Inc.)没产品发布估值已经升到 320–330 亿美金。这应该不是全靠刷脸。
另一个点是:从Hinton老爷子等的的发言来看,现在的AI的问题貌似是个已经确定解决的问题。他们不再谈什么路线,怎么搞定了,大家仔细看看他们最近的发言。
最后就是一个统计的猜想:AI属实在加速。
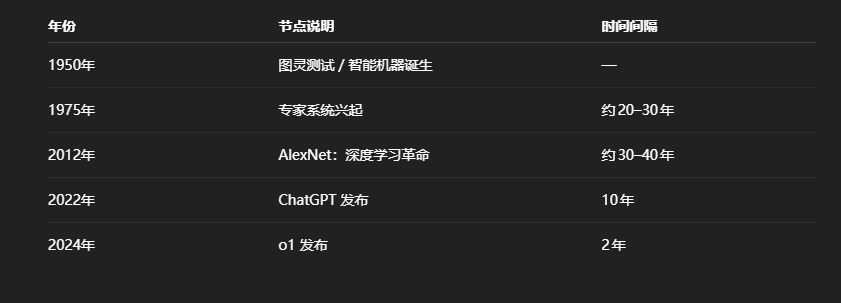
技术上的原因看起来就是GPT4等可以看成一个原始版的人造超级大脑,这和过去的技术完全不一样,过去的技术都是专门化的,而它可以啥都干。它们可以用来加速他们自己。
更关键的是,我们确实总是还可以做出来一个专门化的工具来加速这个进程。
GPT5之后呢?
最近陈果(果总)有本书叫:《AI时代数据价值创造》,前面还有一本叫《业务流程》。我一边看就一边琢磨:如果有GPT5了,这里面还有多少内容是需要人处理的?
拿第一本书来举例子,我得出了个很有意思的结论:
书里的这套数据体系用不用本身不是个AI的问题,而是你生产关系的问题。
生产关系至少要有对外和对内两部分。
对内的部分恐怕不适合每次定义一组schema来表示企业的活动和知识,而是还是要预先确定。
这可以做简单推理:
假设GPT5十分聪慧,你只要和他说清楚目标,它就能给你把活干了。这时候你还是要累积数据资产,而不可能每次都是一个目标和一个混杂不做定义的历史活动记录。
所以对内的部分要向AI倾斜,甚至可以让AI定义,但不会没有。
对外的部分就更麻烦,因为外部世界又不是单个公司定义的,怎么合作也不是一个公司定义的。所以肯定不能全扔给GPT5。
结论是数据和领域模型的定义在无人公司的设想里面是要有人类介入定义的,反倒是变重要了。
虽然可以假设GPT5自己定义数据,自己更新数据定义,但这事儿我这激进派都觉得有点悬了。至少不是可见范围内的预期。
这似乎有点矛盾,无人公司里面和外部相关的生产关系,数据的初始模型其实是需要人类来定义的。
但这应该是数字空间不完备(每个无人公司的外部环境是不完备的)的必然后果吧。
小结
我们其实不太能抛开技术来谈AI,那就有点像耍流氓,但AI这技术变化实在太快,跟起来挺累的。
唯一的方法就是把它们放回到模型,过去我读这些论文挺费劲的,包括想找彼此间的关联,现在基于大模型,这个过程可以提速N倍。
这显然是最简单的AI来提高的例子,所以GPT5这次如果不是第一个AGI,那我想它也不会太远。
OpenAI的五级分级是很有意思的,但它自己假装升级太快了。
本文由人人都是产品经理作者【琢磨事】,微信公众号:【琢磨事】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。









文章深入剖析了 GPT-5 可能不如预期的原因,对 AI 发展现状的洞察发人深省,对技术发展和商业逻辑的探讨也很有价值。
AI重塑内容创作,AIGC工具降低门槛却引发版权争议。创作者需平衡效率与原创,如何建立行业规范,让技术赋能而非消解创作价值呢?