
 起点课堂会员权益
起点课堂会员权益一文读懂2026世界模型四大巅峰架构:Genie3、混元1.5、Marble 与 Gen-3C
2026年的世界模型技术已经突破像素预测的局限,迈向物理仿真的新纪元。本文深度解析三大流派架构——自回归Transformer、自回归扩散Transformer和空间原生3D引导流派的技术突破与应用场景,揭秘Google Genie 3、Tencent Hunyuan1.5和Marble等顶尖模型如何重新定义AI对世界的理解与生成。

第一章:主流世界模型的架构演进——从像素预测到物理仿真
1. 范式转换:为什么视频生成不等于世界模型?
在2024年,公众曾普遍将OpenAI的Sora视为世界模型的雏形。然而到了2026年,学术界与工业界已达成高度共识:“能画出视频”不代表“理解世界”。Sora1.0做的虽然是长视频,但同时他兼负着向物理AI世界进发的责任。传统的视频生成器本质上是基于概率的像素采样器。它们的目标是在像素层面上模仿人类视网膜捕捉到的“视觉统计特性”,即让画面看起来“像”。但这种方式存在一个致命的缺陷:缺乏状态持久性。当你控制相机在视频生成的环境中转动360度后,原来的物体往往会发生形变、位置偏移甚至彻底消失。这是因为模型并没有在内部构建一个稳定的“物理实体”,它只是在不断“续写”像素。
相比之下,2026 年定义下的世界模型必须满足三个核心硬指标:
- 交互性: 模型必须能够实时响应来自外部的动作指令。
- 因果连贯性: 任何动作产生的后果必须符合物理逻辑。
- 几何稳定性: 环境必须具有三维层面的持久性,即“所见即所得,且去而复返”。
为了达成这些目标,2026 年的世界模型演化出了三大截然不同的底层架构流派。
2. 三大流派架构深度对比:因果、视觉与几何的博弈
目前,全球顶尖实验室在构建世界模型时,主要在以下三种数学范式中进行权衡。它们分别代表了人类模拟现实的不同哲学路径。下图展示了一些主流的世界模型以及他们的架构类型,下文会对其中几个模型的架构进行拆解。
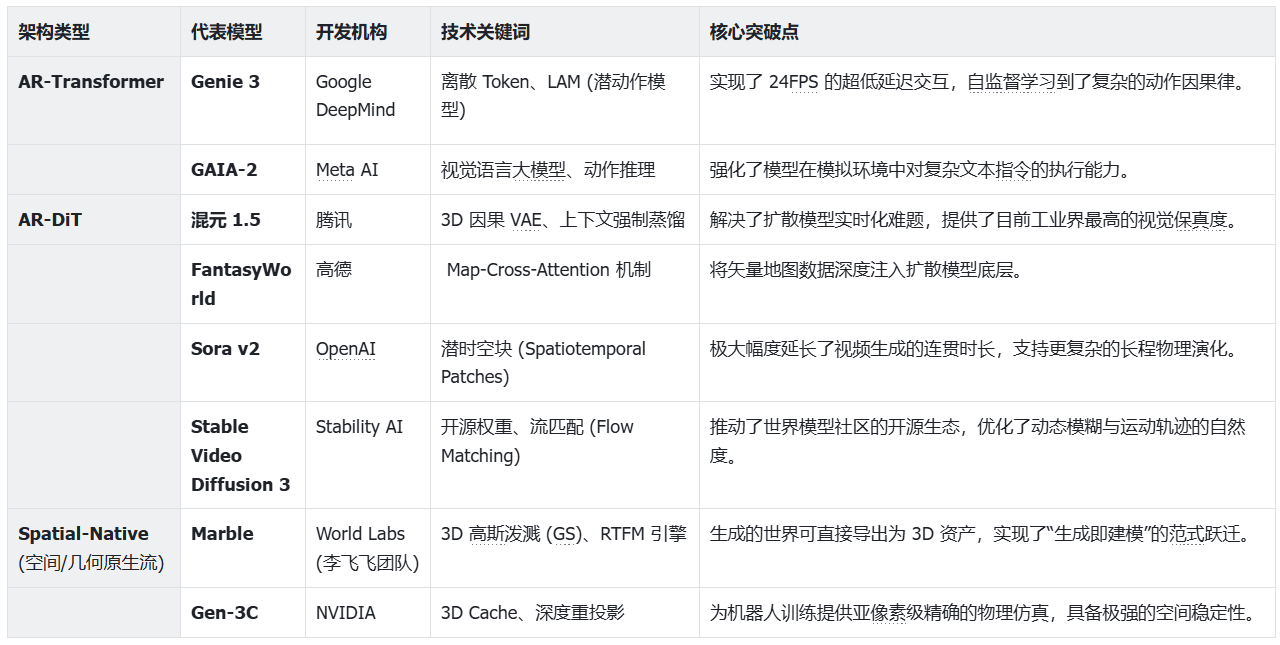
自回归 Transformer 流派 (AR-Transformer) —— “世界即语言”
代表作:Google Genie 3
这一流派继承了LLM的衣钵。它将视频帧和动作指令序列化,转化为一组离散的视觉 Token。他的运作机制就像LLM预测下一个词一样,根据历史帧 Token和当前的动作向量,预测下一时刻的Token。其优势在于极高的逻辑密度。因为它采用纯自回归路径,非常擅长捕捉动作与结果之间的因果链条。例如,在模拟游戏环境时,它能精准记住某个开关被触发后,远处的门应该开启。但同样村咋一定的局限性,受限于分词器(Tokenizer)的压缩损耗,其视觉细节往往存在“数码感”,且在长时间预测后容易产生像素级的“幻觉漂移”。
自回归扩散 Transformer 流派 (AR-DiT) —— “世界即演化”
代表作:Tencent Hunyuan1.5
结合了 Transformer 的序列处理能力与扩散模型(Diffusion)的精细重构能力。它不再预测离散的 Token,而是在潜空间(Latent Space)中通过“去噪”过程还原出连续的视觉分布。这一流派是视觉真实感的巅峰。它能完美还原光影的菲涅尔反射、流体的湍流运动以及微小材质的纹理。通过蒸馏技术,2026 年的 AR-DiT 已经能在消费级 GPU 上实现 24 FPS 的实时渲染。但在物理逻辑上有时会显得绵软。虽然看起来极其真实,但有时物体的碰撞会像橡皮泥一样缺乏刚性,且计算成本依然高居不下。
空间原生/3D 引导流派 (Spatial-Native) —— “世界即实体”
代表作:World Labs Marble、NVIDIA Gen-3C。
这一流派跳出了“二维视频”的思维,试图在神经网络内部直接维护一套 3D 表示(如高斯泼溅 GS、点云或体素)。这类模型生成的是一个持久的 3D 场。当用户移动相机时,模型只是在对这个已有的 3D 场进行重新采样和局部更新。是空间稳定性的终极方案。因为它生成的不仅是像素,更是“几何”。这使得它在具身智能(机器人训练)和 XR 创作中具有无可比拟的地位,因为它支持资产导出和亚像素级的精确编辑。但也有一定的局限性:数据需求极其严苛,需要带有深度、相机参数的高质量 4D(3D+时间)数据进行训练。
第二章:Genie 3 (Google DeepMind) —— 自回归时空演化与交互控制的终极范式
1. 核心架构思想:将世界视为一种“语言”
Genie 3 的核心突破在于它将“世界模拟”彻底转化为了一个序列预测(Sequence Prediction)问题。在 2026 年,主流的视频生成器大多采用扩散模型路线,通过不断消除噪声来“拼凑”出连贯的画面。但这种方式在实时交互中存在致命伤:计算开销巨大且响应延迟高。Google DeepMind 在 Genie 3 中坚定地选择了纯自回归 Transformer(AR-Transformer)路径。
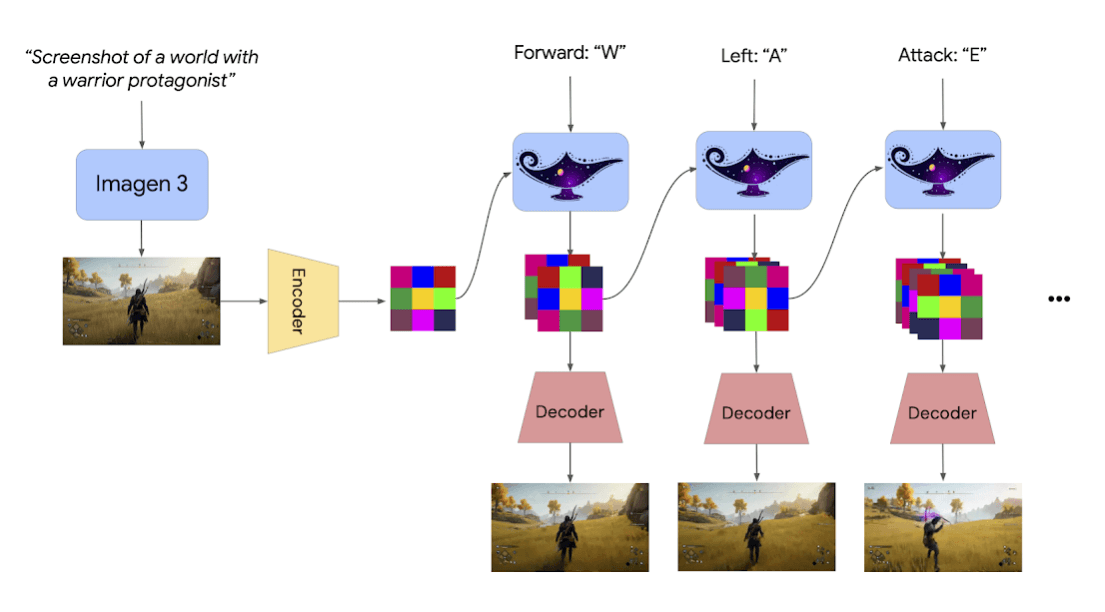
底层逻辑是: 如果我们将一个三维空间及其随时间的变化,压缩成一组具有逻辑关联的“视觉词汇”(Tokens),那么生成世界就变成了像 ChatGPT 写文章一样——根据过去发生的“剧情”,预测下一组“视觉词汇”。Genie 3 拥有 110 亿参数,这让它不仅能记住画面,更能通过概率分布学习到物理法则。
2. 关键组件深度拆解
Genie 3 的技术方案由三个紧密耦合的子系统组成,它们共同完成了从“理解动作”到“预测现实”的闭环。
1)分层时空分词器 (Hierarchical Spatiotemporal Tokenizer)
这是 Genie 3 能够处理 720p 高清视频的基石。传统的图像分词器只能处理静态图片,而 Genie 3 采用了 3D 卷积分词技术。
- 多维度压缩: 它不仅在宽和高上压缩像素,还在时间轴上进行压缩。它会将连续的 8 帧或 16 帧画面看作一个“视频立方体”,将其折叠成一个高维的特征向量,最后映射到一个庞大的数字词典中。
- 分层策略: 这里的“分层”是其深度所在。Genie 3 将视觉信息拆分为“宏观结构层”和“微观细节层”。结构层负责锚定场景的大轮廓(如山川、墙壁、地平线)。细节层则负责捕捉动态变化(如飞溅的水花、树叶的颤动)。这种分层处理确保了模型在快速运动时,背景大环境不会发生崩坏或漂移。
2)潜动作模型 (Latent Action Model, LAM)
这是 Genie 3 区别于所有视频模型的最核心组件,也是它具备“可交互性”的源头。最神奇的是,它是通过自监督学习完成的,不需要人类手动标注。
- 从变化中学习: 在训练阶段,LAM 观察海量的视频数据。它通过对比“当前帧”和“下一帧”之间的像素位移和物体形变,自动推断出导致这种变化的原因——这就是“动作”。
- 动作空间: 它会自动构建一个 8 维或 16 维的控制向量空间。虽然没有明确告诉它什么是“跳跃”,但当模型发现画面中的角色向上快速位移时,它会为这个变化分配一个特定的编码。
- 控制映射: 当你按下键盘上的“W”键时,Genie 3 实际上是将你的按键信号映射到了它自学出的这个“动作空间”里,从而驱动下一步画面的演化。
3)动力学 Transformer (Dynamics Transformer)
这是世界的“大脑”,一个巨大的、仅包含解码器(Decoder-only)的 Transformer 网络。
- 因果因果模拟: 它接收三样东西:过去的画面序列、当前的潜动作向量、以及用户的文本指令。
- 长程记忆缓冲区: 它利用了 128k 甚至更长的上下文窗口。这在技术上解决了“转身即忘”的问题。通过 KV-Cache(键值缓存)优化,模型可以将之前生成过的场景特征保存在隐藏层中。当你走出房间再转回来,模型会优先从缓存中检索这些特征,确保门后的那把椅子依然在原地。
第三章:混元 1.5 (WorldPlay) —— 视觉真实感与几何一致性的实时巅峰
在 2026 年的世界模型格局中,混元 1.5 (HY-World 1.5) 凭借其核心引擎WorldPlay,成功破解了世界模型领域长期存在的“实时性”与“几何一致性”无法兼得的技术悖论。作为AR-DiT路径的代表,它采用“下一帧预测(Next-Frames-Prediction)”的视觉自回归任务进行深度训练,实现了高达 24 FPS 的长程流式生成。
混元 1.5 的成功并非偶然,而是源于对底层动作表征、记忆机制、蒸馏方案以及强化学习反馈逻辑的系统性重构。
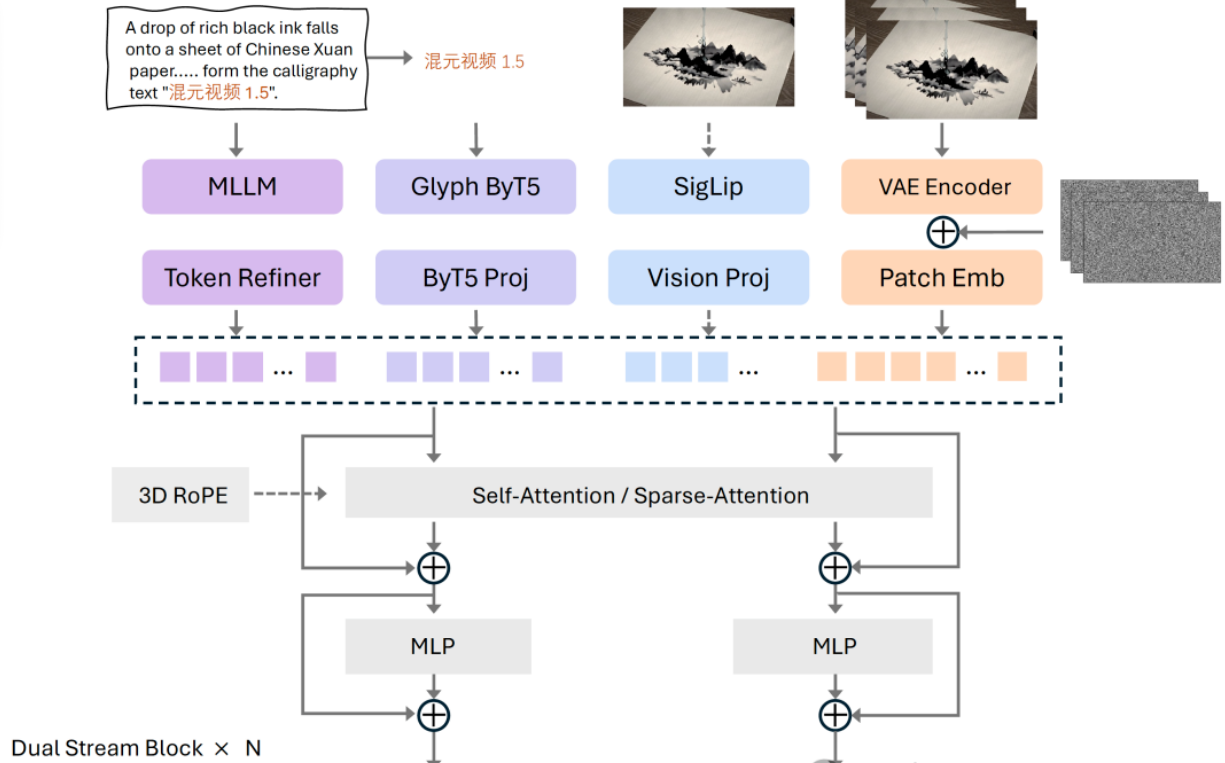
1. 双分支动作表征:实现亚像素级的精准控制
传统的交互式模型通常面临一个选择题:是采用离散的按键指令,还是采用连续的物理相机位姿?混元 1.5 提出了双分支动作表征 (Dual Action Representation)方案,将两者深度融合。
- 连续与离散的合流:模型同时注入连续的 3D 相机位姿(坐标、旋转角)与离散的控制逻辑。
- 空间先验的释放:相比纯指令输入,这种设计利用精确的空间位置作为先验,确保了生成的画面与操作物理逻辑严丝合缝。
- 缓解尺度漂移:相比纯位姿输入,引入离散指令有效解决了因场景尺度(Scale)不一导致的训练不收敛与控制信号“漂移”问题,使模型在多样化场景下均能保持极高的受控精度。
2. 上下文记忆重构:对抗“时间遗忘”与“几何漂移”
长程一致性是世界模型的命门。为了确保玩家在漫游过程中环境不发生坍塌,混元 1.5 建立了上下文记忆重构机制 (Reconstituted Context Memory)。
- 双层记忆结构:短期时序记忆:专注于相邻帧间的微观动态,确保物体的运动平滑无抖动。长期空间记忆:基于视野重叠(FOV)和相机距离采样,将那些即使在视觉中暂时消失、但在空间逻辑中依然存在的关键帧存储起来,防止长距离移动后的几何结构扭曲。
- 时间重构 (Temporal Reframing) 算法: 传统的旋转位置编码(RoPE)存在一个缺陷:历史帧的影响力会随距离增加而单调递减。混元 1.5 通过动态分配 RoPE,将那些空间关联度极高的重要历史帧在时间维度上“拉近”到当前时刻。这种“时间折叠”技术赋予了模型极强的长序列外推能力,确保关键参照点永远处于模型的有效感知范围内。
3. Context Forcing:专为记忆模型设计的蒸馏方案
扩散模型要走向实时交互,必须经过蒸馏(Distillation)。然而,传统的分布匹配蒸馏(DMD)在面对具有长上下文记忆的自回归模型时,往往会导致学生模型“丧失记忆”,产生模式崩溃。混元团队发现,这种失效源于教师与学生模型之间“上下文机制不匹配”导致的概率分布偏差。为此,他们提出了 Context Forcing 策略:
- 记忆上下文对齐:在蒸馏过程中,强力对齐教师与学生模型的记忆状态。
- 分布精准匹配:这种对齐确保了学生模型在大幅提升生成速度(实现实时推理)的同时,完整继承了教师模型的长程记忆能力。这不仅解决了速度问题,还显著减轻了长视频生成中的误差累积现象。
4. WorldCompass RL:基于 3D 空间奖励的强化学习框架
传统的监督学习(SFT)仅能让模型学会像素间的统计规律,却难以约束复杂的三维几何逻辑。为此,混元 1.5 引入了后训练框架 WorldCompass RL。
- 3D 基础模型作为“裁判”:利用预训练的 3D 视觉大模型生成奖励信号,直接对生成的视频进行几何一致性和动作跟随准确性的闭环优化。
- 分段渐进式 Roll-Out 策略:针对自回归模型的特性,在相同历史背景下进行重复采样与评估。这种分段策略不仅提高了训练的稳定性,还让模型在每一个细微的生成步骤中都能精准修正几何偏差。
- 稠密奖励机制:为了克服视觉生成中强化学习的效率难题,WorldCompass 放弃了传统的 PPO 算法,转而采用 On-policy Distillation(在线策略蒸馏)。这种更稠密的反馈方式,让视觉生成任务的 RL 训练变得更加稳定且高效。
第四章:从像素模拟到几何造物——Marble 与 Gen-3C 的空间智能革命
在 2026 年的世界模型演进史中,如果说前三章讨论的是如何优化“视觉续写”的概率,那么本章则标志着世界模型进入了“物理实体化”的阶段。
以 Marble 为首的“空间原生(Spatial-Native)”派与以Gen-3C为代表的“物理辅助(Physics-Informed)”派,彻底改变了神经网络生成世界的逻辑:它们不再仅仅预测下一帧长什么样,而是先构建出下一帧“在哪里”。
1. 架构范式的分水岭:为什么“像素预测”遇到了天花板?
在 2025 年之前,即便是最强的扩散模型,也面临着一个幽灵般的难题——空间坍塌。当相机在一个纯像素生成的房间里转动 360 度后,原先在那里的桌子往往会发生几厘米的偏移,或者纹理发生了细微改变。这是因为模型缺乏一个显式的“三维底座”。Marble 与 Gen-3C 的出现,正是为了给神经网络装上一副“三维骨架”,让生成的每一颗像素都锚定在真实的地理或几何坐标上。
2. Marble (World Labs):RTFM 架构与“生成即资产”
由李飞飞教授领导的 World Labs 推出的 Marble,其核心使命是赋予AI“空间理解力”。它推出的 RTFM (Real-Time Frame Model) 架构,实现了从视频生成向3D资产生成的跨越。
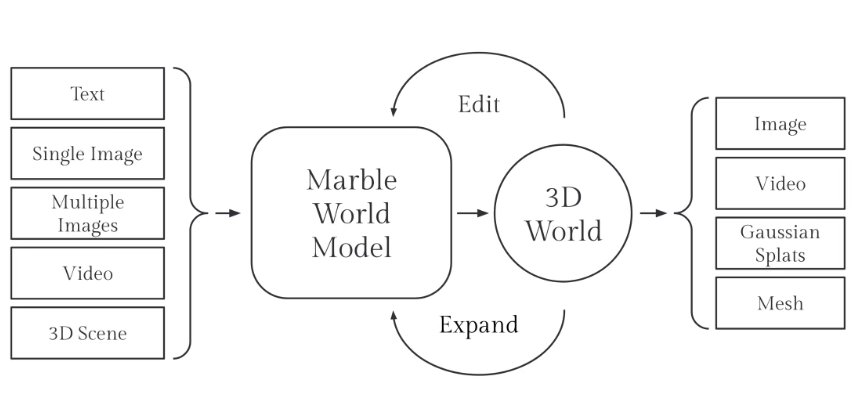
1)核心技术:基于 3D 高斯泼溅 (3DGS) 的生成潜空间
Marble 彻底抛弃了传统的二维像素解码器。
- 空间表征: 它在推理过程中生成的不是像素点,而是成千上万个具有颜色、不透明度、位置和旋转属性的“高斯椭球体”(3D Gaussians)。
- 神经渲染: 每一帧图像都是通过对这些 3D 高斯点进行实时差值和投影(Neural Rendering)得到的。
- 技术价值: 这种架构意味着“世界是实体存在的”。由于物体是锚定在 3D 空间坐标上的,无论相机视角如何剧烈晃动,物体的几何结构都不会发生形变。这从物理底层解决了长程一致性问题。
2)Chisel 模式:打破“黑盒生成”的强交互
Marble 引入了一个名为 Chisel (凿刻) 的交互层,允许用户像雕刻师一样控制世界生成。
- 几何强约束: 用户可以在 3D 空间中画一个框,指定这里必须有一张“明式条案”,模型会围绕这个三维边界进行填充,而不是随机生成。
- 工业级兼容性: 因为 Marble 生成的是点云和高斯数据,它可以直接导出为 USD 或 PLY 格式,无缝接入虚幻引擎(UE5)或数字孪生软件。它不再是一个单纯的视频模型,而是一个自动化的 3D 建模工具。
3. NVIDIA Gen-3C (Cosmos):3D 缓存引导的物理仿真巅峰
英伟达(NVIDIA)推出的 Gen-3C则走了一条极具工程美感的路径:用点云缓存来约束扩散模型。
3D Cache 机制:为预测装上“骨架”
Gen-3C 的核心突破在于其动态的 3D Cache (三维状态缓存) 机制。
- 同步深度感知: 模型在生成视觉 Token 的同时,会运行一个并行的深度预测分支。
- 点云投射与存储: 每一帧生成的像素会被立即投射到 3D 空间,形成一个实时更新的点云模型。这个点云就是“记忆的实体化”。
- 重投影引导 (Reprojection Guidance): 当用户控制相机移动时,Gen-3C 会先根据上一帧的点云缓存,计算出新视角下的“几何轮廓”。扩散模型只需在这个轮廓(骨架)上填充纹理。
- 技术价值: 这种“先建骨架,再填肉”的方法,确保了模型对相机位姿(Pose)极其敏感,支持亚像素级的精准控制,是具身智能训练的绝佳环境。
第五章:共生与大一统——2026年后世界模型的行业终局
通过前四章的深度拆解,我们见证了 Genie 3 对因果逻辑的掌握、混元 1.5 对视觉与几何的平衡,以及 Marble 与 Gen-3C 对空间实体的重构。站在 2026 年的时间节点,世界模型已不再是单一的技术演示,它正在成为驱动通用人工智能(AGI)迈向物理世界的底层操作系统。
世界模型的最终形态将是一个“通用物理模拟器(General Physics Simulator)”。它不仅能模拟肉眼可见的日常场景,更能深入微观(分子运动)与宏观(城市运行)。当喧嚣散去,我们发现,人类正在用代码编织一个与现实平行的数字宇宙。这个宇宙不仅是娱乐和游戏的终点,更是人工智能理解现实、超越现实、并最终安全地服务于物理现实的基石。世界模型不仅是在模拟世界,它是在为 AGI 构建一个可以思考、可以行动、且永远不会坍塌的地基。
本文由 @小嘉带你玩AI3D 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









感觉太震撼了!未来触手可及,人类正在用代码搭建一个全新的数字宇宙,真是既期待又有点害怕。