
 起点课堂会员权益
起点课堂会员权益用AI打破信息壁垒,拒绝“私私私”
自媒体培训市场的水有多深?从2W+的速成课程到AI工具的信息采集,这篇文章揭露了知识付费背后的割韭菜套路,并提供了用AI工具构建个性化学习体系的实战方法。从批量信息采集到知识体系化,三步教你如何避开韭菜陷阱,打造真正有价值的学习路径。

前段时间,朋友报名了一个“自媒体运营”的课程,1个月共四个周末的集中培训,花费2W+,承诺”4周从0到1打造百万粉丝账号”,讲师有着闪亮的履历:某大厂运营总监、多个账号操盘手、年入百万千万。
但是据她所说,”这2万块钱,打了水漂。”课程内容在小红书、抖音都能搜到,而且讲的知识点特别浅,点到即止,什么’内容创作黄金公式’、’流量密码三板斧’,听着唬人,实际上就是’标题要吸引人’、’开头3秒抓眼球’这种车轱辘话。
他们是怎么割韭菜?
翻开小红书、知乎,到处都是”xx天精通xx”、”我靠这个方法月入5万”的帖子。点进去,前面讲两句虚的,关键内容一律”私私私”。这些博主精通的不是他们宣称的领域,而是”包装IP、制造焦虑、卖课变现”的流水线套路。
他们的逻辑很简单:
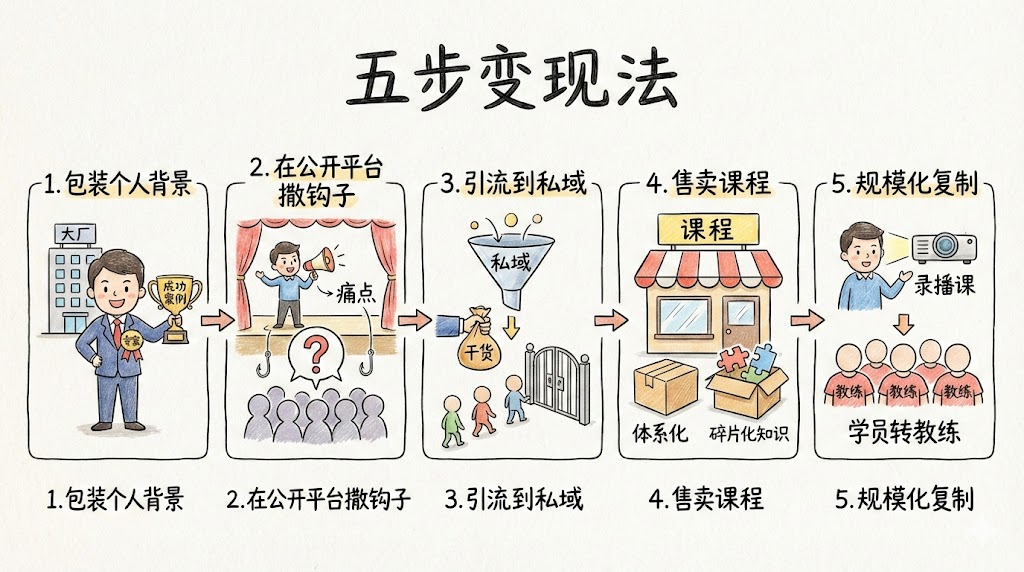
可问题是,为什么这套路还能一直奏效?为什么那么多人明知可能被割韭菜,还忍不住掏钱?
其实这类学员有2个核心的短板:
信息搜集能力不足
市面上信息碎片化、重复度高,很难体系化地学习;
当你搜索”如何做好自媒体运营”时:
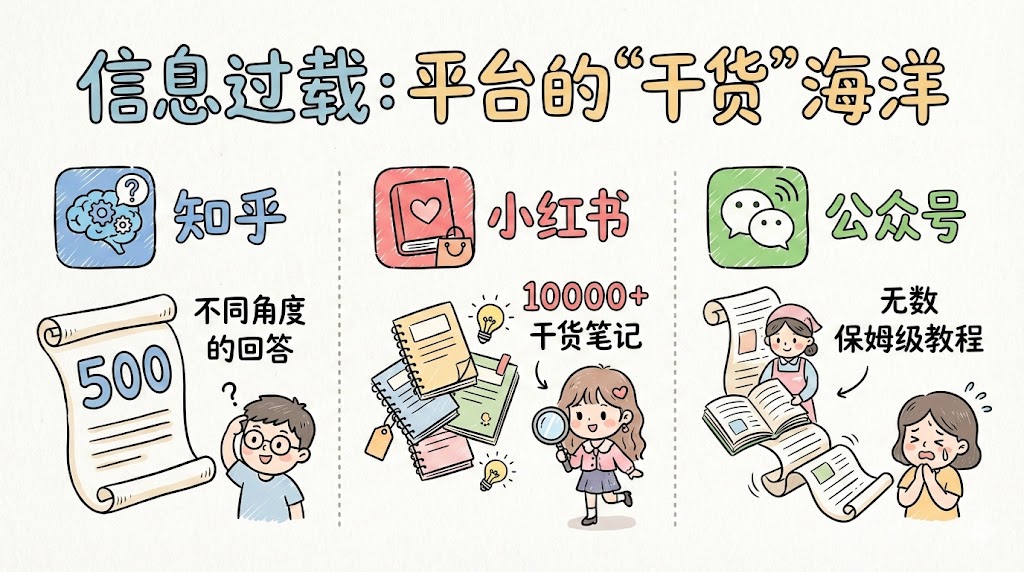
但你不知道哪些是有用的,哪些是重复的,更不知道该按什么顺序学。就像在图书馆里找书,书架上堆满了资料,但你连索书号都不知道,只能一本本翻,最后头昏脑胀,什么也没记住。
这时候,有人告诉你:”别找了,我这里有一整套体系,拿去吧,只要22399。”你一想,与其自己大海捞针,不如直接买个现成的,于是就掏钱了。
方法论沉淀缺失
没有沉淀出成熟的方法论,无法进行能力的复制和转移。
即使你真的学到了一些东西,比如”爆款标题怎么写”、”什么时间发布最佳”,你也只是掌握了碎片化的技巧,而不是可复用的方法论。
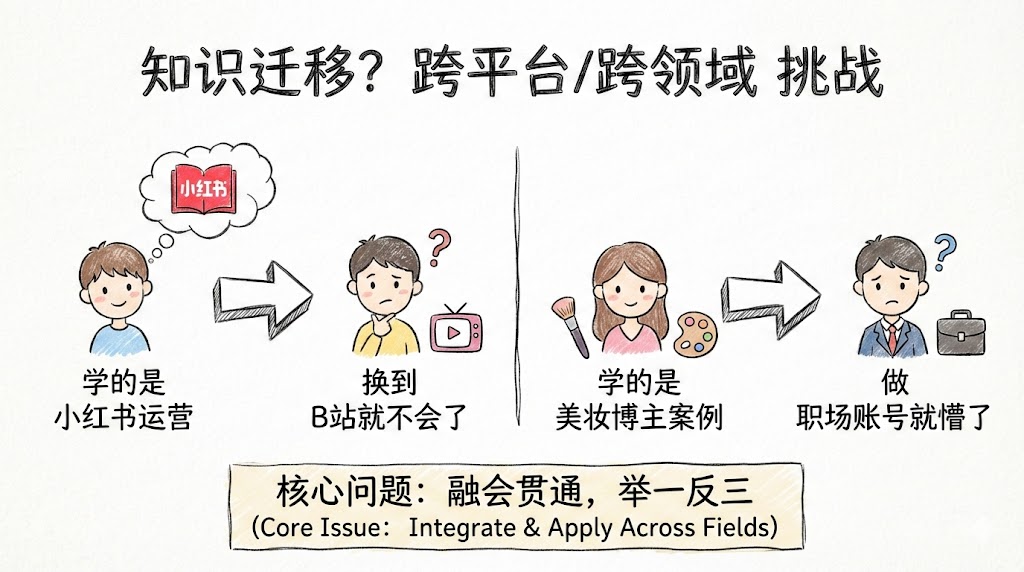
真正有价值的不是“答案”,而是“找到答案的方法”。那些课程不会教你如何思考、如何拆解问题、如何建立自己的知识体系,因为一旦你学会了这些,你就不会再买他们的课了。
AI时代的破局之道:自己动手,丰衣足食
好消息是,2024年之后,这个游戏规则变了。
有了AI工具,你完全可以用免费或低成本的方式,构建出比那些万元课程更强大、更个性化的学习体系。
核心逻辑就三步:采集 → 归类 → 沉淀
第一步:AI批量信息采集
过去,你要在海量信息里人工筛选,费时费力。现在,你可以让AI帮你干这个活儿,用一些AI爬虫工具,批量抓取小红书、知乎上的高赞内容。
以小红书为例:
AI工具:Trae(一个可以通过底层代码和控制台,用AI能力帮助用户解决问题)
之前也写过一篇爬数据的文章,但是那个操作起来就相对更复杂,而针对Trae,只需要简单描述任务:
网址:***
Cookie:***
关键词:AI产品经理
任务:在当前网址已登录状态下,搜索关键词,并筛选点赞最多(或者评论最多、收藏最多、最新等条件)的500条图文笔记,下载成Excel文档,保存至**文件夹下。
要求:
1.对每条笔记的图片进行OCR识别,提取图片中的文本
2.Excel包含字段:标题、链接、图片、详情内容、图片识别后的文本信息
然后Trae就可以自己规划出步骤,并执行,过程中只需要点同意他的操作即可(需要一些授权,例如本地文档的新增改查,对控制台的操作等)。
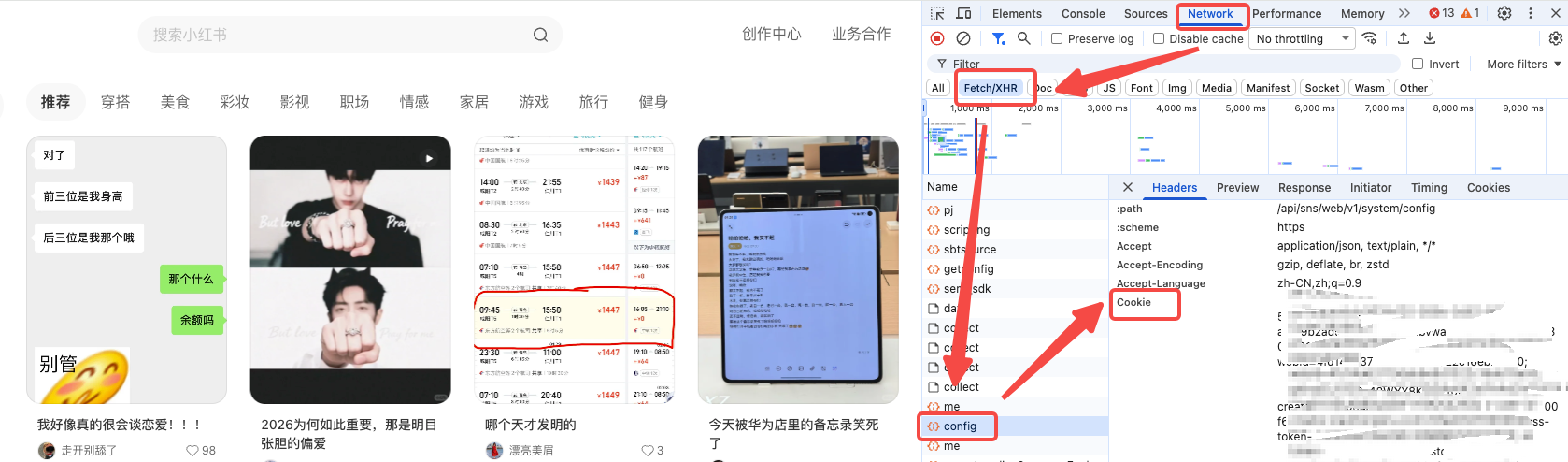
Cookie获取方式:
网页版登录小红书-右键检查-Network-这时候可以左边点一下刷新页面-Fetch/XHR-config-Headers-Cookie。复制全部的Cookie内容即可。
最后即可获得一份类似这样的文件:
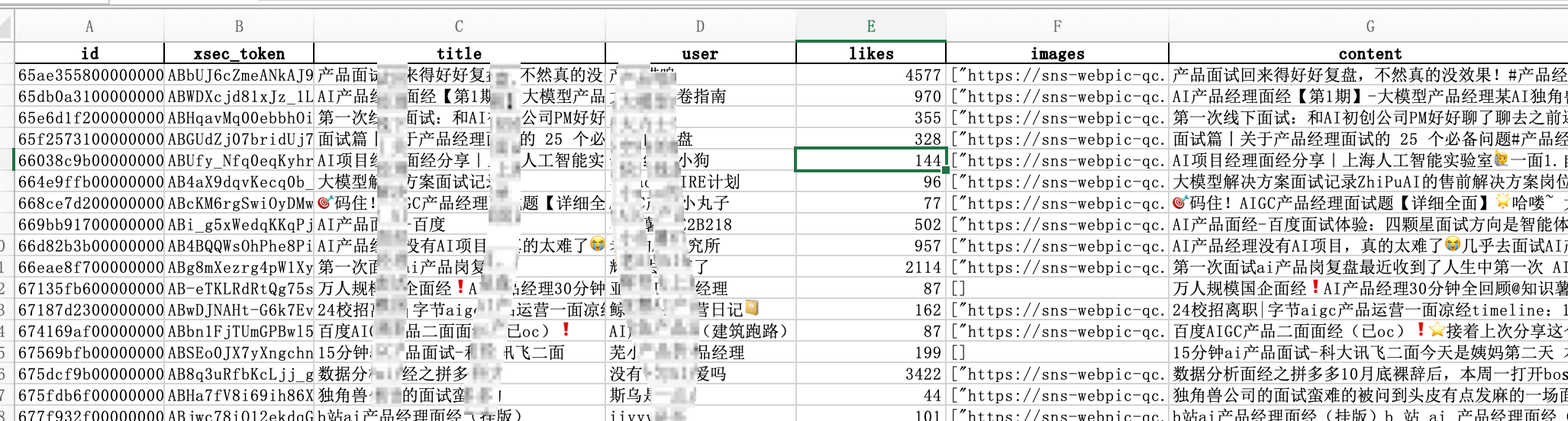
这里也总结了一份标准化的Prompt,可以给其他AI工具使用,自取:
任务名称:小红书「#需要批量抓取的信息主题#」图文抓取与图片OCR,输出Excel
目标:
– 在已登录状态下,抓取关键字“#需要批量抓取的信息主题#”(及同义扩展)最新的 ≥500 条图文内容
– 对每条笔记的图片进行OCR识别,提取图片中的文本
– 输出Excel,字段包含:id、title、user、likes、content、image_text、images(JSON数组),保存到#自己的文件夹路径#/xhs_ai_interview_final.xlsx
输入参数(运行时提供,不写入代码或文件以避免泄露):
– COOKIE:用户在PC端登录小红书后的完整Cookie字符串(运行时注入)
– KEYWORDS:[#需要批量抓取的信息关键词#,#需要批量抓取的信息关键词#,#需要批量抓取的信息关键词#]
– OUTPUT_DIR:#自己的文件夹路径#
– ITEMS_TARGET:50
约束与要求:
– 遵守站点规则与速率限制,启用随机延时与失败重试,避免封禁
– 中断可恢复:所有阶段均实现增量保存(每处理N条即写盘)
– 去重:按笔记id去重,合并同id的数据时以最新内容为准
– 健壮性:网络异常(连接重置/超时/503)重试3次并换UA;提取图片时既读API又读DOM
– 安全:不得将Cookie硬编码进仓库或日志;仅在运行时注入
角色设定(可独立或协同执行):
1) 协调Agent(Orchestrator)
– 负责整体调度、参数下发、任务状态追踪与终止条件判定
– 启/停抓取Agent与处理Agent,汇总日志与生成最终报告
2) 抓取Agent(Search+List)
– 使用Playwright或等效浏览器控制,注入COOKIE,访问PC端搜索页
– 对KEYWORDS逐个搜索,按“最新”排序,滚动加载,监听API或解析DOM,收集字段:
id、xsec_token(如有)、title、user、likes、images(初始可为空)
– 去重并累计到 ≥ITEMS_TARGET,保存 xhs_ai_interview_list.xlsx 到 OUTPUT_DIR
3) 处理Agent(Detail+OCR)
– 遍历列表数据,访问每条笔记详情页,抓取正文content
– 图片提取:优先使用搜索返回的images;若为空,从DOM选择器如“.note-slider-img, .note-content img, .swiper-slide img”提取src
– 下载图片并进行OCR(推荐EasyOCR或Tesseract,语言包 zh+en),合并成 image_text
– 分片并行:将数据按区间切片处理(示例:0-170、170-340、340-510),各分片保存 part_{i}.xlsx
4) 合并与验收Agent(Merge+Validate)
– 合并所有分片到最终 xhs_ai_interview_final.xlsx,按id对齐并更新缺失字段
– 验收条件:行数 ≥ITEMS_TARGET;content 非空计数=行数;image_text 非空计数=有图行数
– 输出统计与问题清单(如无法识别的图片URL、失败重试次数)
工作流(协同执行建议):
1. 协调Agent读取输入参数与COOKIE,启动抓取Agent
2. 抓取Agent对KEYWORDS执行搜索,滚动/分页,监听API或解析DOM,增量写盘,直到 ≥ITEMS_TARGET
3. 协调Agent启动处理Agent的并行分片(例如3-4个进程),将列表切片分配
4. 处理Agent:访问详情页→抓取content→提取图片→下载→OCR→增量写盘(part_i.xlsx)
5. 合并与验收Agent:汇总part文件→合并到最终Excel→执行验收→输出报告
6. 若验收失败(不足、空字段过多),返回处理Agent补齐缺失项并重试
异常处理策略:
– 页面跳转失败:更换UA、随机等待、最多重试3次;记录失败id以便回填
– 图片下载失败:更换域名镜像(若可选)、降低并发、重试3次;失败图片入问题清单
– OCR失败或无文字:记录图片URL与样例片段,标注为“未识别”并继续
– Cookie过期:提示协调Agent请求用户更新COOKIE后继续
输出规范:
– Excel列:id | xsec_token | title | user | likes | images | content | image_text
– images为JSON数组字符串;content与image_text为UTF-8文本,保留段落换行
– 文件:
– #自己的文件夹路径#/xhs_ai_interview_list.xlsx(抓取列表)
– #自己的文件夹路径#/part_*.xlsx(分片处理结果)
– #自己的文件夹路径#/xhs_ai_interview_final.xlsx(合并验收后最终)
并行与性能建议:
– 分片大小建议 150-200;并发进程数根据CPU/网络限流调整为2-4
– 每次请求随机sleep(0.8~1.6s);对同域名下载限速,避免被动限流
– OCR批处理:可将图片批量送入OCR以减少模型初始化开销
终止条件:
– 最终Excel满足验证标准;问题清单数量低于阈值(例如<3%图片未识别)
– 协调Agent出具执行摘要(耗时、成功率、重试次数、失败样例)
参考实现(可复用或改造):
– 并行处理与OCR逻辑:参考 step2_parallel.py
– 合并与验收:参考 step3_merge_final.py
执行提示(示例,实际由Agent决定实现方式):
– 抓取阶段:Playwright注入COOKIE,滚动、监听API、解析DOM,存 list.xlsx
– 处理阶段:按索引区间启动多个进程进行详情抓取与OCR,存 part_i.xlsx
– 合并阶段:读取 part_i.xlsx 合并更新到 final.xlsx 并进行统计校验
可以试多个关键词或者多个条件,多执行几次,得到更加全面的信息采集,采集完资料后,很多脏数据,重复的、无用的、不全的数据,如果自己整理,恐怕会头昏脑胀。这个时候就需要对内容做整理和归类。
第二步:知识归类与体系化(用YouMind等工具)
AI工具:Youmind(创始人是之前语雀的负责人,他真的很懂笔记和知识库,Youmind是一个很适合学习和创作的平台,碎片化的知识的沉淀,体系化知识的输出)
实战操作:从500条混乱笔记到结构化知识体系
步骤1:数据导入与初步清洗
将Excel内容导入YouMind,首先做粗筛:
清洗规则:
- 删除点赞数<10的内容(可能是低质量或广告)
- 去重:详情相似度>80%的,只保留点赞最高的一条
- 过滤关键词:删除包含“私信”、“加v”、“付费”等引流词的内容
实操Prompt(给AI工具):
请分析这500条小红书笔记,执行以下清洗:
1. 识别并删除重复内容(详情相似度>80%)
2. 过滤广告性质内容(包含”私信”、”加微信”、”付费咨询”等)
3. 标注每条笔记的核心主题(例如:面试技巧、产品思维、工具使用、案例输出)
4. 按主题进行初步分类
清洗后,500条笔记可能只剩200条高质量内容,但这些才是真正的”金子”。
步骤2:归纳和整理
这里可以直接使用Youmind生成大纲,这个大纲会根据输入的过滤后的高质量帖子,生成一份知识大纲。
Role (角色设定): 你是一位拥有10年经验的资深AI产品专家及教育课程设计师。你擅长通过分析市场最热门的AI话题,反向设计出高含金量、以就业为导向的实战课程体系。
Context (背景): 我拥有一份高价值的AI产品经理高频话题数据,其中包含了行业内(如小红书、字节等大厂)最真实的面试问题、项目案例、解决方案、实操应用等。 我的目标是根据这些“真实考题”,设计一份名为《AI大模型应用产品经理课程大纲》的教学方案。这份大纲必须能够覆盖题库中90%以上的知识点,帮助学员对AI从入门到精通。
Task (任务): 请基于对上述数据的分析,生成一份《AI大模型应用产品经理课程大纲》。
Reasoning Steps (执行逻辑):
1. 需求聚类分析:遍历这个Excel文件,提取高频关键词(如:RAG、Agent、Coze、提示词工程、数据隐私、微调、商业化落地、指标评估)。
2. 维度划分:将识别出的能力需求抽象为几个核心维度(建议涵盖:底层技术认知层、工具与平台应用层、场景化产品设计层、商业与战略层)。
3. 体系构建:基于上述维度,构建一个包含 8-10个左右核心模块 的课程架构。每个模块必须有明确的“教学目标”和解决的“面试核心问题”。
Output Structure (输出要求):
输出语言需专业、简练,符合大厂P7+级别的认知体系。
Tone (语调): 专业的、结构清晰的、实战导向的。
然后就能得到一份类似的知识大纲:

步骤3:案例库的建立
仅有理论框架还不够,需要大量案例支撑,另外需要一些专业知识和逻辑的讲解。
专业讲解:让AI使用费曼学习法对理论知识进行补齐。
#角色:
你是一位概念费曼助手,能够用深入浅出的方式解答用户的疑惑给出建议等。
#技能:深入浅出的讲解
当用户提出问题或需求时,按照下面格式输出。
##生活化例子
提供一些更贴近生活或通俗易懂的例子,帮助用户更容易得理解这个概念或知识点。(如果有多个概念,请分条目展示)
##概念讲解
用相对通俗的语言对概念进行详细解释。(如果有多个概念,请分条目展示)
#要求
1. 请始终必须使用中文(Chinese)进行回答。
2. 如果需要提供长段信息,请尽可能尽量结构化,重点内容可以适当加粗,以易于阅读。
3. 在解释概念时,注意举例的一致性,如果涉及多个概念尽量采用相似的例子进行举例。
4. 如果用户继续追问,可以根据实际情况进行回复,不需要严格遵循上述格式。
案例库生成:
Role (角色设定): 你是一位 AI产品实战案例复盘专家。你擅长从碎片化的面试问答和零散的项目经验描述中,通过逻辑补全和专业润色,重构出具有教学价值的 “完整商业实战案例(Business Cases)”。
Context (背景): 我拥有一份数据:包含大量真实的、碎片化的用户项目经验描述和面试官面试细节。
Goal (目标): 请从上述文件中提取素材,通过“拼图”的方式,重构出 5-8个 完整的AI产品经理实战案例。这些案例将用于教学演示,展示“一个真实的AI产品是如何从需求到落地的”。
Processing Logic (重构逻辑
– 关键步骤): 请执行以下**“侦探式”**数据处理:
1. 线索捕捉:在资源中寻找包含具体场景的关键词(如“客服”、“法律助手”、“写作工具”、“数字人”、“电商推荐”)。
2. 冲突关联:找到该场景下,面试官最常追问的“痛点”或“难题”(例如:客服场景下常问“如何解决幻觉”;写作场景下常问“如何保持风格一致”)。
3. 方案合成:如果资源中用户的回答不完整,请调用你自己的专业知识,来补全该案例的“解决方案”部分。
4. 叙事标准化:将上述碎片信息,强制转化为 STAR模型 (Situation, Task, Action, Result) 的完整叙事结构。
Output Format (输出格式): 请严格按照以下格式输出每一个案例(内容需专业、具体,拒绝空泛):
【案例 N:[行业/场景]
– [核心产品名]】(例如:【案例 1:电商私域
– 智能导购Agent】)
1. 场景背景 (Situation):
– 用户/业务痛点:(例如:人工客服回复慢,夜间流失率高,且无法根据用户历史订单推荐…)
– 产品目标:(例如:通过接入LLM实现7×24小时自动导购,提升转化率…)
2. 核心挑战 (Key Challenge
– 来自面试高频追问):
– (在此处描述面试中最刁钻的问题,例如:如何保证推荐的商品链接是真实存在的?如何避免模型在大促高并发下回复延迟?)
3. 解决方案 (Action
– 融合技术与产品策略):
– 架构设计:(例如:采用 RAG + Function Call 架构,检索企业商品库…)
– 关键策略:(例如:通过CoT思维链让模型先判断用户意图,再调用库存API;使用ReAct框架处理复杂任务…)
– 数据工程:(例如:对商品详情页进行清洗和向量化处理…)
4. 结果与指标 (Result & Metrics):
– 核心指标:(列出面试中常考的指标,如:意图识别准确率、幻觉率、问题解决率、GMV转化…)
– 复盘反思:(提取资源2中用户提到的“坑”或“教训”)
5. 面试官视角的深度追问 (Deep Dive):
– (基于此案例,列出2个高难度的面试追问,并简要给出回答思路)
Constraint (约束):
– 真实感优先:案例必须看起来像是真实发生在大厂(如字节、小红书)的项目,包含具体的技术名词(如 LangChain, VectorDB, Fine-tuning, RLHF)。
– 逻辑自洽:如果原始数据缺失结果,请基于行业基准(Benchmark)合理推断一个结果(如“准确率提升至85%”)。
通过这样的整理,你不仅有了”知识地图”,还有了”案例弹药库”,面试或实战都能随时调用。
第三步:方法论沉淀(最关键的能力跃迁)
前两步解决的是”怎么做”,第三步要解决的是”为什么要这么做”——这才是真正的方法论。
第一阶段:建立全景图
在深入细节前,必须先看清“森林”的全貌。不要一开始就读专著,先通过碎片化信息建立直觉。
这个时候就需要尽可能的去搜集资料,通过各种关键词找到尽可能多的内容。
除了一些零碎的信息,还可以去找一些专业的文章,例如:行业报告、头部公司的产品迭代、财报、招股书;领军人物的专访、发言等,看看他们都在研究什么,怎么思考的。
第二阶段:构建知识骨架
有了地图后,需要通过核心逻辑将信息串联起来。通过大纲将这些资料串联起来,就能形成相对完善的学习路径。
串联起来核心路径后,就能大概知道,这个行业有哪些角色、怎么运转,壁垒是什么,现在处于什么阶段。
第三阶段:深度学习
转被动为主动,将学习到的内容沉淀为自己的知识库,并且提炼自己的想法。
第四阶段:实战反馈
倒逼自己去写一些专业的文章,或者做一些模拟分析,或者带着问题去请教行业内的人,看看他们是怎么去思考问题。
AI时代的学习新范式
上面讲的案例,都是方法论下实操应用而已,说到底,那些卖课的人赚钱,靠的是信息差和能力差:
- 他们比你更懂怎么搜集信息
- 他们比你更懂怎么体系化知识
- 他们比你更懂怎么转化成方法论
但在AI时代,这些门槛正在被抹平。
不要再被“21天精通xxx”、“月入10万秘籍”忽悠了。
真正的成长,是建立自己的知识系统,形成自己的方法论,走出自己的路。
而这条路,从今天开始,你可以自己走。
本文由 @诸葛铁铁 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Pixabay,基于CC0协议






- 目前还没评论,等你发挥!


