
 起点课堂会员权益
起点课堂会员权益我让 AI 读了 52 篇论文,这是我学到的关于 Loop 的三件事
当AI遇上神经科学论文,万字解读的自动化革命正在上演。本文揭秘了一个名为Loop的智能协议系统如何通过五步流程、独立评审机制和客观评价标准,将52篇论文的深度解读工作量从104小时压缩至近乎自动化完成。更关键的是,作者用实战案例揭示了哪些任务适合AI自动化,哪些仍需人类创意的不可替代性——这是每个试图用AI重塑工作流的产品人都必须掌握的边界判断。

我手上有 52 篇神经科学经典论文的 PDF。我想把每一篇变成一篇中文深度解读文章——不是摘要,是万字级别的、带概念工具箱、带数据引用、带独立判断的完整解读,输出为自包含的 HTML 文件。
手动做?第一篇花了我 2 小时,第二篇还是 2 小时。52 篇就是 104 小时,不现实。
让 AI 做?一个 prompt 搞不定。这个任务有五步:读 PDF 全文、规划文章结构、撰写内容、组装 HTML、检查质量。每一步都依赖前一步的结果,而且”检查质量”这件事不能跳过——AI 写的东西质量波动很大,你不检查就不知道它漏了什么。
所以我写了一个协议(Protocol):告诉 AI 对每篇论文执行这五步,做完一篇检查一篇,不过关就修改,改完再检查,过了就下一篇。
这就是 Loop——不是跑一次祈祷结果好,而是跑完就检查、不行就重来。
Loop 的核心不是”循环”这个动作,而是退出条件:什么情况下算”够好了,可以下一篇”?没有退出条件的循环只是死循环。(当然不是说死循环没有价值,现在死循环有死循环的价值
一个 Loop 长什么样
跑了三个 Loop 之后(两个成功,一个失败),我发现一个能跑起来的 Loop 由五个部分组成:
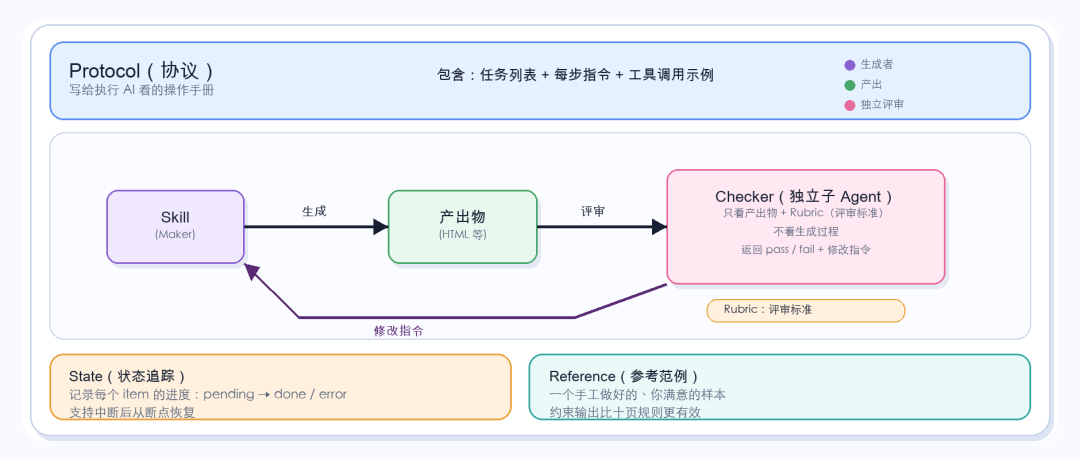
Protocol是写给”没见过这个项目的 AI”看的操作手册。不是给你自己的备忘录——路径要写绝对路径,工具调用要给示例代码,恢复逻辑要显式写明。判断标准:如果你把这个文件发给一个完全不了解项目背景的朋友,他能不能照着跑起来?
- Skill(Maker)是执行任务的指令模板。在我的例子里是论文解读 Skill,定义了五个阶段的写作流程和 HTML 模板。Skill 的质量直接决定首轮通过率——Skill 写得好,Checker 几乎没事做。
- Checker是独立的评审 Agent,后面会详细讲为什么”独立”这两个字是关键。
- State是一个 JSON 文件,追踪每个 item 的状态。它的作用不只是记录进度,更重要的是让 Loop 可以中断和恢复——任何 AI 读到这个文件,都知道从哪里继续。
- Reference是一个你手工做好的范例。它的约束力比规则强得多:规则说”概念工具箱要用人话解释术语”,范例直接告诉你”人话”长什么样。
这五个部分里,最重要的是 Rubric(评审标准)。
Protocol 怎么写、State 用什么格式、Checker 怎么调用——这些都是工程问题,花点时间就能搞定。但 Rubric 不一样:它决定了”什么算好”。Rubric 清晰,Loop 就顺利;Rubric 模糊,Loop 就是在原地打转。
我的论文解读 Loop 之所以 94% 首轮通过,不是因为 Protocol 写得多细,而是因为 8 条 Rubric 每一条都可以客观判定——”术语有没有中文翻译”不需要主观判断,”HTML 结构是不是 .page > .layout > .main-content”看一眼 DOM 就知道。而我的微世界 Loop 失败,本质上是因为写不出好的 Rubric——”这个预测问题是否能触发认知冲突”无法客观判定。
所以设计 Loop 的第一步不是写 Protocol,而是写 Rubric。如果你能列出 5-10 条可以被一个陌生人(或陌生 AI)客观判定 pass/fail 的标准,这个任务就适合 Loop。如果你列不出来,先别急着搭 Loop——先搞清楚你到底要什么。
接下来的三件事,就是我在围绕 Rubric 搭这个结构时踩过的坑。
第一件事:你的 Checker 可能是假的
设计 Loop 的第一个决定是:谁来检查?
最直觉的做法是让做事的 AI 自己检查自己的输出。很多教程也是这么教的:在 prompt 里加一句”现在忘掉你刚才写的内容,以一个严格评审员的身份重新审查这篇文章”。
我最初就是这么做的。结果发现一个问题:它几乎从不给自己打 fail。
原因很简单——它知道自己的意图。当它看到一个段落写得含糊时,它能”脑补”出自己想说什么,然后判定”虽然写得不够清楚,但意思到了”。它不是在评审一篇陌生的文章,它是在回忆自己几秒钟前的思考过程。
这就像让一个学生批改自己的考卷——他知道自己想写什么,所以总觉得自己写对了。
修复方法:用一个全新的、独立的 AI 实例来做 Checker。在 Claude 里,这意味着用 Agent 工具生成一个子 Agent——它有自己独立的上下文,完全没见过主 Agent 的生成过程。给它的只有两样东西:
1. 生成好的 HTML 文件
2. 八条评审标准(能不能独立理解、数据是否精确、术语是否有中文翻译、HTML 结构是否正确……)
它不知道这篇文章是怎么写出来的,不知道作者”想表达什么”,它只看到成品。这才是真正的评审。
独立上下文不是优化,是正确性要求。告诉同一个 Agent “假装忘记”不等于它真的忘了——上下文还在那里,它的判断必然受污染。这个错误在几乎所有 Loop 教程里都存在,但很少有人点破。
第二件事:Checker 拦住的不是”烂”,是”盲点”
协议写好,跑起来。52 篇论文全部完成后,我回头看数据:
- 49 篇:在第一轮就通过了全部 8 条评审标准(pass 8/8)
- 3 篇:在第一轮被 Checker 打回,第二轮修改后通过
被打回的 3 篇分别是什么问题?
- Bliss & Lømo (1973),LTP 论文:概念工具箱里漏了 CaMKII(钙调蛋白依赖性激酶 II)的解释
- Warrington & Shallice (1969),短时记忆论文:漏了 WAIS(韦氏成人智力量表)的中文翻译和全称
- Felleman & Van Essen (1991),皮层层级论文:漏了 RGC(视网膜神经节细胞)等缩写的解释
三个全是同一类问题:特定专业术语没有解释全。
这说明什么?
第一,Maker(生成器)本身已经够好了。94% 的首轮通过率意味着论文解读的 Skill(指令模板)写得足够详细,AI 不需要反复修改就能产出合格的文章。如果你的 Checker 每次都拦住大量问题,说明你的 Maker 需要重写——不是多跑几轮能解决的。
第二,Checker 的真正价值是抓系统性遗漏。这三次 fail 都不是”文章写得烂”,而是在某个具体知识点上有盲区。这种盲区靠主 Agent 自检是发现不了的——因为它如果知道 CaMKII 需要解释,当初就会写进去。只有一个”不知道作者意图”的独立 Checker,才会客观地发现”这里出现了一个没解释的缩写”。
第三,Checker 的成本是可控的。3/52 = 5.8% 的重审率意味着 Checker 子 Agent 平均每 17 篇才需要多花一轮的 token。这比”不检查直接发布然后人工返工”便宜得多。
第三件事:有些任务不该 Loop 化
同一批 52 篇论文,我还尝试过另一个 Loop:给每篇论文生成一个”交互式微世界”——不是让读者读文章,而是让读者亲自体验论文的论证过程。比如 FFA 论文,做成一个淘汰赛游戏:给你看脸和物体的 fMRI 数据,让你预测结果,逐步排除替代假说。
我设计了完整的协议:5 种交互模式(淘汰赛、双重分离、证据累积、模拟体验、概念构建)、7 条 Checker 标准、详细的 HTML 组件规范。从协议设计的角度看,它比论文解读的 Loop 还完善。
AI 跑出了第一个产出。我看了一眼,直接否掉了整个 Loop。
不是因为产出有 bug,而是因为它不是我想要的东西。交互体验的设计空间太大了——同一篇论文可以做成 100 种完全不同的交互方式,每一种都”符合协议”,但大多数都不是好的学习体验。协议能约束格式(必须有预测点、必须有计分板、必须有自测题),但约束不住创意(什么样的预测问题能真正触发认知冲突?什么样的交互节奏能让人”啊哈”?)。
这就是 Loop 的适用边界:Loop 能工作的前提是,输出空间小到 Checker 能覆盖。
论文解读的输出空间很大,但被 Skill 的 10 个固定章节 + 8 条 Checker 标准压缩到了可管理的范围。代码的输出空间更大,但被测试用例压缩到了”通过/不通过”。而”设计一个学习体验”的输出空间几乎是无限的——你可以检查它是否有预测点,但你无法检查这个预测点是否”问得好”。
如果你的 Checker 只能检查格式不能检查内容质量,那这个任务可能不适合 Loop。先手工做一个满意的范例,确认你能说清楚”好”长什么样,再决定是否 Loop 化。
最后
Loop 不难,难的是知道什么时候该用、什么时候不该用。
52 篇论文解读告诉我:如果任务结构清晰、退出条件可检查、有参考范例,Loop 的效果出奇的好——94% 首轮通过,剩下 6% 也在第二轮解决。总耗时从预估的 104 小时变成了”写协议 2 小时 + 跑完等结果”。
但交互式微世界告诉我:如果任务本质上是创意性的,输出好坏取决于品味而非标准,那再完善的协议也救不了你。这时候正确的做法不是设计更复杂的 Loop,而是承认这个任务需要人来做。
回过头看,Loop 其实不是什么 AI 时代的新发明。写 Protocol 就是写 SOP(标准作业程序),写 Rubric 就是写验收标准,Checker 就是质检,State 就是工单系统——这些东西在制造业和软件工程里存在了几十年。变的只是执行者从人换成了 AI,以及因此带来的一个新问题:怎么让一个没有常识兜底的执行者在无人值守的情况下保持质量。所有关于 Loop 的技巧,归根到底都在回答这一个问题。
知道边界在哪,比知道怎么写 Loop 更重要。
本文由 @yan 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务









厉害 第一次知道能这样去快速解读论文,如果后面要写论文会方便得多,那哪个ai执行loop会更好呢?