
 起点课堂会员权益
起点课堂会员权益AI文生视频,会在明年迎来“GPT时刻”
最近,一款名为Pika的文生视频AI,引起了许多业内人士的关注和讨论。那么,在Pika等应用背后,AI文生视频这条赛道,已经走到了哪一步?想在AI文生视频领域保持领先,企业需要具备哪些条件?一起来看看本文的分析。

在当下的AI赛道上,AI生文、生图的应用,早已层出不穷,相关的技术,也在不断日新月异。
而与之相比,AI文生视频,却是一个迟迟未被“攻下”的阵地。
抖动、闪现、时长太短,这一系列缺陷,让AI生成的视频只能停留在“图一乐”的层面,很难拿来使用,更不要说提供商业上的赋能。
直到最近,某个爆火的应用,再次燃起了人们对这一赛道的关注。

关于这个叫做Pika的文生视频AI,这些天想必大家已经了解了很多。
因此,这里不再赘述Pika的各种功能、特点,而是单刀直入地探讨一个问题,那就是:
Pika的出现,是否意味着AI文生视频距离人们期望中的理想效果,还有多远?
一、难题与瓶颈
实事求是地说,目前的AI文生视频赛道,难度和价值都很大。
而其中最大的难点,莫过于让画面变得“抽风”的抖动问题。
关于这一点,任何使用过Gen-2 Runway 等文生视频AI的人,都会深有体会。

抖动、闪现,以及不时出现的画面突变,让人们很难获得一个稳定的生成效果。
而这种“鬼畜”现象的背后,其实是帧与帧之间联系不紧密导致的。
具体来说,目前AI生成视频技术,与早期的手绘动画很相似,都是先绘制很多帧静止的图像,之后将这些图像连接起来,并通过一帧帧图像的渐变,实现画面的运动。
但无论是手绘动画还是AI生成的视频,首先都需要确定关键帧。因为关键帧定义了角色或物体在特定时刻的位置和状态。
之后,为了让画面看起来更流畅,人们需要在这些关键帧之间添加一些过渡画面(也称为“过渡帧”或“内插帧”)。
可问题就在于,在生成这些“过渡帧”时,AI生成的几十帧图像,看起来虽然风格差不多,但连起来细节差异却非常大,视频也就容易出现闪烁现象。

这样的缺陷,也成了AI生成视频最大的瓶颈之一。
而背后的根本原因,仍旧是所谓的“泛化”问题导致的。
用大白话说,AI的对视频的学习,依赖于大量的训练数据。如果训练数据中没有涵盖某种特定的过渡效果或动作,AI就很难学会如何在生成视频时应用这些效果。
这种情况,在处理某些复杂场景和动作时,就显得尤为突出。

除了关键帧的问题外,AI生成视频还面临着诸多挑战,而这些挑战,与AI生图这种静态的任务相比,难度根本不在一个层面。
例如:
- 动作的连贯性:为了让视频看起来自然,AI需要理解动作的内在规律,预测物体和角色在时间线上的运动轨迹。
- 长期依赖和短期依赖:在生成视频时,一些变化可能在较长的时间范围内发生(如角色的长期动作),而另一些变化可能在较短的时间范围内发生(如物体的瞬时运动)。
为了解决这些难点,研究人员采用了各种方法,如使用循环神经网络(RNN)、长短时记忆网络(LSTM)和门控循环单元(GRU)来捕捉时间上的依赖关系等等。
但关键在于,目前的AI文生视频,并没有形成像LLM那样统一的,明确的技术范式,关于怎样生成稳定的视频,业界其实都还处于探索阶段。
二、难而正确的事
AI文生视频赛道,难度和价值都很大。
其价值,就在于其能真切地解决很多行业的痛点和需求,而不是像现在的很多“套壳”应用那样,要么锦上添花,要么圈地自萌。
关于这点,可以从“时间”和“空间”两个维度上,对AI文生视频的将来的价值空间做一番审视。
从时间维度上来说,判断一种技术是不是“假风口”、假繁荣,一个最重要的标准,就是看人们对这类技术的未来使用频率。
根据月狐iAPP统计的数据,从2022年Q2到今年6月,在移动互联网的所有类别的APP中,短视频的使用时长占比均高达30%以上,为所有类别中最高。
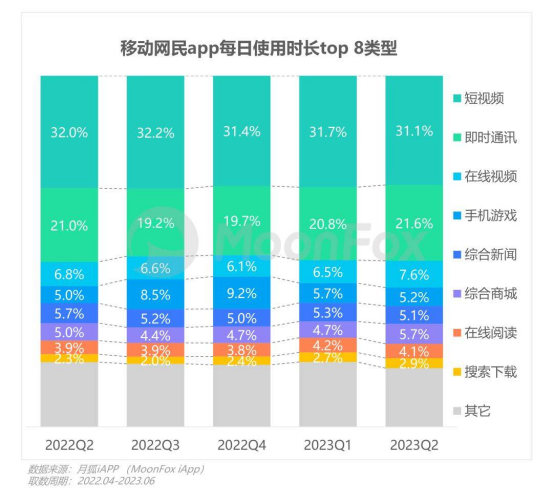
除了时间这一“纵向”维度外,倘若要在空间维度上,考量一种技术的生命力,最关键的指标,就是看其究竟能使多大范围内的群体受益。
因为任何技术想要“活”下来,就必须像生物体那样,不断地传播、扩散自己,并在不同环境中自我调整,从而增加多样性和稳定性。
例如在媒体领域,根据Tubular Labs的《2021年全球视频指数报告》,新闻类别的视频观看量在2020年同比增长了40%。
同样地,在电子商务方面,根据Adobe的一项调查,大约60%的消费者在购物时更愿意观看产品视频,而不是阅读产品描述。
而在医疗领域,根据MarketsandMarkets的报告,全球医学动画市场预计从2020年到2025年将以12.5%的复合年增长率增长。
在金融行业中,HubSpot的一项研究表明,视频内容在转化率方面表现优异。视频内容的转化率比图文内容高出4倍以上。
这样的需求,表明了从时间、空间这两个维度上来说,视频制作领域,都是一个蕴含着巨大增量的“蓄水池”。
然而,要想将这个“蓄水池”的潜力完全释放出来,却并不是一件容易的事。
因为在各个行业中,对于非专业人士来说,学习如何使用复杂的视频制作工具(如Adobe Premiere Pro、Final Cut Pro或DaVinci Resolve)可能非常困难。
而对于专业人士来说,制作视频还是个耗时的过程。他们得从故事板开始,规划整个视频的内容和结构,然后进行拍摄、剪辑、调色等等。
有时候,仅仅一分半的广告视频,就可能耗时一个月之久。
从这个角度来说,打开了AI文生视频这条赛道,就相当于疏通了连接在这个蓄水池管道里的“堵塞物”。
在这之后,暗藏的财富之泉,将喷涌而出,为各个行业带来新的增量与繁荣。
从这样的角度来看,文生视频这条赛道,即使再难,也是正确的,值得的。
三、行业引领者
赛道既已确定,接下来更重要的,就是判断在这样的赛道中,有哪些企业或团队会脱颖而出,成为行业的引领者。
目前,在AI文生视频这条赛道上,除了之前提到的Pika,其他同类企业也动作频繁。

科技巨头Adobe Systems收购了Rephrase.ai,Meta推出了Emu Video,Stability AI发布了Stable Video Diffusion,Runway对RunwayML进行了更新。
而就在昨天,AI视频新秀NeverEnds也推出了最新的2.0版本。

从目前来看,Pika、Emu Video、NeverEnds等应用,已经显示出了不俗的实力,其生成的视频,已大体上能保持稳定,并减少了抖动。
但从长远来看,要想在AI文生视频领域持续保持领先,至少需要具备三个方面的条件:
1)强大的算力
在视频领域,AI对算力的要求,比以往的LLM更甚。
这是因为,视频数据包含的时间维度和空间维度,都要比图片和文字数据更高。同时为了捕捉视频中的时间动态信息,视频模型通常需要具有更复杂的结构。
更复杂的结构,就意味着更多的参数,而更多的参数,则意味着所需的算力倍增。
因此,在将来的AI视频赛道上,算力资源仍旧是一个必须跨过的“硬门槛”。
2)跨领域合作
与图片或文字大模型相比,视频大模型通常涉及更多的领域,综合性更强。
其需要整合多种技术,例如来实现高效的视频分析、生成和处理。包括但不限于:图像识别、目标检测、图像分割、语义理解等。

如果将当前的生成式AI比作一棵树,那么LLM就是树的主干,文生图模型则是主干延伸出的枝叶和花朵,而视频大模型,则是汲取了各个部位(不同类型数据)的养分后,结出的最复杂的果实。
因此,如何通过较强的资源整合能力,进行跨领域的交流、合作,就成了决定团队创新力的关键。
3)技术自主性
诚如之前所说,在目前的文生视频领域,业界并没有形成像LLM那样明确的、统一的技术路线。业界都在往各种方向尝试。
而在一个未确定的技术方向上,如何给予一线的技术人员较大的包容度,让其不断试错,探索,就成了打造团队创新机制的关键。
对于这个问题,最好解决办法,就是让技术人员亲自挂帅,使其具有最大的“技术自主性”。
诚如Pika Labs的创始人Chenlin所说:“如果训练数据集不够好看,模型学到的人物也不会好看,因此最终你需要一个具有艺术审美修养的人,来选择数据集,把控标注的质量。”
在各企业、团队不断竞争,行业新品不断涌现的情况下,文生视频AI的爆发期,就成了一件十分具体的,可以预期的态势。
按照Pika Labs创始人Demi的判断,行业也许会在明年迎来AI视频的“GPT时刻”。
尽管技术的发展,有时并不会以人的意志为转移,但当对一种技术的渴望,成为业界的共识,并使越来越多的资源向其倾斜时,变革的风暴,就终将会到来。
作者:举大名耳
来源公众号:AI新智能(ID:alpAIworks),一个致力于探索人工智能对商业世界和社会影响的平台。
本文由人人都是产品经理合作媒体 @AI新智能 授权发布,未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


