
 起点课堂会员权益
起点课堂会员权益不止于DAU:AI产品经理如何洞察运营数据的独特维度
当通用指标失效,AI产品的真实健康度该如何衡量?本文从能力有效性、用户体验与交互深度、价值创造与业务影响三大核心维度,为你解析AI产品的多维数据视角,构建系统化的数据指标体系。

当通用指标失效时,我们该如何衡量AI产品的真实健康度?
一、为什么通用数据指标在AI产品面前“失灵”?
做产品有些年头了,DAU/MAU、留存率、转化率这些词,简直是刻在骨子里的信仰。每天早上到公司的第一件事,就是打开数据看板,看看昨天的曲线是红是绿。这些指标就像产品的脉搏,告诉我们它“活得”怎么样。对于电商、社交这类产品,这套逻辑跑得很顺。用户来了,逛了,买了,或者跟朋友互动了,这些行为本身就构成了产品的核心价值。
可到了AI产品这儿,我发现这套玩法好像有点不对劲了。我见过一个做智能文档分析的团队,他们把DAU做得特别漂亮,用户每天都来。老板很高兴,觉得产品成功了。可我跟几个深度用户聊了聊,发现他们每天来,是因为AI分析的结果总有错,他们不得不花大量时间来手动校对。用户是来了,可他们来是“擦屁股”的,而不是来享受价值的。你说,这个DAU还能真实反映产品的健康度吗?
这就是AI产品和传统产品的根本区别。传统产品的价值在于“连接”和“平台”,用户在上面花时间,本身就是一种成功。AI产品的核心价值,在于它能不能解决一个具体的问题,以及解决得好不好。用户用AI写代码,不是为了跟AI聊天,是为了更快地写出代码。用户用AI画图,是为了得到一张满意的图片,而不是为了体验生成过程的酷炫。
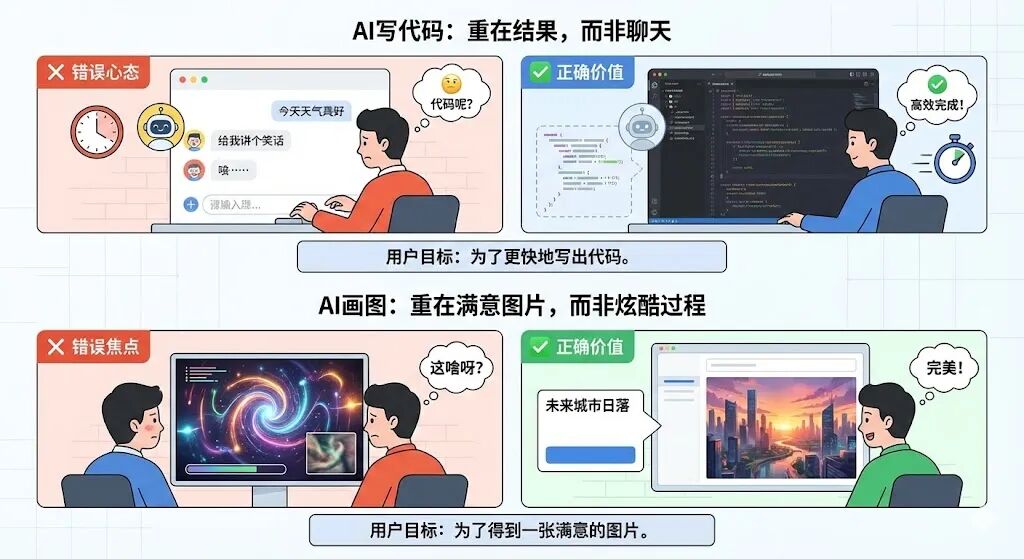
所以你看,当一个用户打开AI产品,问了一个问题,AI没答上来,用户关掉了。在传统数据后台,这可能被记为一次“有效访问”,DAU加一,停留时长三十秒。可对AI产品来说,这是一次彻头彻尾的失败。用户带着问题来,带着失望走。这样的DAU越高,产品的“虚假繁荣”就越严重,我们离用户的真实需求就越远。
说白了,通用数据指标衡量的是用户“来了没有”,而AI产品更需要衡量的是AI“行不行”。这个“行不行”,不是一个简单的“是”或“否”,它是一个复杂的、多维度的概念。它不仅关乎AI本身的技术能力,还关乎它与用户交互的体验,最终更要落到它为用户、为业务创造了什么实实在在的价值。我们需要一套新的尺子,一套更精细、更贴合AI本质的数据视角,去度量这些看不见的东西。这,就是我们今天要聊的话题。
二、核心维度一:能力有效性——衡量AI的“智商”与“靠谱度”
聊AI产品,绕不开的第一个问题就是,这个AI到底聪不聪明,靠不靠谱。这就是我说的“能力有效性”,你可以把它理解成AI的“智商”。这跟传统产品完全不一样,我们不是在评估一个按钮的点击率,而是在直接评估一个“大脑”的工作质量。这是AI产品的根基,根基不稳,上面的楼阁盖得再漂亮也没用。
下面这些指标,就是我们用来给AI“体检”,看它智商和靠谱度在哪个水平的常用工具。
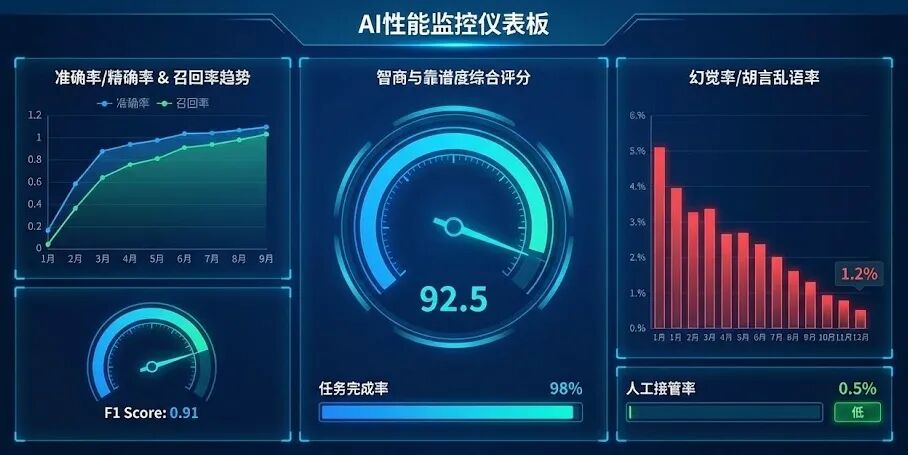
准确率/精确率(Accuracy/Precision)
这两个词听起来很像,但意思不一样。简单说,准确率是“你判断对的占了全部的多少”,而精确率是“你认为是好东西的里面,到底有多少是真的好东西”。举个例子,一个AI邮件分类器,把100封邮件分成了“垃圾邮件”和“正常邮件”。它把10封邮件标为垃圾邮件,其中8封确实是,2封是误判。那它的精确率就是80%。这个指标在那些“宁可错放,不可错杀”的场景里特别重要。比如,你肯定不希望重要的工作邮件被AI当成垃圾邮件给过滤掉。
召回率(Recall)
召回率衡量的是“所有好东西里,你找到了多少”。还是那个邮件分类器,假设总共有12封垃圾邮件,它只找出来了8封,那它的召回率就是8/12,大概67%。在一些“宁可错杀,不可错放”的场景,召回率就比精确率更关键。比如用AI在海量医疗影像里筛查早期病灶,我们希望把所有可能的病灶都找出来,哪怕里面有一些是误报,医生再复核一下就行。漏掉一个,后果可能就很严重。
F1 Score
你看,精确率和召回率经常是“跷跷板”的两头,一个高了另一个可能就低了。F1 Score就是为了综合看它俩,是个调和平均数。当两个指标都比较高的时候,F1 Score才会高。对我们产品经理来说,不用死记硬背公式,只要知道它是用来平衡精确率和召回率的,避免我们被单一指标带偏就行。
幻觉率/胡言乱语率(Hallucination Rate)
这是大语言模型时代一个特别火的指标。说白了,就是AI一本正经地胡说八道的频率。我之前测试一个AI知识问答,问它某个历史事件,它给我编了一个不存在的人物和时间,讲得有鼻子有眼。这就是“幻觉”。对于严肃的、需要事实准确性的应用,比如法律咨询、医疗问答,幻觉率是生死线。追踪这个指标,就是要看我们的AI有多“诚实”,不知道的时候会不会说不知道,而不是瞎编。
任务完成率(Task Completion Rate)
这个指标非常直观。用户来找AI办一件事,办成了没有。比如,用语音助手订一个明天早上八点的闹钟。如果用户说了一遍,AI就成功设置了,这就是一次成功的任务完成。如果AI听不懂,或者设错了时间,用户放弃了,这就是一次失败。对于工具型、任务导向的AI产品,比如智能客服、AI助手,任务完成率是核心中的核心,直接反映了产品的可用性。
人工接管/干预率(Human Escalation/Intervention Rate)
这个指标是任务完成率的另一面镜子。当AI搞不定,需要把用户转给人工客服,或者用户自己手动操作才能解决问题时,就产生了一次人工接管。这个比率越高,说明AI的能力边界越窄,能独立解决的问题越少。它不仅是衡量AI能力的重要指标,还直接跟运营成本挂钩。每降低一个点的人工接管率,可能就意味着节省了巨大的人力成本。所以你看,这个指标,技术、产品、业务三方都会死死盯着。
三、核心维度二:用户体验与交互深度——衡量AI的“情商”与“吸引力”
如果说“能力有效性”是AI的智商,那接下来我们要聊的就是AI的“情商”。一个AI光聪明是不够的,它还得让人用着舒服、愿意用。用户跟AI的互动,不是冷冰冰的“请求-响应”机器,而是一种特殊的“对话”。这些交互行为的数据,能告诉我们这个AI的脾气怎么样,好不好沟通,有没有吸引力。
衡量AI的情商和吸引力,我们得看一些更细腻的指标:
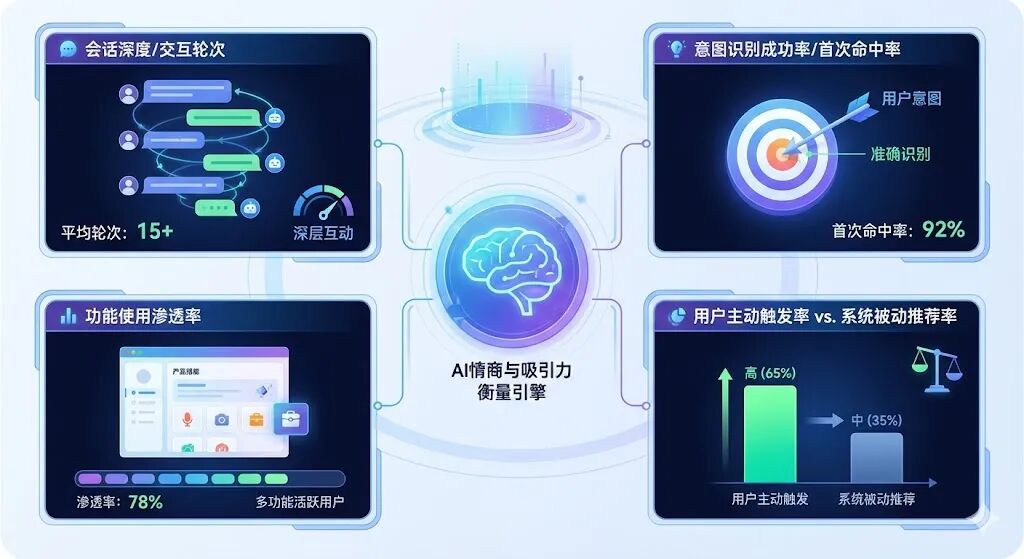
会话深度/交互轮次(Session Depth/Interaction Turns)
这个指标指的是,用户在一次使用中,跟AI来回聊了多少句。这个指标的解读很有意思,不能一概而论。比如一个智能问答,用户问一句,AI答一句,问题解决了,交互轮次少,说明效率高,这是好事。但如果是一个AI聊天伴侣或者一个创意激发工具,我们当然希望用户能跟它聊得更久、更深入,这时候交互轮次多就代表着用户粘性高。
所以分析这个指标,一定要结合产品定位。轮次过少,可能意味着AI没听懂用户意图,用户直接放弃了;轮次过多,也可能意味着AI太笨,用户得反复澄清、追问才能得到答案,体验很差。我们需要找到一个健康的“轮次区间”。
意图识别成功率/首次命中率(Intent Recognition Success Rate/First-Hit Rate)
这个指标特别关键,它衡量的是AI的“默契度”。当用户第一次说出他的需求时,AI能不能一下子就抓住重点,给出靠谱的回应。比如你对智能音箱说“放点适合工作的音乐”,它如果直接播放了一个你喜欢的轻音乐歌单,这就是一次成功的首次命中。如果它反问你“你想听什么类型的音乐”,或者直接放了一首摇滚乐,那体验就差远了。
首次命中率高,意味着交互流畅、不费劲,用户会觉得这个AI“懂我”。反之,如果用户每次都要跟AI解释半天,那他很快就会失去耐心。这个指标是衡量AI产品易用性的一个黄金标准。
功能使用渗透率(Feature Adoption/Penetration Rate)
我们不能只看有多少活跃用户,更要看这些活跃用户里,有多少人真正用到了我们最核心的AI功能。比如一个集成了AI写作功能的笔记软件,我们不能只看DAU,更要看“DAU中使用过AI润色功能的用户占比”。这个渗透率才能告诉我们,我们的核心AI能力是不是真的被用户接受和使用了。
很多时候,产品团队费了九牛二虎之力做了一个强大的AI功能,结果上线后发现渗透率极低。这就说明,要么是功能入口藏得太深,要么是功能本身没有切中用户痛点,要么是用户根本不知道有这个功能。追踪渗透率,能帮我们及时发现这类问题。
用户主动触发率 vs. 系统被动推荐率
这个维度的对比很有意思。它能帮我们分析,用户使用AI,更多是出于自己的主动意愿,还是更多地在接受系统的“投喂”。比如在一个电商APP里,用户是主动去搜索框使用“拍照识图”功能,还是更多地点了首页上“猜你喜欢”的AI推荐商品。
这两种行为模式,反映了产品不同的定位和用户心智。主动触发率高,说明AI功能已经成为用户解决问题的“首选工具”,用户对它有明确的认知和依赖。被动推荐率高,说明AI在“赋能”业务场景上做得很好,能不动声色地提升用户体验和商业转化。一个健康的产品,往往是这两者的平衡。我们需要知道我们的产品,现阶段更侧重哪一头,以及未来要往哪个方向去引导。
四、核心维度三:价值创造与业务影响——衡量AI的“商业价值”
聊完了AI的“智商”和“情商”,最后必须得聊聊它的“商业价值”。说到底,公司投入巨大的资源做AI,不是为了做慈善,也不是为了炫技。AI产品最终要回答一个问题:它给业务带来了什么实际的好处。这个维度的指标,就是我们拿着去跟老板、跟业务方汇报,证明我们工作价值的“硬通货”。
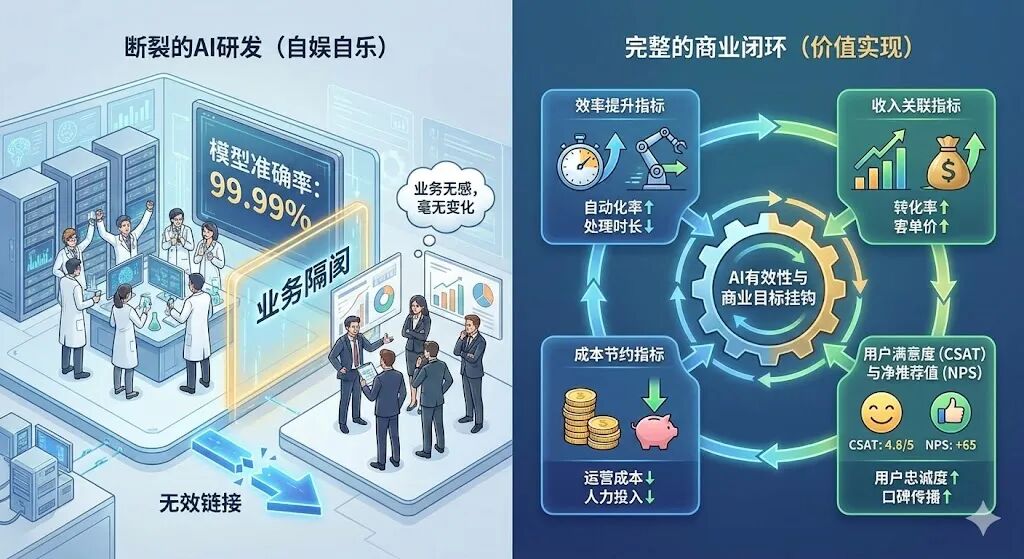
把AI的有效性跟商业目标挂钩,才能形成一个完整的闭环。不然,模型团队在实验室里把准确率刷到99.99%,业务方却感觉不到任何变化,那这个AI就是自娱自乐。
效率提升指标
这是AI最直接、最容易量化的价值之一。AI的出现,就是为了把人从重复、繁琐的工作中解放出来,或者增强人的能力。怎么衡量呢?很简单,就是看用了AI之后,完成某项任务的时间或成本是不是降低了。
举几个例子。用了AI代码助手后,程序员写一个功能模块的平均时间是不是缩短了。用了AI智能客服后,客服人员处理一个工单的平均时长(AHT)是不是下降了。用了AI设计工具后,设计师出一版海报的时间是不是从半天缩短到半小时。这些都是实实在在的效率提升,可以被清晰地度量和呈现。
成本节约指标
效率提升的另一面,往往就是成本节约。最典型的就是AI客服替代人工客服。我们可以直接计算,一个AI客服机器人每天能处理多少会话,相当于替代了多少个人工坐席。把这些坐席的人力成本、场地成本算一算,就是AI带来的直接成本节约。这个数字,在财报里会非常好看。
另一个例子是内容审核。以前一个大型社区可能需要成百上千的审核员来过滤违规内容,现在大部分工作可以由AI完成,只需要少量人工复核。这背后节省的人力成本也是一个巨大的数字。这些指标,能非常有力地证明AI的投资回报率(ROI)。
收入关联指标
除了降本增效,AI在“增收”方面的潜力也巨大。这里的关键是,要把AI的表现和收入指标关联起来。比如,电商平台的智能推荐系统,我们可以通过A/B测试,对比使用新推荐算法和旧算法的两组用户,他们的客单价、转化率、GMV有没有显著提升。这个提升的部分,就可以归因于AI的贡献。
再比如,用AI生成营销文案和广告素材。我们同样可以测试,AI生成的素材和人工制作的素材,在投放后的点击率、转化率上有没有差异。如果AI素材的转化率更高,那它带来的额外收入就是可以计算的。这些指标,直接把AI技术和公司的生命线——收入,连接在了一起。
用户满意度(CSAT)与净推荐值(NPS)
前面说的都是“硬”指标,但用户的“软”感受同样重要。一个AI可能效率很高,也省钱,但如果用户用得一肚子火,那这个产品也走不远。所以,我们需要通过调研的方式,直接问用户。
CSAT(用户满意度)通常是在用户完成一次AI交互后,弹出一个简单的问题,比如“您对本次AI服务满意吗?”,让用户打分。这能帮我们快速了解单次交互的体验质量。
NPS(净推荐值)则问得更深入:“您有多大可能将这个AI功能推荐给朋友或同事?”。这个问题衡量的是用户的整体忠诚度和口碑。一个高NPS的产品,才具备了自增长的潜力。把NPS作为AI产品的一个北极星指标,能确保我们在追求技术和商业目标的同时,没有偏离“以用户为中心”的航线。
五、实战框架:构建AI产品的数据指标体系
前面我们聊了三个维度的各种指标,听起来可能有点散。现在,我们得把这些珍珠串成一条项链,形成一个系统化的、可操作的指标体系。不然,一堆零散的指标只会让我们陷入“数据海洋”,找不到方向。我个人比较喜欢用OSM模型,也就是目标(Objective)-策略(Strategy)-度量(Measurement),这个框架能帮我们把思路理清楚。
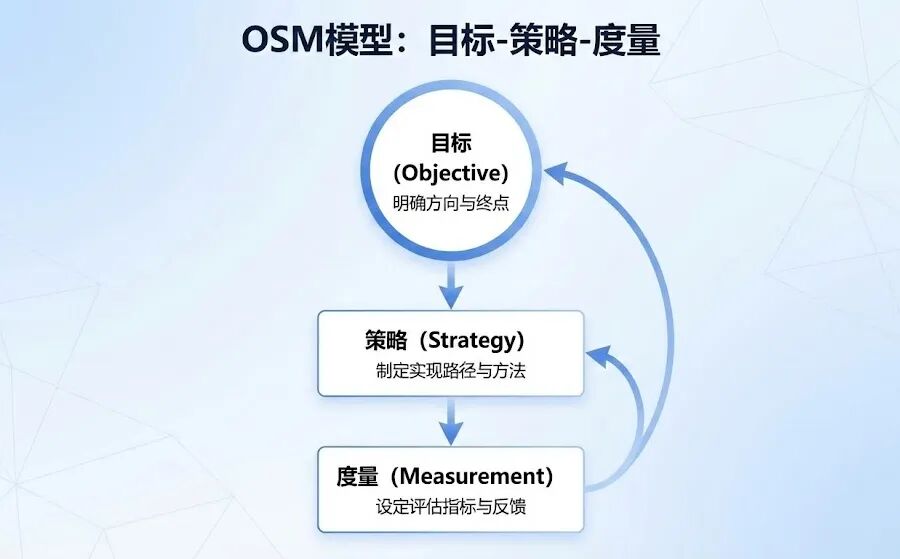
我们就拿一个具体的产品来举例吧,假设我们正在做一个“智能写作助手”,它的目标是帮用户提升内容创作的效率和质量。
第一步:定义目标(Objective)
目标必须是清晰、明确,且能鼓舞人心的。对于我们的智能写作助手,目标可以定义为:成为用户在内容创作时,不可或缺的智能伙伴,显著提升其创作效率与作品质量。这个目标指明了方向,我们所有的工作都要围绕它展开。
第二步:拆解策略(Strategy)
为了实现这个目标,我们需要采取哪些策略?策略是连接目标和具体行动的桥梁。我们可以拆解出几个关键策略。
策略一:提供高质量的核心写作辅助能力。这是产品的根基,AI必须真的有用。具体来说,就是提供精准的语法纠错、流畅的文本润色、富有创意的灵感生成等功能 。
策略二:打造无缝、智能的交互体验。功能再强大,如果用起来很别扭,用户也不会买账。我们需要让AI功能自然地融入用户的写作流程,做到“召之即来,挥之即去” 。
策略三:证明并放大产品为用户创造的价值。让用户明确感知到,用了我们的产品后,他写得更快了,文章质量更高了,获得了更多读者的认可 。
第三步:配置度量(Measurement)
这是最关键的一步,我们要为每一条策略,配置上具体的、可量化的度量指标。这时候,前面讲的内容就派上用场了。我们会从能力、体验、价值三个维度来配置我们的“仪表盘”。
针对策略一(高质量核心能力),我们的度量指标可以是:
- 语法纠错准确率与召回率:衡量AI挑错有多准,有没有漏掉错误(能力有效性)
- 文本润色建议的采纳率:用户有多大比例接受了AI的润色建议,这直接反映了建议的质量(能力有效性 & 用户体验)
- 生成内容的“幻觉率”:在生成灵感或段落时,AI胡说八道的频率要尽可能低(能力有效性)
针对策略二(无缝智能的交互体验),我们的度量指标可以是:
- 核心AI功能的渗透率:有多少用户真正用到了我们的润色、续写等核心功能(用户体验)
- 功能的平均响应时长:从用户触发AI到AI给出结果,需要多长时间。没人喜欢等待(用户体验)
- 会话深度与任务完成率:对于需要多轮交互的复杂指令,用户平均需要几轮能完成,最终成功率如何(用户体验 & 能力有效性)
针对策略三(证明并放大用户价值),我们的度量指标可以是:
- 用户平均创作时长变化:对比使用AI前后的用户,他们的平均文章创作时长是否缩短(价值创造)
- 用户保存/导出/发布的比例:用户在使用了AI功能后,有多大意愿将最终的作品保存或发布,这间接反映了他们对作品的满意度(价值创造)
- NPS净推荐值:直接询问用户是否愿意把我们的产品推荐给其他人(价值创造)
你看,通过OSM这个框架,我们就把一个宏大的目标,拆解成了具体的策略,再把策略落实到了一个个清晰的度量指标上。这个指标体系,既包含了衡量AI“智商”的能力指标,也包含了衡量AI“情商”的体验指标,最终还落脚到了衡量“商业价值”的业务指标。它形成了一个完整的逻辑闭环,指导着我们产品迭代的每一个决策。
六、常见陷阱与最佳实践
理论聊了这么多,框架也搭好了,但在实际工作中,我们还是会踩各种各样的坑。作为在坑里摸爬滚打多年的老兵,我想分享一些血泪教训和个人觉得比较好用的实践方法。这些东西,可能比理论更值钱。
陷阱一:“唯准确率论”
这是最常见的一个坑,尤其是技术背景很强的团队,容易陷入对模型指标的盲目崇拜。大家拼命地刷榜,把某个任务的准确率从98%提升到99%,再到99.5%。在汇报PPT上,这是一个非常亮眼的成绩。
可用户真的关心这1.5%的提升吗?不一定。我亲身经历过一个项目,我们做了一个图像识别功能,模型在标准测试集上的准确率高达99%。但上线后用户抱怨很多。我们深入分析才发现,那1%的错误,全都出在用户最常拍、光线最差的场景里。而在那些光线好、角度正的“标准照片”上,我们的表现完美无缺。用户在真实场景中用不了,你实验室数据再好看又有什么用呢?
记住,模型指标是过程,用户体验和业务价值才是最终目的。过度追求模型指标,而忽略了它在真实、复杂、混乱的用户场景下的表现,就是典型的“只见树木,不见森林”。
陷阱二:“数据孤岛”
另一个大坑是数据不通。算法团队看着他们的模型评估报告,F1 Score又提升了三个点,欢欣鼓舞。产品团队看着用户行为数据,某个AI功能的点击率下降了,一头雾水。业务团队看着客服后台,关于AI答非所问的投诉量上升了,焦头烂额。
这三个团队,说的好像不是一回事。这就是“数据孤岛”。模型效果数据、用户行为数据、业务结果数据,三者之间是割裂的,没有建立起关联分析。模型的一次“优化”,可能在提升某个技术指标的同时,损害了用户体验的另一个方面。如果我们不能把这些数据串起来看,就无法形成一个完整的分析链条,找不到问题的根源。
最佳实践一:建立定性的“案例库”
数据是冷的,但用户是活的。光看报表上的数字,我们很难有体感。我强烈建议,每个AI产品经理都要养成一个习惯:定期去“看案例”。不管是去看智能客服的聊天记录,还是去看AI生成内容的具体case,你都要去品。
建一个案例库,把那些典型的成功案例和失败案例都存下来。一个成功的案例,能告诉你AI在什么场景下最能发光发热。一个失败的案例,往往比一堆数据报表更能揭示产品的深层问题。我经常在团队周会上,分享一两个有趣的失败案例,大家一起讨论“如果我是AI,我该怎么回答会更好”。这种定性的分析,是对定量数据最好的补充和印证。

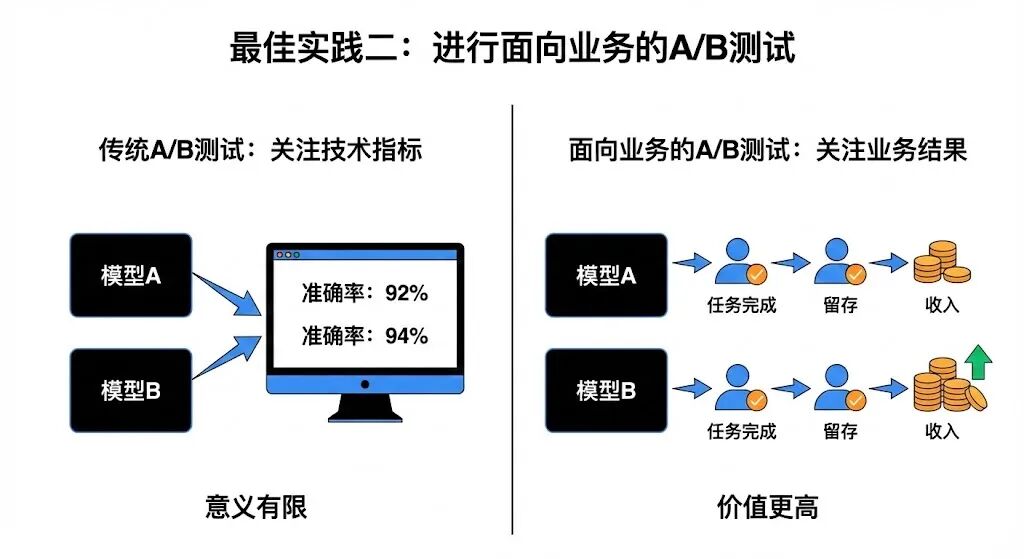
最佳实践二:进行面向业务的A/B测试
A/B测试是互联网产品的基本操作,但在AI产品这里,我们可以玩得更高级。我们不应该只测试“新模型版本A vs. 旧模型版本B,谁的准确率更高”。这种测试意义有限。
我们应该做的是,把新旧两个模型版本同时上线,分流给不同的用户群体,然后去观察这些用户的行为和业务结果有没有变化。比如,用了新模型的那组用户,他们的任务完成率是不是更高?他们的留存率是不是更好?他们带来的收入是不是更多?
通过这种方式,我们把模型迭代的效果,直接跟用户行为和业务指标挂钩。一个模型好不好,不是算法工程师说了算,而是用户和市场说了算。只有在A/B测试中,能带来真实业务提升的模型,才是我们真正需要的模型。
七、从“监控”到“洞察”,让数据为AI产品进化赋能
聊到这里,我们从AI产品为什么需要新的数据视角开始,一路探讨了衡量AI能力、体验和价值的三个核心维度,也分享了构建指标体系的框架和一些实战中的坑与经验。
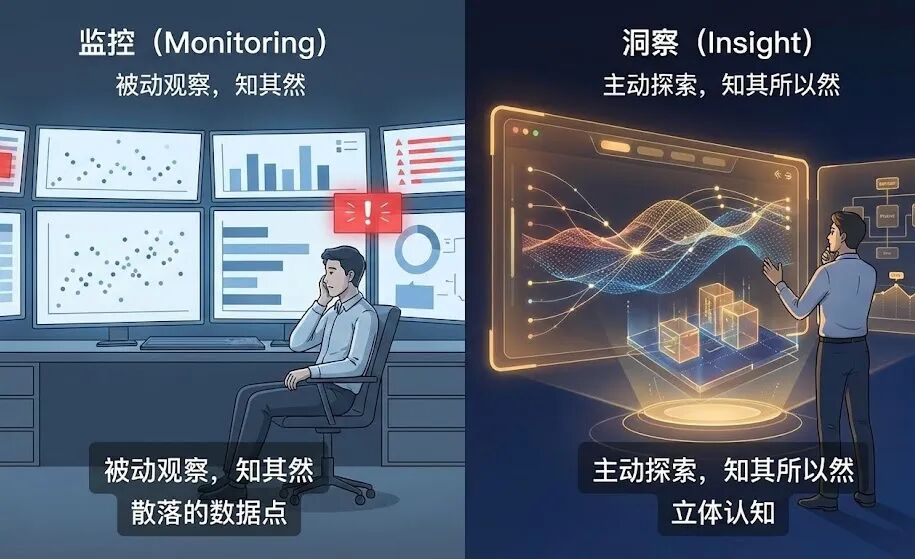
我想说,所有这些指标、框架和方法,都只是工具。工具本身不产生价值,使用工具的人才产生价值。作为AI产品经理,我们的角色绝不仅仅是每天看看数据报表,监控指标有没有异常波动。那是数据分析师的工作,或者说,只是我们工作中最基础的一部分。
我们真正的价值,在于成为数据的“翻译官”和“洞察者”。当看到“幻觉率”上升了0.5%,我们要能翻译出“这意味着我们的用户在某些场景下,被AI误导的风险增加了”。当看到“会话深度”变浅了,我们要能洞察到“这可能是因为我们新上的功能简化了用户操作,也可能是因为AI的回答质量下降,用户不愿意聊下去了”。
从“监控”到“洞察”,一词之差,天壤之别。监控是被动地看,是“知其然”。洞察是主动地问,是“知其所以然”。它要求我们把散落的数据点连接成线,再把线编织成面,最终形成对产品、对用户、对业务的立体认知。
DAU很重要,但它只是故事的开始。在AI的时代,故事的精彩篇章,写在那些更深、更独特的数据维度里。通过这些维度,我们能更早地发现产品的暗礁,更准地把握优化的航向,最终驱动AI产品,从一个“看起来很酷”的技术demo,进化成一个真正为用户创造价值、具备可持续生命力的好产品。
这趟旅程,道阻且长,但充满乐趣。希望今天的分享,能给你一些启发。
本文由 @大叔拯救世界 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Pexels,基于CC0协议






- 目前还没评论,等你发挥!


