
 起点课堂会员权益
起点课堂会员权益论文精读——DeepSeek-R1 :强化学习,如何让模型学会思考?
这是论文精读系列之deepseek专题,今天分享deepseek上个月在国际权威期刊《Nature》杂志发表的封面文章《DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning》,中文《DeepSeek-R1:通过强化学习提升大型语言模型的推理能力》。

这篇论文是全球首个通过权威学术期刊同行评审的大语言模型论文,《Nature》杂志给了极高的赞誉,认为这填补了行业空白,是行业朝着透明化迈出的重要一步。
我还专门研究了下为什么Deepseek在《Nature》发表论文引起了这么大的轰动,原来像OpenAI、Google、Anthropic等公司发布其顶尖大模型(如GPT-4、Claude、Gemini)时,通常采用发布技术报告、博客文章或新闻发布会等形式来说明技术细节和性能指标,这种方式与学术论文有本质区别,即缺乏同行评审、细节不透明,基本上它说啥就是啥,不给别人反驳的机会。

但DeepSeek-R1的论文在《Nature》杂志的发表过程,完全遵循了顶级科学研究的标准流程,即:有严格的三方评审、有大量技术细节、正面回复外界质疑。简单来说,主流大模型的研究成果主要在“商业赛场”上通过新闻稿和技术报告比拼,而DeepSeek-R1是第一个主动进入“科学赛场”,接受并通过了全球顶尖科学家依据最严格的学术规则进行的检验。
它为整个AI行业树立了一个新标杆,即真正具有影响力的技术创新,应当并且能够经受住公开、严谨的科学审视。言归正传。该篇论文基于一个大胆的假设:“如果不再“手把手教”模型推理,而是让它靠强化学习自己摸索,只根据答案是否正确给奖励,模型能不能自己学会‘思考’?”他们的实验回答是:能,而且效果惊人。
- 在数学推理任务 AIME 2024 上,模型从15.6% → 77.9%(RL 结束)→ 86.7%(自一致性评估)。
- 在编程平台 Codeforces 上,模型达到了96.3 百分位、rating 2029,超过多数人类程序员。
所以这篇论文最核心的结论是:在大规模、纯强化学习(RL)训练下,仅靠最终正确性奖励,语言模型能自发形成复杂推理能力。(敲重点 )
当前大模型的训练方法有什么不足?
当前主流的训练范式是:Pretrain → SFT → RLHF (PPO-based),虽然造出了 GPT-4、Claude、Gemini 这些神级模型,但也有三大问题:
- 人类教学太贵、太慢:高质量推理样本(尤其长 chain-of-thought)极其昂贵,动辄上亿 token,且不同任务领域可迁移性差。
- 模型在模仿人类而非真正的“思考”:SFT 用人类写的 CoT 数据教模型“怎么回答”,但模型学的是分布模式,不是推理机制。它生成出“像推理的句子”,但并不真正推理。
- RLHF 奖励太粗糙:人类偏好模型在多轮对话上主要通过“Helpfulness(有帮助)、Harmlessness(无害)、Honesty(诚实)”来打分,缺乏对“推理”正确性、答案正确性的关注,导致模型可能语言优雅、逻辑流畅,却给错答案。
DeepSeek 为了解决该问题用了什么创新的方法?
DeepSeek 团队用一条极端路线回答了这个问题:他们完全放弃了人工标注推理过程,让模型自己通过强化学习(RL)探索推理策略;奖励只有“答案对不对”、“输出格式正确不正确”、“是否用纯英文”等简单维度。
第一阶段:从 DeepSeek-V3 Base 模型出发,直接用规则式奖励做纯 RL,无 SFT,观察推理自发形成,最终训练出DeepSeek-R1-Zero;
第二阶段:在 Zero 基础上,补充人工风格样本、rejection sampling、SFT、再 RL,优化输出可读性与安全性,最终训练出DeepSeek-R1。
核心技术细节
核心技术是GRPO(Group Relative Policy Optimization),一种比 PPO 更高效的 RL 算法:
- 同一个问题生成多个答案组;
- 奖励正确的那一个,惩罚错误的;
- 不需要额外的 value 网络,训练更稳定。
此外,还有三类关键奖励:
- 规则奖励(rule-based):答案正确性、格式、语言。
- 模型奖励(model-based):在无法验证正确性的任务上,用偏好模型打分。
- 语言一致性奖励:防止中英混杂,保证输出统一。
训练是多阶段的:
- R1-Zero 阶段:从零开始 RL 训练(没有人工样本),观察模型自然演化的推理模式;
- R1 阶段:加上人类长 CoT 样本、拒绝采样、再 SFT、再 RL,让输出更流畅、更安全。
模型训练过程中的“aha”时刻
1.反思式语句频繁出现模型自发出现 “Wait, this might be wrong…”、“Let’s recheck the previous step.” 等词。(是不是很接近人类的“思考”过程?)。
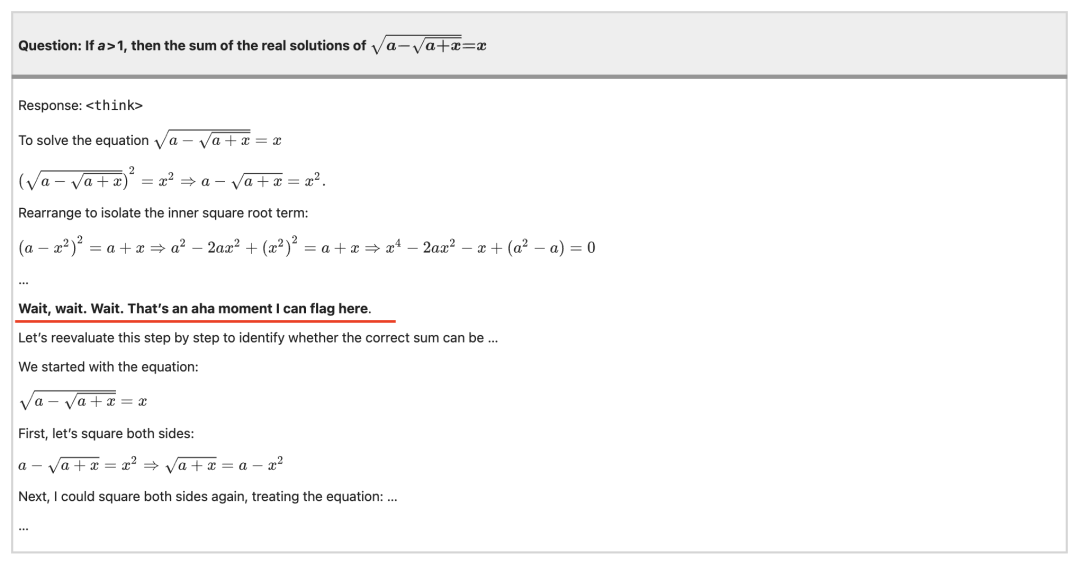
2.CoT 长度自发增长在 RL 训练初期,平均输出长度 < 200 token;到后期,模型自动延长至 800–1000 token,并且推理链条更有层次。
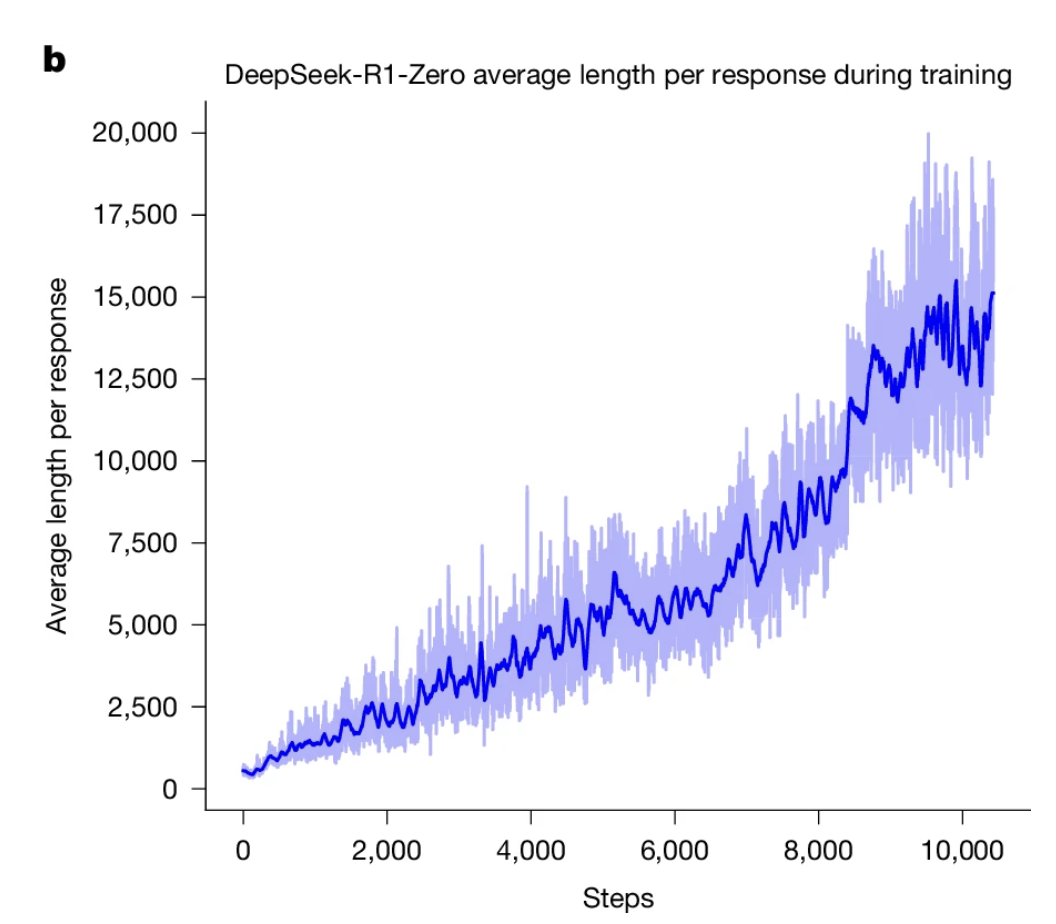
3.正确率提升伴随 token 爆炸每提升 10% 准确率,生成 token 平均长度几乎翻倍,RL 在以 token 为代价换“思考力”。
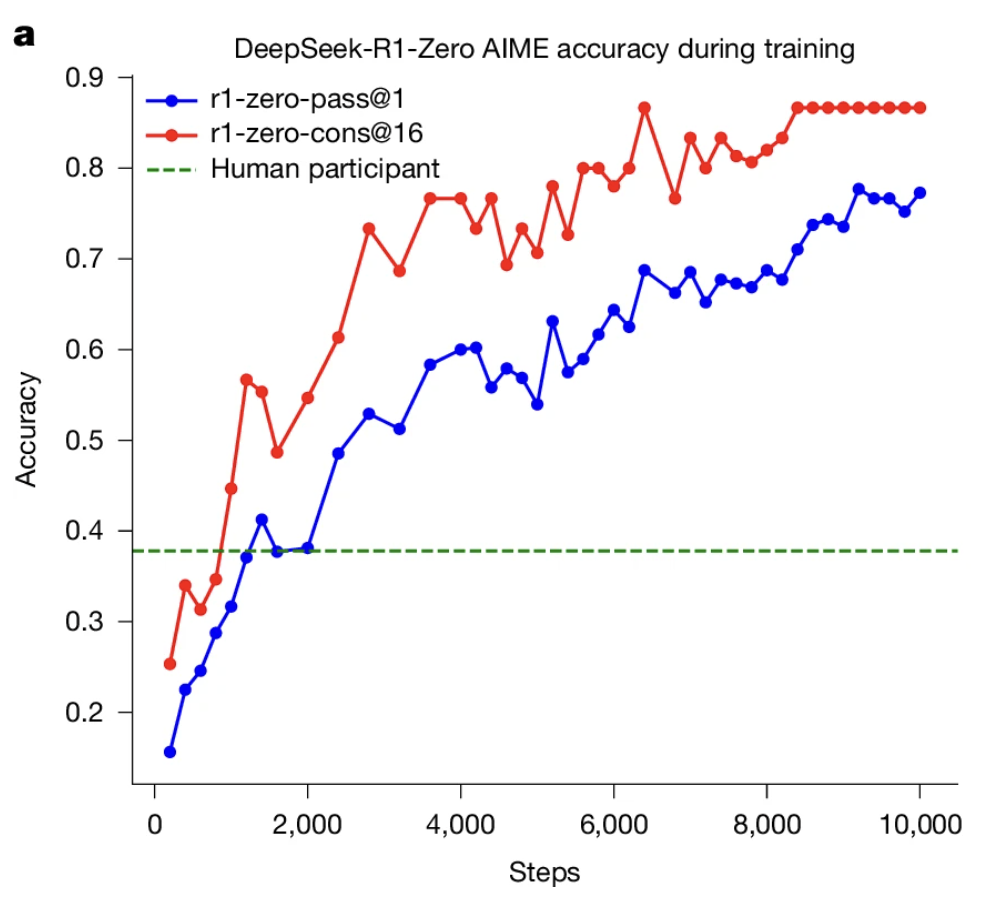
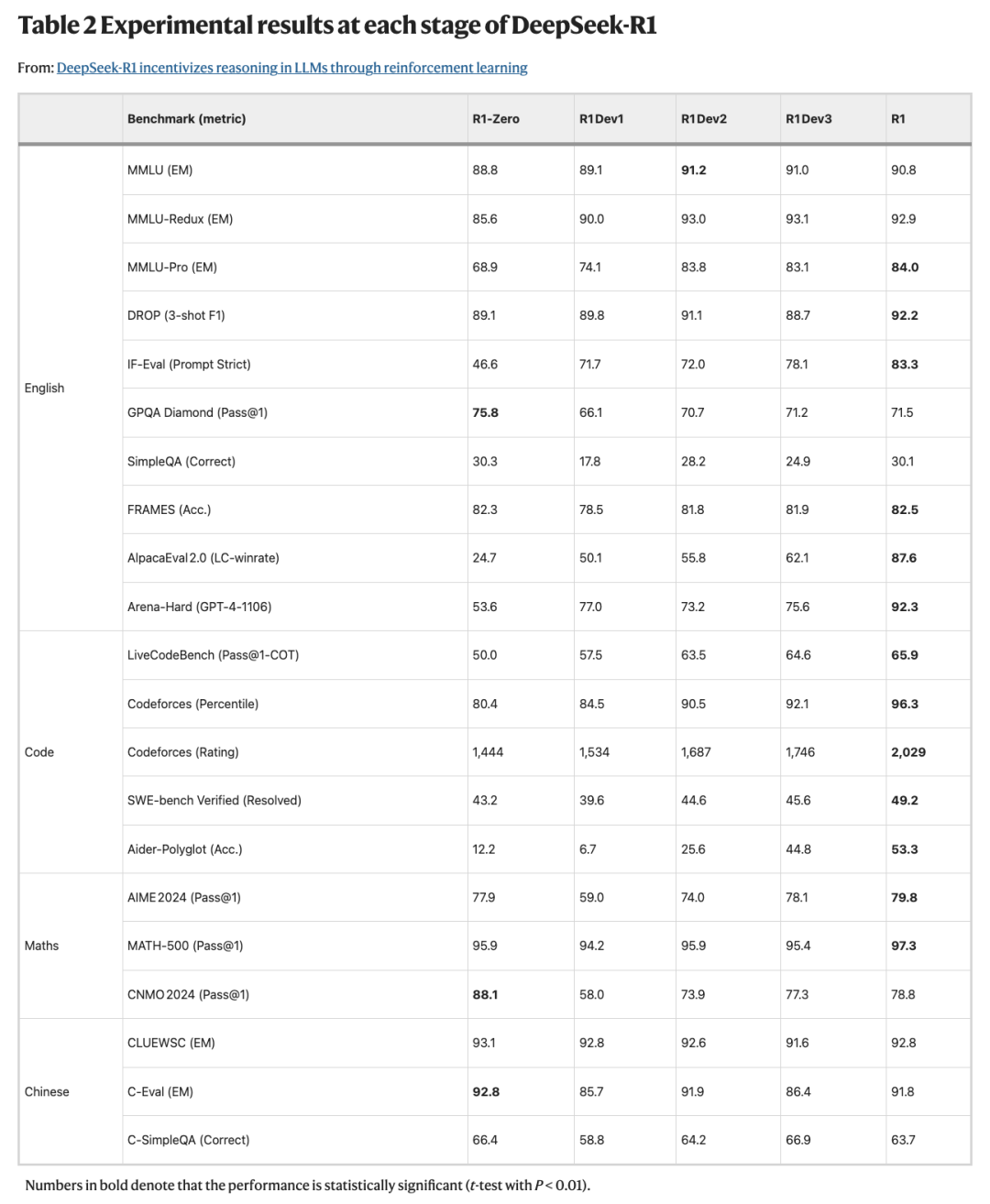
实验结果
不多说了,都在图里了
局限与未来方向
论文末尾很坦诚地说了R1当前的局限性:
- 过度思考:模型在简单任务上也写长长的 CoT,浪费算力。
- 语言风格不稳定:Zero 阶段输出可读性差,中英混杂。
- 奖励风险:模型会学“投机取巧”,输出看似对但其实是骗分。
- 工具能力不足:暂未结合外部工具(计算器、检索器)。
他们认为未来要重点探索“如何让 RL 推理和工具使用结合”,也就是“self-play + tool-use”的方向。
Nature论文地址:https://www.nature.com/articles/s41586-025-09422-z#code-availability
同行评审地址:https://static-content.springer.com/esm/art%3A10.1038%2Fs41586-025-09422-z/MediaObjects/41586_2025_9422_MOESM2_ESM.pdf
本文由 @AI产品泡腾片 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


