
 起点课堂会员权益
起点课堂会员权益AI 智能体“失忆”了吗?
长上下文AI的记忆问题一直是产品设计的痛点,LightMem论文带来革命性解法:模仿人类睡眠机制的三层记忆架构,将Token消耗骤降38倍的同时提升QA准确率。这不仅破解了实时性与成本的悖论,更揭示了异步记忆体验与端云协同的新产品逻辑。
在构建 Long-context(长上下文)或多轮对话 Agent 时,产品经理和开发者最头疼的问题往往不是模型“不够聪明”,而是模型“记不住”或者“记得太贵”。
现有的记忆系统(Memory Systems)虽然让 LLM 摆脱了无状态的限制,但在高频交互中,它们往往变成了拖慢响应速度、消耗巨额 Token 的“吞金兽”。
近期新出炉的论文《LightMem: Lightweight and Efficient Memory-Augmented Generation》,来聊聊智能体记忆设计的现状、瓶颈,以及一种模仿人类“睡眠整合机制”的新架构。
01 当前智能体记忆的“三座大山”
尽管 RAG(检索增强生成)和向量数据库已经普及,但在处理动态、复杂的长期交互时,现有的记忆系统仍面临三大痛点:
信息冗余与噪声
在长对话中,用户和模型都会产生大量废话(寒暄、重复确认)。现有的系统通常不管三七二十一,将原始数据直接塞进处理流程。
后果:只有少部分信息对决策有用,大量噪声不仅浪费 Token,甚至会因为干扰信息太多降低模型的推理能力。
语义割裂
目前的记忆构建通常是基于固定的“窗口”或逐轮处理的 ()。这忽略了对话中跨轮次的语义联系。
后果:记忆片段是破碎的。当模型试图回顾历史时,往往只能检索到只言片语,丢失了关键的上下文细节。
在线更新的延迟
这是最影响用户体验的一点。目前的系统大多采用“读写同步”——即在用户等待回复的那几秒钟里,系统还要忙着更新记忆库、删除旧数据 ()。
后果:随着记忆库变大,推理延迟直线上升。用户感觉 AI 反应越来越慢。
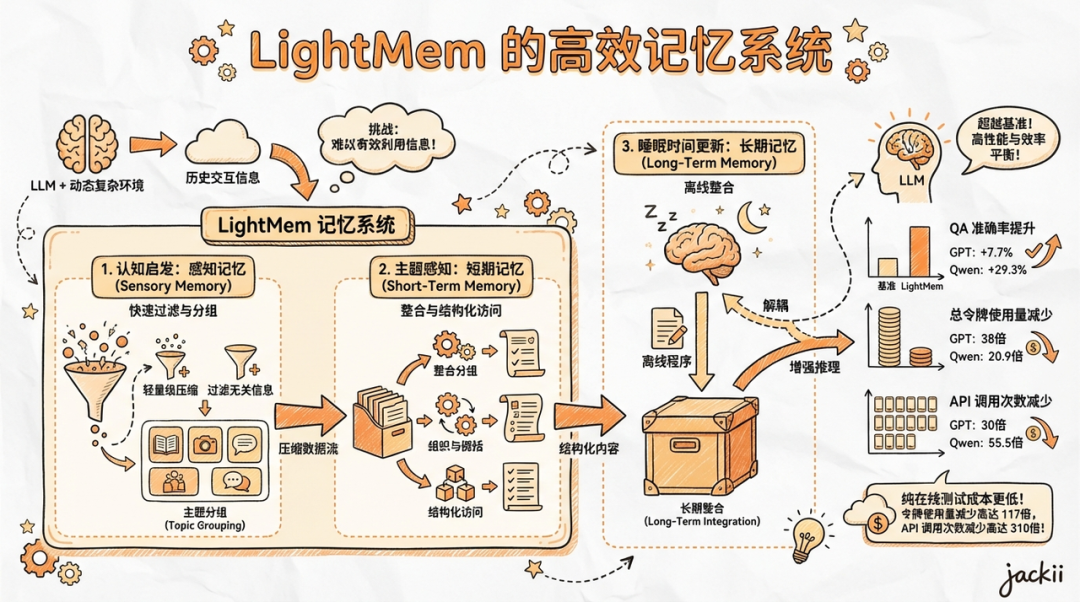
02 LightMem解法:像人脑一样的分层处理
LightMem 的核心逻辑是:不要让所有信息都进入长期记忆,也不要时刻都在整理记忆。它模仿人类的记忆模型(Atkinson-Shiffrin模型),把记忆分成了三层:
第一层:感官记忆 (Sensory Memory) ——“过滤器”
人类的眼睛和耳朵每秒接收无数信息,但我们只会注意重要的部分。
LightMem 引入了一个轻量级的小模型(或者基于熵的压缩器),在信息进入系统前先做两件事:
- 去噪:把那些“嗯、啊、好的”这种低信息量的 Token 直接扔掉。
- 话题切分:不是按字数切,而是按“话题”切。比如用户聊完“写代码”转头聊“去旅游”,系统能识别出这是两个话题,分别打包。
收益:垃圾进,垃圾出。这一步直接把“垃圾”挡在门外,Token 消耗立减。
第二层:短期记忆 (Short-Term Memory) —— “缓冲区”
信息经过过滤后,先放在短期记忆里暂存。
重点来了:它不会每轮对话都去触发总结。 只有当这个话题聊透了,或者缓冲区满了,系统才会把这一坨相关的对话打包,生成一个高质量的“记忆胶囊”。
收益:大幅减少了调用 LLM 做总结的次数,省钱又省时。
第三层:长期记忆 (Long-Term Memory) —— “夜间模式”
这是 LightMem 最天才的设计:“睡眠更新机制” (Sleep-time Update)。
- 白天(在线对话时):当需要存新记忆时,只做“软更新”(Soft Update)。就像你忙的时候随手贴一张便利贴,只管记下来,不花时间去整理归档。这样用户感觉不到延迟。
- 晚上(离线空闲时):当用户不聊天了,系统进入“睡眠模式”。这时候,它才开始在后台慢慢整理便利贴,把重复的合并,把冲突的修正,把碎片知识连成网。
收益:彻底解耦了推理和记忆维护。用户端响应毫秒级,后台维护异步进行。
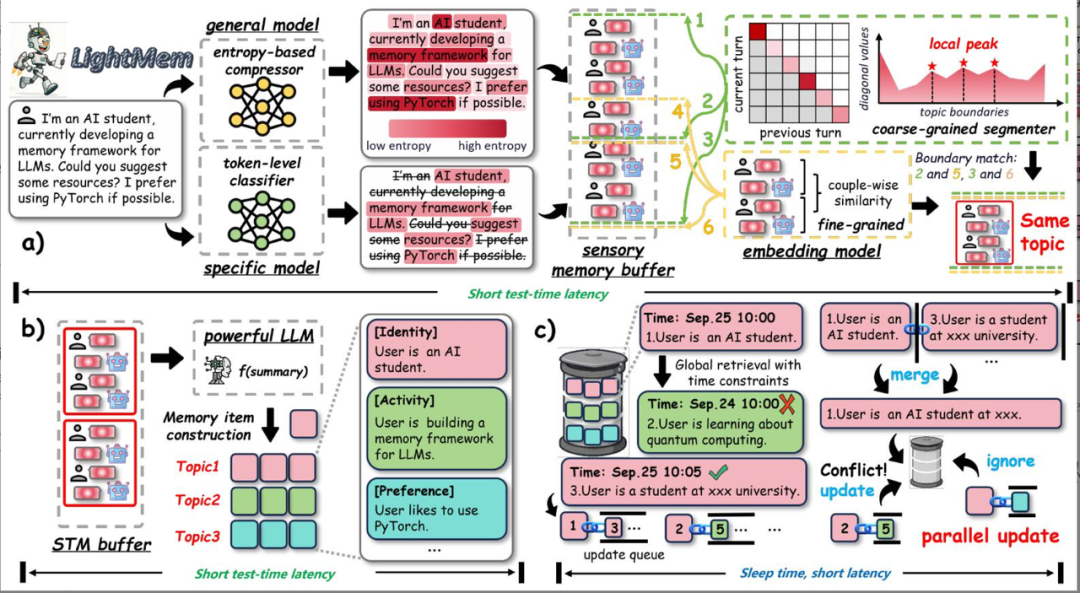
LightMem 架构
LightMem 由三个模块组成:a) 高效感知记忆模块,b) 主题感知 STM 模块,以及 c) 在睡眠时间更新 LTM 模块。
03 效果有多炸裂?用数据说话
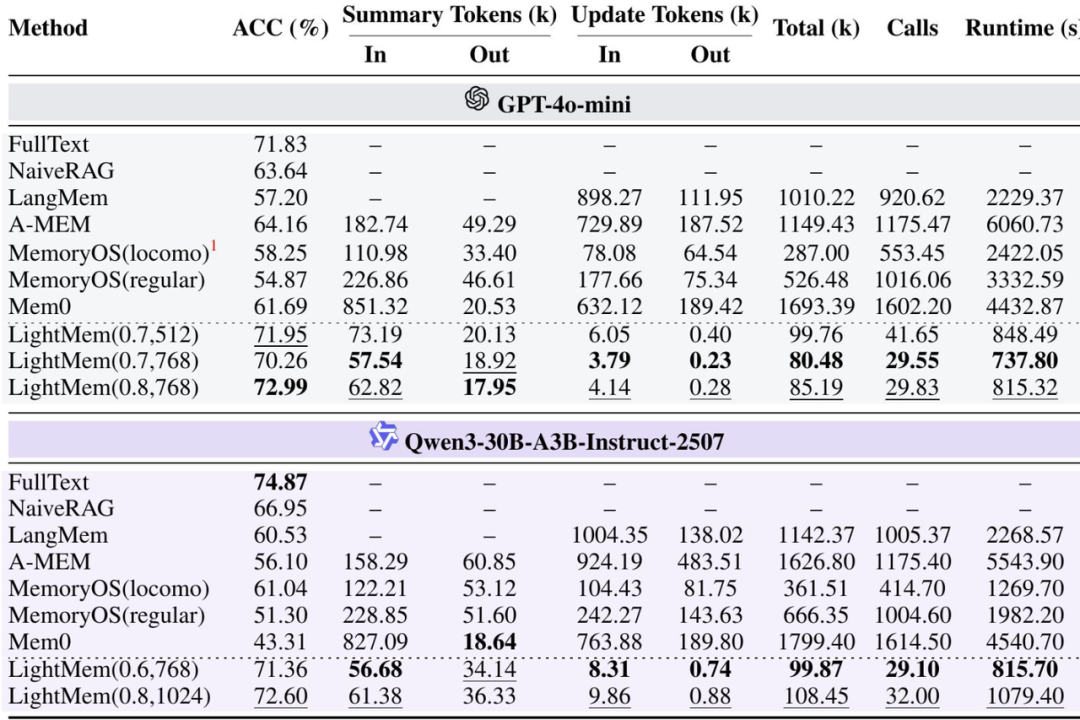
别光听概念,看看论文里的实测数据(对比 GPT-4o 和 Qwen):
- 更聪明了:相比最强基线(如 A-MEM,Mem0), QA 准确率提提升了7.7% 到 29.3%。
- Token 省疯了:总 Token 消耗量减少了20倍 到 38倍!原来花 100 块钱的 Token,现在只要 3 块钱。
- API 调用少了:它是批量处理的,API 调用次数减少了30倍 到 55倍。
- 纯在线推理成本:如果只看在线测试阶段,Token 减少高达106倍,API 调用减少159倍。
这不仅仅是“优化”,这是数量级的跨越。
论文评测集效果对比
04 产品反思
作为AI产品经理,LightMem 给我们的启示远不止技术架构:
重新定义“实时性”
我们真的需要 AI 实时整理好所有记忆吗?LightMem 证明了:不需要。
我们在做产品时,完全可以设计“异步记忆”体验。比如,你的 AI 伴侣可以说:“今天聊得好开心,我晚上回味一下。”第二天它变得更懂你了。这种拟人化的“睡眠”设定,既掩盖了技术边界,又增加了情感厚度。
商业模式的转折点
之前做长程记忆 Agent,最大的痛点是“越聊越贵”。随着对话历史增加,成本是线性甚至指数级增长的。
LightMem 把成本降低了 38 倍,意味着“伴随用户一生的 AI” 在商业成本上终于变得可行了。个性化AI(Personal AI )的时代可能真的要来了。
“大小模型”的黄金搭档
LightMem 的架构再次印证了一个趋势:端云协同。
- 端侧用小模型做“感官过滤”(去噪、切分话题)。
- 云端用大模型做“深度思考”和“记忆整合”。
- 这比把所有压力都给 GPT要聪明得多。
写在最后
AI 不仅需要更强的大脑,更需要更聪明的记忆机制。
LightMem 告诉我们:有时候,学会“遗忘”和“休息”,学会“断舍离”,是为了更好地“记住”。
参考来源:
LightMem:Lightweight and Efficient Memory-Augmented Generation. arXiv:2510.18866.
本文由 @杰克说AI 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


