
 起点课堂会员权益
起点课堂会员权益再次创造历史!DeepSeek-V3.2两大模型放出,性能对标Gemini-3.0-Pro
ChatGPT发布三周年之际,DeepSeek推出两款新模型,DeepSeek-V3.2和DeepSeek-V3.2-Speciale,分别主打平衡实用和推理狂魔,性能媲美Gemini-3.0-Pro。DeepSeek-V3.2在日常Agent任务中表现出色,而DeepSeek-V3.2-Speciale则是科研党的福音。
突袭!ChatGPT发布三周年,DeepSeek“咣”地一声甩出两个新模型:DeepSeek-V3.2和DeepSeek-V3.2-Speciale。 前者主打“平衡实用”,后者直接化身“推理狂魔”,性能媲美Gemini-3.0-Pro 。
更离谱的是,Speciale 一口气把 IMO 2025、CMO 2025、ICPC World Finals 2025、IOI 2025 四块金牌全揣兜里——ICPC 成绩排人类第二,IOI 飙到人类第十,堪称“奥林匹克收割机”。
下面直接上硬菜,一口气把俩模型的里子面子全扒光。
一、DeepSeek-V3.2:平衡怪,日常 Agent 全能王
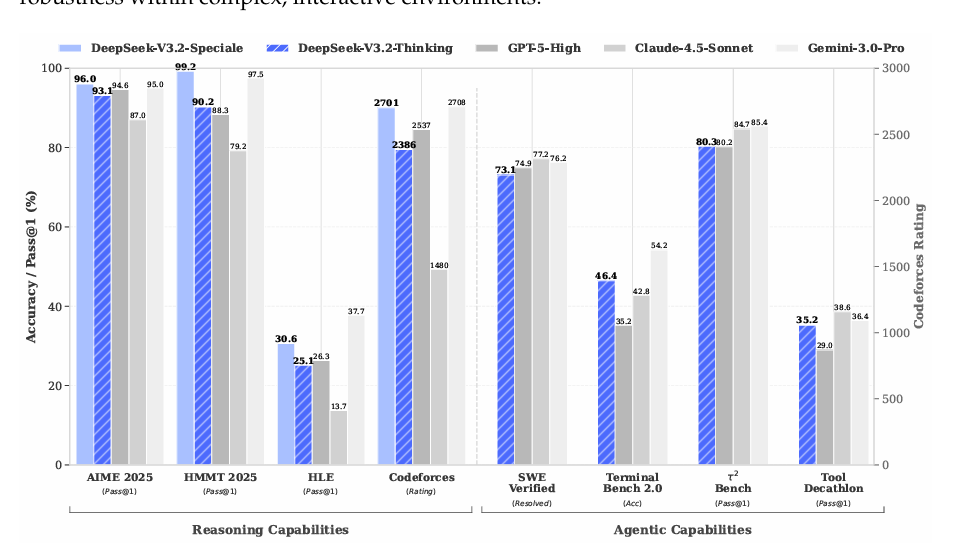
总结:V3.2侧重于平衡推理能力与输出长度,降低计算开销日常问答、通用 Agent、真实场景工具调用,推理对标 GPT-5,略逊 Gemini-3.0-Pro,但输出长度砍半,用户等待时间直接腰斩。
- 1800+ 环境、8.5 万条复杂指令喂出来的 Agent 数据,泛化到没见过的工具也能秒上手。
- DeepSeek模型体系当中首个“思考/非思考”双模式工具调用:想深思就深思,想秒回就秒回。
- 相比Kimi-K2-Thinking大幅缩短输出长度,减少用户等待时间;
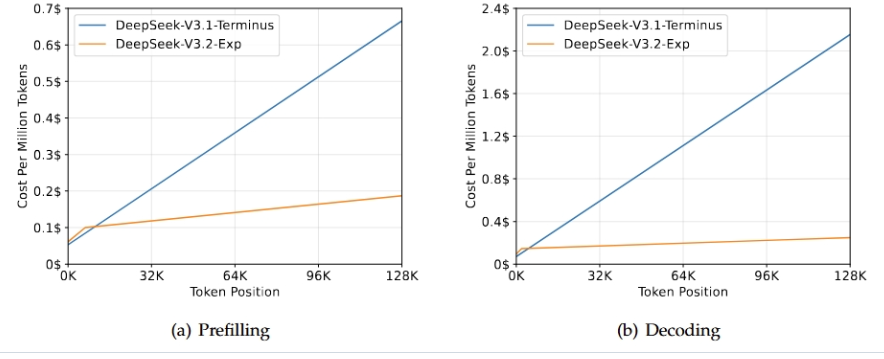
- 推理成本128 k 长下文在 H800 上预填充成本从 0.7 → 0.2 美元/MTok,解码 2.4 → 0.8 美元/MTok,直接打骨折。
成绩SWE-Verified 73.1 %、Terminal Bench 2.0 46.4 %,开源圈里横着走;MCP-Universe、Tool-Decathlon 跟闭源怪物肩并肩。
二、DeepSeek-V3.2-Speciale:长思考怪兽,科研党福音
定位:数学证明、编程竞赛、学术研究,日常聊天别找它——它连“你好”都懒得优化。
绝活:把 DeepSeek-Math-V2 的定理证明能力直接融进骨髓,复杂逻辑一路火花带闪电。
代价:输出长度爆表,Token 烧钱速度肉眼可见,目前只给临时 API,不支持工具调用。
三、架构黑科技:DSA 稀疏注意力,长文本不再是电费黑洞
DeepSeek-V3.2 的核心架构创新是 DSA(DeepSeek Sparse Attention),把注意力复杂度从 O(L²) 砍到 O(L·k),长上下文推理几倍提速且几乎不掉点,同时支持 FP8 与 MLA,训练友好。
做法分两步:
第一步:Lightning Indexer 先以 ReLU 激活快速算出查询与历史 token 的相关分,只留 top-k。
第二步:细粒度 token 选择机制用这 top-k 完成稀疏注意力。
继续训练采用两阶段:
- Dense Warm-up(1000 步,21 B token)只训 indexer,对齐分布;
- 再开稀疏阶段(15 k 步,943 B token)每查询仅取 2048 键值对。128 k 序列实测:H800 集群预填充成本从 0.7 → 0.2 美元/百万 token,解码从 2.4 → 0.8 美元,提速数倍。

四、后训练:RL 预算飙到预训练 110 %
DeepSeek团队在强化学习上下了血本
- 改进 GRPO:重新推导 K3 估计器,消除原公式带来的系统性偏差,防止梯度权重爆炸
- Keep Routing:MoE 训练-推理路由经常不一致,先缓存推理时的专家路径,训练时强制复刻,锁住参数空间
- 离线序列掩码:把大幅偏离当前策略的负样本序列直接 mask,避免大批量 off-policy 更新搅局
- 训练流程采用“专家蒸馏”:先给数学、代码、通用推理、Agent 等 6 大场景各训一套小专家(均含思考/非思考双模式),再用它们产出的高质量数据灌进最终模型,保证难度与多样性兼顾
五、Agent 能力的突破
此外,此次新模型在Agent任务上的突破也让人眼前一亮。这次DeepSeek团队找到了让模型同时具备推理和工具使用能力的方法。
训练方式可以概括为以下几点
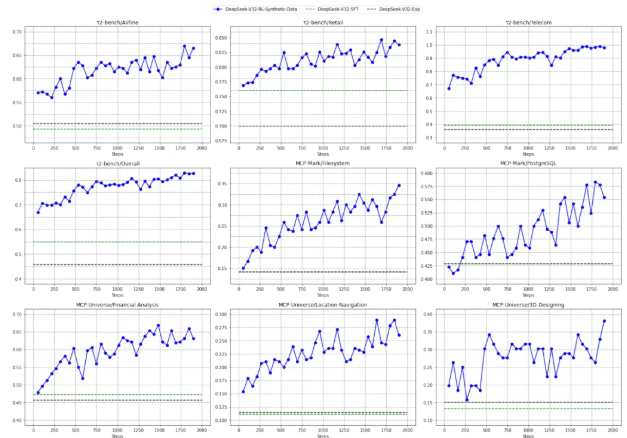
- 自动环境合成pipeline:团队开发了自动生成任务的系统,创建了1827个任务导向环境和85000个复杂提示,例如旅行规划任务,模型需在多种约束下规划三天行程,涉及不重复城市、根据酒店价格调整预算等复杂逻辑。
- 推理与工具使用能力结合:团队找到了让模型同时具备推理和工具调用能力的方法。
- 上下文管理优化:改进了DeepSeek-R1每次新对话就丢弃推理内容的策略,只在引入新用户消息时才丢弃历史推理内容,工具相关消息则保留推理内容,确保工具调用历史和结果始终在上下文中。
- 冷启动策略:通过精心设计的系统提示,让模型在推理过程中自然插入工具调用,例如在编程竞赛题目中明确要求模型先思考再作答,并用特殊标签标记推理路径。
- 代码Agent方面:团队从GitHub挖掘数百万issue-PR对,经严格筛选和自动环境构建,搭建数万可执行软件问题解决环境,覆盖Python、Java、JavaScript等多语言。
- 搜索Agent方面:通过多Agent流水线生成训练数据:先采样大规模语料中的长尾实体,再经问题构建、答案生成与验证,产出高质量数据。DeepSeek-V3.2在SWE-Verified达73.1%解决率,Terminal Bench 2.0达46.4%准确率,显著超越开源模型,并在MCP-Universe、Tool-Decathlon等工具基准上逼近闭源模型表现
六、官方自曝局限
总 FLOPs 仍少,世界知识广度落后顶尖闭源。
Token 效率有待提升,同样质量需要更长轨迹。
别催,R2 还在锅里。
七、消息推送
App 和 Web 已全量推送 DeepSeek-V3.2,Speciale 临时 API 限量开测,技术报告同步上线。
本文由 @产品经理小易 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


