
 起点课堂会员权益
起点课堂会员权益Claude Fable 5 重新上线:AI 产品经理该看的不是模型参数,而是能力边界如何被产品化
Anthropic 重新开放 Claude Fable 5 不仅是一次模型恢复,更是 AI 产品设计逻辑的转折点。当大模型能力逼近临界点,产品经理面临的核心挑战已从功能交付转向能力边界管理——如何平衡安全合规与用户体验、如何设计动态权限系统、如何处理误伤与滥用的结构性矛盾。本文将深度解析 AI 产品正在经历的能力开放秩序重构。

2026 年 7 月 1 日,Anthropic 重新开放 Claude Fable 5。表面看,这是一次模型恢复上线:美国出口管制解除,产品重新面向全球用户开放。但如果站在 AI 产品经理视角,这件事真正值得看的不是“某个模型又能用了”,而是一个更底层的问题:当模型能力越来越强,产品经理到底要怎么设计能力边界、风险分流和用户预期?
大模型产品不再只是能力交付,而是“能力+合规+安全边界”的组合交付
越强的 AI 模型,越不能只按功能上线来管理,而要按能力等级、用户类型、国家政策和风险场景来管理。
Anthropic 在 6 月 9 日发布 Fable 5 和 Mythos 5,二者共享同一个底层模型,但开放方式不同。Fable 5 面向更广泛用户,叠加了更强安全机制;Mythos 5 则面向少量可信任的防御性网络安全合作伙伴,部分防护限制更少。三天后,美国政府对这两个模型施加出口管制,要求限制外国国民访问。由于 Anthropic 无法实时验证用户国籍,只能暂停所有用户访问。
这对 AI 产品经理的启发很直接:未来的模型发布,不只是“谁能调用 API、价格是多少、上下文多长”。真正复杂的是,产品要回答“谁能用、能用到什么程度、在哪些场景下要降级、哪些能力要被拦截”。模型能力越接近关键基础设施、网络安全、金融决策、代码自动化这些高风险领域,产品形态就越像一套动态权限系统,而不是一个简单工具。
原文中提到:
Anthropic 因无法实时验证用户国籍,选择先暂停两个模型的访问;Fable 5 恢复全球开放,而 Mythos 5 只恢复给部分美国组织。
安全分类器不是后端细节,而是 AI 产品体验的一部分
AI 产品里的风控模块,最终一定会变成用户体验的一部分,产品经理不能把它只当成算法或安全团队的事情。
这次事件的触发点,是 Amazon 研究人员发现了一种绕过 Fable 5 防护的方法:通过特定提示词让模型识别软件漏洞,其中一次还生成了漏洞利用示例代码。Anthropic 后续测试认为,这个能力并不是 Fable 5 独有,其他较弱模型也能完成类似任务;但 Anthropic 仍然训练了新的安全分类器,用来拦截这个特定绕过方式。
更有意思的是,Anthropic 没有把被拦截的请求简单拒绝,而是路由到 Claude Opus 4.8,并通知用户发生了回退。这是一个非常产品化的处理:高风险模型不直接输出,但用户任务也不至于中断。对 AI 产品经理来说,这里不是一个“拒绝策略”,而是一套“风险分流策略”。
真正要设计的可能包括:哪些请求必须拒绝,哪些可以降级到更保守模型,哪些需要人工审核,哪些需要给用户解释原因。过去产品经理关心的是主链路转化率;在 AI 产品里,还要关心安全分类器的误杀率、降级后的任务完成率、用户是否理解被拦截原因,以及企业客户是否接受这种不可预测性。
原文中提到:
新分类器可以在超过 99% 的情况下拦截报告中的绕过方式;被拦截请求会转交给 Opus 4.8,而不是直接拒绝。
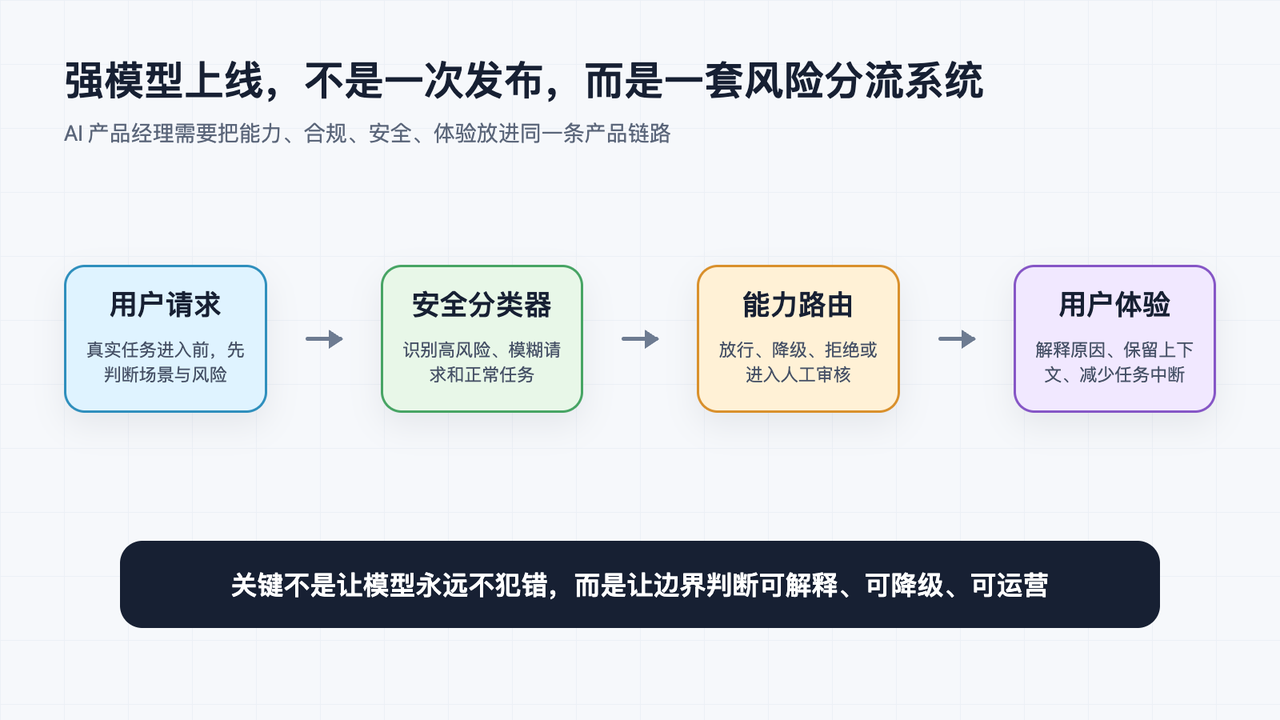
AI 产品的核心矛盾,是“能力开放”和“误伤体验”之间的长期拉扯
越想让模型安全,就越容易牺牲一部分正常用户体验;越想减少误伤,又可能放大滥用空间。
Anthropic 官方说明里用了一个关键概念:安全边际。简单说,分类器不只拦截明确危险的请求,也会拦截一部分“看起来大概率无害、但仍有小概率有害”的请求。Fable 5 的安全边际比以往模型更大,所以它更不容易被滥用,但也更容易误伤正常的代码调试、漏洞排查和防御性安全工作。
这就是 AI 产品经理会越来越频繁遇到的结构性矛盾。用户买一个更强的模型,是为了更少被打断、更强地完成任务;平台上一个更强的模型,却不得不设置更多护栏。这两件事天然冲突。尤其在开发者产品里,一次误判可能会让用户觉得“模型不可靠”;而一次漏判,又可能让平台承担严重安全和合规风险。
所以,AI 产品未来不能只做“能力指标看板”,还要做“边界体验看板”。例如:误杀发生在哪些任务类型?用户是否能提交反馈?降级模型能否保留上下文?企业管理员能否查看被拦截原因?这些问题看起来不性感,但会决定 AI 产品能不能进入真实业务系统。
原文中提到:
Anthropic 承认新分类器会让日常编码和调试中的正常请求更容易被误判,但认为这是开放强模型能力时必须承担的安全代价。
Jailbreak 需要像 Bug 一样分级,安全运营会成为 AI 产品的标配能力
大模型越强,越需要一套类似漏洞管理的安全运营体系,而不是每次靠临时公关和工程补丁救火。
这次事件还暴露了一个行业问题:什么样的 jailbreak 算严重?如果一个提示词绕过了模型防护,但只得到低风险信息,它和一个能稳定生成攻击链的绕过方式,显然不应该被同等对待。Anthropic 因此提出要和 Amazon、Microsoft、Google 等伙伴制定一套 jailbreak 严重性评估框架。
这个框架包括四个维度:能力增益、能力增益的覆盖范围、武器化难度、可发现性。翻译成产品经理熟悉的话,就是看这个问题到底让用户“多获得了多少危险能力”、能不能被大规模复用、执行门槛高不高、是否容易传播。它本质上是在把 AI 安全问题产品运营化、标准化。
对 AI 产品经理来说,这意味着未来的 AI 产品 Roadmap 里,安全不只是合规 checklist,而会变成长期模块:漏洞提交渠道、风险等级定义、响应 SLA、紧急降级策略、客户通知机制、模型回滚机制、红队测试流程。谁能把这些做成稳定系统,谁才有资格把高能力模型交给企业和开发者长期使用。
原文中提到:
Anthropic 提议从能力增益、覆盖范围、武器化难度和可发现性四个维度评估 jailbreak 严重程度,并建立 24/7 监控机制。
开源模型的竞争压力,会倒逼商业模型重新定义价值
当商业模型因为安全和合规限制出现访问波动,开源模型会趁机成为企业的备选甚至主选。
MarkTechPost 在原文中提到,Fable 5 暂停期间,智谱 AI 发布了开源权重模型 GLM-5.2,并在部分独立测试中表现强势。报道还指出,GLM-5.2 在成本上明显更低,在一些任务上的平均花费远低于 Fable 5。这里的重点不是简单比较谁更强,而是商业模型面临的新压力:如果高端闭源模型更贵、更受管制、更容易因为安全策略被打断,企业自然会开始评估开源模型作为替代方案。
这对 AI 产品经理尤其重要。未来企业不会只问“哪个模型效果最好”,而会问一组更现实的问题:哪个模型可持续访问?哪个模型能部署在本地?哪个模型的成本结构更可控?哪个模型的安全策略更适合我的业务?哪个供应商在政策波动时能给出稳定预案?
因此,AI 产品经理做模型选型时,不能只看 benchmark。更实际的模型矩阵应该包括:能力、成本、延迟、上下文、可用性、合规限制、安全策略、可替换性。真正成熟的 AI 产品,不应该把自己绑定在一个模型上,而应该具备模型路由和供应商切换能力。
原文中提到:
报道认为,Fable 5 暂停给竞争对手留下了窗口;GLM-5.2 作为开源权重模型,在成本和部分测试表现上形成了压力。

结语:AI 产品经理要从“功能经理”转向“能力边界经理”
Claude Fable 5 重新上线这件事,给 AI 产品经理一个很清晰的提醒:未来的大模型产品,竞争点不只是能力更强、价格更低、上下文更长。真正难的是,如何把强能力放进一个可控、可解释、可降级、可运营的产品系统里。
模型能力本身会越来越接近商品化,但能力边界的设计不会。谁能把权限、分类器、降级、通知、审计、风险分级、成本路由这些东西做成稳定体验,谁才能把 AI 从“好用的 Demo”推进到“可信赖的生产力系统”。
从这个角度看,Claude Fable 5 的暂停和恢复,不只是 Anthropic 的一次安全事件,也是一堂 AI 产品课:强模型上线以后,产品经理真正要管理的,不是一个按钮,而是一整套能力开放的秩序。
本文由 @怂怂的AI脑内小剧场 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


