
 起点课堂会员权益
起点课堂会员权益AI产品手札:具身数据的底层思考
GEN-0证明了具身的Scaling Law,物理世界的通用智能并非遥不可及,但它标好了昂贵的价格——那就是海量、高保真、包含物理常识的交互数据。数据的多样性(Diversity)和交互密度(Interaction Richness)远比单纯的 Token 数量重要,因此未来的竞争,是“高质量真机数据供应链”的比拼。

01 引言:信仰与荒原
如果说大语言模型(LLM)的成功,是人类知识在文本维度的“暴力压缩”;那么具身智能(Embodied AI)的终局,必然是物理世界在交互维度的“全息投影”。
从GPT-3到GPT-5,我们见证了算力和数据堆叠带来的智能涌现。但在机器人领域,这个公式似乎遇到了阻力。我们不缺H100(算力),不缺Transformer(算法),甚至也不缺钱。
我们缺的是那把打开物理世界的钥匙——数据。
更准确地说,是“带有物理常识的高保真真机交互数据” 。作为一名AI产品经理,今天我想和大家聊聊在通往通用具身智能的路上,关于“数据”的底层思考。
02 维度诅咒:物理世界的 Token 在哪里?
在LLM时代,互联网上万亿级的 Text Token 是天然的燃料。它们离散、符号化,是人类思维的高度抽象 。
但当你把目光转向物理世界,情况变得极其复杂。 机器人的每一次抓取、每一次移动,产生的不是离散的 Token,而是一条连续的流(Stream):关节的力矩、视觉的光流、指尖的触觉反馈 。
具身智能面临着“维度的诅咒”:
- 文本是 1D 的;
- 具身数据是 3D(空间)+ 1D(时间)+ Force(力)的高维纠缠
我们可以轻易用AI生成完美的文本,但目前很难生成完全符合真实物理定律(摩擦、形变、流体)的完美数据。因此,在完美的“物理世界模拟器”出现之前,高质量的真机数据(Real-world Data)依然是跨越模型能力鸿沟的唯一金桥。

03 标杆解构:7B 参数的“智力涌现”
近期备受关注的 GEN-0 模型,其实是一次关于具身基座模型(Embodied Foundation Model)的大规模验证实验。它告诉了我们要达到“通用智能”,门槛在哪里。
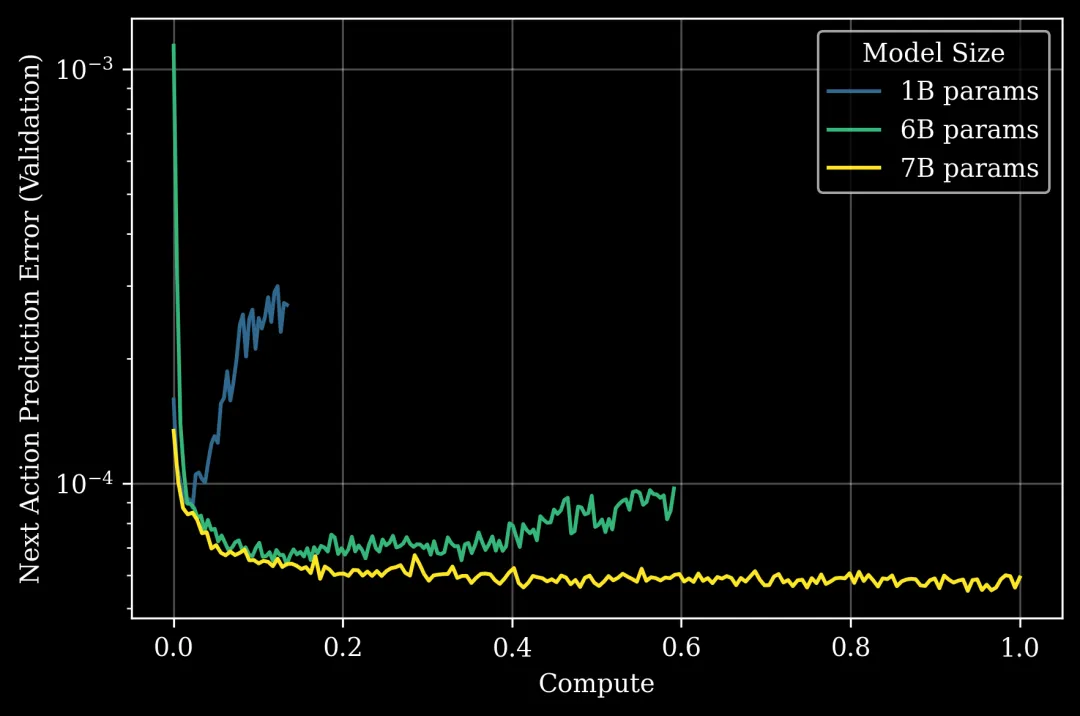
GEN-0 的实验揭示了一个关键结论:7B(70亿)参数是模型从“记忆”走向“泛化”的临界点。
- <; 7B 参数:模型只是一个“轨迹拟合器”。它像个死记硬背的学生,虽然在训练集上表现完美,但换个环境就歇菜,出现了“模型钙化”(Model Ossification)现象。
- ≥ 7B 参数:模型开始展现出对未知场景(OOD)的泛化能力,真正“理解”了物理常识。
但支撑这 7B 参数的,是27万小时的真实世界操作轨迹,涵盖了家庭、工厂、野外等数千个非标场景。这个数据量级,是许多同类模型的几十倍。
其实在 GEN-0 正式提出前,Generalist AI已经把“端到端 + 高频控制 + 双手灵巧 + 跨本体”的核心链路跑通。
- 2025-06-17:公开端到端模型在多具身与多任务上的早期结果,强调高频控制、毫米级精度与跨设备泛化(如 7-DoF Flexiv Rizon 4 ↔ 6-DoF UR5)。
- 2025-09-24:发布“一次示范组装(one-shot assembly)”内部评测:人类先搭一遍,机器人纯端到端模仿复刻,中间无任务特化工程与规则。

而GEN-0这个目前基于最大规模、场景最丰富真实数据集的基座模型背后的数据秘密,核心关键在于构建UMI的数据基建。
- GEN-0 建立了一个庞大的Data Infrastructure(数据基建)。目前涵盖27 万小时的真实世界操作轨迹,这不仅仅是存储,而是一套覆盖家庭、工厂、野外等非标场景数据采集网络。并且每周新增超过 1万小时数据,持续为模型提供真实物理交互经验。
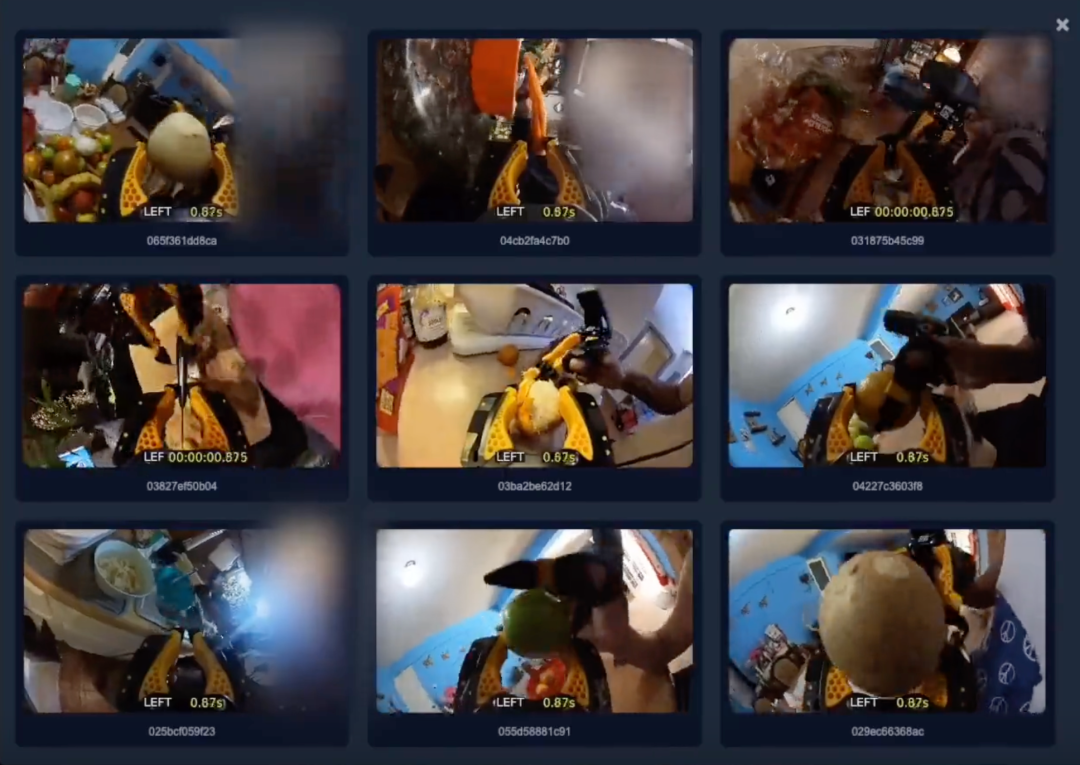
- Generalist AI 还建立了非常方便的数据可视化系统,搜索关键词即可看到不同场景下该技能的数据。
- 有专业人士预测,如果一个现在起步的玩家,1:1复刻Generalist AI的数采方式和规模,算上前期数采的爬坡的时间,也需要至少超过半年,甚至一年的时间。
04 战国时代:真机数采的三大流派
既然数据如此重要,那么数据从哪来? 放眼目前的具身智能领域,数据采集方案正处于“战国时代”。为了解决“在保证物理真实性的前提下实现规模化”这一核心矛盾,行业内衍生出了三大流派:
精密遥操作流派 (Teleop):昂贵的“金标准”
代表:ALOHA, Vision Pro VR控制、动捕、外骨骼等。
逻辑:依靠人佩戴动捕设备或操作主从机械臂,Human-in-the-loop。
评价:
- 不可扩展 (Unscalable):1 小时数据 = 1 小时人工 + 昂贵硬件折旧。
- 场域限制:很难把一套几十万的真机数采设备搬到星巴克/工厂去采数据,导致数据极度缺乏场景多样性。

视频流派 (Video):巨大的“暗物质”
代表:Ego4D。
逻辑:大力出奇迹,利用海量互联网视频数据(YouTube/Ego4D)进行Retargeting映射。
评价:规模巨大,但质量一般。视频数据只有RGB,缺失了最核心的 Action(动作指令)和 Proprioception(本体感知/力反馈)。就像看人游泳一万遍,自己下水可能还是会淹死。

便携式/手持采集流派(Portable / UMI):破局的“游击队”
代表:UMI (Universal Manipulation Interface)。
逻辑:消费级 GoPro + 3D 打印的机械夹爪 + 鱼眼镜头。彻底解绑机器人本体,像拿自拍杆一样去采集。
评价:这是近两年最大的变量。极低成本(<;300美元)换取了极高的场景多样性(Diversity)。这是解决“机器人出不了实验室”痛点的最佳方案。
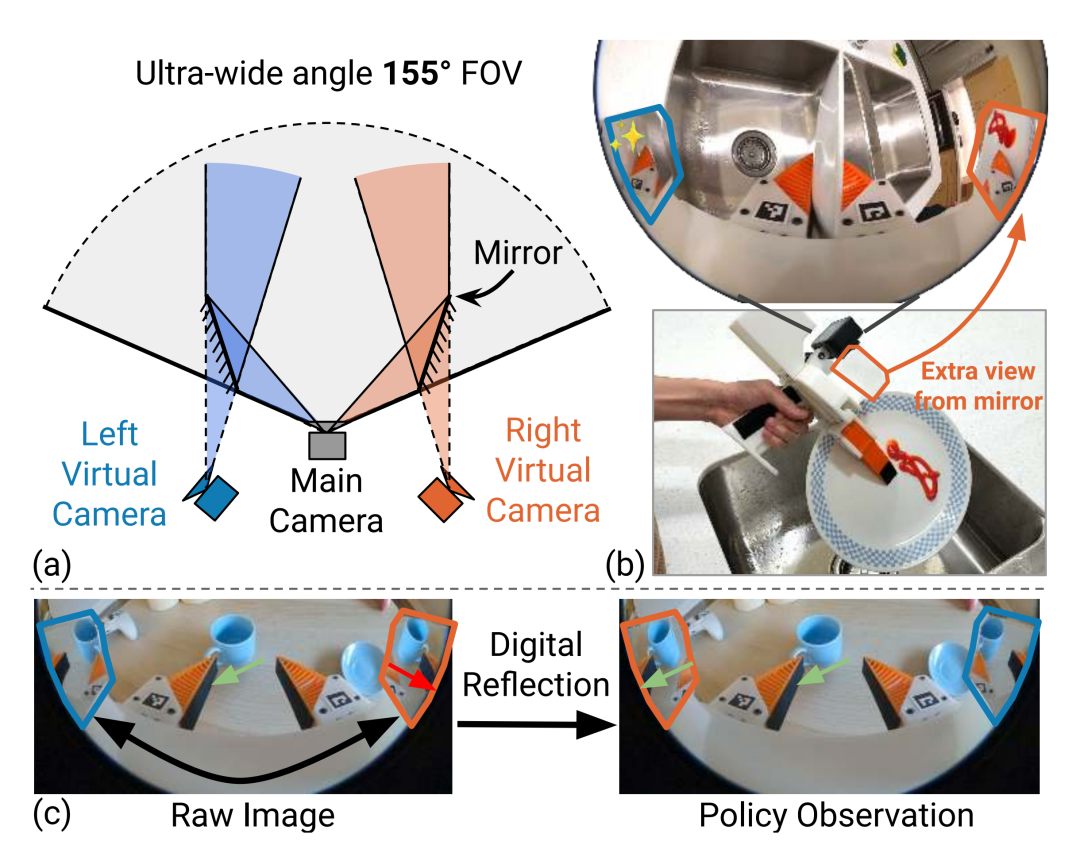
丁琰博士最近发布的FastUMI-Pro可以前去了解。
主流真机数采方案的多维对比:
为了更直观地看清各方案的优劣,从采集效率、数据质量、硬件成本、场景多样性等维度进行了对比分析:

05 底层哲学:告别“停下来思考”
除了数据采集,GEN-0 在模型架构上引入的Harmonic Reasoning(谐波推理)同样令我着迷。
传统的机器人往往是“串行”的:观察 ->; 思考 ->; 行动。 但这有个致命伤:物理世界不会暂停,重力不会等你思考完再发挥作用。
谐波推理让模型学会了“边想边做”。感知流(Perception)和动作流(Action)像音乐的和声一样,异步但协同运行。它不需要生成完整的思维链(CoT)后再动,而是像人类的小脑一样,在执行当前动作的同时,并行预测下一秒的物理状态。
这也是为什么我们需要“实时(Real-time)”甚至“超实时”的数据,而不是那些慢吞吞的遥操作数据。因为只有敏捷的数据,才能训练出敏捷的智能。这也侧面解释了现在大部分模型PR是需要视频加速处理的。
06 结语:从输血到造血
具身智能的竞争,归根结底是“高质量真机数据供应链”的比拼。
现阶段,大家还在通过“资本雇佣生产力”的方式(如数采厂),专门雇人去采集数据,这是成本中心的运作模式,是以牺牲生产力为代价的数据获取策略,数据量的累积取决于资源,从本质上是不Scalable的。
但我相信,理想的终局是数据闭环:当机器人的能力跨过那个临界点,它们将真正进入工厂、家庭开始作业。那时的数据采集将是生产过程的“副产物”,好比Tesla的影子模式——机器人越多,数据越多;数据越多,机器人越聪明。

这,或许就是所有具身智能从业者梦寐以求的时刻。
本文由 @杰克说AI 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


