
 起点课堂会员权益
起点课堂会员权益从语义快照到结构化诊断:三层判定模型与模式匹配机制
面对AI产品界面中的语义断层问题,结构化诊断方法(Semantic Pipeline)提供了一套工程化解决方案。本文详解三层递进诊断模型:从组件语义分类到漂移模式匹配,再到视觉表达校验,形成完整的诊断数据链,最终输出可直接进入契约工作台的标准化报告,实现从发现问题到修复执行的无缝衔接。

上一篇《组件语义快照:我观察 AI 产品界面时用的 6 字段记录法》建立了发现问题阶段的观察层——用 6 个字段把界面观察标准化为机器可读的快照。但记录本身不产生诊断。当积累了数十条甚至上百条快照后,如何判断其中存在语义断层?如何归类、归因、并输出可直接进入下游的修复指令?
本文提出”结构化诊断”(Semantic Pipeline)作为阶段一的工程化落地层。它不是一套主观判断,而是一套有输入、有步骤、有输出的诊断流程:把 6 字段快照转化为可归类的诊断路径,最终输出可直接进入阶段二契约工作台的标准化诊断报告。
一、发现问题阶段的工程化架构:观察层和诊断层
“组件语义快照与模式诊断“不是单一工具,而是两层工程化架构:

为什么必须分成两层?
在实际工程中,观察者和诊断者往往是不同角色。设计师负责走查并记录快照,但诊断需要同时理解”设计意图“和”语义模式“,通常由设计系统负责人或体验架构师完成。如果让记录者边观察边判断,标准会漂移:今天觉得”红色按钮”是问题,明天觉得不是,取决于记录者当天的主观判断。
分层设计让观察可以并行(多人同时记录不同产品),诊断可以集中(统一标准判定),避免标准漂移。
二、结构化诊断的设计方案:三层判定
2.1 设计目标
结构化诊断面临三个现实问题,也是三个设计目标:
- 可归类:两条快照都显示”红色按钮”,一条是错误状态,一条是删除操作,本质问题不同。诊断结果必须能归入已知的语义断层类型,而不是每次重新描述。
- 可归因:发现”文案用词不一致”,是设计规范缺失、AI 生成随机性、还是前端实现错误?不同归因对应不同修复方。诊断必须能定位到”缺少什么语义规则”。
- 可产出:诊断完成后,应该输出一份设计规范修订、一段 AI 指令前缀、还是一个组件库变更?没有标准,诊断结果无法流转到下游。
2.2 为什么设计为三层递进
经过对 50+ 条快照的试点诊断,我发现语义断层的判定存在天然的递进关系:
- 先定类型:不知道组件类型,就无法判断语义问题是否属于已知模式。”红色按钮”在错误状态中是”后果差异未分级”,在操作控件中是”高危操作风险未约束”——修复方完全不同。
- 再定模式:知道类型后,才能在对应模式子集中匹配,避免误判。如果跳过类型直接匹配,”红色”会同时命中错误状态和高危操作两个模式。
- 最后定表现:知道模式后,才能具体判定当前视觉层缺失什么、应该补什么。如果跳过模式直接校验视觉,会出现”改了颜色但没改文案”的修复遗漏。
三层的递进关系是:第一层缩小范围,第二层定位本质,第三层指导修复。 跳过任何一层,诊断都会失焦或遗漏。
2.3 与6字段记录法的衔接设计
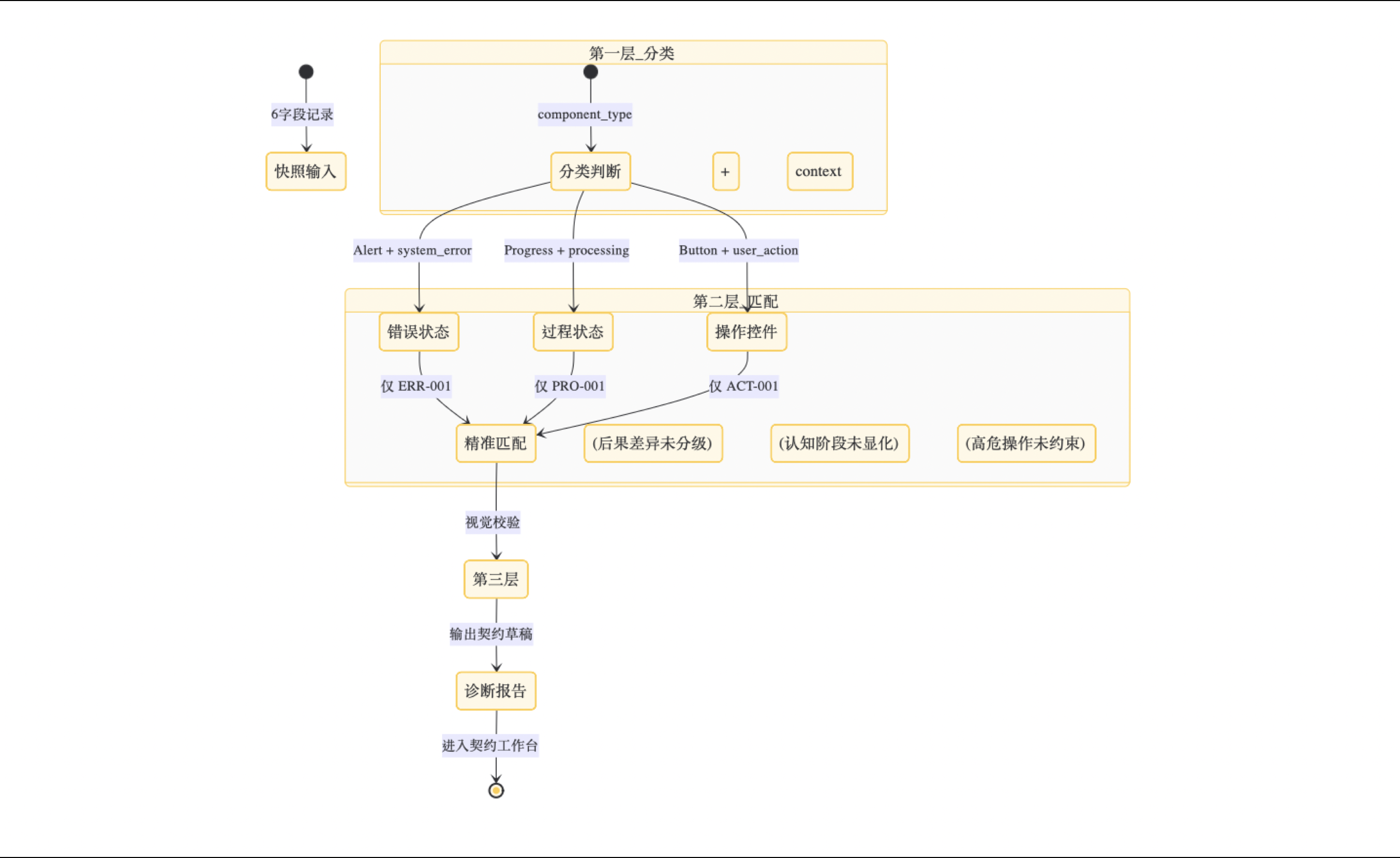
三层判定模型的输入完全依赖 6 字段快照。每个层级的判定逻辑都直接消费6字段中的特定字段:

这意味着:只要记录规范,第一层可以自动完成;第二层可以自动推荐匹配结果,人工确认即可;第三层目前需要人工校验,但校验标准已经结构化,未来可以交给机器比对。
三、第一层:组件语义分类 诊断的入口
3.1 设计方案:按交互路径分类,而不是按视觉形态分类
分类体系面临一个选择:按视觉形态(按钮、弹窗、提示条)还是按交互路径(错误状态、过程状态、边界动作)?
我选择了后者。原因是:
- 视觉形态相同,语义功能可能完全不同。一个红色按钮可能是”错误提示”(信息展示),也可能是”删除确认”(高危操作)。按形态分类会导致同一类别内语义问题混杂,修复指令无法精准下发。
- 交互路径决定语义约束。用户遭遇错误时,系统应该提供恢复路径;用户等待过程时,系统应该展示可信度。交互路径直接决定了”应该有什么语义规则”,修复方也自然对应(错误状态归设计系统,操作控件归前端安全规范)。
3.2 分类体系的设计
当前版本包含5个一级类别,基于用户与系统的交互路径:
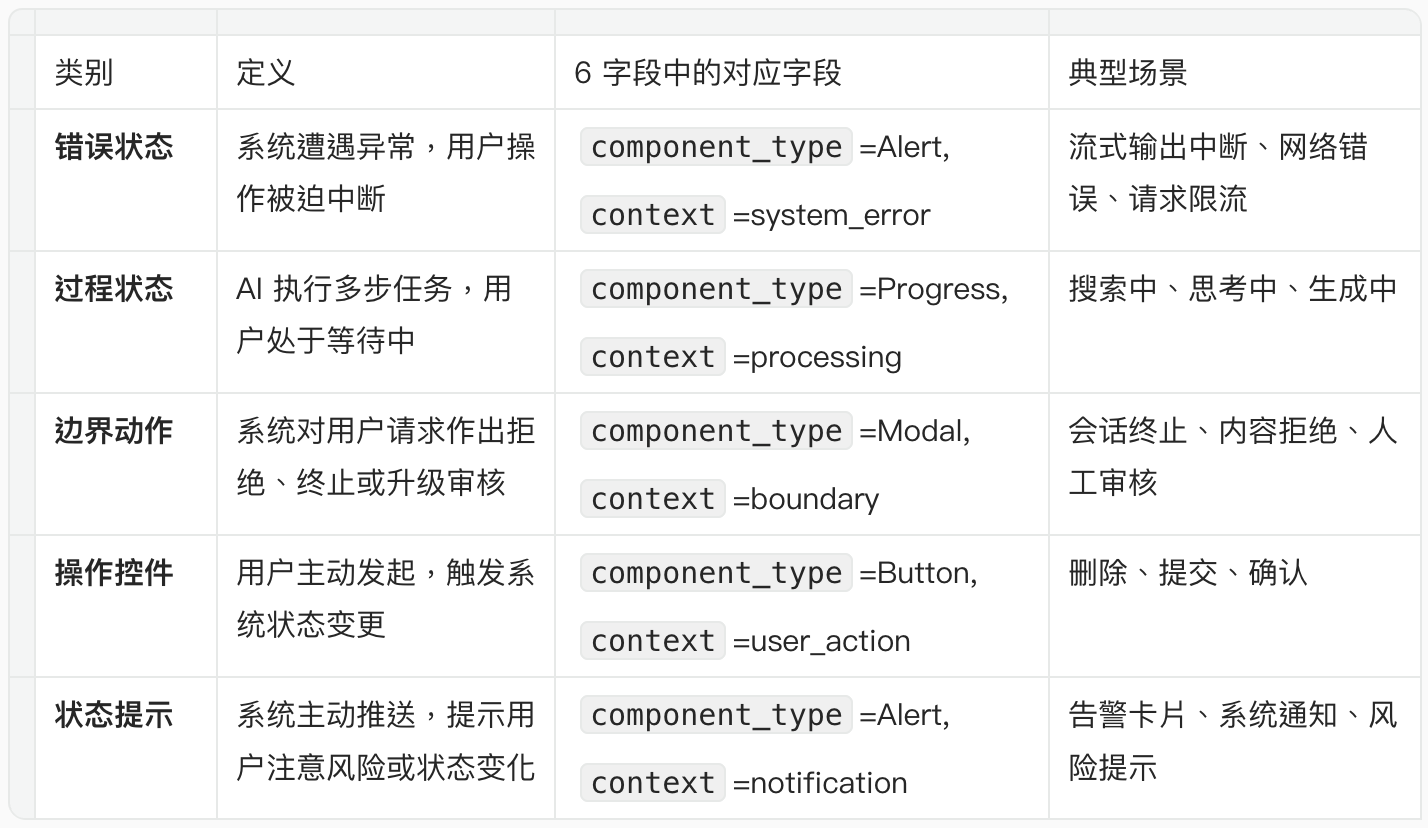
3.3 应用:分类作为诊断的入口,如何缩小模式匹配范围
第一层是诊断的入口层。它的核心作用不是”给快照贴标签”,而是缩小第二层的模式匹配范围。
第一层输出一个分类标签(如 error_state)。这个标签进入第二层时,作为模式候选集筛选器——不是从全部6个模式中匹配,而是只从该类别对应的模式子集中匹配。
分类的自动化程度:第一层可以完全基于6字段中的 component_type 和 context 自动完成,不需要人工判断。只有当两个字段值矛盾(如 component_type=Button 但 context=system_error)时,才需要人工确认。
四、第二层:漂移模式匹配 定位断层本质
4.1 设计方案:为什么用6字段组合规则,而不是关键词匹配或单一特征
模式匹配面临两个选择:用关键词匹配(如文案中包含”错误”就匹配 ERR-001)还是用6 字段组合规则?用单一特征(如”红色”)还是用特征组合?
我选择了6字段组合规则。原因是:
- 单一特征容易产生误判。”红色”本身不是问题,问题是”所有错误都用红色”且”没有区分行动指引”。如果只匹配”红色”,会把正常的单一错误提示也误判为断层。
- 关键词匹配无法捕捉结构性问题。ERR-001 的本质不是”某个错误用了红色”,而是”多种不同后果的错误共用同一种红色,且缺少与后果级别匹配的用户行动”。这需要同时检查 visual.color、context(多个错误场景是否颜色相同)、interaction.actions(是否缺少恢复路径)三个字段的组合。
- 语义断层是结构性问题,不是表面特征问题。只有组合规则才能捕捉”同一产品内多种错误共用同一种视觉语言”这种结构性特征。
4.2 应用:6个漂移模式的规则设计
每个模式包含四个要素:模式ID、所属类别、断层名称、6字段组合规则。
以 ERR-001(后果差异未分级)为例,其组合规则为:
IF component_type = “Alert”
AND context = “system_error”
AND visual.color = “red”
AND COUNT(DISTINCT visual.color BY context) = 1 // 同一产品内所有错误状态颜色相同
AND interaction.actions 缺少 “recovery_path” // 缺少恢复路径指引
THEN 匹配 ERR-001
这个规则的含义是:只有当一个错误状态组件使用了红色,且同一产品内所有错误状态都使用同一种红色,且缺少恢复路径指引时,才判定为”后果差异未分级”。
6个模式的完整规则设计:
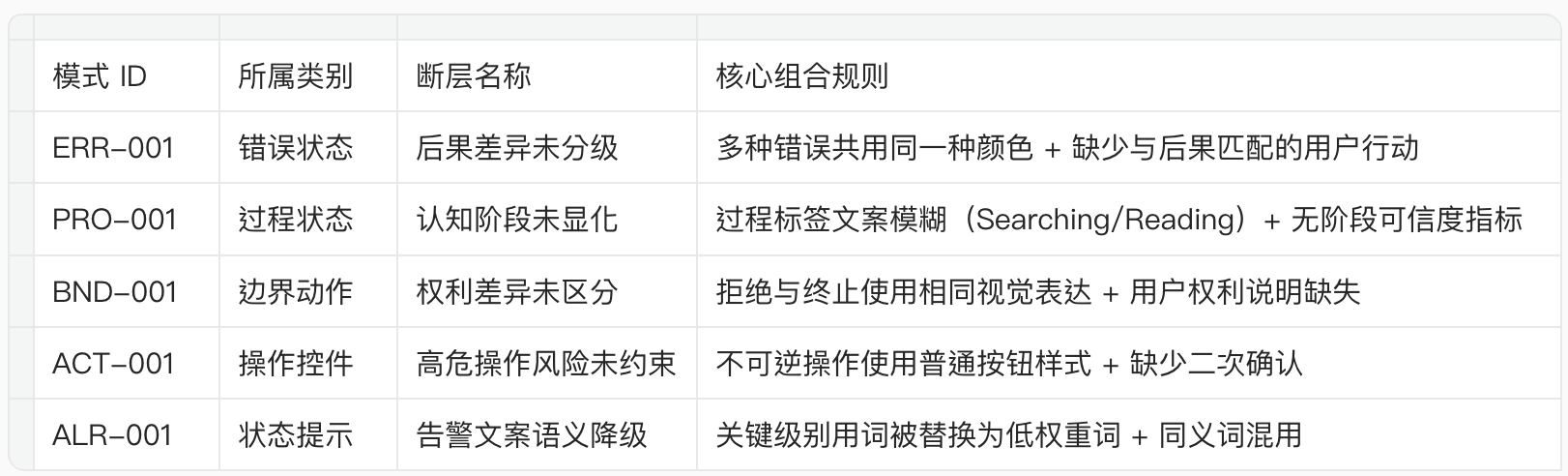
4.3 设计方案:模式库的动态扩展机制
6个模式不是封闭集合。当新的快照无法匹配现有模式时,会触发模式提案流程:
- 记录未匹配的 6 字段特征组合
- 对比同类产品是否存在相同症状(横向验证)
- 提炼断层本质(根因分析)
- 提交新模式提案,包含模式 ID、类别、名称、症状规则、产品证据
- 经审核后纳入模式库,版本号递增
这意味着模式库是可演化的,不是静态清单。当前版本为 v1.0,包含 6 个模式;未来扩展至 10-12 个时,版本号递增,旧版本诊断报告仍可追溯。
五、第三层:视觉表达校验 指导具体修复
5.1 设计方案:为什么需要视觉层校验,而不是停留在模式定位
第二层定位了断层本质(如 ERR-001:后果差异未分级),但还没有回答”具体怎么修”。第三层的设计目标是:把抽象的语义断层转化为具体的界面修改点。
语义断层最终要在视觉层呈现。如果第二层判定为 ERR-001,第三层需要具体回答:
- 当前视觉层如何表现这个问题?(Fatal 错误和 Transient 错误都使用红色背景)
- 语义分级后应该是什么视觉?(Fatal 用红色脉冲,Transient 用灰色加载)
- 当前缺少哪些视觉元素?(缺少恢复路径按钮、缺少倒计时显示)
没有第三层,诊断报告会停留在”问题描述”层面,修复方(设计师、前端、AI 工程师)不知道改什么。
5.2 设计方案:视觉-语义映射表
第三层校验基于视觉-语义映射表。映射表的设计逻辑是:每个语义级别必须对应唯一的视觉表达,且必须包含与该级别匹配的用户行动。
以 ERR-001 的校验为例:
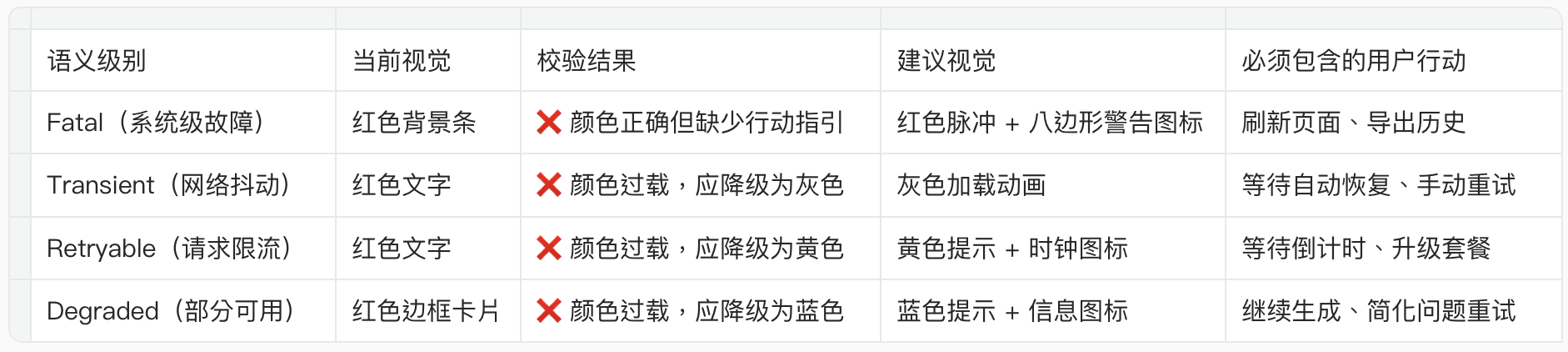
映射表的设计原则是:
- 颜色与后果级别一一对应:Fatal(红)、Transient(灰)、Retryable(黄)、Degraded(蓝)
- 文案必须包含后果说明:用户必须知道”发生了什么”和”该怎么办”
- 交互必须包含行动路径:每个级别必须提供至少一个可执行的用户行动
5.3 应用:校验的产出
第三层输出一份标准化诊断报告,包含:
- 模式 ID 与断层名称
- 6字段快照证据(截图 + 字段值)
- 根因分析(为什么会产生这个断层)
- 视觉表达校验结果(当前 vs 建议)
- 修复优先级(基于用户影响面评估)
- 契约工作台输入项:YAML 契约片段草稿(直接为阶段二准备)
其中,”契约工作台输入项”是第三层最重要的设计。它不是最终契约,而是基于校验结果自动生成的预填充模板,例如:
# 基于 ERR-001 诊断结果生成的契约草稿
intent_id: “ERR-001”
semantic_domain: “observational”
semantic_tokens:
error_severity:
fatal:
description: “系统级故障,对话上下文可能丢失”
visual_mapping:
color_token: “status.critical”
motion_token: “pulse.red.urgent”
user_action:
– label: “刷新页面”
– label: “导出历史”
transient:
description: “网络抖动,系统可自动恢复”
visual_mapping:
color_token: “status.neutral”
motion_token: “spinner”
user_action:
– label: “等待自动恢复”
这段草稿进入阶段二的契约工作台后,设计师可以基于实际业务场景调整字段值,前端可以确认技术可行性,规范管理人员可以评估规范影响面。
六、三层协同:从诊断到契约的完整数据流
三层判定模型不是三个独立步骤,而是一条数据流转链:
6 字段快照 → 第一层分类 → 第二层模式匹配 → 第三层视觉校验 → 诊断报告 → 契约工作台
各层之间的协同关系:

关键设计:诊断报告中的“契约工作台输入项”
这是三层协同的终点。诊断报告不仅告诉团队”问题是什么”,还直接输出一段可编辑的 YAML 契约草稿。这意味着:
- 诊断不是终点,而是契约生成的起点
- 修复方不需要重新理解问题、重新设计规则,直接基于草稿调整
- 缩短从“发现问题”到“锁定规则”的距离,避免二次翻译成本
契约草稿的可编辑性设计
诊断报告中的 YAML 草稿不是最终版本,而是预填充模板。设计师在契约工作台中需要完成:
- 确认语义令牌命名是否符合团队规范
- 调整视觉映射值(如将 status.critical 映射到具体的设计系统 Token)
- 补充业务特定的约束(如某些产品不允许“导出历史”功能)
- 设定不可变边界(哪些规则绝对不能被 AI 突破)
这意味着三层判定模型不负责输出”完美契约”,而是输出“有依据、可验证、可调整”的契约起点。
七、与阶段二的关系:诊断是契约的输入
三层判定模型在整体工作流中的位置:
阶段一:Guard(诊断)
├── 6 字段记录法(观察标准化)
├── 三层判定模型(诊断结构化)
│ ├── 第一层:组件语义分类(缩小范围)
│ ├── 第二层:漂移模式匹配(定位本质)
│ └── 第三层:视觉表达校验(指导修复)
└── 产出:标准化诊断报告(含 YAML 契约草稿)
↓ 输入
阶段二:Contract(契约)
└── 契约工作台(基于诊断报告生成/编辑 YAML 契约)
为什么诊断必须输出契约草稿?
如果没有契约草稿,诊断报告会停留在”问题描述”层面,修复方需要重新理解问题、重新设计规则,产生二次翻译成本。契约草稿把诊断结论直接转化为可执行的规则格式,让阶段二从”编辑”开始,而不是从”空白”开始。
阶段二的核心任务
阶段二《设计师作为”语义翻译者”》将解决:
- 如何把诊断报告中的契约草稿,完善为团队可用的 YAML 契约
- 如何让设计规范像代码一样版本管理(Git + Diff + 回滚)
- 如何把一份 YAML 契约编译为四种消费格式(规则文件本体、AI 指令前缀、走查清单、自动校验规则)
- 真实案例:ERR-001 从诊断到契约的完整过程
八、当前局限与下一步
三层判定模型当前版本存在以下局限:
- 模式库规模:6 个模式覆盖常见场景,但尚未覆盖表单验证、数据可视化、多模态界面等类别。模式库需要持续扩展。
- 自动化程度:第一层分类可基于 6 字段自动完成,但第二层模式匹配目前需要人工审核确认,第三层视觉校验依赖人工截图对比。未来需要引入自动化比对工具。
- 跨产品验证:当前模式主要基于 ChatGPT、文心一言、通义千问、Kimi、豆包、DeepSeek 等对话产品验证,尚未覆盖电商、金融、医疗等垂直领域的 AI 界面。
下一步工作:
- 扩展模式库至 10-12 个,覆盖更多组件类型
- 建立模式贡献流程,接受社区提交的新模式提案
- 开发自动化视觉比对工具,减少第三层的人工校验成本
- 在更多垂直领域产品中验证三层判定模型的适用性
本文由 @阿基拉de_Akir 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









把诊断和契约衔接的思路很实用,很多团队卡在发现问题后不知道怎么传给前端和AI工程师。这段YAML草稿哪怕只是模板,也比纯文字报告省了一半对齐时间。