
 起点课堂会员权益
起点课堂会员权益我的AI写稿全流程公开
现在我发公众号就是打开手机跟Hermes聊两句。它对接4个新闻源,过八层skill写作规则,自动排版推到公众号草稿箱,整条链路跑通了。以前开电脑、找素材、写稿、排版、发布,搞下来一晚上没了。现在是真的没理由再坐到电脑前了。
我有一个从AI新闻选题到文章发布的完整工作流。今天把这条链路拆开讲,每个环节做了什么、数据怎么流、人和AI怎么分工,按顺序梳理一遍。
四个新闻源
AI新闻的起点是四个独立的数据源,每个源的采集方式、数据格式、接入路径都不一样。
数据源1:aiposter
aiposter 是我23年用 vibe coding 做的项目,从一个简单的 AI 翻译迭代成一个灵活而强大的分布式可插拨系统。跑了三年多没断过。它每天从国内外一些我觉得质量较高的网站爬取新闻,自动做总结、筛选,然后生成新闻卡和海报图。这三年我经常用它给社群发AI小报、新闻卡、下载卡,功能从新闻聚合到图片生成都有。
aiposter 的数据让 Hermes 自己写了对接脚本,封装了API调用和本地缓存逻辑,调一下就能拿到当天采集的全部新闻数据,后续环节直接读。
数据源2:news_system
PC 上还跑着 news_system,一个定时运行的 python 项目。它监控的是微博、论文站、行业网站、一些KOL信息源,加上Hacker News,总共七十多个RSS订阅。每天爬取一次,存到本地硬盘。通过SMB挂载读取,Hermes同样自己写了脚本处理挂载检测、文件读取和格式转换。
这两个源的新闻覆盖面互补:aiposter偏精选,news_system偏广撒网,合在一起漏不掉什么大事。
数据源3:Grok每日任务
Grok 官方提供了一个免费的每日任务功能,每天早上自动推送两轮AI新闻:一轮文字版,一轮视频版。零成本,算是Twitter新闻源的一个补充。从Grok拿数据有点曲折:它不提供直接API,通过 Grok tasks 每天把内容推到我的 Gmail 邮箱里。所以流程变成了Hermes先用 CLI 从邮箱读邮件、解析出对话链接、再用 OpenCLI 抓取完整内容。中间几步自己写脚本串起来的,反正是由 Agent 处理的,只要稳定就不叫麻烦。
数据源4:AIHOT
AIHOT是数字生命卡兹克的开源项目,提供分类整理好的AI新闻资讯。接进来作为补充源,丰富整体的信息覆盖面。
合并
四个数据源最终合成一个信息池。合并这件事本身也封装成了一个skill,每个数据源独立采集、独立缓存为JSON,最后由这个skill统一读取、合并、评分、输出。
合并的第一步是URL去重。四个源经常抓到同一条新闻,尤其是大事件,aiposter和news_system会同时收录,AIHOT也可能覆盖。不去重的话同一条新闻会被重复评分,把后面的排序搞乱。去重的时候有个优先级:aiposter因为是精选源,同一条新闻如果aiposter收录了就用aiposter的版本,信息密度更高。
去重之后进入评分。评分规则不是随便定的,是我在实际做新闻筛选的过程中慢慢摸索出来的,针对不同类型的新闻有不同的判断标准。
大厂的战略动作和内幕信号权重高。比如Apple claude.md 泄露这种事,它跟产品发布无关,但暴露了大厂在AI方向上的实践,这种信息对我来说比官方通稿有价值得多。产品翻车、意外爆发的真实案例同样权重高,这种东西自带传播力,还能意外看到各种蛛丝马迹,写起来读者也有共鸣。
反过来,”AI将改变一切””某机构预测2030年市场规模”这种宏大空话直接扣分。但有个例外:像”2028智能危机”这类看起来宏大但确实在讨论真实风险的,反而值得留。区别在于它是空对空的预测,还是有具体场景和论据的判断。
还有一类:实际应用和操作层面的东西。比如某个开发者用特定方法跑通了一个流程、某个工具在真实场景下的使用经验。这类内容不一定有”新闻感”,但对读者来说信息密度高,我也会给不错的分数。
这些规则写进了skill里,定时自动执行。每天跑完输出一个按分数排序的列表,附带上每条新闻的来源标签,方便后面简报筛选的时候做判断。
每天两期推到微信
四源合并后的数据量不小,一次全推过来根本看不过来。所以我把它拆成了两期:中午一期,晚上一期,每期精选5到8条最值得关注的新闻,加上写作灵感的建议。拆成两期有几个好处:每期数量少,我能认真看完;中午和晚上都可能临时起意写点东西,两期简报对应两个可能的写作窗口;另外分两次筛选,质量也比一次堆一堆要高。
简报直接推到我微信上。打开看到两块内容:一块是新闻摘要,另一块是”写作灵感”:从新闻里挑出最适合深写的方向,给一个切入角度。比如某条新闻下面附一句”可以从监管收紧对中小AI公司融资的影响切入”,或者”这个产品翻车事件适合写用户真实体验”。
选题:新闻只是原料之一
写作灵感只是选题的一部分。我这个号的素材来源比新闻简报要杂得多。
比如我自己正在做的事:试着用AI做创作闭环,从选题到发布全部串起来,中间踩的坑本身就是素材。再比如临时起意搞的一些东西:用《三角洲行动》的3D世界来训练AI、重写计算机二进制,各种突如其来的新AI玩儿法,折腾的过程中经常会产生值得写的话题。还有跟朋友聊天时大家对文章的反馈,这些反馈本身就是下一篇文章的种子。
所以选题这个环节,AI负责把新闻原料端上来,但真正触发我写一篇文章的,往往是新闻之外的东西,比如我自己在做什么、碰到了什么、别人怎么回应。
选题决策是我做的。AI能告诉我”这个话题在热”,但判断不了”这个话题值不值得我写”。热点清单里十个话题,八个要么跟别人撞车、要么跟我的调性不符、要么可能是AI说的对而我理解不了? 这都有可能…… 不过目前为止还是我主导。
确定话题之后,我会从各种方便可能的角度指挥 Hermes 开始写初稿,比如一个观点结合一些以前写的文章。 或者心情好了直接口述一些内容告诉 Hermes 怎么继续。 或者直接从推送的新闻加上我的观点。 甚至直接让他推的写作灵感开始写……
写作:八层规则,一层只做一件事
选定话题后进入写作环节,jovi-writing-style。
这个skill不是一开始就长这样的。最早我写了一个很大的skill,把所有写作规范塞在一起,让AI一次全读进去然后写。效果很差。AI面对一大坨规则,要么顾此失彼,要么自以为全都遵守了但实际哪条都没到位。
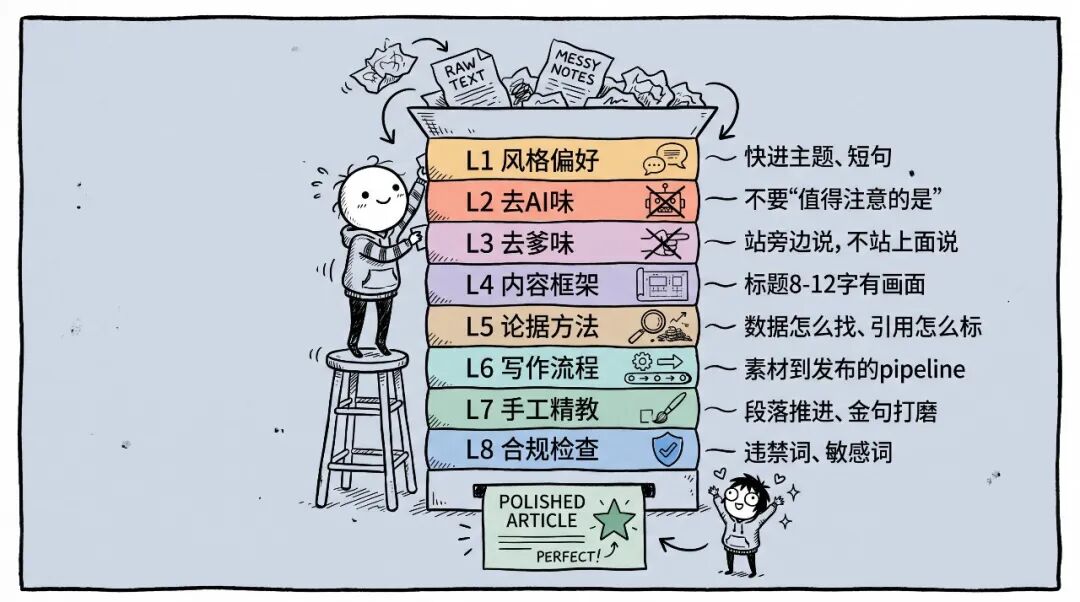
后来我换了思路。我自己写过一套prompt ,认知操作系统LifeOS,里面有一个runtime的概念,核心想法就是让Agent每次只专注处理一件事。我把这个思路搬到写作skill上,把一个大skill拆成了八层,每一层只解决一个具体问题,按顺序加载,处理完一层再进下一层。
L1 风格偏好:定义我说话的基本习惯:快进主题、短钉子句、经济表达。这层是底色,后面所有层都在这个底色上操作。
L2 去AI味:25条技术规范,专门压制大模型的默认表达。不要一句一换行、不要”值得注意的是”、不要替读者说”这很扎心”而要直接写出扎心的事实。大模型的默认说话方式太整齐了,整齐到一眼就能看出来不是人写的。压制这些习惯之后,出来的东西才有了点粗糙的人味。
L3 去爹味:AI写东西容易站在高处提醒读者,语气像在上课。不让它说”你应该””必须警惕”,改成”我现在更倾向于””至少我自己会先这样试”。站旁边说,不站上面说。
L4 内容框架:标题公式、开头模板、叙事模式。比如标题8到12个字要有画面感,开头100字以内进正题。AI的默认倾向是先铺垫再说事,不压着它就会先来三段背景介绍。这层先定结构再动笔,避免写到一半发现框架不对推倒重来。
L5 论据方法:数据怎么找、引用怎么标注、来源怎么归档。
L6 写作流程:从素材到发布的完整pipeline,定义每个阶段该做什么不该做什么。
L7 手工精教:最后一道工序。段落推进有没有断裂、叙述有没有只给结论不给状态、论证有没有停在表层、金句有没有被AI写成”结论宣言”。六个步骤串行执行,一步做完再做下一步。
L8 合规检查:违禁词替代、敏感词、广告合规。发布前最后一道关卡。
这八层不是一次全加载的。写新文章走L1→L4→L5→写初稿→L2→L3→L7→L8。改文章走L2→L3→L7。写标题只用L4。每一层只做一件事,Agent不用同时记住所有规则,处理质量反而比一次性塞一大坨规则强得多。
初稿到大改
初稿的创作方式不固定。有时候我给一个方向,AI自己查证数据、搭结构、出完整稿;有时候综合好几个素材源一起喂给它,让它交叉消化后输出;还有时候我自己口述一版,AI帮我整理、补充论据、深化验证。三种方式出来的质量差别挺大,有时候初稿就很惊艳,有时候看着像两个人写的。
质量波动的原因我现在还在持续探索。是skill的规则没覆盖到这种话题?是prompt给的信息不够?还是输入输出本身就决定了上限?我在过程中不断识别到底是哪个环节影响了稿件质量,然后针对性调整对应的skill层或者prompt策略。这个pipeline本身也在迭代。
看完初稿之后给修改意见。角度不对换一个、这段太长砍掉、这个数据不能暴露、这个例子没发生过不能编。AI根据意见改,有时候来回两三轮。说实话,我不确定有些时候不满意是我自己的偏好问题,还是AI写得其实可以但我的审美没跟上,还是AI的能力(或我的心智不到)确实到不了那个点。目前我还是以自己的主观判断为准,毕竟我没法判断自己能力之外的东西。这是一个开放的方向,我也一直在学习。 这个过程基本是我通过聊天软件语音给 Hermes 反馈搞定。
改完大方向之后我自己上手过最后一遍,改语气、节奏那些微妙的感觉。好在因为八层skill已经把语言层面的常见问题处理得比较干净了,这一步需要动手的地方不算多,占用时间也少。这也是我对整个pipeline比较认可的地方。精修的负担确实在变轻。
发布:离开电脑也能把事办了
前几天把 md2wechat 这个 skill 跑通了之后,有一个变化对我来说特别大:我可以完全离开电脑了。
之前写过一篇文章专门讲这个事。以前写完文章,还得坐在电脑前打开 md.doocs.org、复制渲染结果、登录公众号后台、粘贴、手动上传封面、填摘要,一步一步来。手机上干不了这些事。现在稿子确定之后,skill自动完成标题编写、摘要生成、封面插图、md2wechat排版渲染,图片自动上传微信图床,然后直接推到公众号草稿箱。我在手机上跟 Hermes 聊几句,文章就进草稿箱了,微信公众号 App 审一下点了发布就完事。
这不止是省几分钟排版时间。以前必须坐在电脑前才能完成发布,现在随时随地都行。对我来说这个自由度很重要,毕竟坐在电脑前直接就很累了……
点连成网
今天还把公众号运营数据接进来了。gzh-data 也是以前用 vibe coding 做的系统,几乎快想不起有这个代码了。 跑在本地服务器上,爬取公众号后台的阅读量、点赞、分享、认同互动率这些指标,通过API提供出来。之前这些数据是孤立的,现在接进Hermes,发文后的复盘、历史表现对比、同题材参考,对话里直接调用。
把目前串起来的点放一起看:四源新闻采集、八层写作skill、md2wechat 推草稿、公众号运营数据分析。之前全是单独的点,很难用起来,现在串起来之后创作闭环就闭上了。
有个趋势我很在意:这些点越来越多地由agent来串联。另外我新的vibe coding项目越来越倾向于加CLI接口,主要是方便agent调用。两个趋势叠加,点连成网的速度比预想的快。
整条链路走下来之后,我发现自己的角色变了。
以前写公众号,从选题到发布每一步都得自己来。现在大部分执行环节(新闻采集、数据合并、竞品分析、初稿生成、排版、推草稿)都交给agent了。我做的事情变成了两件:决定做什么不做什么,以及识别哪里出了问题。
做什么不做什么,就是在做方向判断。今天这几个话题里选哪个写、从什么角度切入、写到什么深度停笔。这些判断决定了内容的价值,AI目前做不了这个判断。
识别问题,是过程中不断看:是skill没覆盖到这种话题?是prompt信息不够?还是模型能力上限就在这?找到之后调对应环节,让pipeline往前走。
说白了,人变成了策展人:决定展什么不展什么,在幕后确保整套系统高效运行。听起来像是给agent打工、给agent铺路。确实有点这个意思。
但有件事一直没变:怎么用这套系统创作出有价值的东西。自动化解决的是效率问题,不解决价值问题。一篇稿子从选题到发布可以全自动化,但如果选题本身没判断力、内容本身没观点,自动化的结果只是更快地产出没人看的东西。
至少目前,这东西还是得人扛。
本文由 @jovi_AI电报 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供






- 目前还没评论,等你发挥!


