
 起点课堂会员权益
起点课堂会员权益马斯克的Grok-1为什么不采用经典Transformer?
前段时间,马斯克开源了大模型Grok-1的源代码。开源本来是件好事,不过很多人发现Grok-1采用的是Mixture-of-Expert,而不是大家熟悉的Transformer架构。这是为什么呢?本文尝试解答一下此类问题。

2024年3月17日马斯克旗下的xAI公司开源了其大语言模型Grok-1的源代码。Grok-1并未像GPT模型那样,采用AI新贵Transformer,而是用了AI老兵Mixture-of-Expert(混合专家架构)。
经典Transformer架构作为当前自然语言处理领域的一项重要成就,虽然在许多任务上表现出色,但在某些情况下可能存在一些局限性。
Grok-1选择采用混合专家(MoE)架构,源于对未来低成本超大参数模型架构的训练研究和预期,以及对模型性能、效率和灵活性的追求。
在本文中,我们将探讨Grok-1为何不采用经典Transformer架构的原因,以及采用MoE架构的优势和潜在影响。
一、Grok-1详情
1. Grok技术详情
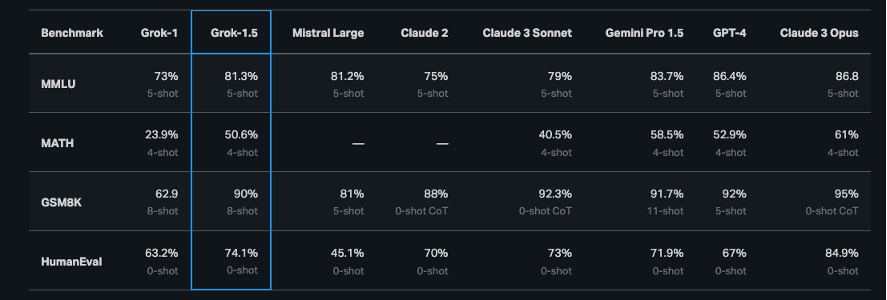
Grok-1和Grok-1.5能力评估表
根据Grok-1公开的技术详情如下:
(1)Parameters:314B。
这表示架构的参数数量为3140亿,即3140亿的训练权重量,是目前发布的大语言模型中参数量最大的一种。
(2)Architecture:Mixture of 8 Experts (MoE)。
这指的是Grok-1采用了专家混合(MoE)架构,其中包含8个专家。MoE是一种架构,通过组合多个专家网络,以便可以选择性地依赖于不同专家的输出。
(3)Experts Utilization:2 experts used per token。
对于每个Token,架构使用了2个专家,这意味着对每个输入Token,架构可以从2个专家的输出中进行选择。
(4)Layers:64。
表示架构由64个神经网络层组成,每一层都包含一组特定的向量矩阵和计算操作。
(5)Attention Heads:48 for queries,8 for keys/values。
说明架构依然采用了自注意力机制,注意力头(Attention Heads)被分为两部分:48个用于查询(queries),8个用于键(keys)和值(values)。帮助架构理解输入序列中的不同部分之间的关系。
(6)Embedding Size:6144。
表示输入Token映射到向量空间的维度大小是6144,即将每个输入Token映射到6144维的向量空间中进行处理。
(7)Tokenization:SentencePiece tokenizer with 131072 tokens。
架构使用SentencePiece的Token生成器,共有131072个Token。Token生成器用于将文本输入拆分为架构可以理解的单词或子词单元。
SentencePiece tokenizer是一种用于分词和标记化文本数据的工具,它可以将文本数据拆分成模型可理解的单词或子词单元。SentencePiece tokenizer可以将文本分割为子词级别,这有助于处理未登录词(Out-Of-Vocabulary,OOV)和稀有单词,提高模型对于复杂语言的适应能力;可以根据数据动态调整词汇量,从而更好地适应不同任务和数据集的需求;其采用内存和时间效率较高的算法,可以快速有效地处理大规模文本数据;可以应用于多种语言的文本处理,帮助跨语言任务的进行。
(8)Additional Features
Rotary embeddings (RoPE):架构使用旋转嵌入作为一种特征表示方法。
RoPE是一种用于神经网络中表示特征的技术,旨在改善对序列数据的处理。
RoPE的设计灵感来自于对旋转变换(rotation transformations)的研究,这种变换可以帮助减少神经网络中的对称性,并提高网络的表示能力。
RoPE的关键思想是将输入特征映射到一个高维球面(high-dimensional sphere)上,并通过在球面上进行旋转操作来引入额外的非线性表示。这种球面上的旋转变换可以帮助网络学习更为复杂和多样化的特征表示,从而提高其性能和泛化能力。
Supports activation sharding and 8-bit quantization:架构支持激活分片(Activation Sharding)和8位量化(8-bit Quantization),这些技术有助于提高模型的效率和性能。其中激活分片是一种优化技术,用于减少内存消耗和加速推断过程。在神经网络中,激活是指在每层网络中经过激活函数后的输出。激活分片将这些激活数据划分成多个片段(shards),每个片段表示神经网络中的一部分激活输出。通过将激活数据分割成片段,模型可以更有效地管理内存,并且可以在多个计算设备上并行处理不同的激活片段,从而提高推断速度和效率。
8位量化(8-bit Quantization)是一种减少模型计算和存储需求的技术,通过将浮点数参数和激活值转换为更小的整数或定点数。8位量化特指将参数或激活值表示为8位(即一个字节)整数。8位量化可以显著减少模型在内存和计算资源上的需求,从而加快推断速度并减少功耗,适用于一些资源受限的场景,如移动设备或边缘计算环境。
(9)Maximum Sequence Length (context):8192 tokens。
架构支持的最大上下文序列长度为8192个Token,这限制了架构能够处理的输入序列的最大长度。
2. 科学计算库
Grok-1采用了JAX作为科学计算库。
JAX(即可加速的Python)是一种用于高性能数值计算和深度学习的开源软件库。它由Google开发,旨在提供NumPy的功能,同时允许用户利用GPU、TPU等加速器进行高效的计算。
JAX的设计理念包括函数式编程、自动微分和XLA编译器等方面的理念,使其成为许多深度学习框架的底层支持,如Flax、Haiku等。JAX不仅支持自动微分,还能将用户编写的Python代码转换成高效的XLA内核,从而提高计算性能。这使得JAX成为深度学习研究和实践中的重要工具之一。
3. 开发语言
Grok-1采用Rust作为编程语言。
Rust是一种由Mozilla开发的系统级编程语言。它被设计为一种安全、并发和实用的编程语言,旨在解决C和C++等语言存在的安全性和内存安全性问题。Rust具有许多特性,包括零成本抽象、模式匹配、类型系统、所有权系统等,这些特性使得编写高性能和安全的软件变得更加容易。Rust还支持并发编程,提供了轻量级的线程和通道机制,使得编写并发程序更加简单和安全。由于其性能和安全性方面的优势,Rust在诸如系统编程、嵌入式开发、网络服务等领域得到了广泛的应用。
Rust是一种注重安全、并发和性能的系统编程语言。它旨在帮助开发者构建高效、可靠的软件,而不牺牲速度或低级控制。这使得Rust在系统编程、网络服务、并发应用、嵌入式设备等领域越来越受欢迎。许多公司和项目已经采用Rust来提高其软件的性能和安全性,包括Mozilla、Dropbox、Cloudflare等。美国政府内部的一些机构和项目开始探索和采用Rust,特别是那些关注软件安全和性能的部门。例如,美国国家安全局(NSA)发布的一份报告中推荐使用内存安全语言,如Rust,来增强软件开发的安全性。
4. 训练架构
MoE—混合专家架构(Mixture-of-Experts)是一种采用人工神经网络的训练架构,最早由Jacobs 等人在1991年的论文《Adaptive Mixtures of Local Experts》中提出。其核心思想是一种将多个局部专家模型组合在一起的方法,以适应不同的输入数据分布,并且这些专家模型可以动态地分配权重。
在MoE中,每个专家模型都被训练来解决特定的子问题,而门控网络则是用来决定在给定输入情况下,哪个专家模型应该负责给出最终的输出。MoE出现时间较早,是为解决算法复杂性、提高训练性能、降低成本而提出的。与Transformer不同,其架构充分利用GPU集群的分布式计算能力,将多任务执行从算法结构层面转移到GPU集群层面从而降低算法的结构复杂性。
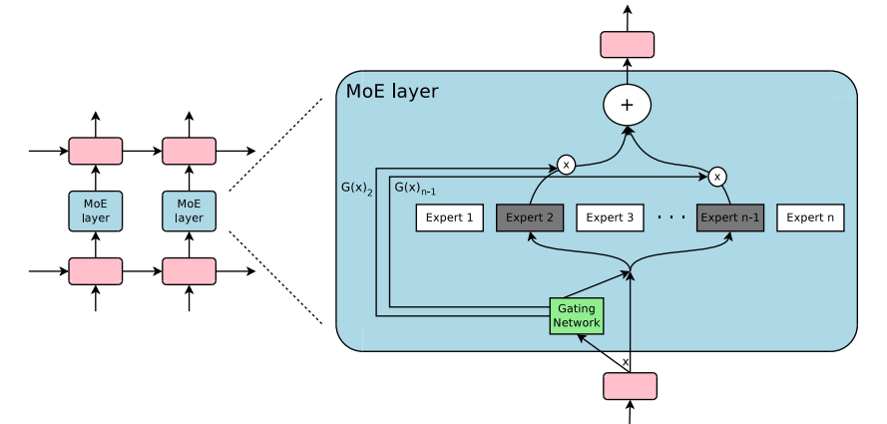
经典MoE示意图
Mixture-of-Experts架构的主要组成部分:
- 专家模型(Expert Models):每个专家模型是一个独立的神经网络,它们被设计用于解决特定的子问题或者在特定的输入数据分布下表现良好。每个专家模型都接收输入数据,并且输出对应的预测结果。
- 门控网络(Gating Network):门控网络用于动态地分配权重给各个专家模型。给定输入数据,门控网络计算每个专家模型对于当前输入数据的相关性或者重要性。这些权重通常是通过softmax函数归一化得到的,以确保它们的总和为1。
- 混合操作(Mixture Operation):通过将每个专家模型的输出与门控网络计算得到的权重相乘并相加,可以得到最终的输出。每个专家模型的输出都被乘以对应的权重,然后再相加,以产生最终的输出。
- 训练策略:MoE架构通常使用端到端的反向传播算法进行训练。在训练过程中,专家模型和门控网络的参数都会被调整,以最小化模型在训练数据上的损失函数。门控网络的训练目标通常是最大化模型的整体性能,并且也可以通过额外的正则化策略来提高模型的泛化能力。
总体上,Mixture-of-Experts架构通过将多个专家模型组合在一起,并且通过门控网络动态地分配权重,可以提高模型的灵活性和适应性,从而在处理复杂的输入数据分布时取得更好的性能表现。MoE架构的专家可以是任何神经网络,例如:多层感知器(MLP)、卷积神经网络(CNN)等。
MoE早在1991年就问世,当时的专家模型主要用知识库和规则引擎。随着NLP各类神经网络算法和架构的演进,MoE架构也随之演进。通过Grok-1的技术详情不难看出Grok在MoE架构中依然结合了Transformer,通过将MoE组件嵌入到Transformer的每个层中,以增强每个层的表达能力。
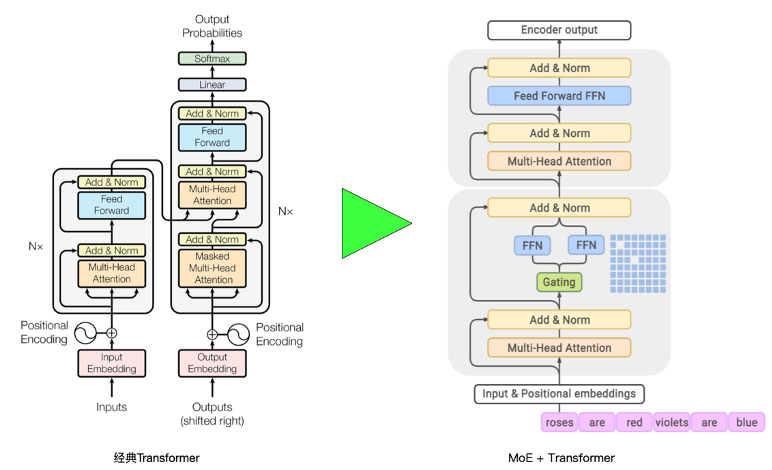
MoE+Transformer混合架构示意图
如右图所示,在每个Transformer层中,可以将输入分成多个子空间,并为每个子空间分配一个MoE组件。这些MoE组件将并行地处理各个子空间的信息,并产生相应的输出。然后,将这些输出组合起来,作为下一层Transformer的输入。这样,每个Transformer层都能够从多个专家的信息中受益,并在整个模型中实现更强大的建模能力。每个MoE层都由作为“专家”的独立前馈神经网络集合组成,由一个门控函数使用softmax激活函数来对这些专家的概率分布进行建模。
每个MoE层(底部块)与Transformer层(上部块)交错。对于每个输入Token,例如“roses”,门控模块从多个专家模型中动态选择两个最相关的专家,这由MoE层中的蓝色网格表示。然后,这两位专家模型输出的加权平均值将被传递到上层Transformer层。对于输入序列中的下一个Token,将选择两个不同的专家系统。
二、为什么不用经典Transformer?
1. 支持超大规模参数和复杂任务
MoE允许在不显著增加计算成本的情况下扩大模型容量。MoE架构通过在处理输入时仅激活与输入相关的专家子集来实现这一点。换句话说,对于每个输入,只有与其相关的一部分专家会被激活,而其他专家则处于非激活状态。
由于只有部分专家被激活,MoE架构实际上只需要处理一部分模型参数,而不是整个模型的参数。这使得模型的参数量得以增加,而实际的计算负载却只增加了少量或不增加。换言之,尽管模型的容量增加了,但由于只有部分参数被激活,因此模型的计算成本并没有显著增加。
这种设计使得MoE架构能够更好地利用参数,以应对更复杂的任务和更大规模的数据,而不会显著增加计算成本。
2. 更好的计算效率和性能
MoE提高了计算效率,因为它可以根据输入动态激活模型的不同部分。这意味着对于每个输入,只有一小部分专家会被计算,从而减少了不必要的计算并提高了处理速度。研究表明,MoE架构在多个任务和基准测试中提供了优于经典Transformer架构的性能。通过合适的专家选择和路由策略,MoE可以提供更丰富的数据表示和更精细的决策能力。
3. 灵活性和专业化考虑
在MoE架构中,每个“专家”都可以学习并专门处理输入空间的不同部分。这意味着在MoE架构中,不同的专家被设计成负责处理输入数据的不同方面或子空间,而不是一概而论地处理整个输入。这种专业化的设计使得模型可以更灵活地适应多样化的数据特征和复杂的任务需求。
例如:假设一个MoE架构用于自然语言处理任务。在这个模型中,可以有一个专家负责处理词义的理解,另一个专家负责处理句法结构的分析,还有另一个专家负责处理上下文信息的推理,等等。每个专家在训练过程中会学习到针对自己负责的那部分输入数据的特定特征和模式,从而使得模型可以更好地理解和利用输入数据的不同方面。
通过这种专业化的设计,MoE架构可以更好地适应多样化的数据特征和复杂的任务需求,从而提高了模型的灵活性和泛化能力。这也是MoE架构在许多任务和基准测试中表现出色的原因之一。
4. 拥有天然的可扩展性和并行
MoE架构的设计允许不同专家在不同的处理单元上独立运行。因为每个专家只处理输入空间的一部分,所以它们之间没有直接的依赖关系。这意味着每个专家可以在独立的处理单元上并行地执行,而无需等待其他专家的结果。这种天然的并行性使得MoE架构可以在并行计算环境中高效地运行。
由于MoE架构可以并行地处理输入数据,因此它在扩展到大型数据集和复杂任务时具有很强的能力。在处理大规模数据集时,可以将数据分配给多个处理单元,每个处理单元负责独立地处理一部分数据。这样不仅可以加快处理速度,还可以有效地利用计算资源。
MoE架构的并行计算性质使得它可以有效地利用计算资源,从而保持高效的资源利用率。通过在多个处理单元上并行地执行专家网络,MoE架构可以充分利用现代计算平台的并行计算能力,实现高效的计算。
5. 节省成本和能耗
MoE架构使用稀疏激活的专家混合架构来扩展模型容量,同时与密集变体相比,训练成本也大大降低。相关研究表明当有1.2万亿个参数MoE训练架构,参数量大约是GPT-3的7倍,但只消耗了训练GPT-3能耗的1/3,并且需要一半的计算触发器来进行推理,同时在29个NLP任务中仍然实现了更好的零次、一次和少次学习性能。
当然,MoE也有一个问题,就是静态内存占用大。尽管使用稀疏门控网络可以降低计算成本,但参数总数会随着专家数量的增加而线性或亚线性增加。增加专家的数量需要保留大量的硬件设备。因此,节省了动态(已使用)功率,而不节省静态(保留)功率。需要节能技术拥有在不使用时硬件设备时,置于低功率状态的能力,这样有助于降低保留能耗。
三、最后
分治原理是贯穿应用数学和计算机科学始终的一个具有广泛适用性的原理。通过将复杂问题分解为更简单的子问题,并通过组合这些子问题的解决方案,我们可以更有效地解决复杂问题。
Grok-1采用Mixture-of-Experts(MoE)架构,也是出于类似的分治原理。
这种架构使得低成本处理超大参数量的大型语言模型(LLM)训练成为可能,通过将模型划分为多个专家,并对每个专家进行独立处理,最终将它们的输出进行组合,从而达到更高效和优雅的算法结构。
这种分治的方法为解决复杂的计算问题提供了一种有效的方式,为未来的研究和应用提供了新的思路和可能性。
参考文献
- Jacobs R A, Jordan M I, Nowlan S J, et al. Adaptive mixtures of local experts[J]. Neural computation, 1991, 3(1): 79-87.
- Jordan M I, Jacobs R A. Hierarchical mixtures of experts and the EM algorithm[J]. Neural computation, 1994, 6(2): 181-214.
- Yuksel S E, Wilson J N, Gader P D. Twenty years of mixture of experts[J]. IEEE transactions on neural networks and learning systems, 2012, 23(8): 1177-1193.
- Eigen D, Ranzato M A, Sutskever I. Learning factored representations in a deep mixture of experts[J]. arXiv preprint arXiv:1312.4314, 2013.
- Masoudnia S, Ebrahimpour R. Mixture of experts: a literature survey[J]. Artificial Intelligence Review, 2014, 42: 275-293.
- Shazeer N, Mirhoseini A, Maziarz K, et al. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer[J]. arXiv preprint arXiv:1701.06538, 2017.
- Riquelme C, Puigcerver J, Mustafa B, et al. Scaling vision with sparse mixture of experts[J]. Advances in Neural Information Processing Systems, 2021, 34: 8583-8595.
- Zhou Y, Lei T, Liu H, et al. Mixture-of-experts with expert choice routing[J]. Advances in Neural Information Processing Systems, 2022, 35: 7103-7114.
- Du N, Huang Y, Dai A M, et al. Glam: Efficient scaling of language models with mixture-of-experts[C]//International Conference on Machine Learning. PMLR, 2022: 5547-5569.
- Rajbhandari S, Li C, Yao Z, et al. Deepspeed-moe: Advancing mixture-of-experts inference and training to power next-generation ai scale[C]//International conference on machine learning. PMLR, 2022: 18332-18346.
专栏作家
黄锐,人人都是产品经理专栏作家。高级系统架构设计师、资深产品经理、多家大型互联网公司顾问,金融机构、高校客座研究员。主要关注新零售、工业互联网、金融科技和区块链行业应用版块,擅长产品或系统整体性设计和规划。
本文原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


