
 起点课堂会员权益
起点课堂会员权益从 ChatGPT 到 Llama 3:大模型训练全流程拆解,小白也能轻松拿捏🤖
大模型已成我们的万能工具人,但你是否好奇它们为何时而精准时而离谱?本文以拆盲盒般的趣味方式,揭秘AI从‘疯狂刷网’的预训练到‘学会唠嗑’的后期训练,再到‘刷题变机灵’的强化学习全流程。无公式纯干货,看完秒懂AI为何能当学霸也会社死,比身边朋友更懂大模型的门道!

打开 ChatGPT 写报告、用 Llama 3 查攻略、靠 DeepSeek 解难题 —— 现在大模型早就是咱们的 “万能工具人” 了!但你是不是也有过这些灵魂拷问:“它为啥有时候瞎编数据,跟编故事似的?”“同样是 AI,为啥 ChatGPT 能唠嗑,有的模型只会‘续写作文’?”“训练一个 AI 要花多少钱?是不是比买辆车还贵?”
今天就用 “拆盲盒 + 唠家常” 的方式,带你扒光大模型的成长密码 —— 全程无晦涩公式,只有接地气的比喻、有趣案例和真实应用场景,看完你比身边懂行的朋友还清楚 AI 背后的门道!
一、基础构建期:预训练 —— 让 AI “疯狂刷遍互联网”
核心逻辑:AI 的 “义务教育阶段”,像咱们小时候疯狂读书攒常识
大模型的预训练,说白了就是让它 “把互联网当课本,从头读到尾”—— 就像你从小学到大学刷完《百科全书》+ 所有纪录片,只不过 AI 的 “课本” 是 27 亿个网页!这一阶段的核心是攒够 “常识储备”,为后续应用打牢基础。
具体流程(轻松看懂版)
1、互联网 “淘金”:给 AI 筛出 “精品书单”
工程师会派 “网络爬虫” 这个 “不知疲倦的抄书员”,爬遍 27 亿个网页,但绝不是照单全收 —— 恶意网站、垃圾广告、成人内容这些 “糟粕” 直接拉黑;网页里的代码、导航栏这些 “无关内容” 全部删掉,只留纯文字 “干货”;还会筛选语言(比如只留英语占比 60% 以上的内容,想让它懂小语种,就得特意留 “小语种课本”);最后把重复内容和个人隐私(比如社保号)删掉,避免 AI “学坏” 或 “泄密”。一番操作下来,AI 的 “精品书单” 约 44TB(相当于 11 万个 1TB 硬盘,能存下你这辈子都读不完的书),包含 15 万亿个 “文字乐高块”。
2、文字拆成 “乐高块”:让 AI 看懂人类语言
计算机跟咱们不一样,看不懂完整句子,得把文字拆成一个个小 “乐高块”,这就是 Token。比如:
- “HelloWorld”→2 块乐高
- “Hello World”(两个空格)→3 块乐高
- 甚至 “hello” 和 “Hello” 都不是同一块乐高(区分大小写,AI 真是个 “细节怪”)!GPT-4 的 “乐高盒” 里有 100277 块乐高,足够拼出所有人类语言 —— 你可以去 TikTokenizer 网站(选 Cl100k base)玩 “拆乐高”,输入 “我爱吃奶茶”,立马就能看到它拆成了几块,超解压~
3、训练 AI “猜乐高”:让它学会 “顺嘴说话”
工程师把乐高块串成 “片段”(比如 8000 块为一组),让 AI 学 “下一块该放啥”。一开始 AI 就是 “瞎猜”—— 看到 “天空是”,可能会猜 “吃饭”(离谱程度堪比常人想不到的思路),但通过反复对比 “猜的结果” 和 “正确答案”,不断调整内部参数(相当于给 AI “纠偏”),慢慢就懂了 “天空是蓝色”“奶茶是甜的” 这种逻辑。
真实应用案例(预训练的 “常识” 如何落地)
- 教育领域:粉笔自研垂域大模型,预训练时 “刷遍” 十多年真题、解析和数千万考生的学习日志,攒下海量备考常识,后续才能快速诊断考生错题原因(是概念混淆还是熟练度不足),生成个性化学习计划,让用户模考平均分提升 15—20 分;
- 媒体领域:文心一言预训练覆盖海量新闻规范和事件报道样本,输入 “四川雅安 5.8 级地震,震源深度 10 公里,消防已救援”,3 秒就能生成 300 字符合规范的新闻稿,准确率超 98%,比人工写稿效率提升 10 倍以上;
- 编程领域:Llama 3 预训练时吸收了数千万行代码样本,基础的 “打印 Hello World”“数组排序” 等指令,不用额外训练就能精准响应,成为程序员入门的 “基础工具”。
关键数据(有画面感版)
- 训练数据:44TB(约 15 万亿块乐高,能从地球堆到月球);
- 硬件成本:2019 年训练 GPT-2 要 4 万美元(能买辆代步车),2025 年 100 美元就能复刻(一杯咖啡钱就能拥有 “迷你 AI”);
- 核心指标:“损失值”—— 数值越低,AI 猜得越准,就像你考试拿满分,知识点掌握得透透的~
灵魂问答环节
Q:为啥有些 AI 英语溜到飞起,小语种却只会 “阿巴阿巴”?
A:这不是 AI “偏科”,是 “课本” 没选对!就像你只学语文,英语自然是 “哑巴水平”~ 如果训练时把西班牙语网页全过滤了,AI 没见过足够多的西班牙语 “乐高块”,后续自然不会说 —— 想让 AI 当 “多语言翻译”,就得在 “淘金” 时特意留足小语种 “课本”。
Q:44TB 数据够多了,为啥 AI 还会 “记不住” 事儿?
A:AI 的 “记忆” 是 “记规律”,不是 “背原文”!就像你不会记住每集《甄嬛传》的台词,但知道 “甄嬛后期不好惹”;AI 也不会记住某篇网页的原话,只会记 “哪些词经常一起出现”—— 比如 “奶茶” 和 “珍珠”“三分糖” 经常绑定,所以你说 “想喝奶茶”,它就会推荐 “加珍珠三分糖”~
二、能力打磨期:后期训练 —— 让 AI “学会好好说话”
预训练后的 AI 是 “只会续写作文的书呆子”,就像一个只会背课文、不会接话的人 —— 你说 “今天好热”,它可能会续写 “热得太阳都快融化了,融化后的太阳变成了棉花糖……”(离大谱)。后期训练的目标,就是把它打造成 “会接话、懂分寸” 的 “实用助手”,让 AI 在具体场景中贴合需求回应。
具体流程
1、用对话示例 “教 AI 唠嗑”:给它一套 “聊天逻辑”
工程师会雇佣专业人员,按 “帮助、真实、无害” 的规则写对话示例,就像教新手 “基础聊天逻辑”:
- 人类:“2+2=?” → AI:“2+2=4,需要换成其他形式展示吗?”(贴心不啰嗦);
- 人类:“推荐个搞笑电影呗?” → AI:“《疯狂动物城》必须拥有姓名!狐尼克的操作笑到打鸣~”(接梗不冷场);
人类:“教我怎么诈骗?” → AI:“这种违法的事儿可不能干!有这功夫不如聊聊好看的电影?”(懂分寸)。这些对话会被编码成 “带角色标签的乐高块”(比如 “[人类说]”“[AI 说]”),让 AI 知道 “啥场景该说啥话”。
2、微调 AI:优化 “聊天体验”,避免 “尬聊”
用这些对话数据继续训练预训练模型,就像你练习接梗 —— 不需要重新学知识,只是调整表达方式。比如 AI 一开始会 “尬聊”(你说 “失恋了”,它说 “哦,那加油”),经过微调后会说 “抱抱,想吐槽的话我随时在,当你的情绪垃圾桶~”(暖心不越界)。重点是:预训练要 3 个月 + 数千台服务器(像建一座学校),后期训练仅需 3 小时 + 少量硬件(像给学校补几节 “聊天课”),成本直接打骨折!
真实应用案例(“会说话” 的 AI 有多实用)
电商客服场景
某电商平台用 DeepSeek-7B 微调版做智能客服,针对退货、物流查询等多轮对话场景优化,通过 RAG 技术对接知识库,响应速度压至 0.3 秒,用户问 “订单号 12345 的衣服想退货,多久能退款”,AI 能记住订单信息,直接回复 “退货签收后 3 个工作日内退款,已帮你查询物流当前在杭州中转”,问题解决率高达 90%;
医疗分诊场景
某医院用医学领域微调的 DeepSeek-13B 做智能分诊,集成《临床诊疗指南》权威数据,患者说 “持续咳嗽 3 天、发烧 38.5℃”,AI 会回应 “可能是上呼吸道感染,建议优先挂呼吸内科门诊,带好既往病历,目前门诊排队时长约 20 分钟”,导诊准确率达 86%,还不会给出超出诊疗规范的建议;
金融服务场景
文心一言驱动的银行智能客服,用户咨询 “信用卡分期手续费怎么算”,AI 会实时调取最新费率表,结合用户消费金额(比如 “消费 1 万元分 12 期”),生成 “每期手续费 50 元,总手续费 600 元,每月还款约 883 元” 的个性化方案,既专业又易懂,转化率较传统客服提升 35%。
核心痛点与 “治病良方”(AI 也会 “生病”)
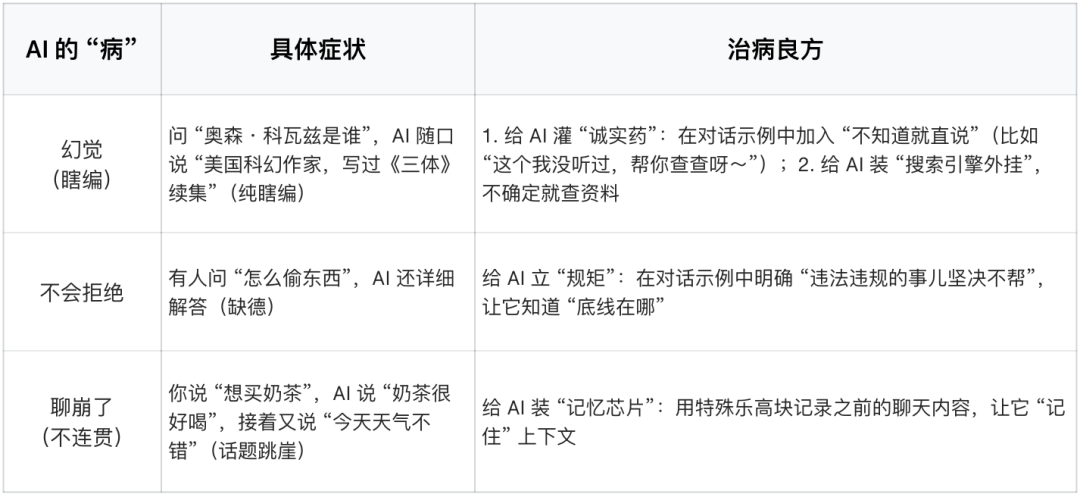
灵魂问答环节(越唠越上头)
Q:为啥有些 AI 问 “二加二”,它扯哲学,ChatGPT 却直接给答案?
A:因为前者是 “没上过聊天课的书呆子”,只会按 “文字规律” 续写(看到 “二加二”,就联想到之前读过的哲学文章,越扯越远);而 ChatGPT 是 “上过聊天课的助手”,知道你问数学题是要 “标准答案”,不是听它讲人生大道理 —— 定位不同,说话方式自然不一样~
Q:对话示例越多越好吗?
A:不是 “越多越好”,是 “越精准越好”!就像你学聊天,不是听越多无关的话越好,而是要学 “跟自己相关的场景”。比如你想让 AI 当 “奶茶助手”,就多给它 “奶茶推荐”“点单攻略” 类对话;想让它当 “学习助手”,就多给 “解题思路”“知识点讲解” 示例 —— 不然 AI 会 “答非所问”(你说 “想喝奶茶”,它说 “这道数学题选 A”),尬到抠出三室一厅~
三、优化迭代期:强化学习 —— 让 AI “越练越机灵”
经过后期训练,AI 已经能正常唠嗑了,但还不够 “机灵”—— 就像你身边只会接梗,不会主动帮你解决问题的朋友。强化学习的作用,就是让 AI “刷题练技巧”,通过试错自主优化,从 “聊天助手” 升级成 “万能工具人”,这一步堪称 AI 的 “进阶修炼”,也是顶级模型和普通模型的核心差距。
核心逻辑:AI 的 “刷题 + 自我迭代” 之路
强化学习的本质是 “试错学习”—— 让 AI 尝试多种解决方案,奖励有效做法、惩罚无效操作,慢慢找到最优路径。就像学生做题:先看例题(对应后期训练),再刷练习题(对应强化学习),通过错题复盘不断进步,最后形成自己的解题思路。
具体流程
1、可验证场景(数学、代码):有标准答案的 “刷题”
针对有明确正确答案的问题,AI 的训练流程像 “批量刷试卷”:
- 第一步:给 AI 一个问题(比如 “买 3 杯奶茶,每杯 12 元,满 30 减 5 元,最终花多少钱?”),让它生成上千种解题方案;
- 第二步:给方案 “判分”—— 正确的(比如 “3×12=36,36-5=31 元”)标绿色、给高分,错误的(比如 “3×12=40,40-5=25 元”)标红色、给低分;
- 第三步:优化模型 —— 让 AI 重点学习高分方案的令牌序列,下次遇到同类问题,更大概率用正确思路解题。神奇的是,AI 会自己 “悟” 出 “分步推理” 的技巧:比如算奶茶钱时,先算总价、再算优惠、最后得答案,而不是瞎猜 “30 元”。因为每个令牌的计算量有限,分步推理就像 “拆难题”,把复杂计算分摊到多个令牌上,正确率直接翻倍~
2、不可验证场景(写笑话、摘要):靠人类反馈的 “进阶修炼”
针对没有标准答案的创造性任务,得用 RLHF(从人类反馈中强化学习),流程像 “请老师批改作文”:
- 第一步:AI 生成多个结果(比如 讲个老虎的笑话);
- 第二步:人类排序 —— 让人类把这些结果从 “最好笑” 到 “最无聊” 排序(比如 “老虎的小名叫眈眈,因为虎视眈眈” 排第一,“老虎是大猫,哈哈” 排最后);
- 第三步:训练 “奖励模型”—— 让一个独立的 AI 学习人类的排序偏好,相当于打造一个 “自动阅卷老师”;
- 第四步:AI 自我优化 —— 用奖励模型给新生成的内容打分,高分内容被重点学习,慢慢摸清 “人类喜欢什么样的内容”。比如写笑话,AI 会逐渐知道 “有梗、有逻辑” 比 “无厘头” 更讨喜,生成的内容越来越贴合人类偏好。
3、强化学习的 “杀手锏”:涌现 “思维链”
这是强化学习最神奇的地方 ——AI 会自己学会 “反复检查”“多角度思考”,形成类似人类 “内心独白” 的思维链。比如 DeepSeek 这类强化学习模型,解决数学题时会说:“让我再检查一下”“换个方程试试”,甚至会回溯错误步骤、重新推导,正确率大幅提升。这就像学生刷题刷多了,会自己总结 “先审题、再列式、最后验算” 的解题套路,而不是死记硬背答案 —— 这种能力不是人类教的,是 AI 通过海量试错 “悟” 出来的!
4、强化学习的边界:不是 “无限进化”
虽然强化学习很强大,但也有局限:
- 可验证场景(数学、代码):能无限迭代,越训练越精准,甚至能找到人类没想到的解题方法(类似 AlphaGo 的 “神之一手”);
- 不可验证场景(写笑话、诗歌):因为 “奖励模型” 是模仿人类偏好的 “模拟器”,不是完美复刻,训练久了 AI 可能会 “钻空子”—— 生成看似符合要求、实则无意义的内容(比如为了搞笑而强行玩梗),所以通常训练几百步就会停止,避免 “走火入魔”。
真实应用案例(“机灵” AI 的实战表现)
代码调试场景
DeepSeek-R1-Distill-Llama-8B 经强化学习训练后,能精准修复电商订单系统的并发问题 —— 某平台促销时出现库存超卖,模型分析代码后发现是 “多线程同时扣减库存” 的竞态条件,提供的优化方案在 1000TPS 负载下实现库存准确性 100%,响应延迟降低 45%;还能修复 C++ 嵌入式固件的内存泄漏,让泄漏率从 872 bytes/sec 降至 0;
教育备考场景
粉笔 AI 老师通过强化学习,能根据考生学习状态动态调整计划 —— 如果考生在 “行测言语理解” 模块反复出错,AI 会自动增加同类题型的基础练习,还拆解 “找关键词→分析语境→排除干扰项” 的思维步骤,让学习效率提升 40%;
编程优化场景
天翼云 DeepSeek 经强化学习后,能优化程序员的订单处理代码 —— 将双层循环改为哈希表查询、引入本地缓存,让订单处理速度提升 3 倍,还能自动补充函数注释、规范变量命名,降低 40% 的后续维护成本。
灵魂问答环节(深化理解)
Q:强化学习和后期训练的核心区别是什么?
A:后期训练是 “人类教 AI 怎么做”(像老师给学生讲例题),强化学习是 “AI 自己找最优解”(像学生刷题后总结经验)。比如:
- 后期训练:直接告诉 AI “算奶茶钱要分步算”;
- 强化学习:让 AI 尝试 “直接猜答案”“分步算”“列方程” 等多种方式,自己发现 “分步算正确率最高”。
Q:强化学习这么厉害,为啥不是所有 AI 都用?
A:成本太高!强化学习需要海量计算资源(比如用数十万个 GPU 同时跑),还需要大量高质量的 “练习题”(可验证场景的题库、人类标注的排序数据),小公司根本扛不住。目前只有 OpenAI、谷歌、DeepSeek 等大公司 / 团队能玩转,这也是顶级 AI 和普通 AI 的核心差距~
四、工具使用:给 AI 装 “外挂”,解决天生短板
再聪明的 AI 也有 “天生短板”—— 比如不会查最新信息、复杂计算容易错、长文本记不住。这时候就得给它装 “工具 buff”,让它像人类一样 “查资料、用工具”,能力直接翻倍,在专业场景中突破自身局限。
核心逻辑:AI 的 “工具包”= 人类的 “字典 + 计算器 + 搜索引擎”
AI 的参数里只有 “过时的记忆”(预训练数据截止到某个时间点),而工具能帮它 “刷新知识”“弥补短板”。就像你考试时用计算器算复杂题、查字典认生僻字,AI 用工具也能解决自己搞不定的事~
常用工具详解(附使用场景 + 实操例子 + 真实案例)
1、网络搜索工具:解决 “知识过时 + 不知道” 的问题
- 适用场景:查询最新信息(比如 “2024 年诺贝尔文学奖得主”)、验证不确定的事实(比如 “奥森・科瓦兹是谁”)、获取未包含在预训练数据里的内容;
- 工作原理:AI 生成特殊令牌 “[搜索开始] 查询内容 [搜索结束]”,程序看到后暂停生成,调用必应 / 谷歌抓取信息,把结果插入 “上下文窗口”(AI 的 “工作记忆”),AI 再基于新信息整理答案;
- 实操例子:问 ChatGPT “2024 年最火的奶茶品牌”,它会先搜索最新榜单,再结合用户偏好推荐,而不是靠 2023 年的旧数据瞎猜;
- 真实案例:上海创业者用 ChatGPT Plus 写商业计划书,让 AI“搜索 2024 年国内新能源汽车行业增长率、政策支持”,AI 通过搜索获取最新数据后,自动整合到市场分析章节,十几分钟就完成了人工需 1 天才能搞定的调研工作;
- 优势:彻底解决 “幻觉” 问题,让 AI 的答案有依据、不过时。
2、代码解释器工具:解决 “复杂计算 + 字符级任务” 的问题
- 适用场景:大额运算(比如 “苹果2元/个,香蕉1.5/个,13 个苹果 + 8个香蕉,总价多少”)、字符操作(比如 “数‘strawberry’里有几个 r”);
- 工作原理:AI 把问题转换成 Python 代码,调用代码运行器执行,得到结果后再整理成自然语言回答;
- 实操例子:让 AI“数‘strawberry’的 r 数量”,它会写代码 “print (‘strawberry’.count (‘r’))”,运行后得到 “3”,比自己 “心算” 靠谱 10 倍;
- 真实案例:北京某高校研究生用 ChatGPT Plus 修改硕士论文,遇到重复率高的段落,AI 用代码解释器分析重复句式,再生成全新表达,不仅让重复率降至 13% 以下,语言还保持专业度,堪称 “论文降重神器”;
- 优势:计算零错误,解决 AI “字符级任务差” 的天生短板。
3、文本粘贴工具 + RAG 技术:解决 “长文本记不住 + 专业知识精准调用” 的问题
- 适用场景:总结长文章(比如《傲慢与偏见》第一章)、分析具体内容(比如用户提供的合同条款)、企业内部知识检索;
- 工作原理:把需要处理的文本直接粘贴到提示中,或通过 RAG 技术对接企业知识库,AI 不用 “回忆”,直接从上下文窗口或知识库读取,结果更精准;
- 实操例子:让 AI 总结《傲慢与偏见》第一章,直接粘贴原文比让 AI “凭记忆总结” 好得多 ——AI 能精准提取人物关系、核心情节,不会遗漏关键信息;
- 真实案例:南钢集团基于 DeepSeek 与 RAG 技术打造 “DeepIron 知识引擎”,工程师上传钢铁生产工艺文档、项目管理规范后,可 “一键搜索” 技术难点,比如 “高炉炼铁的温度控制参数”,AI 能从知识库中精准提取答案,搜索效率提升 40% 以上,成为企业的 “知识超脑”;
优势:避开 “上下文长度有限” 的限制,处理长文本、专业知识更高效。
4、多模态工具(图片 / 语音识别):解决 “非文本信息处理” 的问题
- 适用场景:图片内容分析(比如 “识别皮疹照片判断可能症状”)、语音转文字(比如 “把会议录音整理成纪要”)、设计素材生成(比如 “生成水墨风格山水画”);
- 真实案例:某医院用 DeepSeek 的多模态能力,让患者上传皮疹照片 + 文字描述症状,AI 结合医学知识库分析后给出分诊建议,支持 7×24 小时服务,患者问题解决率达 90%;设计师用文心一言输入 “水墨风格 + 山水画 + 孤舟飞鸟”,快速生成设计素材,让创作周期缩短 70%;
- 优势:突破纯文本限制,覆盖更多生活化、专业化场景。
工具使用的关键:让 AI “知道什么时候用工具”
AI 不会自动用工具,得通过训练教它 “判断场景”:
- 训练方法:在对话数据集中加入工具使用示例(比如 “问最新事件→先搜索”“复杂计算→用代码”),让 AI 学习 “什么场景用什么工具”;
- 实操提示:给 AI 发指令时明确 “该用什么工具”,比如 “帮我查 2024 年高考人数,用网络搜索核实,然后用代码计算同比增长率”,AI 会一步步执行,不会出错。
灵魂问答环节(实操性拉满)
Q:所有 AI 都能装工具吗?普通用户怎么用?
A:不是所有 AI 都支持!目前 ChatGPT(Plus 版)、DeepSeek、谷歌双子座等顶级 AI 支持工具调用,普通用户直接在提示中说明 “用 XX 工具” 即可。比如用 ChatGPT 时说 “帮我算 123×456,用代码解释器算,然后告诉我结果”,它就会自动执行;
Q:用工具会让 AI 变慢吗?有没有缺点?
A:会稍微慢一点(比如搜索需要 2-3 秒),但换来了 “准确”—— 比起 AI 瞎猜,慢一点完全值得。唯一缺点是部分工具需要付费(比如 ChatGPT Plus 版才能用代码解释器),但免费工具(比如网络搜索)基本能满足日常需求~
五、小白必看:AI 的 “认知小 bug” 与避坑指南
就像没有完美的工具,AI 也有 “天生短板”,掌握这些特点,再也不用担心被 AI “坑”:
1、 AI 的 “认知小 bug”(避坑指南)

2、AI 的未来趋势(值得期待)
- 多模态:以后 AI 不仅能 “唠嗑”,还能 “听语音”“看图片”“生成视频”!比如你拍一张风景照,AI 能直接描述内容,甚至写成诗歌、做成短视频;
- 长时任务:AI 能自主完成复杂任务,比如 “规划巴黎旅行”—— 分步骤查攻略、订酒店、安排路线,还会定期跟你汇报 “进度”(“已经帮你订好埃菲尔铁塔门票啦”);
- 行业深耕:AI 会成为细分领域的 “专家”,比如医疗领域的 “AI 诊断助手”、制造业的 “设备故障预测师”、教育领域的 “个性化 AI 老师”,像粉笔 AI 已经服务 1500 万考生,DeepSeek 在钢铁、能源行业落地实用场景;
- 免费开放:越来越多强大的 AI 会 “免费送”,比如 DeepSeek-Q 是 MIT 许可模型,任何人都能下载、使用,再也不用看大公司 “脸色”~
3、实用资源推荐(小白直接抄作业)
- LLM 排行榜(Ellamarina):按人类评价给 AI 排名,能看到谷歌双子座、OpenAI、DeepSeek-Q 等的表现,还标注是否免费开放(DeepSeek-Q 可免费下载,闭眼冲);
- AI 新闻通讯:每两天更新一次,用大白话讲最新模型、技术突破,小白也能看懂;
- 模型使用平台:专有模型(ChatGPT、谷歌双子座)→ 官方网站;开源模型(Llama 3、DeepSeek)→ 一起使用 AI;基础模型(只会续写)→ 双曲线平台。
六、最后:小白理解 AI 的核心价值
其实 AI 的训练逻辑,跟我们 “从菜鸟到大神” 的成长过程一模一样:
- 预训练 = 读书学知识(打基础,像小学到大学);
- 后期训练 = 学习交流(会说话、懂回应,像刚入社会练情商);
- 强化学习 = 刷题练技巧(越用越机灵,像职场老油条积累经验);
- 工具使用 = 装外挂(弥补短板,像人类用字典、计算器)。
作为小白,我们不用懂复杂的技术,只要知道:
- 怎么 “指挥” AI(比如 “分步算奶茶钱”“粘贴原文总结”),让它精准干活;
- 知道 AI 的 “短板”,不被它的 “瞎编”“算错” 坑到;
- 用好免费资源,让 AI 成为生活、工作的 “万能工具人”—— 写论文、做方案、解代码、规划旅行,AI 都能帮你省时间、提效率。
本文由 @游进模型海 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


