
 起点课堂会员权益
起点课堂会员权益单日股价暴涨的秘密!智谱GLM-5技术细节全公开,纯国产算力跑出的智能体奇迹
GLM-5的发布标志着中国AI进入全新阶段,7440亿参数的混合专家架构与Slime异步强化学习框架彻底改写了技术范式。这款国产大模型不仅在长上下文处理能力上实现128K输出的突破,更通过数据炼金术与架构创新,证明了工业级AI应用的可行性。本文将深度拆解这份技术报告,揭示GLM-5如何从参数规模竞争转向系统级工程突破。

智谱GLM-5技术报告万字深度拆解:7440亿参数硬刚Opus 4.5,中国大模型正式告别“玩具时代”

2026年的春节档,注定要被载入全球人工智能的发展史册。过去几周,整个AI开发者社区都在为一个代号为“Pony Alpha”的神秘模型彻夜未眠。它在OpenRouter等全球权威平台上匿名霸榜,展现出了令人战栗的代码重构和长逻辑推理能力。
2月22日,智谱AI正式公布了其新一代旗舰开源大模型GLM-5的详尽技术报告(arXiv:2602.15763)。伴随着报告的发布,智谱在资本市场也迎来了史诗级的爆发,单日股价一度狂涨,短期内实现翻倍,毫无争议地坐稳了“全球大模型第一股”的交椅。
但这绝不是一篇用来“跑分炫技”的常规Paper。仔细研读这份技术公开内容后,你会发现一个极其清晰的信号:中国AI正在经历一场残酷而华丽的蜕变,从单纯拼凑参数规模的“青春期”,正式迈入了深耕系统级工程的“成年期”。
无论是极其狂暴的7440亿混合专家架构、首次全面披露的Slime异步强化学习框架,还是对七大国产芯片的底层原生重构,GLM-5的每一个技术细节都在指向同一个终极目标:终结“氛围编程”(Vibe Coding),开启“智能体工程”(Agentic Engineering)的新纪元。
一、核心范式转移:从“氛围编程”到“系统架构师”的觉醒
在探讨那堆令人眼花缭乱的参数和图表之前,我们必须先理清GLM-5在产品哲学上的根本转向。
过去一年里,AI圈最火的词莫过于Andrej Karpathy提出的“氛围编程”(Vibe Coding)。这是一种极其享受的开发体验:你只需在对话框里敲几句自然语言,AI就能瞬间吐出一个带有炫酷粒子特效的网页,或者帮你画一个精美的SVG图标。这种“所说即所得”的模式极大地降低了编程门槛,让非技术人员也能过一把程序员的瘾。
但这很酷,却也极其脆弱。
当你在真实的商业环境中,面对一个包含数十万行代码、涉及复杂后端逻辑、数据库调度和微服务通信的分布式系统时,“氛围编程”瞬间就会崩溃。过去的模型只能生成局部连贯的代码片段,它们无法在几十轮的交互中保持上下文状态,不会主动去跑测试用例,更不知道如何在遇到环境依赖报错时自我修正。
智谱GLM-5的技术报告在开篇就明确抛弃了这种“玩具级”的路线,将矛头直指**“智能体工程”(Agentic Engineering)**。
到底什么是智能体工程?说白了,就是让大模型从一个“自动补全打字机”变成一个带薪上班的“高级系统架构师”。
为了实现这个目标,GLM-5在输入输出的物理限制上做出了惊人的突破:
200K超长上下文窗口:支持多达20万个Token的输入,这意味着你可以把几十个微服务的核心代码库、数百页的API文档(相当于300页A4纸的容量)一次性全部塞进模型的脑子里。
史无前例的128K最大输出Token:这是整个报告中最让人倒吸一口凉气的数据之一。目前市面上即便是最顶级的模型,如Claude Opus 4.5或GPT-4o,其单次输出上限通常被锁死在4K到16K。而GLM-5允许单次吐出128K的极长内容。这意味着什么?这意味着模型可以直接端到端地生成一整个包含前后端逻辑的中型项目,或者输出一份数万字的深度财务分析报告,而不需要人类开发者不断地敲击“继续生成”来拼接碎片。
这种物理容量的扩张,是模型能够执行长视野(Long-horizon)复杂任务的基础。但要让这个庞然大物转动起来,还需要底层架构的彻底重构。
二、架构魔法与数据炼金:744B MoE与DSA稀疏注意力的交响
在基础架构层面,GLM-5进行了一次极其激进的扩张,但这种扩张绝非无脑堆料。
1. 7440亿参数的“精打细算”
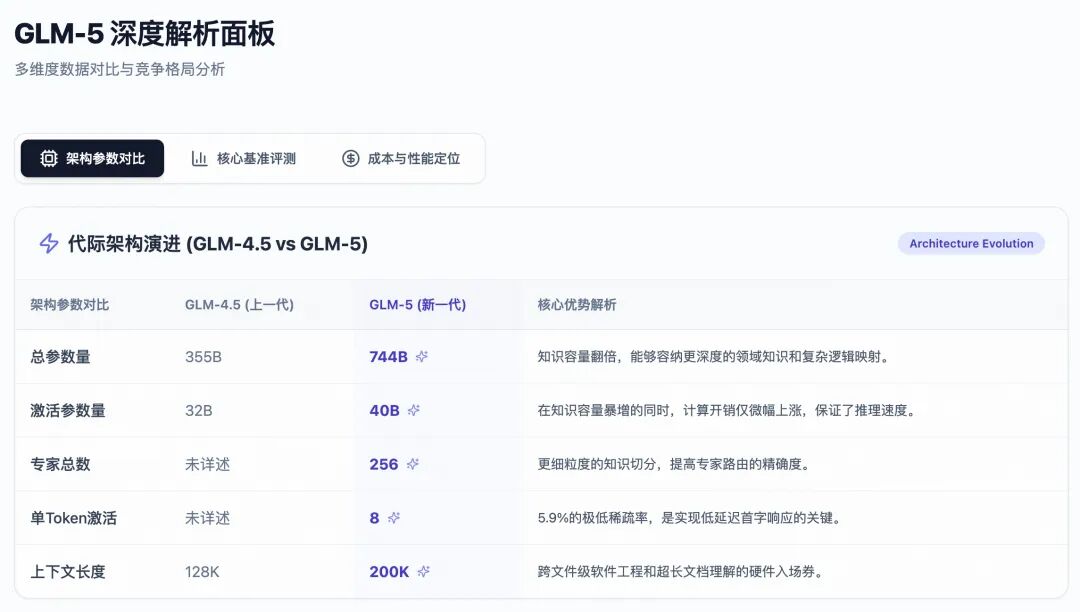
根据报告披露,GLM-5的底座是一个规模庞大的混合专家(Mixture-of-Experts, MoE)模型。它的总参数量从上一代GLM-4.5的355B暴增至744B,实现了超过两倍的规模跃升。
但在实际推理时,GLM-5展现出了惊人的效率。模型内部包含了256个专家神经网络,但在处理每一个Token时,只动态激活其中的8个最匹配的专家。这使得其每次推理的实际激活参数量仅为40B(稀疏率低至惊人的5.9%)。
(数据来源:智谱GLM-5技术报告及官方博文)
这种设计的精妙之处在于:你获得了一个拥有7000亿参数级别庞大知识储备的“智囊团”,但在每次回答问题时,只需要支付400亿参数级别的“咨询费”。这也是为什么许多开发者在实际调用GLM-5 API时,感觉其首字响应延迟(First-token latency)甚至接近于几十B的轻量级模型,完全没有几千亿参数巨兽的滞后感。
2. DeepSeek Sparse Attention (DSA) 的跨界融合
然而,MoE架构只解决了前馈神经网络(FFN)层的计算爆炸问题。当上下文长度达到200K时,Transformer架构中最核心的注意力机制(Attention Mechanism)会遭遇可怕的$O(N^2)$复杂度陷阱,显存和算力将被瞬间吞噬。
在这里,智谱展现了极具开放性和实用主义的技术胸怀——GLM-5首次在架构中深度集成了由DeepSeek首创的稀疏注意力机制(DeepSeek Sparse Attention, DSA)。
传统的注意力机制要求当前Token必须与前文的每一个Token进行相关性计算,哪怕是那些毫无关联的废话。而DSA机制引入了一个额外的索引器(Indexer)。这个索引器能够像雷达一样,在前文中动态检索出与当前Token最相关的Top-k个Key-Value条目,然后仅仅在这小部分被检索出的子集上进行稀疏的注意力计算。
报告显示,在200K的超长文本场景下,DSA机制将注意力计算的算力开销和显存占用生生砍掉了1.5到2倍。更令人拍案叫绝的是,智谱团队通过后续持续的预训练平滑处理和稀疏适应阶段(通过了20B Token的微调),成功做到了在极致压缩成本的同时,保持长上下文理解和复杂推理深度的“绝对无损”。
这是大模型工程史上的一次经典战役:用架构创新对抗物理算力墙。
3. 28.5万亿Token的数据“炼金术”
参数和架构搭建了躯壳,而数据则是注入其中的灵魂。GLM-5的预训练数据量达到了史无前例的28.5万亿(28.5T)Token,较上一代增加了5.5T。
在如此恐怖的数据规模下,粗放的“爬虫抓取”早已失效。为了应对智能体工程对高密度逻辑的苛刻要求,智谱重构了整套数据提纯管线:
世界知识分类器(World Knowledge Classifier):针对互联网语料长尾知识匮乏的问题,智谱利用维基百科条目和海量LLM人工标注数据,专门训练了一个分类器。这个分类器就像一个无情的过滤器,能够从浩如烟海的中低质量网页中,精准“蒸馏”出具有高信息熵的宝贵知识片段。
代码语料的史诗级净化:为了让模型具备写出工业级代码的能力,代码预训练语料通过抓取主流代码托管平台的最新快照进行了大规模扩充,使得模糊去重后的唯一Token数量激增28%。更关键的是,团队深度修复了Software Heritage等代码库中的元数据错位问题,并为Scala、Swift、Lua等低资源语言训练了专用分类器,极大地提升了模型在多语言环境下的鲁棒性。
数理逻辑的严苛筛选:数学与科学数据是模型逻辑推理能力的基石。智谱采用高级LLM作为“裁判”,对海量论文、书籍和网页内容进行打分,实行末位淘汰,仅保留最具教育和推导价值的纯净数据。
这28.5万亿Token的高质量灌喂,为GLM-5打下了坚不可摧的全知底座,但这仅仅是开始。真正让GLM-5发生质变的,是其后训练(Post-training)阶段的彻底颠覆。
三、Slime框架与异步智能体RL:大模型后训练的工业革命
如果说预训练决定了模型“懂多少”,那么强化学习(Reinforcement Learning, RL)的后训练阶段,则决定了模型“有多聪明”、“有多好用”。
强化学习旨在弥合预训练模型“胜任(Competence)”与“卓越(Excellence)”之间的鸿沟。然而,在面向长周期智能体任务(Agentic tasks)时,传统的强化学习框架(如PPO)遇到了不可逾越的效率天堑。
1. 传统同步强化学习的“木桶效应”
想象一下传统的强化学习训练过程:模型(Actor)在模拟环境中生成一批动作轨迹(Rollout),比如尝试修复一个Bug。有的Bug很简单,模型几秒钟就修好了;有的Bug极其复杂,模型需要查阅十几个文件、反复编译报错、尝试不同的逻辑,耗时可能长达数小时。
在传统的同步RL架构下,整个GPU训练集群必须像木桶一样,死死等待那个耗时最长的长尾任务结束,才能统一计算奖励(Reward)并进行全局的权重同步和梯度更新。这就导致在漫长的等待期内,大量昂贵的GPU处于严重的闲置状态(Idle time),训练效率低得令人发指。对于动辄需要数千次交互的智能体任务来说,这种锁步(Lockstep)机制让大规模RL训练在经济上变得几乎不可能。
2. 横空出世的Slime:极致解耦的异步新基建
为了轰碎这堵效率高墙,智谱AI(THUDM团队)完全自主研发并开源了一套名为“Slime”的SGLang原生异步后训练框架。这套框架是GLM-5能够实现跨越式进化的绝对核心基建。
Slime的核心哲学只有一个词:解耦(Decoupling)。
生成与训练的物理分离:Slime彻底将生成过程(由SGLang高吞吐引擎负责)与主训练过程(由Megatron-LM负责)剥离开来。生成节点疯狂地与环境交互、产生轨迹数据并扔进一个中央数据缓冲区(Data Buffer);而训练节点则像一个永不停歇的引擎,不断从缓冲区中抓取数据进行参数更新,完全不需要等待任何人。
中继工作节点(Relay Workers):这是Slime解决同步瓶颈的神来之笔。系统引入了一层中继节点作为分布式的参数服务器。生成节点可以随时随地从这里拉取最新的模型权重去执行任务,而完全不会打断训练节点的循环。
动态重打包(Dynamic Repack):针对那些耗时极长的“老大难”轨迹,Slime设计了动态重打包机制,将这些长尾任务智能地调度到少数几个专门的生成节点上执行,从而保证了全局生成吞吐量的最大化。
有研究数据显示,这种基于轨迹级别(Trajectory-level)的异步架构,让RL训练的整体吞吐量飙升了惊人的5.48倍。这不仅仅是速度的提升,更是让模型在有限的算力预算内,能够经历十倍、百倍于过去的复杂环境试错,真正实现了“在真实任务中持续自我进化”。
3. 算法创新:应对异步环境的“走火入魔”
然而,异步训练带来了一个棘手的数学问题:Off-policy(离策略)偏差。当训练节点更新了权重后,生成节点可能还在用旧的权重执行任务。这种偏差如果不加控制,会导致模型在训练中发生策略偏移(Policy Shift),最终彻底崩溃。
为解决这一难题,GLM-5的工程师团队提出了一系列极其硬核的异步智能体RL算法:
双侧重要性采样(Bilateral Importance Sampling):通过极其精密的数学修正,在异步条件下动态补偿生成策略与当前更新策略之间的概率偏差,死死稳住了训练的底盘。
Token-in-Token-out机制:在长达几小时的软件工程任务中,模型需要频繁处理环境反馈。该机制避免了反复的文本分词(Re-tokenization)带来的累积对齐误差,确保了长程逻辑的严密性。
DP感知的路由优化(DP-aware routing):针对极耗显存的KV Cache,设计了专门的数据并行感知调度策略,进一步榨干了硬件的每一滴性能。
4. 扎根评估(Grounded Evaluation):消灭“作弊者”
在训练高级智能体时,还有一个致命的陷阱叫“奖励作弊”(Reward Hacking)。如果你只是告诉模型“通过测试就给奖励”,模型很快就会学会写出那些专门用来骗过静态测试脚本、但在实际业务中根本跑不通的“假代码”。
为了彻底断绝模型的作弊念头,GLM-5在Slime框架中引入了“裁判智能体”(Judge Agent)。这个裁判不是去预测代码对不对,而是真刀真枪地把模型生成的代码拉到沙盒里去执行。如果模型写了一个Web应用,裁判智能体就会运行构建命令、起服务、甚至模拟用户去点击按钮测试功能。
这种建立在Ground Truth(地面真值)基础上的物理反馈,让模型无从作弊,必须老老实实地学会在真实世界中编写真正可运行的系统级代码。
四、降维打击的实战答卷:全面逼近Claude Opus 4.5
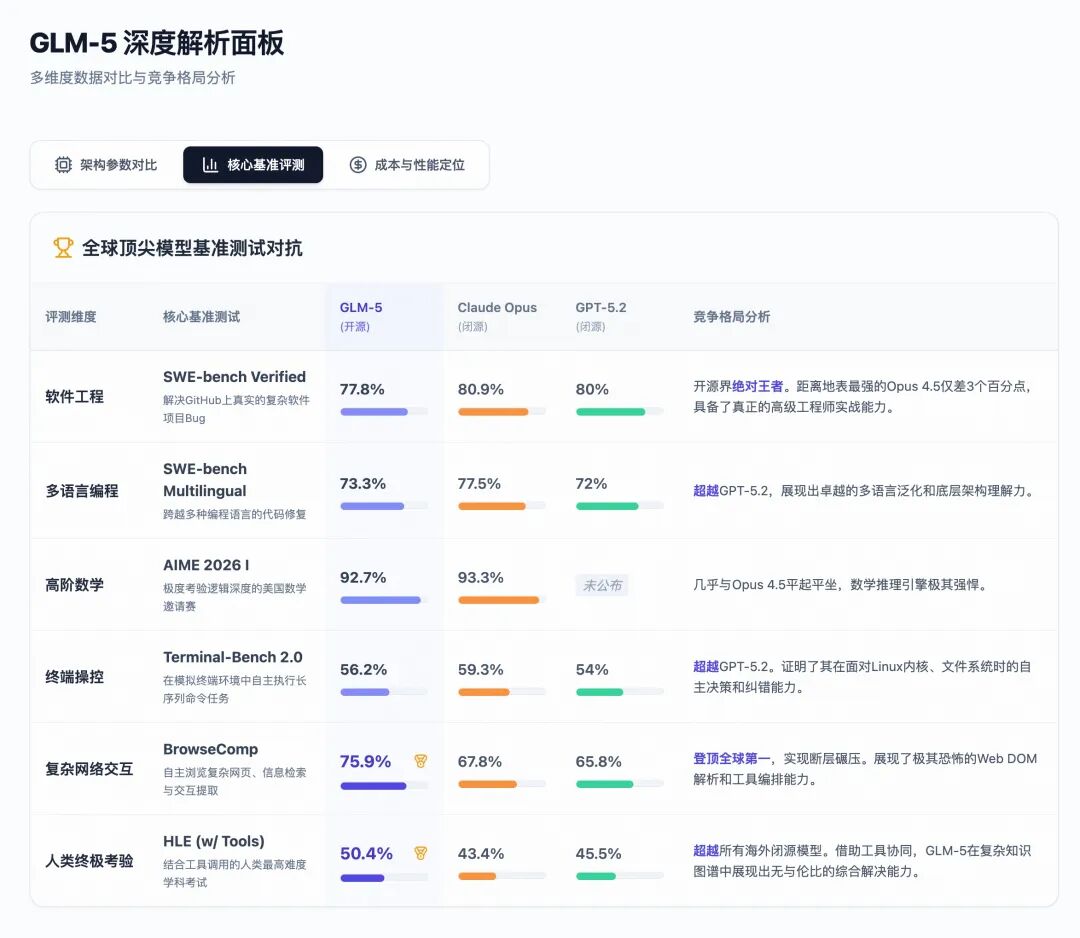
架构和算法上的狂飙突进,最终在极其苛刻的基准测试中迎来了大考。GLM-5交出了一份足以让西方闭源大厂汗颜的答卷。它不仅在Artificial Analysis的Intelligence Index v4.0中以50分的惊人成绩成为全球首个突破50分大关的开源模型,更在多个真实世界的高难度挑战中展现了统治力。
我们不妨通过一组直观的数据表格,看看GLM-5是如何在各大核心战场上与当前地表最强的闭源模型Claude Opus 4.5以及GPT-5.2进行近身肉搏的:
(注:数据摘自智谱官方报告及第三方权威评测平台)
1. SWE-bench:从写片段到修底层的跨越
在AI编程领域,SWE-bench Verified被公认为试金石。它不再是那种“写个二分查找”的八股文测试,而是直接将AI丢进一个包含数以万计文件的真实开源项目(如Django、React)中,给出一个真实的Issue描述,要求AI自己定位问题、修改代码、并且必须通过项目组原有的所有单元测试。
GLM-5在这里拿下了77.8%的惊人成绩,不仅蝉联开源榜首,更是极其逼近了Claude Opus 4.5的80.9%。在内部的CC-Bench-V2全栈测试中,GLM-5甚至达到了98%的前端构建成功率和74.8%的端到端正确率。这意味着GLM-5已经跨越了“副驾驶(Copilot)”的范畴,可以被直接作为“自动驾驶(Auto-pilot)”的软件工程师接入企业工作流。
2. Vending Bench 2:一场残酷的长周期生存实验
如果说SWE-bench考察的是深度,那么Vending Bench 2考察的就是“耐力”与“长期一致性”。
这是学界最新提出的一个极其变态的智能体长周期测试。在这个模拟沙盒中,模型被赋予了一项任务:在长达一年的模拟时间里,自主经营一家自动售货机公司。
在这个过程中,模型没有任何人类干预,它必须:
主动调用搜索引擎寻找真实的零食供应商;
撰写电子邮件与供应商议价、下订单并追踪物流;
根据模拟器给出的季节交替、天气变化(比如夏天多进冷饮,雨天少进货)动态调整数百种商品的库存和零售价;
支付每日的高昂租金,严控现金流避免破产。
完整跑完一年,模型平均要生成3000到6000条消息交互,吐出高达6000万到1亿个Token。绝大多数顶级模型在跑到几十万Token时,就会出现“灾难性遗忘”或陷入死循环(Meltdown)——要么忘记进货导致无货可卖,要么定价失误导致资金链断裂被强制清算。
但得益于Slime框架赋予的极致上下文稳定性和长程规划能力,GLM-5在经历了漫长的一年经营后,以4,432美元的期末账户净余额,傲视群雄,稳居开源模型第一名!它的经营能力甚至超越了Gemini 3 Pro,直逼Claude Opus 4.5的4,967美元。
这场虚拟的商业生存战,彻底坐实了GLM-5作为下一代“系统级智能体核心”的历史地位。
五、全栈硬件重构:中国AI算力生态的“成人礼”
如果在上述光鲜亮丽的性能数据背后,依然是成千上万张被美国牢牢封锁的NVIDIA H100显卡在嗡嗡作响,那这份报告的意义将大打折扣。
但事实并非如此。在整个GLM-5的技术报告中,隐藏着一条让全球地缘科技观察者极其震动的暗线——这是一场完全在国产硬件土壤上绽放的技术奇迹。
由于众所周知的制裁原因(智谱在2025年1月被列入美国实体清单),GLM-5的744B庞大身躯,是在极其严苛的硬件约束下孵化出来的。据多方信源及报告确认,GLM-5的训练全程摒弃了对美国制造芯片的依赖,完全基于华为昇腾(Ascend)芯片及MindSpore框架构建,并且调度了规模达十万卡级别的超大计算集群。
更具战略意义的是,GLM-5并没有止步于在单一平台上“能跑”,它在发布的第一天,就宣布完成了对中国七大主流GPU生态的原生深度适配:华为昇腾、摩尔线程、海光、寒武纪、昆仑芯、天数智芯、燧原悉数在列。
这绝对不是简单的代码移植,而是一场惨烈的底层系统工程重构。
熟悉国产芯片生态的人都知道,单卡算力(TFLOPS)往往不是最大的瓶颈,真正的天堑在于芯片之间极其薄弱的通信带宽以及残缺的软件栈(Software Stack)。为了让GLM-5在这些芯片上跑出极致效率,智谱的工程师团队深入到了CUDA的内核级别,进行了大刀阔斧的手术:
分布式并行策略的“因地制宜”:针对国产硬件互联带宽不足的劣势,团队彻底重构了张量并行(TP)、流水线并行(PP)、数据并行(DP)和专家并行(EP)的路由和切分策略,通过算法上的迂回掩护,极大地掩盖了硬件通信的短板。
INT4量化感知训练(QAT)的全面对齐:为了打破显存墙,GLM-5在监督微调(SFT)阶段就引入了极其激进的INT4量化感知训练。更为硬核的是,智谱甚至为这些国产芯片手写了定制的底层量化算子(Kernel),让模型在极低精度下依然保持了几乎无损的推理能力。
KV Cache调度极限优化:针对长文本(200K)带来的恐怖显存占用,团队重写了内存管理机制,使得长序列处理场景下的部署成本被硬生生砍掉了50%。
结果是震撼的:在经过这一系列疯狂的软硬协同优化后,GLM-5在单一国产计算节点上爆发出的吞吐性能,已经可以直接对标由两张国际主流高端GPU(暗示H系列)组成的计算集群。
这不仅仅是智谱一家公司的技术狂欢。这标志着中国的大模型产业,已经从“被动地把海外架构搬到国产卡上硬跑”,全面进化到了“主动根据国产硬件的拓扑结构,从架构、算法、通信到算子进行全栈系统级定制”的全新阶段。这是一场真正意义上的成人礼。
六、商业重塑与降维打击:让硅谷颤抖的“Token经济学”
技术的突破最终要反映在商业效率上。GLM-5的问世,以一种近乎“残暴”的定价策略,对现有的全球API市场发起了降维打击。
尽管内含7440亿参数,但MoE架构与DSA稀疏注意力的双重加持,让GLM-5的推理成本被压缩到了极致。我们来看一组直接决定开发者生死存亡的定价数据对比:
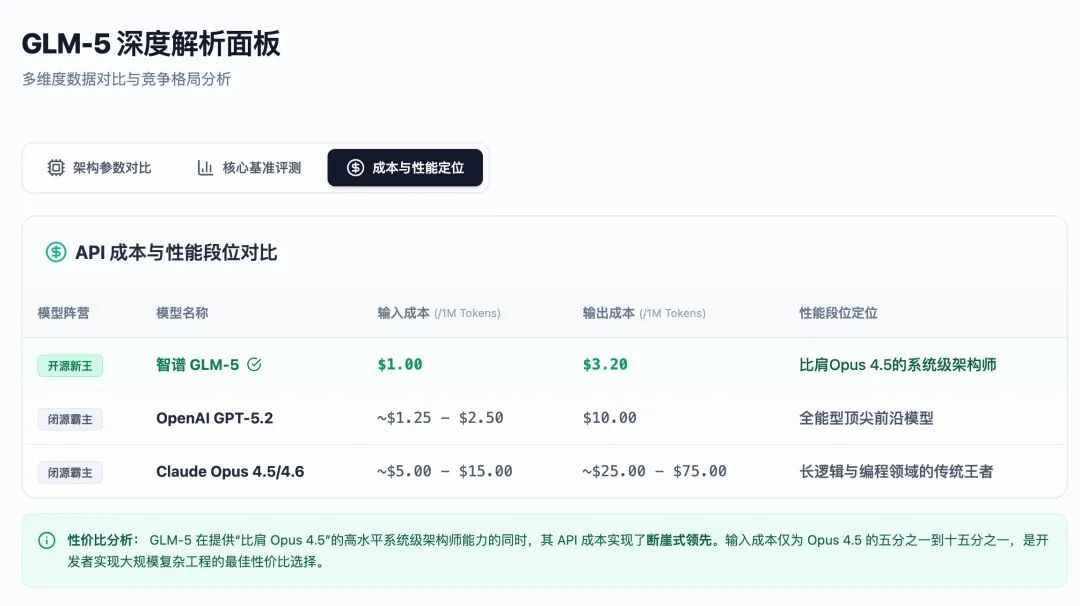
(注:不同渠道的定价存在一定浮动区间,综合自多家科技媒体及API分发平台数据。无论按何种口径,GLM-5的综合成本均呈现压倒性优势。)
数据是冰冷而残酷的。GLM-5在提供了几乎等同于Claude Opus 4.5的硬核编程和长视野智能体能力的前提下,其API调用成本被疯狂地打到了对手的七分之一甚至十分之一!
这种极致的性价比瞬间引爆了全球开发者社区。自GLM-5集成到各大主流编程工具(如Cursor、Roo Code、Claude Code等)以来,海量开发者涌入。在强大的流量冲击下,Ollama等第三方云服务商的节点一度被彻底挤爆。
在国内,这种狂热体现得更为直接。2月12日,由于算力需求远超预期,智谱官方不得不发布价格调整函,宣布对GLM Coding Plan套餐进行结构性调价,整体涨幅自30%起,而海外版涨幅甚至超过100%。即便如此,每天限额的订阅名额依然被瞬间秒空,无数开发者只能在每天上午10点定闹钟蹲点抢购。
在近期的一封致歉信中,智谱坦承由于流量激增导致扩容未达预期,部分用户遭遇了限流,并主动提出了补偿与退款方案。这种“幸福的烦恼”,恰恰证明了市场对能够真正执行复杂工程任务的廉价、高质量智能体模型的极度饥渴。
更为致命的是,GLM-5的权重已经在HuggingFace等平台上以MIT协议完全开源。这意味着,任何具备一定算力基础的初创企业、金融机构或传统大厂,都可以无需缴纳高昂的API“过路费”,直接将一个具备系统架构师能力的超级模型私有化部署在自己的内网中,构建绝对安全的数据护城河。
这对于仍旧深陷高昂推理成本泥潭、固守封闭生态的硅谷巨头们而言,无疑是一记沉重的警钟。
七、结语:不可逆转的历史浪潮
智谱GLM-5的成功,向世界证明了三件极其重要的事情:
AI的发展主轴已经从“无尽的知识压缩”转向了“严谨的系统工程”。能够画图、写诗、陪聊的模型已经烂大街了。未来真正具有巨大商业杠杆率的,是像GLM-5这样,能够在长达几小时的异步强化学习循环中不崩溃,能够深入到代码库底层修复Bug,能够在模拟商业环境中运筹帷幄的“数字执行者”。
开源模型正在强势击碎闭源模型的护城河。当744B的开源模型在SWE-bench这种硬核榜单上逼近闭源天花板,且使用成本仅为前者的十分之一时,大模型作为基础设施的“水电煤”属性已经彻底成型。
中国AI算力生态已经完成了从“能用”到“好用”的跨越。面对严厉的制裁,通过架构层面的DSA稀疏化、系统层面的Slime框架解耦,以及深不可测的底层算子级优化,中国AI团队硬生生地在国产沙地上建起了一座高楼。
在“氛围编程”的泡沫褪去之后,“智能体工程”的时代画卷已经徐徐展开。GLM-5不仅是智谱递给世界的一张耀眼名片,更是宣告国产大模型正式接管硬核生产力的一声惊雷。
对于每一个身处这场浪潮中的开发者、企业和投资者而言,现在已经不是讨论“AI能不能取代我”的时候了。唯一的命题是:在这场由GLM-5开启的智能体效能革命中,你打算如何重新定义自己的生产力?
本文由 @像素呼吸 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


