
 起点课堂会员权益
起点课堂会员权益财务系统选大模型场景比参数重要:六个核心场景 × 六款主流模型 × 一份选型决策框架
财务系统的AI落地绝非单一场景,而是多个细分场景的精准匹配。从发票识别的多模态能力到现金流预测的数学推理,不同场景对AI模型的要求截然不同。本文深度拆解6大财务场景与主流国产大模型的适配关系,揭示如何用DeepSeek、通义千问等模型组合打造真正可落地的财务AI解决方案。

财务系统不是一个场景,是六七个场景的集合。每个场景对模型能力的要求完全不同——有的要算得准,有的要读得长,有的要调得稳,有的要管得住。拿一个”综合评分最高”的模型去覆盖所有场景,结果往往是每个场景都差口气。
一、先搞清楚,财务系统到底有哪些场景
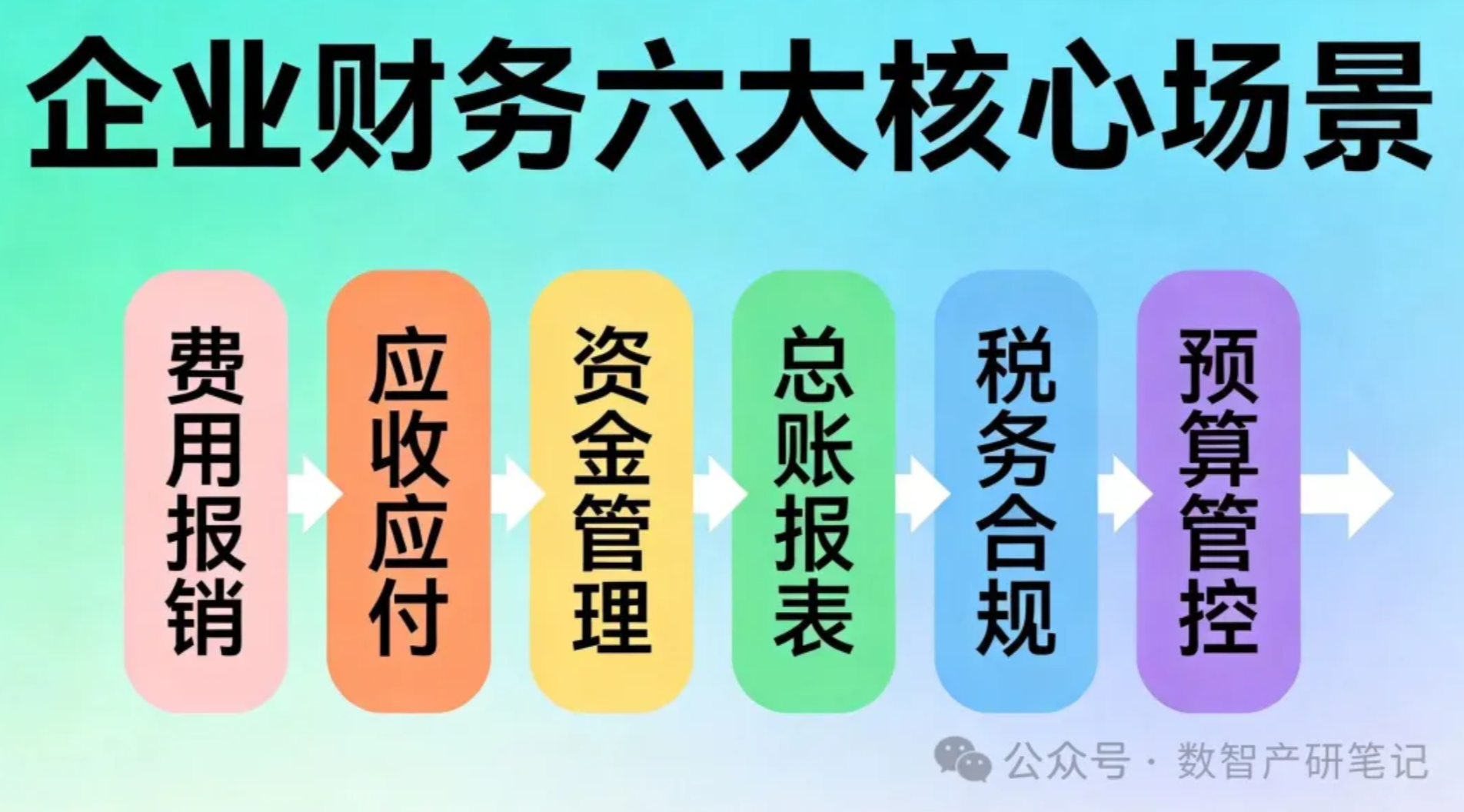
很多人一说”财务系统+AI”,脑子里浮现的就是”智能报销”。实际上财务系统的业务场景远比这复杂,每个场景对AI的能力诉求差异巨大。我把企业财务系统里最需要AI介入的场景梳理成六个:
- 费用审核与报销 — 发票识别、制度匹配、异常标记。核心能力:多模态识别(看发票)+ 规则推理(对制度)。
- 应收应付与三单匹配 — 采购订单、入库单、发票的智能比对和差异处理。核心能力:数据提取 + 逻辑比对。
- 资金管理与现金流预测 — 资金日报生成、现金流预测、头寸调度建议。核心能力:数学推理 + 时序分析。
- 总账与报表分析 — 长财报解析、科目余额异常检测、经营分析报告生成。核心能力:长文本理解 + 结构化输出。
- 税务合规与风控 — 税务风险扫描、合规条款匹配、申报辅助。核心能力:领域知识 + 合规推理。
- 预算管理与经营分析 — 预算编制辅助、执行偏差分析、经营仪表盘解读。核心能力:多数据源整合 + 业务逻辑理解。
看出区别了吗?同样是”财务场景”,费用审核要的是”眼睛好”(多模态识别),资金管理要的是”脑子好”(数学推理),报表分析要的是”记性好”(长文本),税务合规要的是”规矩熟”(领域知识)。一个模型不可能每项都是顶尖。
二、2026年国产大模型,谁擅长什么

在匹配场景之前,先把几款主流国产大模型的核心能力摊开看。截至2026年6月,财务场景用得最多的六款模型,各有各的”杀手锏”:
DeepSeek-V4-Flash — 算账最准的”精算师”
核心参数:284B总参数,13B激活,MoE架构,1M上下文
最强项:数学推理(MATH 84.3分)、代码生成(HumanEval 92.5%),推理效率极高
财务适配点:数据提取准确率在六大模型横评中表现稳定;计算能力突出,毛利率、流动比率等财务指标一次算对;API调用免费,大规模批量处理成本几乎为零
短板:多模态能力偏弱,不擅长直接看发票图片;创意写作和开放性分析略逊
通义千问Qwen3.5 — 看图识字最全能的”多面手”
核心参数:122B总参数,10B激活,原生多模态,1M上下文,Apache 2.0
最强项:多模态理解(图像+文本)、中文语义理解、100+语言支持
财务适配点:能直接”看”发票、合同、银行回单等图片并提取结构化信息;中文财报理解能力强,自动将千元转换为亿元等符合国人习惯的格式;私有化部署友好
短板:纯数学推理略弱于DeepSeek;超长文档处理不如Kimi
智谱GLM-5.2 — 调工具最稳的”执行者”
核心参数:744B总参数,40B激活,MoE+DSA架构,1M上下文,MIT协议
最强项:Agent能力(Function Calling成功率98.5%)、工具调用稳定性、长程工程任务
财务适配点:跨系统操作最可靠——ERP取数、税务系统开票、银行系统查流水,这些需要反复调API的环节,GLM的稳定性是最大优势;企业级权限控制和审计日志完善;已原生支持A2A协议,多Agent协调能力强
短板:多模态能力弱于Qwen;纯文本场景下性价比不如DeepSeek
Kimi-K2.6 — 读长文最强的”档案管理员”
核心参数:~1T总参数,~32B激活,原生多模态Agent,2M上下文(业界最长)
最强项:超长文本处理(2000页PDF一次性通读)、文档理解、跨文档对比
财务适配点:几百页的年报、招股书、审计底稿,一次扔进去就能提取关键数据;多份财报横向对比效率高;API收入增长400%,企业级服务能力在快速提升
短板:计算精度有翻车记录(横评中毛利率计算出错);无私有化部署方案,数据必须上云,涉密场景受限
文心一言5.0 — 合规落地最成熟的”老法师”
核心参数:自研ERNIE架构,金融/能源/制造业私有化部署市场占有率第一
最强项:产业落地能力、工具调用(直接对接金融分析工具和政务系统)、国产化适配
财务适配点:税务合规、审计监管等需要对接官方系统的场景,文心的工具链最成熟;私有化部署经验最丰富,央国企案例最多;幻觉控制能力在横评中表现较好
短板:API定价高于DeepSeek和Qwen;开源生态不如DeepSeek和Qwen活跃
腾讯混元Hunyuan-T1 — 财务分析最细腻的”研究员”
核心参数:自研架构, SuperCLUE第一梯队
最强项:财务比率解释附带风险提示、分析深度好、安全边际评估
财务适配点:在六大模型横评中,混元给出的财务分析最”像分析师写的”——不只算出数字,还会指出潜在风险点和安全边际;适合做经营分析报告和预算偏差解读
短板:品牌知名度和社区生态不如前几家;独立私有化部署方案信息较少
三、场景×模型,精准对号入座
下面进入核心部分。我根据每个场景的能力需求,给出推荐的模型组合和使用建议。注意,我说的是”组合”,不是”唯一解”——实际落地中,一个场景往往需要两个模型配合。
场景一:费用审核与报销
推荐组合:Qwen3.5(主) + DeepSeek(辅)
为什么这么选:费用审核的第一步是”看图”——识别各种格式的发票、收据、行程单。Qwen的原生多模态能力在这里发挥最大价值,能直接读取发票图片并提取金额、日期、税号等结构化字段。第二步是”对规矩”——拿提取出来的数据和公司差旅制度、费用标准做比对,这一步交给DeepSeek的逻辑推理能力更靠谱。
实操建议:先用Qwen做多模态前置处理(OCR+实体抽取),再用DeepSeek做规则匹配和异常标记。连号发票、高频小额、超标住宿这些异常模式,DeepSeek的推理能力比纯规则引擎灵活得多。
场景二:应收应付与三单匹配
推荐组合:GLM-5.2(主) + DeepSeek(辅)
为什么这么选:三单匹配的痛点不是”算”,而是”调”。你需要从ERP拉采购订单、从WMS拉入库单、从税务系统拉发票,三个系统的数据格式不一样、字段名不一样、精度不一样。GLM的Agent能力(Function Calling成功率98.5%)在这种跨系统调度场景下最可靠。等数据都拉齐了,差异比对和容差范围内的自动匹配,交给DeepSeek处理效率最高。
实操建议:给GLM写清楚Function定义——哪个系统取什么字段、返回什么格式。匹配逻辑里设一个容差阈值(比如金额差异≤0.01元自动通过),超出阈值的再走人工。这套”Agent取数+精算匹配”的组合,实测能把三单匹配的人工工作量砍掉70%以上。
场景三:资金管理与现金流预测
推荐组合:DeepSeek-V4-Flash(主) + 混元T1(辅)
为什么这么选:现金流预测本质是数学问题——历史回款周期、应收账款账龄、应付账款到期日、资金头寸余额,这些数据的计算和推演,DeepSeek的数学推理能力是国产模型里最强的。而且它API免费,每天跑资金日报、每周跑现金流预测,调用成本几乎可以忽略。混元的角色是”解读”——算出数字之后,用混元生成带风险提示的分析报告,它在六大模型横评中给出的风险分析最到位。
实操建议:DeepSeek负责”算”(日报、周报、预测数据),混元负责”说”(把数字翻译成管理层能看懂的经营分析)。两者搭配,一个出数据、一个出观点,资金管理报告的质量会有明显提升。
场景四:总账与报表分析
推荐组合:Kimi-K2.6(主) + Qwen3.5(辅)
为什么这么选:月度/年度结账后要做的事——科目余额分析、异常凭证筛查、经营报告撰写——往往需要同时翻阅大量资料。Kimi的2M上下文意味着你可以把整本年报、审计报告、管理层讨论全部扔进去,让它一次性提取关键数据并生成对比分析。Qwen在这里做辅助,主要负责中文报表的格式化输出和图表描述。
实操建议:Kimi适合”读”和”比”,但不要让它”算”——前面提到过,它在计算精度上有翻车记录。涉及具体数字计算的部分(同比增速、结构占比),建议用DeepSeek复核一遍。另外Kimi没有私有化部署方案,涉密财报数据慎用。
场景五:税务合规与风控
推荐组合:文心一言5.0(主) + GLM-5.2(辅)
为什么这么选:税务合规是一个对”可靠性”要求极高的场景——你不可能让AI自由发挥,它必须严格基于税法条文和最新政策来做判断。文心一言在金融、能源行业的合规场景积累最深,工具链可以直接对接税务申报系统,幻觉控制也做得比较好。GLM在这里做”执行”——合规检查通过后,用GLM的Agent能力自动完成申报表的填写和提交。
实操建议:把最新的税收法规、优惠政策、行业特殊规定做成知识库(RAG),让文心基于知识库做合规判断,而不是靠模型本身”记忆”。GLM的Agent负责走完最后一步——填表、提交、留痕。两步分开,既保证了合规准确性,又提升了操作效率。
场景六:预算管理与经营分析
推荐组合:GLM-5.2(主) + 混元T1(辅) + DeepSeek(计算)
为什么这么选:预算管理是财务系统里业务逻辑最复杂的场景——它不只是数字计算,还要理解业务部门的计划、市场假设、历史执行偏差背后的原因。GLM的Agent能力可以串联预算系统、ERP、业务系统的数据,完成”取数→对比→分析→建议”的完整工作流。混元负责把分析结果”翻译”成管理层能直接用的经营洞察,DeepSeek负责中间的偏差计算和趋势推演。
实操建议:这个场景不建议一步到位。先把”预算执行偏差分析”这个单点做透——GLM取数、DeepSeek算偏差、混元写分析——跑顺了再扩展到预算编制辅助。预算涉及的利益方多、敏感度高,AI的角色定位应该是”辅助分析”而不是”自动决策”。
四、落地之前,这三件事没想清楚别动手

选完模型不等于能落地。我见过太多项目,模型选型做得漂漂亮亮,一到落地就卡壳。三个最容易踩的坑:
第一,数据治理先行,别急着接模型
财务系统最大的问题不是”AI不够聪明”,而是”数据太乱”。科目编码不统一、客商主数据重复、组织架构变更后历史数据没清洗——这些问题不解决,再强的模型进来也是一堆垃圾进、一堆垃圾出。我的建议是:先花两周做轻量化数据治理,统一科目体系、清洗客商主数据、确认数据接口规范,再开始接模型。磨刀不误砍柴工。
第二,安全合规是硬约束,不是可选项
财务数据是企业最敏感的数据之一。选模型时必须考虑:能不能私有化部署?数据出不 outbound ?有没有审计日志?哪些模型有等保认证?前面提到的六款模型中,DeepSeek(开源私有化)、GLM(MIT协议私有化)、文心(私有化部署最成熟)在安全合规方面最让人放心。Kimi目前只有云端方案,涉密财务数据不建议用。Qwen和混元需要看具体的企业版部署方案。
第三,多模型编排比单模型能力更重要
前面每个场景我都推荐了”组合”而不是”唯一”,这不是故弄玄虚,而是实际需要。一个财务AI系统,往往需要同时调用多个模型:一个负责”看”(多模态识别),一个负责”算”(数学推理),一个负责”跑”(Agent调度),一个负责”写”(报告生成)。怎么把这些模型串起来、做好路由和容错,是系统工程问题,不是模型选型问题。
我的经验:不要一开始就搞”全场景覆盖”。挑一个高频、痛点明确、容错度相对较高的场景(通常是费用审核或资金日报),用4-6周做出一个MVP,跑通数据流、模型调度、人工复核的完整闭环,拿到业务部门的信任后,再逐步扩展到其他场景。急于求成是财务AI项目最大的敌人。
五、我的几点判断
最后说几个我个人的判断,不一定对,供参考。
1. “场景驱动选型”会成为主流方法论。2026年还在纠结”哪个模型综合评分最高”的企业,到2027年会发现已经落后了。先进入的做法是:先拆场景、再定能力需求、最后选模型。就像你买电脑不会只看一个”综合跑分”,而是看CPU、内存、显卡是否匹配你的使用场景。
2. 国产模型在财务场景的可用度已经过了临界点。不是”能不能用”的问题,而是”怎么用更好”的问题。DeepSeek的数学推理、Qwen的多模态、GLM的Agent调度、Kimi的长文本、文心的合规落地,各有所长。关键是别指望一个打天下。
3. 框架和工程能力比模型本身更影响最终效果。Braintrust今年的报告有一组数据很说明问题:在同一模型上,不同的编排框架对任务成功率的影响是模型切换的7倍[1]。换句话说,你用DeepSeek搭配好的工程框架,效果可能比用GPT-5.5搭配粗糙的框架好得多。对企业来说,投资在工程化能力上的回报率,远高于追逐”最强模型”。
4. 财务AI的终局不是”替代人”,是”人机协同”。每个场景我都提到了”人工复核””人工抽检””人工判断”,这不是保守,是现实。财务数据的特殊性决定了:AI做80%的重复工作,人做20%的判断和兜底,这是当前技术条件下最合理的分工。指望AI全干、人只管签字的企业,大概率会交学费。
技术选型从来不是选最好的,而是选最对的。对的意思,是在对的场景、用对的模型、解决对的问题。财务系统如此,其他系统也如此。
参考来源:
[1] CSDN《DeepSeek、千问、混元、文心、Kimi与智谱,六大国产大模型横评》2026-06-26
[2] CSDN《2026开源大模型深度评测:GLM-5.2、Kimi-K2.6、Qwen3.5》2026-06-26
[3] 网易《2026财务经理AI大模型学习指南》2026-06-29
[4] 实在智能《AI Agent在企业财务共享中心全场景落地指南》2026-06-27
[5] 凤凰网《Kimi估值升至315亿美元,API收入增长400%》2026-06-30
本文由 @数智产研笔记 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议






- 目前还没评论,等你发挥!


