
 起点课堂会员权益
起点课堂会员权益你装了 10 个 AI 插件,Obsidian 还是一个文件夹
从给Obsidian装AI插件到让AI读取Obsidian知识库,这是一场认知革命的反转。当AI真正成为生产力主力时,我们需要重构知识库分类逻辑、建立可进化的指令流水线、设计动态项目空间——这些才是让AI突破'更聪明文件夹'局限的关键。本文将揭示如何通过三层系统设计,将个人知识库转化为AI可执行的'操作系统'。

我第一次装上 Obsidian 的 AI 插件时,确实兴奋了。Smart Connections 能帮我找到”相关笔记”,Copilot 能在笔记里直接对话,Text Generator 能一键生成摘要。那种感觉像什么呢——就像你刚拿到一把电钻,满屋子找钉子,觉得什么都能钻。我真的什么都试了。给读书笔记自动打标签,给会议记录自动总结,给零散灵感自动找关联。折腾了几个月,vault 里干干净净,双链密密麻麻,打开图谱视图,好看得像一幅星空图。
然后呢?
2024 年底,我正在做一个 AI 辅助诊断系统的产品方案。打开 Obsidian 准备翻之前收集的行业资料,突然想到一个问题:”今年我用这套系统产出了什么?”
我翻了翻。笔记从大概 180 条涨到了快 600 条。标签翻了好几倍。但如果你问我”做成了几件事”,我想了半天——那个诊断系统的方案确实在推进,但其他收集的素材呢?几乎全躺着。
笔记越来越多,产出没有变多。
当时我坐在电脑前愣了好一会儿,心想:我是在做知识管理,还是在做知识收藏?
这不是 Obsidian 的问题,也不是插件的问题。是我搞反了一件事:我一直在让 AI 帮我整理笔记,但从来没问过,这些笔记整理完了给谁用。
给我自己用啊——当时觉得理所当然。我记笔记,AI 帮我理笔记,我再读笔记。这个闭环看起来完美,但有一个致命的瓶颈:我自己。
我一天能读多少笔记?能处理多少信息?能做多少个决策?就算 AI 把我的 vault 整理得像图书馆一样有序,干活的还是我。AI 的能力被锁死在了”帮我整理仓库”这一件事上。
说白了,我花了几个月时间,用 AI 搭了一个更高级的文件夹。
后来想明白了。问题的根源在别处:如果 AI 才是真正干活的主力,它需要什么样的工作环境?
一、反向插件:别给 Obsidian 装 AI,给 AI 装 Obsidian
2024 年以前,我跟大多数人一样,觉得 AI 是工具,我是使用者。所以我给 Obsidian 装 AI 插件——AI 是螺丝刀,拧在 Obsidian 这把瑞士军刀上。
2026 年,我发现这个关系完全可以反过来。
不是给 Obsidian 装 AI,而是给 AI 装 Obsidian。
什么意思?以前 AI 是装在 Obsidian 里面的一个功能模块,你打开笔记,点一下按钮,AI 帮你干点活。现在反过来——Obsidian 是 AI 的操作系统,AI 打开你的 vault,读你写的规则和流程,照着你的方法论去干活。
我把这叫”反向插件”。
正向插件:AI 装在 Obsidian 里,你触发它,它帮你干活。本质是 AI 服务人。 反向插件:Obsidian 变成 AI 的上下文层,AI 读取你的 vault 来决定怎么干活。本质是人的经验服务 AI。
打个比方。正向插件是给木匠买了一把电钻——木匠还是木匠,活还得他自己干,只是快了一点。反向插件是把木匠三十年的手艺写成了操作手册,交给了一台能读懂手册的机器人。木匠不再动手,但他的经验在每一件产品里。
为什么”反向”更强?
因为 AI 真正的瓶颈在上下文。一个没有上下文的 AI,你每次跟它对话都是从零开始——它不知道你之前踩过什么坑,不知道你的项目用什么技术栈,不知道你习惯怎么做决策。你跟它的协作永远停在”第一天上班”的状态。
但如果你把所有经验、所有踩过的坑、所有标准化的流程都写进了 Obsidian,然后让 AI 读取这些文件再开始干活——它的起点就变了。你积累了多少年,它就站在多少年的经验之上。
Obsidian 天然适合干这件事。它的底层是 Markdown 纯文本,AI 可以直接读写,不需要 API 适配、不需要格式转换。vault 就在你的硬盘上,Claude Code 这样的 AI 工具直接访问文件系统就行,不需要过云端,也没有数据隐私问题。更关键的是,你的目录树本身就是 AI 的导航地图——”知识库/运维部署/”这个路径就在告诉 AI:遇到部署问题,来这里找答案。不需要数据库,不需要任何配置。
Obsidian 的 CEO Steph Ango(网名 Kepano)显然也看到了这个方向。2026 年初,他亲自开发并开源了一套官方 Agent Skills,让 Claude Code、Codex 这些 AI 工具能直接读写 Obsidian vault。一个 9 人团队、400 万用户、2500 万美金 ARR、拒绝融资的公司,CEO 亲自下场给 AI 写 Skills——他在押注方向。
大多数人在教 AI 读他们的笔记。少数人在把笔记写成 AI 能执行的指令。前者是在调教一只宠物,后者是在设计一个操作系统。
那”操作系统”长什么样?我拆成三层来说。
1. 记忆层:知识库不是给你看的,是给 AI 读的
翻转了方向之后,第一个要重建的是知识库。
以前我的知识库是按”来源”分类的——读书笔记、课程笔记、文章摘抄、会议记录。这是人的直觉:我从哪学到的,就放到哪个文件夹。
但你想过没有,当知识库的消费者从”你”变成”AI”的时候,这种分类方式就完全不对了。
场景是这样的:我让 Claude Code 帮我部署一个服务。它需要知道服务器 IP 是什么、环境变量怎么配、上次部署踩了什么坑。这些信息分散在我的”读书笔记””工作日志””踩坑记录”三个不同文件夹里。AI 不会像我一样去翻——它不知道”这个知识是我从上次部署事故中学到的”。
它只知道一件事:我正在做部署,部署相关的信息应该在哪里?
所以我重构了整个知识库的分类方式。不按来源分,按消费场景分。
这不是换了个名字而已。背后的逻辑完全不同。
按来源分类,检索路径是”我记得这个知识是从哪本书看到的”——你需要回忆信息的出处。但出处记忆是相对脆弱的。你可能记得”服务器端口冲突怎么解决”,但你大概率不记得”这个解决方案是在哪本书第几章看到的”。
按场景分类,检索路径变成了”我正在做什么”——认知心理学里叫编码特异性原则(Encoding Specificity Principle)。1975 年 Godden 和 Baddeley 做过一个经典实验:让潜水员在水下记单词,结果在水下回忆的成绩远高于在岸上回忆。原因很简单——回忆时的情境越接近编码时的情境,提取效果越好。你正在做部署,大脑会自动激活所有和”部署”相关的记忆。同样,AI 正在执行部署流水线,它自然应该去”运维部署”目录下找信息。
对 AI 来说,场景分类还有一个更直接的好处:它可以只读需要的文件夹,不用扫描整个 vault。上下文窗口是有限的,你不希望 AI 在写文章的时候,脑子里塞满服务器配置信息。
重构之后我做了一件事来验证效果。我让 Claude Code 读取”运维部署”目录下的文档,然后直接执行一次服务部署——从拉代码、配置环境变量、启动服务到检查日志,全程它自己看着文档干。
以前这套流程我自己做,翻文档加上排查问题,至少半小时。现在 AI 照着知识库执行,我只在最后看一眼日志确认服务正常。
这才是知识库真正的价值——”AI 在过去 30 天内调用了我的几条知识”,这个指标比”我记了多少笔记”重要得多。你可能觉得这话太绝对了。但你想想——如果一条知识既不被你用,也不被 AI 用,它存在的意义是什么?安慰你”我是一个爱学习的人”?
我现在定期清理 vault,标准就一条:过去一个月没被调用过的笔记,要么合并到对应的知识库场景下,要么直接删掉。刚开始删的时候心疼,后来发现删完之后 AI 的效率反而提升了——因为它需要扫描的干扰信息变少了。
2. 指令层:流水线才是你最值钱的资产
知识库解决了”AI 知道你知道什么”的问题。但光有知识不够——AI 还需要知道你怎么干活。
我管它叫指令层,具体落地形式是流水线。跟大多数人理解的”工作流”或者”模板”不一样,流水线是会自己进化的。
先说一个你大概率经历过的场景。
你让 AI 帮你写一篇文章。你打开对话框,输入”帮我写一篇关于 Obsidian 的文章”。AI 花三分钟给你生成了 2000 字——结构是”引言→三个要点→总结”的万能模板,内容正确但平庸,读起来像每个 AI 都会写的那种东西。
你不满意,又花 20 分钟跟它来回调教:加点案例、换个角度、语气别那么 AI、结尾别写”欢迎留言”。改了三轮,勉强能看。
下次写文章,你还得重复这整个过程。
问题出在哪?AI 不笨,是你没告诉它你的标准是什么、你的流程是什么、你之前踩过什么坑。你跟 AI 的每一次对话都是一次性的。今天教它的东西,明天它全忘了。
你以为 AI 没记性。其实是你没给它记忆。
流水线就是解决这个问题的。
一条流水线长什么样?我拿自己写文章的流水线举例。别把它想成一个模板——它是一整套系统,存在 Obsidian 里:
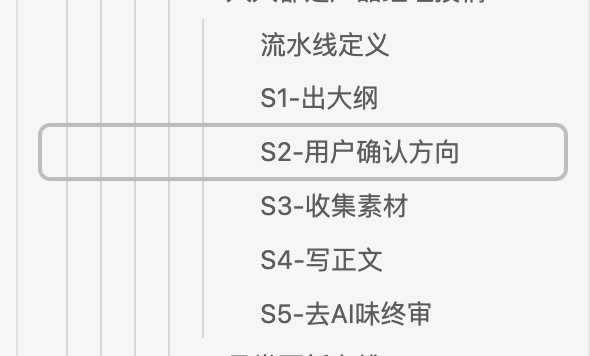
每一步都有明确的输入和输出,有评分标准,有提示词。但这些都不是最关键的。
最关键的是流水线定义文件底部的经验库。
每完成一篇文章,我会在经验库里追加这篇文章的”有效升分动作”和”踩过的坑”。比如我写第一篇文章的时候,犯了一个错——把三层结构压缩成了一章子弹点,论证骨架全塌了,自评只有 79 分。这个教训被记录在了经验库里。写第二篇的时候,AI 在出大纲阶段就会读到这条教训,自动避开同样的坑。
第二篇的框架命名也有一个教训:最初叫”三块拼图”,描述性太强,读者记不住。后来改成”三种判断权”,命名性一下就上来了。这个经验也沉淀进了经验库。
到第三篇文章(就是你现在读的这篇),AI 出大纲时已经站在前两篇的经验之上。它知道每层必须独立成章,知道框架必须有可复述的命名,知道金句要有攻击性而不是鸡汤。
这就是我说的经验复利。
写文章是这样,部署上线也是这样。我有一条”日常更新上线”流水线,4 步走完:本地推送代码 → 服务器拉取重启 → 检查启动日志 → 浏览器验证。第一次部署的时候踩了一堆坑——端口被占用、环境变量漏配、进程没杀干净。这些全被记进了流水线的踩坑记录。第二次部署,AI 读到这些记录,每一步都会主动检查”端口是否占用””环境变量是否完整”。到现在,部署基本不出问题了。
普通人写第十篇文章和写第一篇文章的效率差不多——因为经验存在大脑里,模糊、不稳定、容易遗忘。但如果你把经验写进流水线的经验库,AI 每次读取它,起点就比上一次高。第一篇靠直觉,第三篇靠系统。第一次部署靠运气,第五次部署靠积累。
这不是工作流自动化。自动化只是让你”做得更快”。流水线让你”做得越来越好”——因为它包含了一个学习机制。
有人可能会问:这不就是 SOP 吗?
不完全一样。传统 SOP 是写给人看的,但人会偷懒、会跳步骤、会”我觉得这步可以省”。流水线是写给 AI 看的——AI 不会偷懒,你写了 5 步它就走 5 步,你写了评分标准它就逐项打分。而且 AI 不会觉得”这个教训我已经知道了不用再看”——它每次都会老老实实读一遍经验库。
说白了,大多数人和 AI 的关系,就像每天面试一个新员工,面试完不录用,第二天再面试一个新的。你从不写 SOP,从不做入职培训,然后抱怨”这个员工怎么什么都不会”。
流水线就是你给 AI 写的入职培训手册、操作规范和经验传承文档——打包放在 Obsidian 里,AI 每次开工前自己读。
这样做的结果是什么?
我现在半天可以从零到一做出一款产品。这句话需要拆开说:AI 先读我知识库里的技术栈文档,知道我用什么框架、什么部署环境;然后按流水线走——先出 UI 设计方案让我确认,再写前端页面,再搭后端接口,中间还会自己调用需要的工具。每一步都有知识库里的踩坑记录兜底。我做什么呢?我在几个关键节点做判断——这个交互对不对、这个逻辑有没有漏洞、这个页面上线前要不要再调一下。
这个效率差距,根子上取决于你花了多少时间把自己的经验写进了系统里。AI 的能力大家都一样,马具不一样。
3. 执行层:项目空间让 AI 知道”现在该干什么”
记忆层告诉 AI”你知道什么”。指令层告诉 AI”你怎么干活”。但 AI 还需要知道第三件事——现在该干什么。
你可能有这个经历:每次开始一个新对话,你得花 10 分钟给 AI 交代背景。”我们在做一个什么项目””做到哪一步了””上次我们聊到什么结论了”。这 10 分钟不产出任何价值,纯粹是在弥补 AI 的失忆。
项目空间消灭的就是这 10 分钟。
我做一个 AI 辅助诊断系统,跨度好几个月。如果每次开工都要重新交代一遍”这个系统是给谁用的、现在做到哪个模块了、上一轮评审提了什么修改意见”,AI 和我的协作效率会被这种重复性背景交代拖死。
所以我在 Obsidian 里给每个在进行的项目建了一个空间:

AI 每次开工,先读项目空间的当前阶段——”正在开发报告模块,上一步已经完成了数据库设计,下一步是前端页面”。然后读流水线知道这步该怎么做。如果中间遇到技术问题,去知识库找答案。
三层的协作关系是这样的:没有项目空间的时候,知识库和流水线是”闲置资产”——它们存在,但 AI 不知道什么时候该用哪一个。项目空间是触发器,它把”我现在在做什么”这个上下文注入到整个系统里,让知识库和流水线动起来。
缺了记忆层,AI 每次都在裸奔。缺了指令层,AI 知道该知道的,但组织不成行动。缺了执行层,AI 有知识有方法,但不知道你现在在做哪个项目的哪一步。哪一层缺了,AI 都只是一个更快的搜索引擎。
Martin Fowler 在 2026 年写过一个公式:Agent = Model + Harness。Model 是 AI 模型本身,Harness(马具)是模型周围的一切——文档、约束、反馈回路、质量标准。模型决定 AI 的能力上限,马具决定 AI 的实际表现。
这三层——记忆层、指令层、执行层——就是你的个人马具。
OpenAI 的工程师 Ryan Lopopolo 用五个月做了一个实验:团队不手写一行代码,全靠 AI agent 生产,人只负责搭马具。五个月,0 行人类手写代码,约 1500 个 PR,超过 100 万行 agent 生成的代码。到实验后期,单人每天能推 5 到 10 个 PR,产出达到了传统模式的 5 倍。
但有一个细节很少有人提:Ryan 说实验第一个半月,效率比自己单干还慢 10 倍。为什么?因为那段时间他在搭马具——写文档、建反馈回路、设计质量检查规则。马具搭好之后,效率才开始指数级上升。
这跟我的体验一模一样。我花在 Obsidian 里搭知识库和流水线的时间,短期看是”没在产出”。但这些时间投入一旦过了临界点,后面每一次执行都在吃复利。
二、衡量你的 vault,用产出而不是笔记数
大多数人评估自己的知识管理系统时,看的是输入指标:记了多少条笔记、建了多少双链、图谱视图有多壮观。
这就好比一家工厂,老板每天盯着原材料仓库有多满,仓库越满越开心——”你看我们备了多少料!”但客户要的是产品,跟你仓库里堆了多少钢材没有半毛钱关系。
我以前也这样。每周回顾 Obsidian 的时候,心里的尺子是”这周记了几条笔记”。直到我开始跑流水线之后,衡量标准自然切换了——这周 AI 调用我的 vault 产出了什么? 写完了几篇文章?部署了几个服务?推进了哪些项目?
这个视角一转,很多事情变清晰了。
我发现 vault 里有大量笔记从来没有被任何流水线调用过。它们被精心整理、标签齐全、双链完备——但对 AI 来说,它们就是噪音。AI 读取 vault 的时候,这些”死库存”占用上下文窗口,反而降低效率。
所以我做了一件以前绝对不舍得做的事:删笔记。
把那些纯粹”收藏了但从没用过”的内容清掉,把散落的踩坑记录合并进对应流水线的经验库,把写了但从未被调用的读书摘抄归档。清理完之后,vault 从快 600 条笔记降到了不到 200 条——但每一条都在系统里有明确的位置,被真实地调用着。
Obsidian 社区有一种主流叙事叫”构建你的第二大脑”——收集一切、连接一切、永不遗忘。我不否认这种方式对一些人有效。但对我来说,它最大的问题是把收集本身当成了目的。Martin Fowler 在谈驾驭工程时说了一句话,大意是:如果你只有前馈控制(一直往里塞指令和文档)而没有反馈控制(检验这些东西是否真的起作用),你”编码了规则却永远不知道它们是否有效”。笔记也是一样——你往 vault 里塞了一堆知识,但如果从不检验它们是否被调用、是否产生了产出,你就永远不知道你的知识管理到底有没有在工作。
你的笔记不是资产,你的流水线才是。笔记是原材料,流水线是生产线。看一家工厂强不强,看出货量,不看仓库。下面每一个主点都是一条流水线。

三、你的马具,决定了你的马能跑多远
2026 年,AI 领域有一个正在发生但大多数人还没注意到的变迁:从”提示词工程”到”驾驭工程”。
2023 年,大家在研究怎么写好一段 prompt——措辞、格式、少样本示例,像是在跟 AI 谈判。
2025 年,关注点移到了上下文工程——不只是 prompt 怎么写,而是 AI 看到的全部信息怎么组织。
2026 年,OpenAI 发了一篇博客,标题叫《Harness Engineering: Leveraging Codex in an Agent-First World》。Martin Fowler 也写了长文讨论,把马具拆成了四类组件:计算型指引(linter、类型检查)、推理型指引(文档、Skills)、计算型传感器(测试、pre-commit 钩子)、推理型传感器(AI 代码审查)。前沿的做法已经不只是管理信息了,而是设计 AI 周围的整个运行环境。流水线、知识库、反馈回路、质量标准、经验沉淀——这套东西合在一起,就是驾驭工程。
这听起来像是给企业团队准备的高级概念。但你回过头看看前面五章——知识库是推理型指引(告诉 AI 该知道什么),流水线是推理型指引加推理型传感器(告诉 AI 怎么做,做完了怎么自评),项目空间是上下文入口。你已经在做驾驭工程了,只是没用这个名字而已。
Obsidian 恰好是个人实践驾驭工程最顺手的工具。Notion 的数据库功能比它强,飞书的协作能力比它好,语雀的在线体验比它流畅。但这些工具有一个共同的局限:它们是云端优先的、富文本的、需要 API 才能让 AI 访问的。Obsidian 是本地的、纯文本的、AI 打开文件夹就能读的。在驾驭工程的语境下,这个特质比任何花哨的功能都重要。
所有人都在讨论 AI 取代人。但真正发生的事情没那么戏剧化——人和 AI 在重新分工。你判断,它执行。你积累经验,它把经验变成产出。你搭系统,它跑系统。
两年后回头看,拉开差距的不是谁的 AI 更聪明,而是谁更早把自己的经验写进了系统里。
本文由 @苏苏的AI笔记 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


