
 起点课堂会员权益
起点课堂会员权益我搭了一个智能体,帮你”魂穿”体验另一个人的一天!
如何真正理解他人的生活?这款名为'魂穿:体验TA的一天'的智能体给出了全新答案。通过AI模拟不同角色的完整一天,在5-8个关键决策点做出选择,用户能沉浸式体验外卖员、历史人物甚至3岁孩童的日常生活。本文将深度拆解这个基于工作流架构的LLM应用,揭秘其人物解析、决策循环与复盘总结三大核心模块的技术实现。

你有没有想过,真正理解另一个人是什么感受?
不是站在外面观察,而是真正”成为”他们——感受他们的疲惫、他们的纠结、他们的喜悦,体验他们一天中遇到的每一个关键决策。
这就是我最近搭建的智能体:”魂穿:体验TA的一天”。
这篇文章分享一下这个智能体的搭建过程,帮助大家了解一下工作流架构和LLM应用开发的玩法。
为什么做这个?
共情是人类最珍贵的能力之一,但也是最难培养的。
- 理解缺失:我们很容易站在自己的立场评判他人,却很难真正理解他们的处境和选择。
- 体验成本高:想要理解一个外卖员、一个3岁小孩、一个80岁老人的生活,现实中需要巨大的时间和机会成本。
- 沉浸感难营造:即使看过再多的纪录片、文章,也很难真正”代入”另一个人的视角。
所以我做了这个智能体:通过AI模拟另一个人完整的一天,让你在5-8个关键决策点做出选择,体验每个选择带来的连锁反应,最后获得一天的总结和决策复盘。
它不想取代真实的体验,而是把体验的门槛降低——让你能够低成本、低风险地”穿越”到不同身份、不同时代的人身上。
智能体的体验链接在文章最后。
定位&整体交互
产品定位
目标用户:想要理解不同群体的人、对历史和人物感兴趣的用户、教育工作者、想要提升共情能力的人
核心价值:通过AI模拟生成沉浸式的身份体验,让用户在决策中理解另一个人的处境和选择逻辑
能力边界:
- 支持现代角色(外卖员、清洁工、3岁小孩、80岁老人等)
- 支持历史人物(乾隆皇帝、诸葛亮、李白等)
- 支持复合身份(大城市的5岁男童、旅居的自由职业者等)
- 每次体验包含5-8个关键决策点,完整的一天流程
整体交互设计
交互流程非常简单直观:
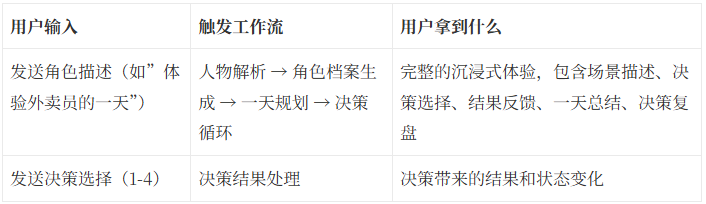
三个工作流协同
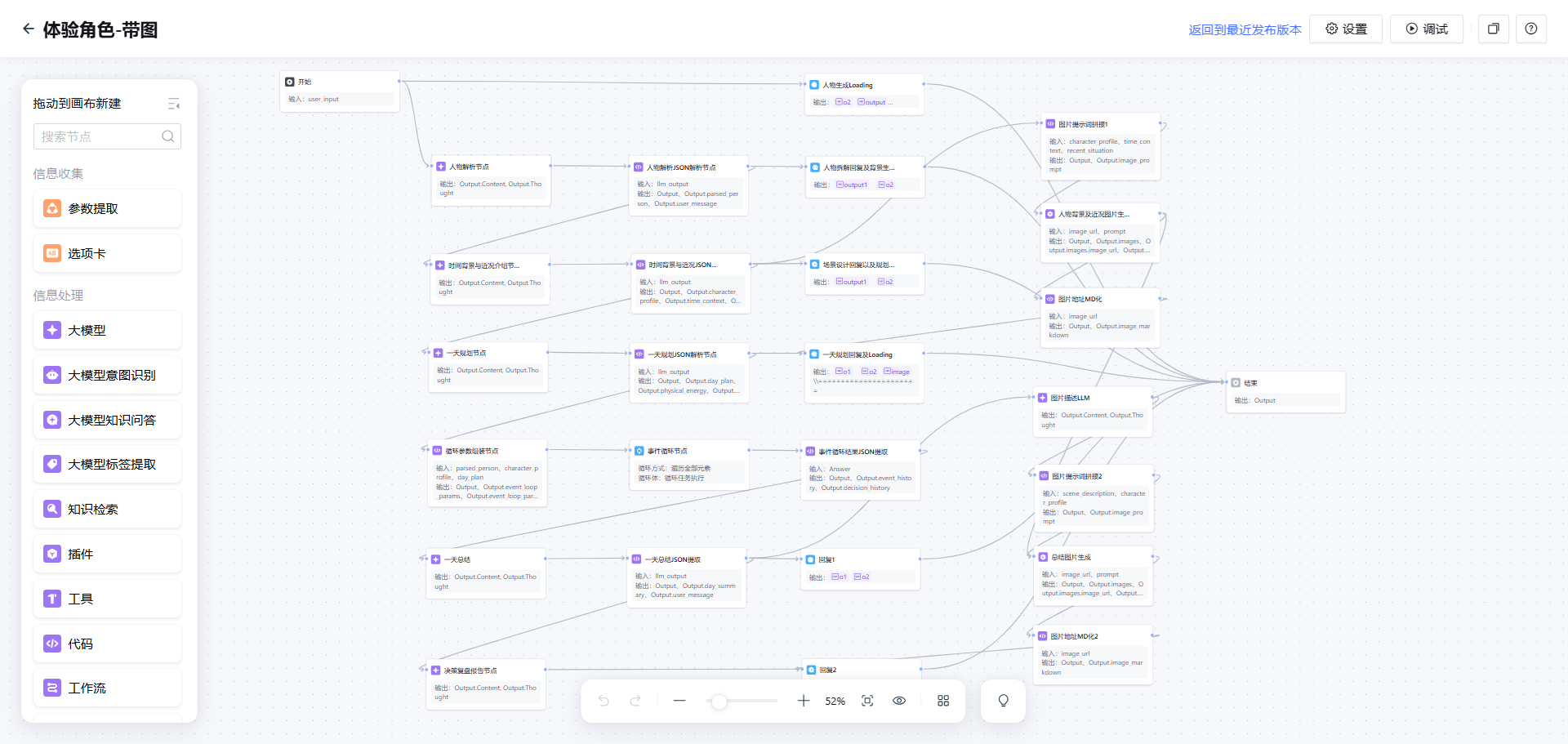
整个智能体基于工作流架构搭建,分为三个核心模块:
工作流1:人物解析与场景构建(主流程)
输入:用户想要体验的角色(如”体验外卖员的一天”)
处理流程:
1. 人物解析节点(LLM):识别人物类型和关键特征
- 判断是历史人物/岗位角色/年龄层角色/复合身份
- 提取年龄、职业、时代背景、生活状况等关键信息
2. 角色档案生成节点(LLM):生成详细的角色档案
- 设定时间背景
- 生成角色的基本信息、性格特点、近期状况
- 输出符合角色特征的描述
3. 一天规划节点(LLM):规划一天的事件序列
- 确定起床/睡觉时间
- 生成5-8个符合角色身份的关键事件
- 每个事件包含决策主题和场景设定
流程非常简单,一路走到底型:
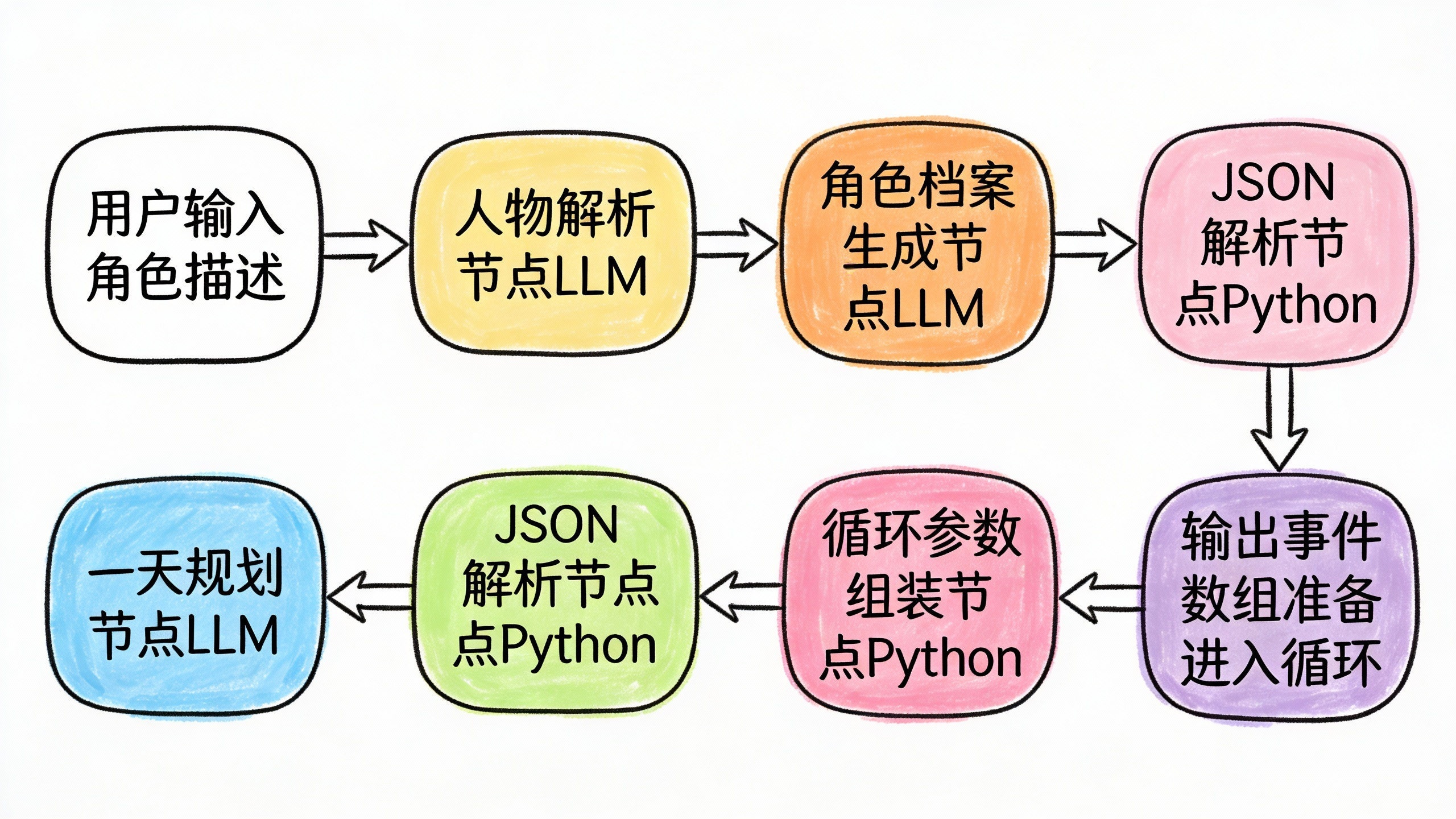
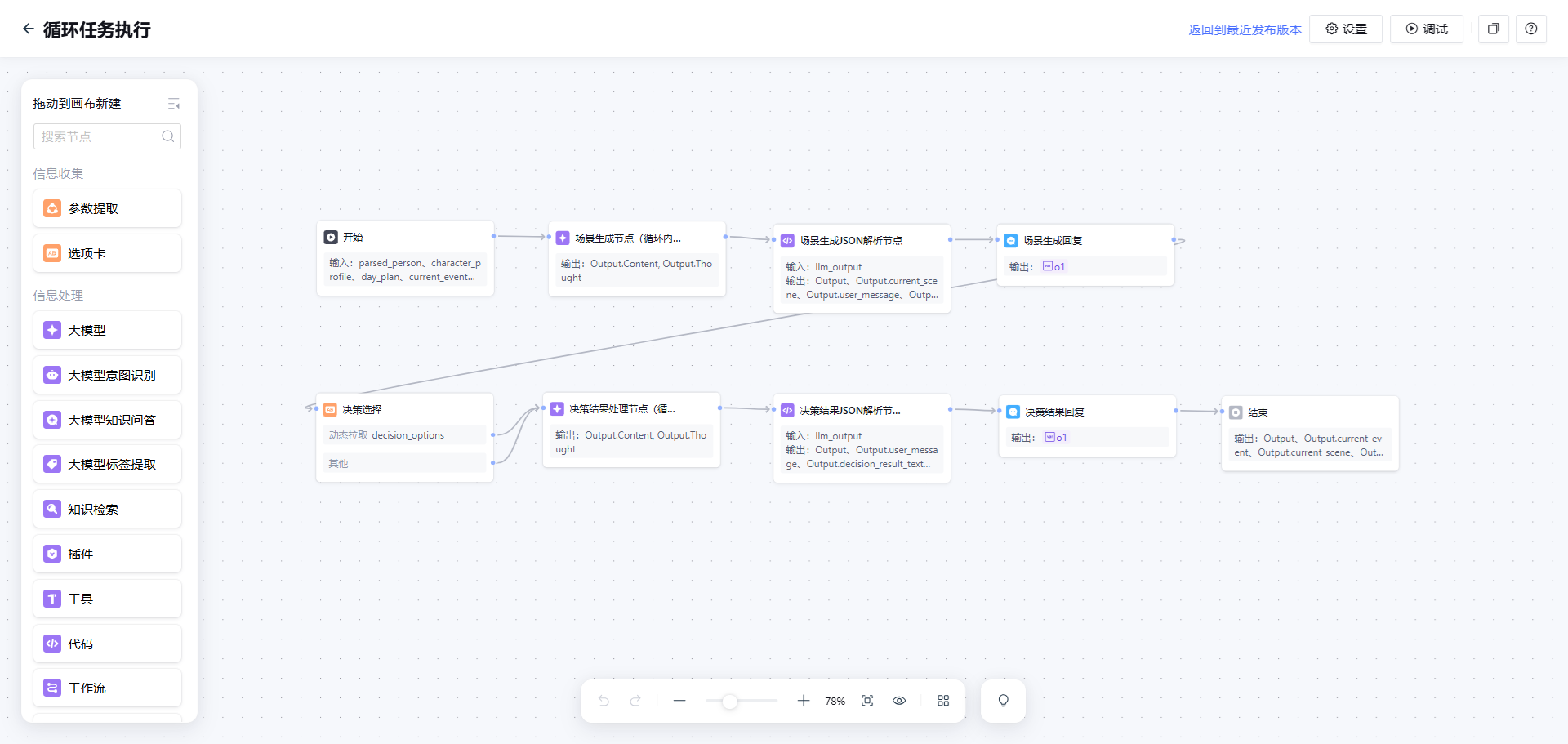
工作流2:决策循环(子流程,核心体验模块)
输入:单个事件对象(包含时间、地点、事件描述、决策主题等)
这是整个体验的核心,通过循环节点调用这个子工作流。
子工作流的处理逻辑:
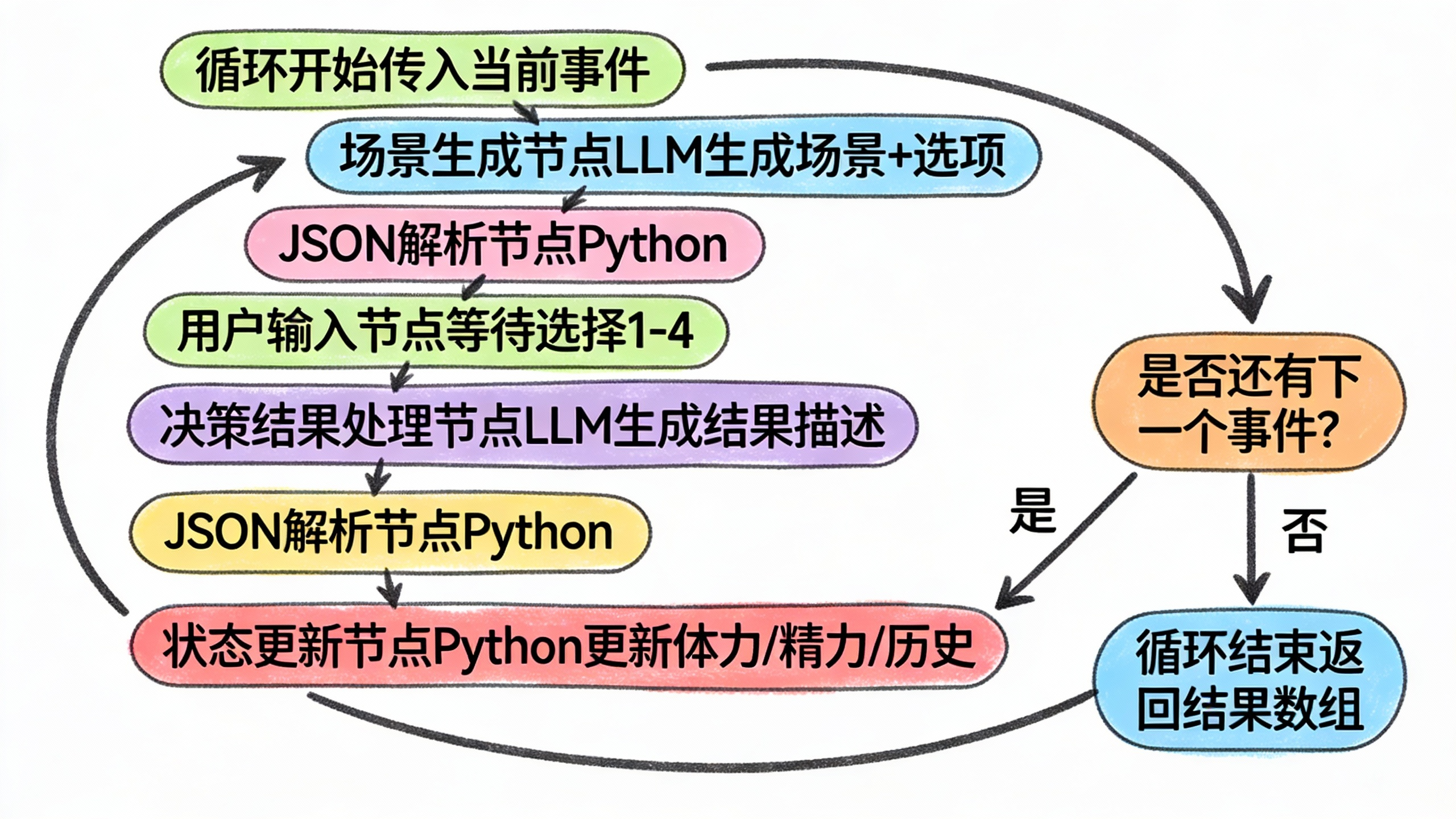
这个工作流会被循环调用5-8次,每次处理一个事件。
关键技术点:
1. 状态管理:状态完全在循环体内管理
- 第一次循环时,初始化状态(体力=100,精力=100)
- 每次循环结束后,状态在状态更新节点中更新
- 更新后的状态通过输出变量传递给下一个循环
- 循环结束后,最终状态传递给总结节点
2. 场景生成的沉浸感:
- 使用第一人称描述(”我蹲在…””我跨上电动车…”)
- 场景描述包含时间、地点、环境细节
- 内心思考部分使用” 我在想”来增强代入感
3. 决策选项的设计:
- 每个决策点提供4个选项
- 选项要符合角色身份和处境
- 选项之间有明显的利弊权衡,不存在”完美答案”
- 选项直接嵌入在user_message中,用序号(1. 2. 3. 4.)标记
4. 结果描述的自然过渡:
- 使用”—“分隔线区分场景和结果
- 使用”### 然后”作为口语化的标题,自然地开始描述
- 避免系统化的表述(如”我选择了…”),保持故事的流畅性
- 不包含具体时间点,只描述决策带来的结果
工作流3:总结与复盘
当所有决策循环完成后,进入总结阶段:
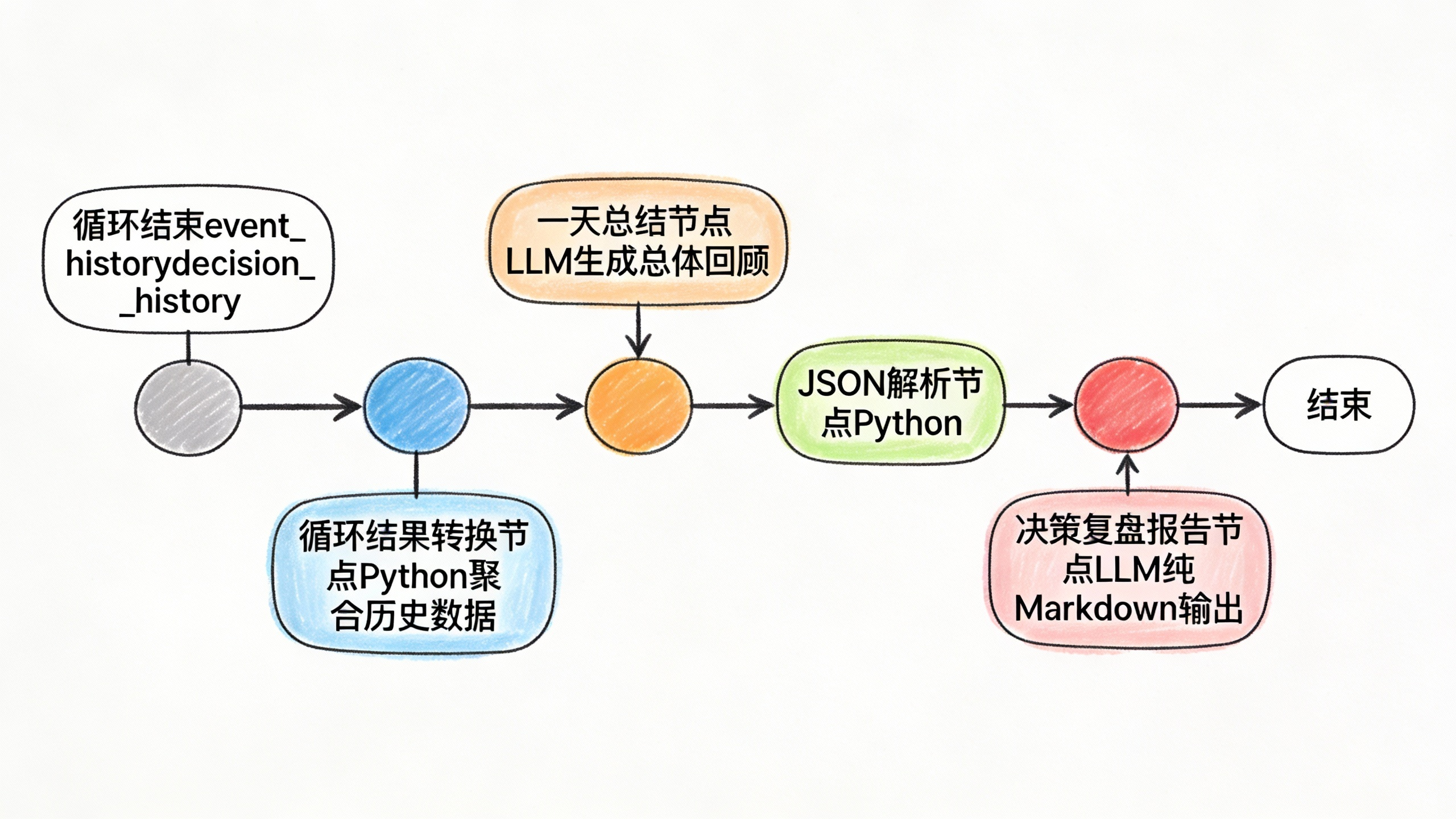
1. 一天总结节点(LLM):
- 生成”### 这一天就这样过去了”等口语化的标题
- 包含” 总体回顾”和” 主观感受”两个部分
- 总结一天的体力/精力消耗、关键事件、整体感受
2. 决策复盘报告节点(LLM):
- 决策回顾 (50-100字):回顾当时的情况和决策逻辑
- 未来影响 (100-150字):预测这个决策在未来可能产生的影响
- 对每个决策点进行复盘分析
- 每个决策包含:
- 使用纯Markdown格式输出,确保格式渲染正确
技术实现细节
接下来逐个功能点拆分。
1. LLM节点与JSON解析的配合
整个工作流中,大部分LLM节点输出JSON格式:
{
“user_message”: “用户看到的内容(Markdown格式)”,
“context_data”: {
// 后续节点需要的结构化数据
}
}
每个LLM节点后都跟着一个Python代码节点来解析JSON,提取context_data供后续节点使用,同时提取user_message用于展示给用户。
关键设计:user_message必须是对当前步骤执行结果的概括,而不是”正在处理”等过程性提示,这样用户能实时看到进度。
JSON解析节点的通用代码:
import json
import re
def main(params: dict) -> dict:
input_str = params.get(‘llm_output’) or params.get(‘input’, ”)
if not input_str:
return {}
# 处理可能被markdown代码块包裹的情况
input_str = re.sub(r’^“`json\s*’, ”, input_str, flags=re.MULTILINE)
input_str = re.sub(r’“`\s*$’, ”, input_str, flags=re.MULTILINE)
input_str = input_str.strip()
try:
parsed_data = json.loads(input_str)
context_data = parsed_data.get(‘context_data’, {})
user_message = parsed_data.get(‘user_message’, ”)
return {
‘context_data’: context_data,
‘user_message’: user_message
}
except json.JSONDecodeError:
return {}
这里有三个细节,需要做到位:
- 处理可能被markdown代码块包裹的JSON(去除“`json标记)
- JSON解析失败时的降级处理(返回空字典)
- 确保提取的字段都有默认值,避免后续节点报错
2. 循环节点的状态传递
循环节点的设计,本质上是让你用工作流构造一个”工具插件”,循环调用、处理事件。
关键设计:状态完全在循环体内管理,不依赖循环体外的全局变量。
状态管理方式:
- 第一次循环时,在循环开始节点初始化状态(体力=100,精力=100,历史记录为空)
- 每次循环结束后,状态在状态更新节点中更新
- 更新后的状态通过输出变量(previous_physical_energy、previous_event_history等)传递给下一个循环
- 循环结束后,最终状态会传递给总结节点
循环参数组装节点的代码:
def main(params: dict) -> dict:
parsed_person = params.get(‘parsed_person’, {})
character_profile = params.get(‘character_profile’, {})
day_plan = params.get(‘day_plan’, {})
# 从day_plan中获取事件列表,数组长度即为循环次数
events = day_plan.get(‘events’, [])
# 组装循环参数数组(只包含静态参数,不包含动态状态)
event_loop_params = []
for i in range(len(events)):
loop_param = {
‘parsed_person’: parsed_person,
‘character_profile’: character_profile,
‘day_plan’: day_plan,
‘current_event’: events[i],
‘current_event_index’: i
}
event_loop_params.append(loop_param)
return {‘event_loop_params’: event_loop_params}
循环结束后,通过代码节点将循环的返回结果(数组)转换为event_history和decision_history:
def main(params: dict) -> dict:
# 获取循环返回的数组,支持多种可能的字段名
answer_data = params.get(‘Results’) or params.get(‘Answer’) or params.get(‘loop_output’, [])
event_history = []
decision_history = []
for item in answer_data:
# 提取事件信息和决策信息,组装成event_history和decision_history
# …
return {
‘event_history’: event_history,
‘decision_history’: decision_history
}
3. Markdown格式的严格控制
为了确保前端能够正确渲染,所有LLM节点的输出都严格遵循Markdown格式规范:
- 标题格式 使用###
- 粗体文本 使用**文本**
- 列表 使用-或数字列表
- 分隔线 使用—
特别注意的是,节点7(决策复盘报告)直接输出纯Markdown文本,而不是JSON包装,这样可以避免JSON转义导致的Markdown渲染问题。
4. 提示词工程的精细化
每个LLM节点都有详细的提示词,包含:
- 角色设定:明确LLM扮演的角色(如”你是一个场景生成助手”)
- 输入说明:清晰说明输入变量的含义和格式
- 输出格式:严格要求输出格式,提供示例
- 风格要求:强调沉浸感、口语化、自然流畅等
场景生成节点的提示词关键部分:
角色信息:
{{parsed_person}}
角色档案:
{{character_profile}}
当前事件:
{{current_event}}
请生成一个生动的场景,要求:
1. 使用第一人称描述(”我蹲在…””我跨上电动车…”)
2. 场景描述要生动具体,包含时间、地点、环境细节(80-120字)
3. 内心思考要符合角色身份和处境,使用” 我在想”标记(50-100字)
4. 决策选项要有明显的利弊权衡,每个选项10-20字
5. 使用Markdown格式输出,包含三级标题和列表
请严格按照以下JSON格式返回:
{
“user_message”: “### [时间] ([时间段]) [地点]\n\n[场景描述]\n\n### 我在想\n\n[角色思考]\n\n### [决策问题]\n\n1. [选项1]\n2. [选项2]\n3. [选项3]\n4. [选项4]”,
“context_data”: {
“scene_context”: “…”,
“location”: “…”,
“decision_point”: {
“question”: “…”,
“options”: […]
}
}
}
关键点:
- 必须使用结构化输出(JSON格式),确保后续节点能正确解析
- 输出格式要严格规定,包含示例,避免模型自由发挥
- 风格要求要明确具体(第一人称、口语化、沉浸感等)
[配图建议6:可以展示场景生成节点的完整提示词,或者展示输出示例]
5. 错误处理与容错
代码节点中实现了完善的错误处理,确保流程不会因为数据格式问题中断。
JSON解析失败时的降级处理:
try:
parsed_data = json.loads(input_str)
context_data = parsed_data.get(‘context_data’, {})
except json.JSONDecodeError:
# 解析失败时返回空字典,而不是抛出异常
return {‘context_data’: {}}
数据格式不一致时的类型检查:
# 确保体力精力值在0-100范围内
updated_physical_energy = context_data.get(‘updated_physical_energy’, 100)
if isinstance(updated_physical_energy, str):
try:
updated_physical_energy = int(updated_physical_energy)
except ValueError:
updated_physical_energy = 100
updated_physical_energy = max(0, min(100, int(updated_physical_energy)))
循环返回结果的结构化解析,支持多种可能的字段名:
# 兼容不同的返回结构
answer_data = params.get(‘Results’) or params.get(‘Answer’) or params.get(‘loop_output’, [])
if not isinstance(answer_data, list):
if isinstance(answer_data, dict) and ‘Results’ in answer_data:
answer_data = answer_data[‘Results’]
else:
answer_data = []
实际效果展示




- 用户选择”体验韦小宝的一天”
- 生成的场景描述(包含时间、地点、场景、内心思考、4个选项)
- 用户选择某个选项后的结果反馈
- 最终的一天总结和决策复盘报告
体验一个完整流程后,用户能够:
- 理解外卖员面临的时间压力、体力消耗、经济压力
- 体验决策的复杂性(比如”安抚康熙还是天地会”的两难选择)
- 看到每个选择带来的短期和长期影响
- 获得共情和理解,而不是简单的同情
拓展和延伸
场景延伸
这个智能体的核心是基于LLM的场景生成和决策模拟能力。
类似的玩法可以延伸到:
- 教育场景:让学生体验历史人物的决策困境,理解历史事件的复杂性
- 职业规划:让求职者体验不同职业的真实工作场景
- 社会认知:帮助人们理解不同社会群体的生活状态
- 心理健康:通过体验他人的处境,培养共情能力
技术延伸
工作流架构的优势在于模块化和可扩展性:
- 知识库增强:可以为历史人物添加专门的知识库,提高场景生成的历史准确性
- 多分支剧情:可以根据不同的决策路径生成不同的后续事件,实现真正的分支剧情
- 状态系统扩展:可以增加更多状态维度(如经济状况、人际关系、情绪状态等),让体验更加丰富
- 多角色互动:可以支持多个角色的同时体验,模拟复杂的社交场景
关于智能体平台
搭建这个智能体使用的是工作流平台,它提供了完整的工作流搭建能力:
- 可视化工作流:通过拖拽节点就能搭建复杂的业务流程
- LLM节点:内置多种大模型,支持灵活的提示词工程
- 代码节点:支持Python代码,实现复杂的数据处理逻辑
- 循环节点:支持循环调用子工作流,实现批量处理
- 变量管理:完善的状态管理和变量传递机制
最关键的是,你可以把搭建好的智能体直接发布到小程序,不需要自己搞备案、买服务器,用户体验流畅,价值完全不同。
(主工作流)
(子工作流)
写在最后
这个智能体的核心价值不在于技术有多复杂,而在于它把”理解他人”这件事的门槛降低了。
通过AI模拟,我们可以在几十分钟内体验另一个人完整的一天,感受他们的处境和选择。这种体验虽然不能完全替代真实经历,但足以让我们获得宝贵的共情和理解。
如果你也想搭建类似的智能体,或者对技术实现细节感兴趣,欢迎交流。
体验链接:https://yuanqi.tencent.com/webim/?sessionid=#/chat/SgGAyd?appid=2003750988803319040&experience=true
欢迎体验”魂穿:体验TA的一天”,并反馈任何建议或BUG。
本文由 @崔峻 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Pexels,基于CC0协议






- 目前还没评论,等你发挥!


