
 起点课堂会员权益
起点课堂会员权益AI 写 PRD 的瓶颈从来不是模型,而是上下文
AI写PRD的困境并非技术瓶颈,而是行业痛点被集体误诊。本文撕开表层问题,揭示PRD作为产研契约的本质,提出四层重构方案——从隐性规范显性化到业务上下文资产化,再到UI约束与下游对齐机制。这套方法论不仅解决AI工具的结构性缺陷,更重塑了文档作为产研中间件的价值评估标准。

市面上的 AI 写 PRD 产品体验普遍差强人意。
第一反应通常是模型不够强。但把整条流程拆开重搭一遍之后会发现,真正没被解决的问题不是模型能力,而是上下文。这些产品几乎都把 PRD 当成格式问题——给一个模板、套进去、产出一份”看起来像 PRD”的文档。而 PRD 真正难的地方,从来不在格式。
AI 写 PRD 跑不通的根本原因,不是 AI 不会写,而是没有人把”当前公司的 PRD 应该长什么样”翻译成 AI 可执行的输入。
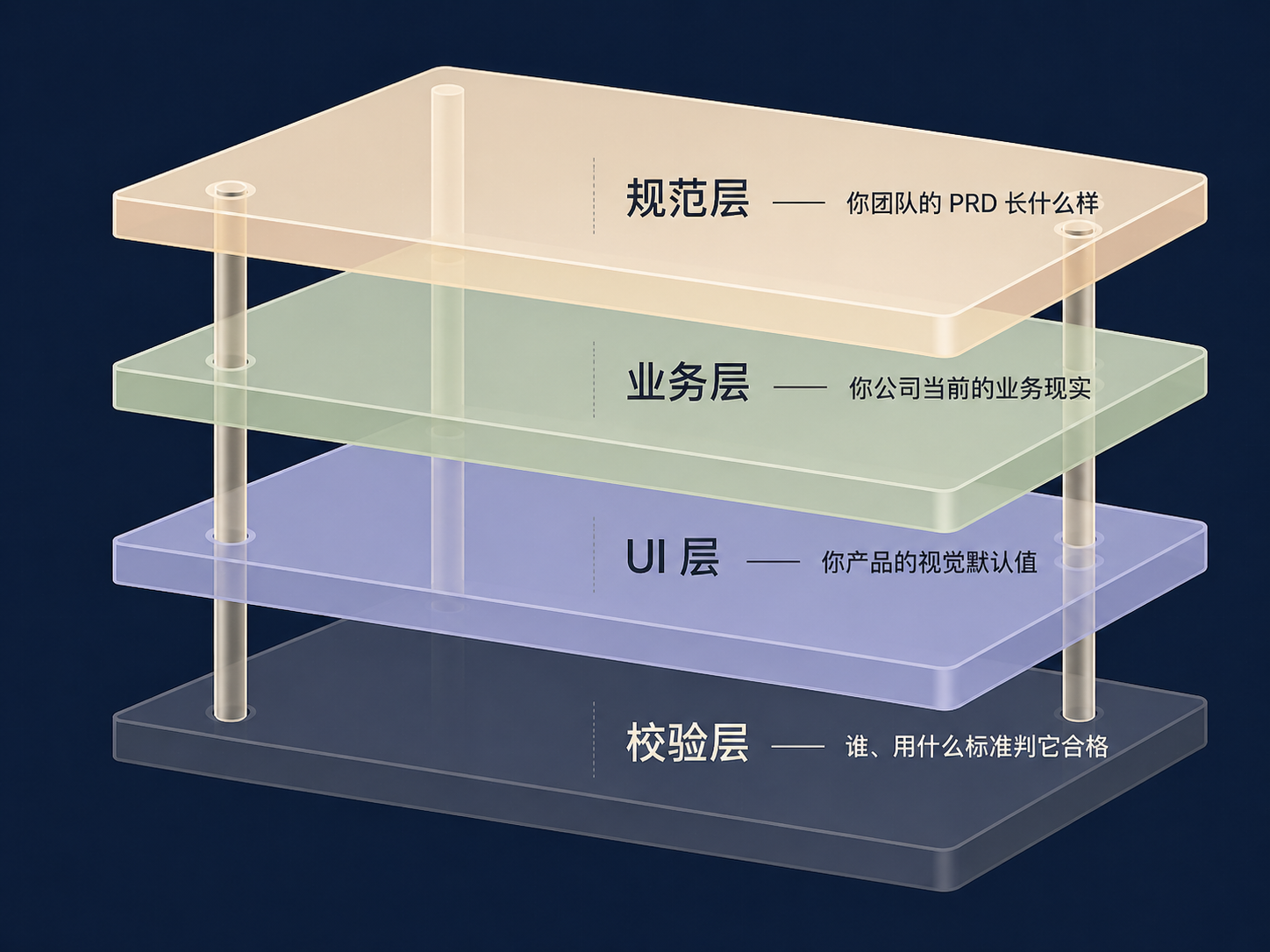
PRD 必须被拆成四层重新理解。
一、PRD 的本质是契约,不是文档
PRD 不是写给 AI 的,也不是写给老板的,而是研发、设计、测试、业务方之间的一份契约。
契约能否成立,取决于四件事是否被同时锁住:
- 规范层:这家公司的 PRD 长什么样、写到什么颗粒度、哪些字段不可省略。
- 业务层:当前的业务模式、组织架构、上下游约束、历史包袱。
- UI 层:产品的视觉默认值、组件库、交互范式。
- 校验层:写完之后,由谁、按什么标准判它合格。
通用 AI 写 PRD 工具最多覆盖第一层的一部分,剩下三层全部依赖用户在对话里临时补全——补一次丢一次。”差强人意”是结构性结果,不是模型迭代能解决的问题。
可用的流程,本质上是把这四层逐一显性化、外置化、可复用化。
二、规范层:把隐性共识强制显性化
第一步不是给 AI 一个模板,而是把团队历史上的多份真实 PRD 与一个基础模板交叉喂给 AI,让它反向归纳出一份规范。
看似偷懒,实际是在做一件没人做过的事:把那种”老人一眼能看出哪里不对、新人写出来总差点意思”的隐性共识,逼成一份白纸黑字的规则。
模板是死的,历史 PRD 是活的。两者交叉之后产出的规范,比任何单独模板都贴近团队真正的写作习惯。
真正的问题不是 AI 不知道 PRD 长什么样,而是团队从未把”自己 PRD 应该长什么样”系统性地写下来过。
到这一步,AI 已经能产出一份形式合格的 PRD。但还无法落地——因为它不懂业务。
三、业务层:把上下文从对话沉淀成资产
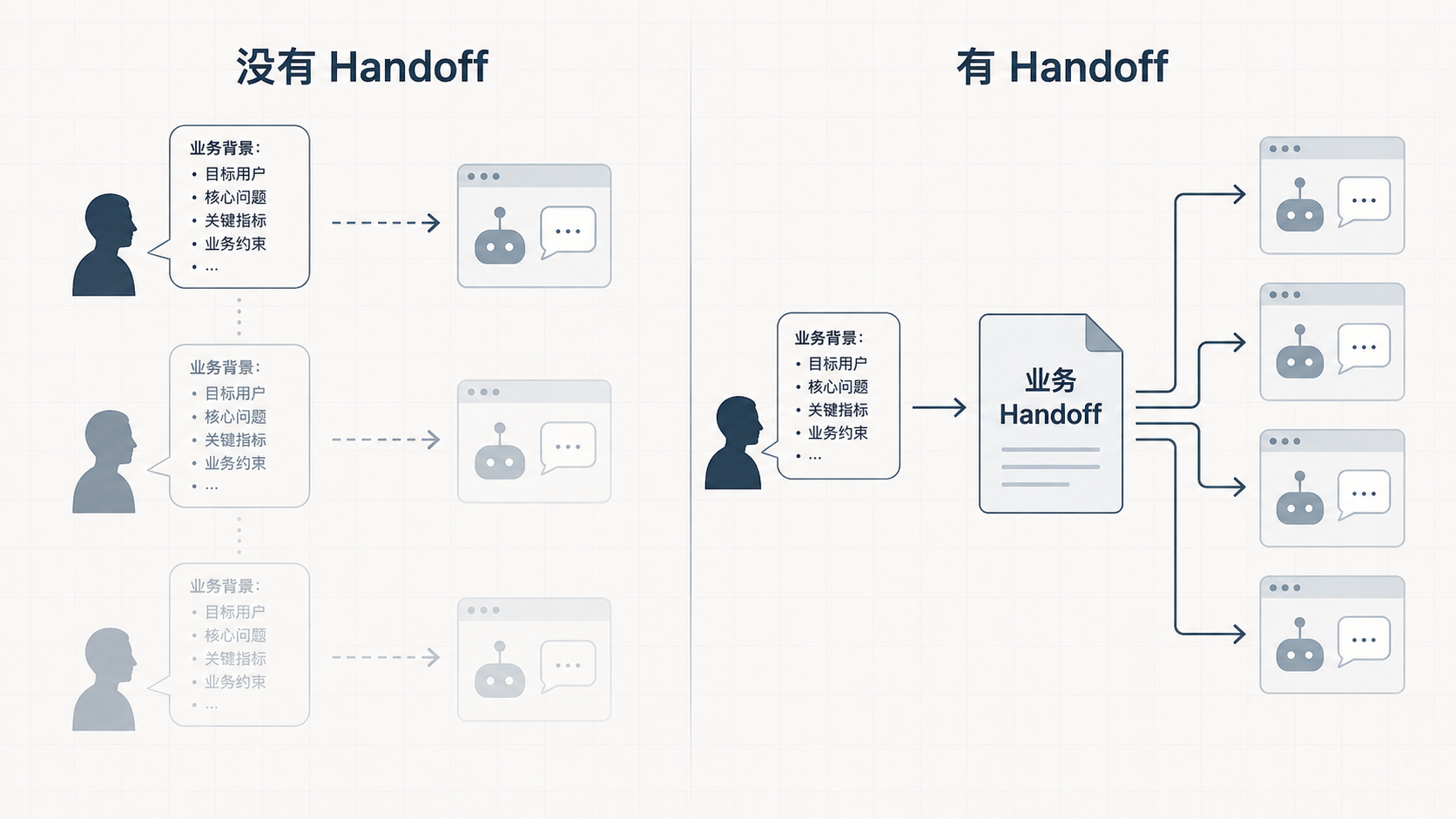
绝大多数流程卡在这里。每开一个新对话,都要重新讲一遍业务模式、用户画像、链路逻辑、决策背景。讲完一次产出一份还能看的东西,下一次又得从头讲。
这不是 AI 的问题,是上下文缺乏沉淀机制。
可用的做法是引入两个 Skill:Office Hour 和 ljg-roundtable。前者负责追问业务现实——需求服务谁、现状是什么、当前方案为什么是这个样子;后者负责多角色辩论——把同一件事从不同利益方的视角再撕一遍。
产出物不是 PRD,而是一份业务 Handoff 文档。它的价值在于:
- 把业务上下文从一次性对话变成可复用资产。
- 强制把模糊的业务理解写成明确判断;写不出来的部分,就是尚未真正想清楚的部分。
- 让后续每一次写 PRD,AI 拿到的都不是临时拼凑的背景,而是与规范同等地位的输入。
业务上下文最大的浪费,不是讲不清楚,而是讲清楚了之后没存下来。
规范 + Handoff 共同作用,才能让 AI 输出一份既标准化、又贴业务的 PRD。
四、UI 层:把视觉默认值写进契约
涉及前端功能的 PRD 一旦缺失 UI 规范,等于把交互定义权完全交给模型的训练分布——默认产出一种”通用 SaaS 风格”,与公司现有任何页面都对不上。
补救方式很直接:把 UI 规范 + 几个真实 UI 样例喂给 AI,让它生成一段适配当前 PRD 场景的 UI 描述。
这一步的目的不是让 AI 设计界面,而是:
- 把视觉默认值锁进契约。
- 让下游原型生成工具拿到的是有约束的输入,而不是一张白纸。
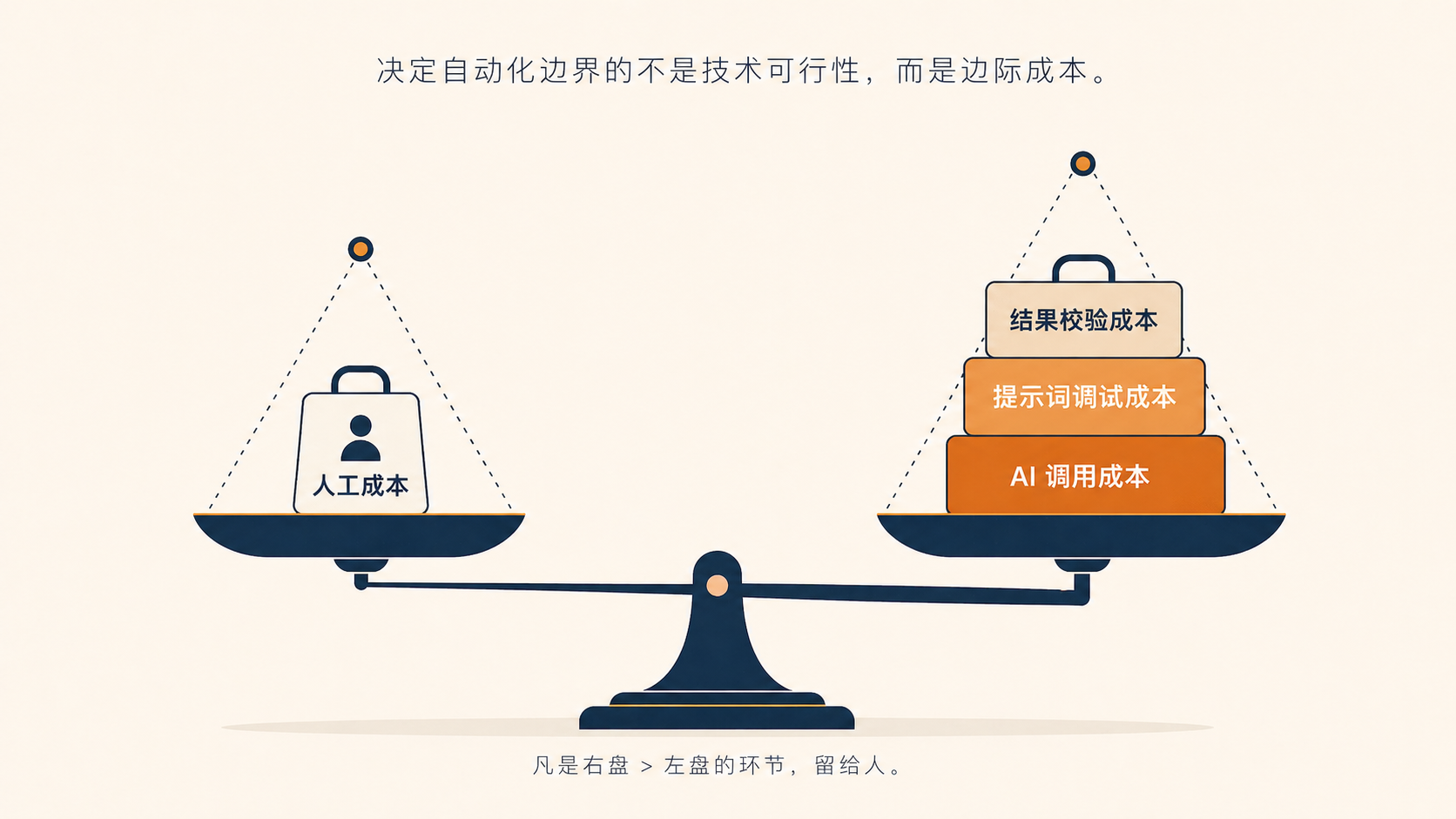
五、原型层:自动化的边界由经济性决定
把 PRD + UI 规范喂给原型生成工具,拿到原型图后,手动贴回 PRD。
看似反 AI,实际是一次清晰的成本判断:让 AI 自动识别、定位、插入正确位置的原型图,所需的提示词调试成本、错误率、复核成本,显著高于人工复制粘贴两分钟。
自动化不是越多越好。一个动作要不要交给 AI,看的是边际成本,不是技术可行性。
六、校验层:判断、执行、校验三件事必须拆开
PRD 写完后,先按规范让 AI 自检——字段是否缺失、颗粒度是否到位、是否存在自相矛盾,再进入人工复核。
AI 自检不是替代人,而是清掉机械的、规则化的、人容易漏掉的问题,把人的注意力释放到真正需要判断的地方:业务逻辑是否自洽、边界是否清晰、风险是否暴露。
这是 AI 自动化里最稳的一种结构:判断、执行、校验三件事拆开。规范定义判断,AI 完成执行,自检 + 人工承担校验。任何一层省掉,整套流程的可靠性都会指数级下滑。
七、再往前一步:格式必须向下游对齐
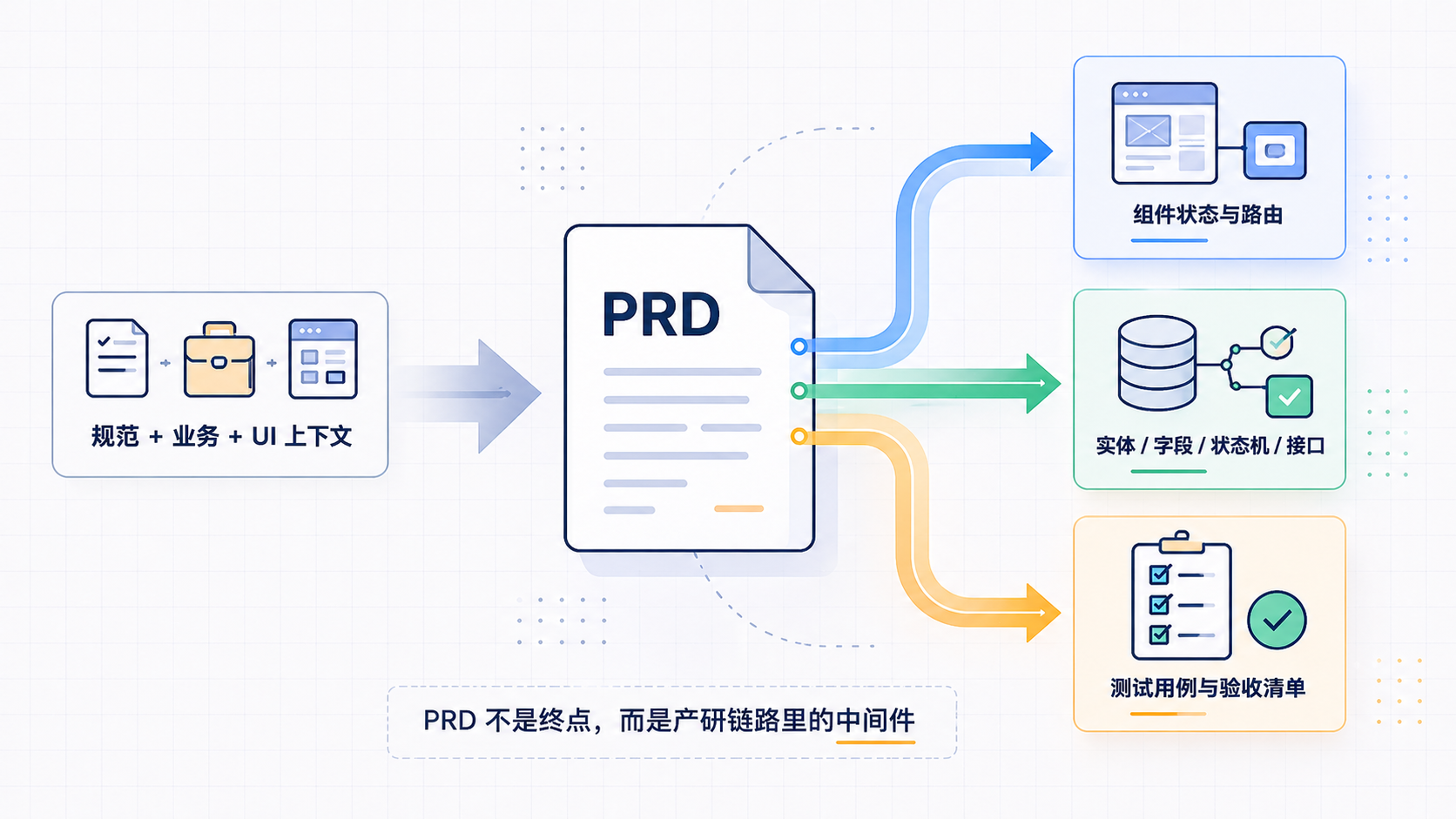
PRD 不是终点,而是上游。它真正的读者不是 AI,也不是产品本身,而是下游三个角色——开发、设计、测试。三类角色阅读 PRD 的姿势完全不同:
- 前端关注:页面有几个状态、每个状态的数据来源、交互触发后跳转到哪、空态错态加载态如何处理、字段从哪个接口取。
- 后端关注:实体定义、字段约束、接口出入参、状态机流转、异常分支、幂等并发、权限边界。
- 测试关注:每条业务规则能否拆成可验证用例、边界值在哪、前后端契约是否一致、什么算”做完了”。
大多数 PRD 难用的根本原因是按产品经理的叙事顺序写——先讲背景、再讲方案、再贴几张图——而下游三个角色没有一个按这个顺序读。前端跳着找状态,后端跳着找字段,测试跳着找规则,每个人都要做一次二次加工。
看起来是 PRD 写得不够清楚,本质上是 PRD 的结构没有向下游产物对齐。
迭代规范时,PRD 的格式必须主动向下游需求形态靠拢:
- 业务规则写成可枚举的条件 – 行为对,测试可直接抽用例,而非从散文里翻规则。
- 数据部分写成实体 + 字段 + 约束 + 状态机,后端可直接对照建表与定义接口契约。
- 交互部分写成状态 + 触发 + 下一状态 + 数据依赖,前端可直接拆组件与路由。
- 验收部分单独成节,写成可勾选的检查项,测试与复核共用同一份清单。
PRD 一旦如此组织,开发拆任务、测试写用例的时间会被显著压缩——下游不再需要把 PRD 翻译成各自工种的工作语言,PRD 本身就已经是下游可执行结构的草稿。
抽象到上层结论:
一份文档是否好用,不取决于作者自认为多清晰,而取决于读者需要做多少二次加工。
PRD 不是孤立产物,而是产研链路中的中间件。中间件的价值不在自身完整度,而在两端对接成本的低。优化”PRD 看起来对不对”是优化错误的目标;正确的目标是优化”下游拿到这份 PRD 之后,到能写代码、能拆用例之间还差几步”。
差得越少,PRD 越值钱。
八、五条可迁移原则
跑顺这套流程之后,真正沉淀下来的不是一份 PRD 模板,而是几条可迁移到任何 AI 协作场景的判断:
- 任务输出与团队风格强相关时,必须先把隐性共识显性化。 通用工具能解决格式,解决不了风格;风格只能从历史样本反向归纳。
- 任何会被反复使用的上下文,都必须沉淀为可复用文档。 上下文的浪费不在讲不清,而在讲清了不存。
- 当某个动作的”AI 成本 + 校验成本”高于人工成本时,留给人。 自动化的边界由经济性决定,不由技术可行性决定。
- AI 输出需要承担业务责任时,必须有规范层做约束、校验层做兜底。 AI 写得对不对,不能由 AI 自己说了算。
- 任何中间产物,格式都要向下游对齐,而不是向上游叙事对齐。 文档好坏的衡量标准,是下游二次加工成本,不是作者的清晰感。
九、结论
AI 写 PRD 的瓶颈从来不是模型。
模型能力每半年翻一倍,但团队规范、公司业务、UI 默认值、PRD 验收标准、下游真正需要的结构——这五件事不会因为模型变强就自动出现在对话里。
真正能跑通的 AI 写 PRD 流程,不是寻找更聪明的 AI,而是把这几层上下文一次性外置好,做成可喂给任何模型的输入管线,并让输出直接对齐下游可执行形态。
跑通一份 PRD 不难,难的是搭一套不依赖某次对话、某个模型、某个人记性的 PRD 生产管线。
模型会换,规范会沉淀。这才是真正的杠杆。
本文由 @诸葛铁铁 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Pexels,基于CC0协议









差强人意:基本上满意
哈哈哈哈,你不提都快忘了这个词原本的意思了