
 起点课堂会员权益
起点课堂会员权益我为什么开始认真用Codex:从Claude备胎到主力工作台
当单一AI工具的风险日益显现,Codex的独特价值正在被重新定义。它不仅是一个代码生成工具,更是项目执行层的全流程工作台——能够读取文件、修改内容、运行命令并验证结果。本文深度解析Codex如何从备选方案升级为主力工具,以及它与Claude、ChatGPT等工具在真实工作流中的差异化定位。

我开始认真使用 Codex,并不是因为某一次模型发布带来的新鲜感,而是因为工作流里出现了一个现实问题:长期依赖单一 AI 工具,风险正在变高。
过去相当长一段时间里,Claude 是我处理文字和复杂材料时的主力工具。写文章、拆结构、调整表达、整理观点,它确实有很强的舒适区。很多任务一旦形成习惯,后续需求也会自然继续交给同一个工具。
但当一个工具的账号状态、访问稳定性或服务连续性开始让人担心时,使用策略就不能只看体验本身。关于 Claude 的封号和可用性问题,我不打算把个人感受写成行业结论;不同地区、账号和使用方式对应的风险并不相同。这里真正影响工作流的是:如果一个工具随时可能中断,就不适合继续承担唯一主力的角色。
在这个背景下,我开始重新评估 OpenAI 体系里的工具。起初,Codex 只是被我当作 Claude 的备选方案;真正使用一段时间后,它的定位逐渐清晰起来。Codex 并不是另一个聊天模型入口,也不是 ChatGPT 的代码版皮肤。它更像一个面向项目的执行工作台:能读取文件,修改文件,运行命令,观察报错,并继续推进后续修正。
这也是 Codex 值得单独讨论的原因。它不适合所有场景,也不需要承担所有 AI 工具的职责;但只要任务进入“落到文件、运行、验证、交付”的阶段,Codex 的优势会明显放大。
使用背景:从单一依赖到多工具配置
在 AI 工具刚进入日常工作流时,很多人会自然寻找一个“总入口”:写作、代码、资料整理、方案推演,尽量交给同一个模型完成。
长期使用之后,问题会变得更细。写观点文章和修改真实项目,是两类完全不同的工作;解释一个概念和在本地目录里修复报错,也不是同一件事。把这些任务全部交给单一模型,长期会牺牲稳定性和可控性。
我对 Codex 的重新评估,正是从这个变化开始的。Claude 仍然适合长文本和表达推演,ChatGPT 仍然适合作为通用问答入口;Codex 更适合接住那些已经进入执行阶段的任务。它的价值不在于“回答得更漂亮”,而在于把任务从想法推进到可检查的结果。
这也改变了我的判断标准。过去常问哪个模型更强,现在更需要问:它能接触哪些上下文?能不能操作文件、运行验证,并把过程沉淀为可复用规则?
Codex 的核心变化:从给答案,走向读、改、跑、验。
Codex 的定位:项目执行层
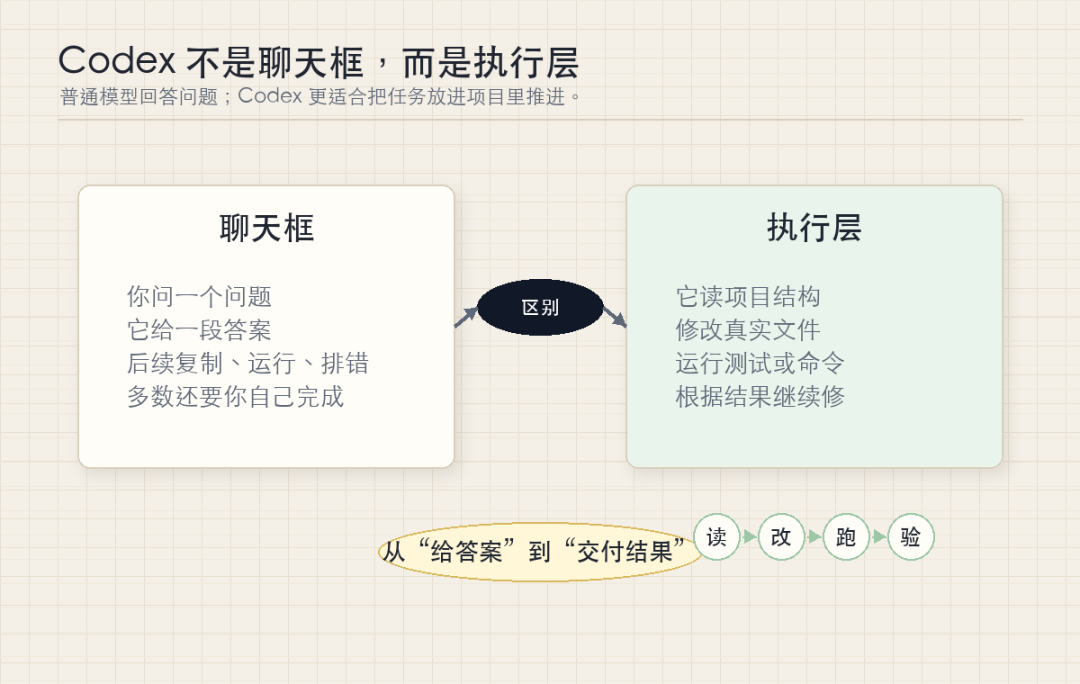
OpenAI 官方把 Codex 定义为面向软件开发的 coding agent。它可以写代码、理解代码库、进行代码审查、调试问题,并自动化部分重复性开发任务。目前 Codex 有桌面 App、CLI、IDE 扩展和 Web/Cloud 等入口。
普通聊天模型通常停留在“给出答案”的层面。用户提出问题,模型输出解释、代码片段或建议;后续复制、保存、运行、检查和修正,主要仍由用户完成。Codex 的路径更接近项目协作:它可以在指定目录中读取上下文,修改真实文件,执行测试或命令,并根据结果继续调整。
因此,在我的工作流里,Codex 更适合被放在执行层。讨论方向、整理观点、润色表达,可以继续使用 Claude 或 ChatGPT;一旦任务变成“修改页面”“生成文章包”“复现并修复报错”“跑完一套本地流程”,Codex 就更适合接手。
这不是模型智商高低的简单比较,而是工具形态的差异。Codex 把对话、文件、命令和验证放在同一条链路里,减少了用户在多个工具之间复制、切换和确认的成本。
给 Codex 任务时,目标、上下文、限制、完成标准缺一不可。
提高 Codex 输出质量的四个输入
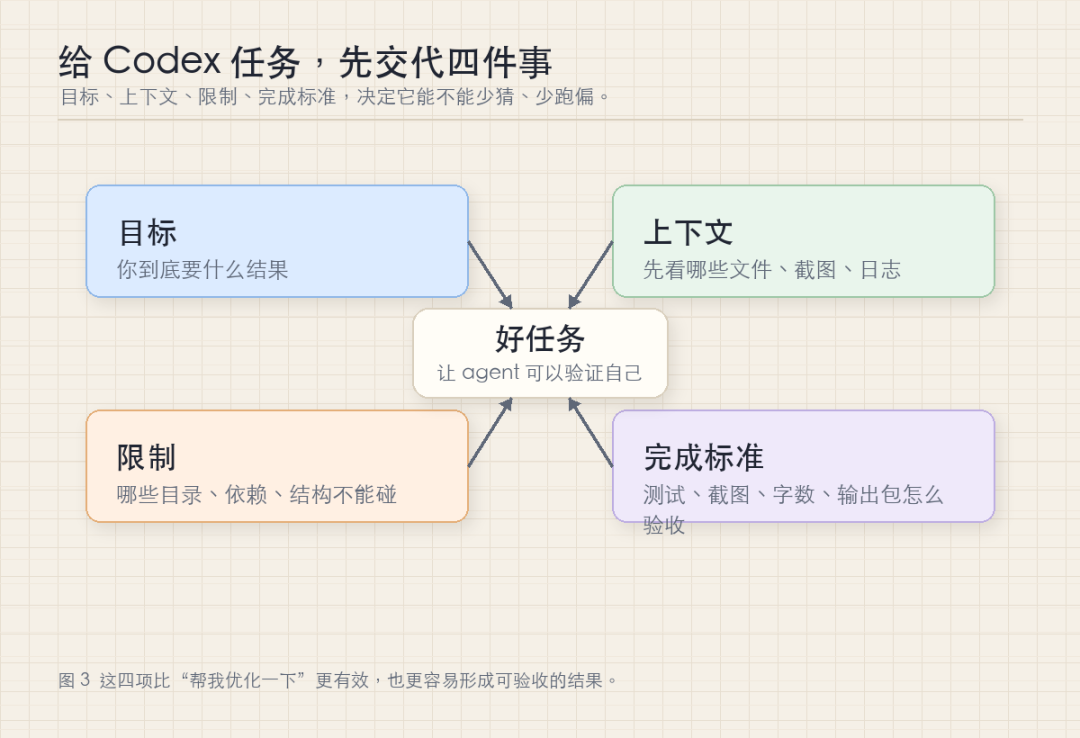
Codex 能直接动手,也就更需要清晰边界。我的经验是,给 Codex 的提示最好包含四类信息。
第一是目标。不要只写“优化一下页面”或“改一下 bug”,而要写清楚最终希望看到什么结果。例如“把这个 React 页面调整到移动端可正常使用”,就比“优化页面”更容易执行。
第二是上下文。真实项目路径、相关文件、参考截图、报错日志、旧版本输出,都应该尽量直接提供。Codex 可以自行搜索,但明确入口能显著减少误判。
第三是限制。是否允许引入新依赖,是否可以改数据库结构,哪些目录不能碰,是否必须沿用现有样式和组件,这些都需要提前说明。agent 一旦开始执行,模糊边界很容易扩大改动范围。
第四是完成标准。测试是否需要通过,截图是否需要检查,文章是否需要控制字数,输出包是否必须包含 README 和图片清单,这些决定了 Codex 能否判断自己是否完成任务。实际使用中,我更倾向于把“完成”的定义写进任务。
ChatGPT 更考验提问质量,Codex 更考验任务定义质量。目标、上下文、限制、完成标准写得越清楚,结果越容易验收。
使用技巧:让 Codex 形成验证链路
复杂任务不要急着让 Codex 直接改。更稳妥的做法,是先让它阅读项目、复述理解,再给出计划。Codex App 的 Plan mode 适合需求还没有完全成形、文件结构又比较复杂的任务。
反复出现的项目规则,应该写进 AGENTS.md。项目如何启动、测试命令是什么、哪些目录不能改,都不应该每次重新解释。一个短而准确的 AGENTS.md,通常比宽泛提示词更有效。
验证步骤要尽量交给 Codex 执行。能跑 lint 就跑 lint,能跑单测就跑单测,能截图检查就截图检查。Codex 的优势并不只是生成内容,而是生成之后还能根据检查结果调整。
大任务也不适合一次性交给它。更好的节奏是分阶段推进:先信息架构,再页面骨架,再关键交互,再视觉调整,最后做测试。任务越大,越需要阶段边界。
本地材料也应该尽量给足。截图、文档、表格、旧代码、参考文章都可以放进工作区。很多偏差并不是模型能力不足,而是上下文不足。
还有一类工作适合沉淀为 Skill,例如文章包生成、PR 评审、发布检查、图片处理、数据报表。一次性提示词很难保证长期稳定,Skill 可以把流程、参考文件和脚本放在一起。真正提高效率的,往往是下一次不必重新解释同一套流程。

长期省时间的不是某一次回答,而是可复用流程。

一个可审查的 Codex 工作台:文件、命令、验证和输出在同一条链路里。
与其他工具的分工
讨论 AI 工具时,很多比较会落到“哪个模型最强”。这个问题并非没有意义,但对日常工作流来说并不充分。模型进入不同产品后,解决的问题会发生变化。
Claude 仍然适合长文本、观点推演和表达润色。尤其在中文写作和复杂材料整理上,它仍然有较好的手感。但我不会再把 Claude 当作唯一工作台,因为它更偏向思考和表达。
Claude Code 与 Codex 的位置更接近。Anthropic 官方将 Claude Code 描述为 agentic coding tool,可以读取代码库、编辑文件、运行命令,并集成到终端、IDE、桌面和浏览器。两者都属于能参与执行的代码代理。区别更多来自生态:如果已经深度依赖 Claude 体系,Claude Code 会更自然;如果希望围绕 OpenAI 账号、Codex App、Skill、插件和 MCP 沉淀流程,Codex 更像长期工作台。
ChatGPT/GPT 更适合作为通用入口。问答、解释、搜索、轻量代码讨论,它仍然非常方便。但一旦进入项目文件改动、命令执行和交付验收,我会把任务切到 Codex。一个负责帮助想清楚,一个负责推动落地。
Hermes 如果指 Nous Research 的 Hermes Agent,它更像长期代理系统。官方页面强调跨平台入口、长期记忆、自动化、子代理和沙箱能力,覆盖 Telegram、Discord、Slack、邮箱、CLI 等表面。它适合多渠道自动化和个人代理场景;Codex 更聚焦本地项目和一次可审查交付。
Qwen Code 的定位则更接近开源 coding agent。官方文档提到 IDE、GitHub Actions、MCP、Memory、Skills、Sub-Agents、Sandbox 等能力;阿里云发布 Qwen3-Coder 时也强调 agentic coding、浏览器使用和工具使用。它的优势在开源、国产生态、成本和模型可替换空间。
豆包和 Seed 系列则更适合中文生态、办公任务、TRAE 工作流和多模态生产力场景。字节 Seed2.1 的官方发布重点包括通用 Agent、代码工程交付、多模态和生产力任务,并已经在豆包产品、TRAE 和火山引擎上线。
所以,我不会把 Codex 写成“全面替代其他工具”的答案。它的优势更具体:在真实项目里,把读文件、改文件、跑命令、查资料、调用工具、验证结果放进一个连续工作流。

选型方法:按任务分配工具
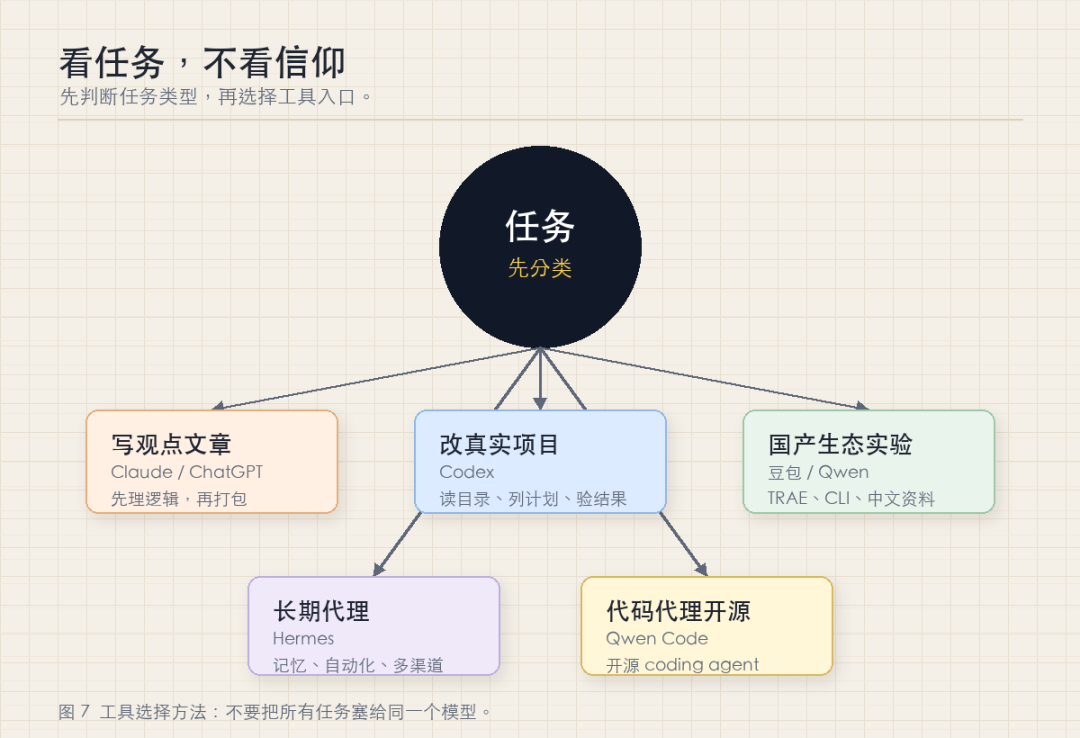
我的工具选择原则很简单:先判断任务类型,再选择入口。
- 如果任务是观点文章、长文本表达或复杂材料消化,我会优先使用 Claude 或 ChatGPT 梳理逻辑,再交给 Codex 处理文件、图片和来源。
- 如果任务是修改真实项目,我会直接使用 Codex,让它先读取目录、给出计划,再分步骤改动和验证。
- 如果任务是开源 coding agent 尝试,Qwen Code 值得关注。
- 如果任务在中文产品生态、办公或 TRAE 工作流中展开,可以关注豆包和 Seed 系列。
如果需要跨平台、长期记忆和自动化的个人代理,可以研究 Hermes。
这不是谁替代谁的问题,而是任务分工问题。聊天模型帮助想清楚,coding agent 负责把任务做下去,国产模型补足成本、访问和中文生态,自动化代理负责长期任务。把所有工作都交给一个工具,反而会降低稳定性。
看任务,不看信仰:不同工具负责不同阶段。
回到 Codex:为什么它值得成为主工作台
我最初把 Codex 视为 Claude 的备选方案,是出于工具可用性的考虑。使用一段时间后,这个定位发生了变化。
对我来说,Codex 的吸引力不是输出一段更漂亮的回答,而是能把任务从想法推进到文件、命令、验证和交付。它让 AI 工具从“对话辅助”进一步靠近“工作流执行”。
如果你已经在同时使用 Claude、ChatGPT、Cursor、Claude Code 或国内模型,我并不建议立刻迁移到某一个阵营。更实际的做法,是挑一个真实任务,把 Codex 放进项目里,让它经历一次读取、修改、运行和验证。
跑过一次完整流程后,很多判断会变得更清楚。AI 工具的差异已经不只在于谁更会回答,而在于谁更能稳定地把事情做完。
资料来源
– OpenAI Codex 官方文档:https://developers.openai.com/codex
– OpenAI Codex Best practices:https://developers.openai.com/codex/learn/best-practices
– OpenAI Codex Prompting:https://developers.openai.com/codex/prompting
– OpenAI Codex App:https://developers.openai.com/codex/app
– OpenAI Codex Skills:https://developers.openai.com/codex/skills
– OpenAI Codex Plugins:https://developers.openai.com/codex/plugins
– OpenAI Codex MCP:https://developers.openai.com/codex/mcp
– Anthropic Claude Code Overview:https://code.claude.com/docs/en/overview
– Nous Research Hermes Agent:https://hermes-agent.nousresearch.com/
– Qwen Code 官方文档:https://qwenlm.github.io/qwen-code-docs/en/users/overview/
– Alibaba Cloud Qwen3-Coder 发布说明:https://www.alibabacloud.com/blog/alibaba-unveils-cutting-edge-ai-coding-model-qwen3-coder_602399
– ByteDance Seed2.1 发布说明:https://seed.bytedance.com/zh/blog/seed2-1-officially-released-advancing-ai-productivity
本文由 @岚天 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









Codex的Plan mode对复杂项目起步很有帮助,但实际用下来,它给出的计划有时会漏掉项目里的隐式约定。这种情况该怎么让Codex更了解潜规则?
关于Codex定位的总结很清晰,但它目前对项目上下文的理解依赖用户手动提供AGENTS.md和明确边界,这个门槛其实不低。很多团队连需求文档都写不清楚,更别说给AI写执行边界了。