
 起点课堂会员权益
起点课堂会员权益不懂AI工具也能学!手把手教你搭建科普短视频生成Agent
从两天到五分钟,Agent如何重塑科普短视频创作?本文通过实战演练,揭秘如何搭建智能工作流,将文案生成、图片创作、视频剪辑等繁琐工序自动化。一个人即可实现整个视频工作室的产能,不仅大幅提升效率,更为初创团队节省人力成本。跟随作者的步骤,探索AI时代内容创作的全新可能。

我自己出于爱好,会经常使用视频剪辑工具进行科普短视频制作,非常耗时耗力,而且花大精力做出的短视频,往往观看量也不高,如果尝试去切换不同的短视频风格,同样需要投入大量的时间和精力。所以我在思考,是否可以搭建一个智能的Agent,让Agent帮我生成各种风格的科普视频,批量产出,这样快速投放平台,经受用户检验,来发掘出匹配观众风格的短视频,从而提升短视频的传播量。
我的总体的思路是Agent可以根据我们的主题,生成和主题相关的短视频。这就需要Agent对于我们的主题有扩展功能,例如,我们希望生成一个以【从脑科学的视角为什么吃甜食会令人愉悦】为主题的科普短视频。以我之前的操作,需要自己去编写这个主题的文案,虽然现在已经可以通过AIGC生成,这个文案的编写,差不多需要1天的时间,即便是很投入地去写,加上资料检索,最快也要4个小时。文案编写完成后,对文案进行拆解,分解出若干片段,根据片段的内容,去制作相应的图片提示词,然后将每一个提示词输入大模型,生成几十张图片,再基于图片编写视频片段的提示词,生成视频,最后将这些生成的视频整合在视频剪辑软件里,加上字幕和配音。另外,在发布前,还需要手动做一个封面图片。这么这个全流程下来,基本上一个几分钟的视频,就需要花费2天左右的时间。
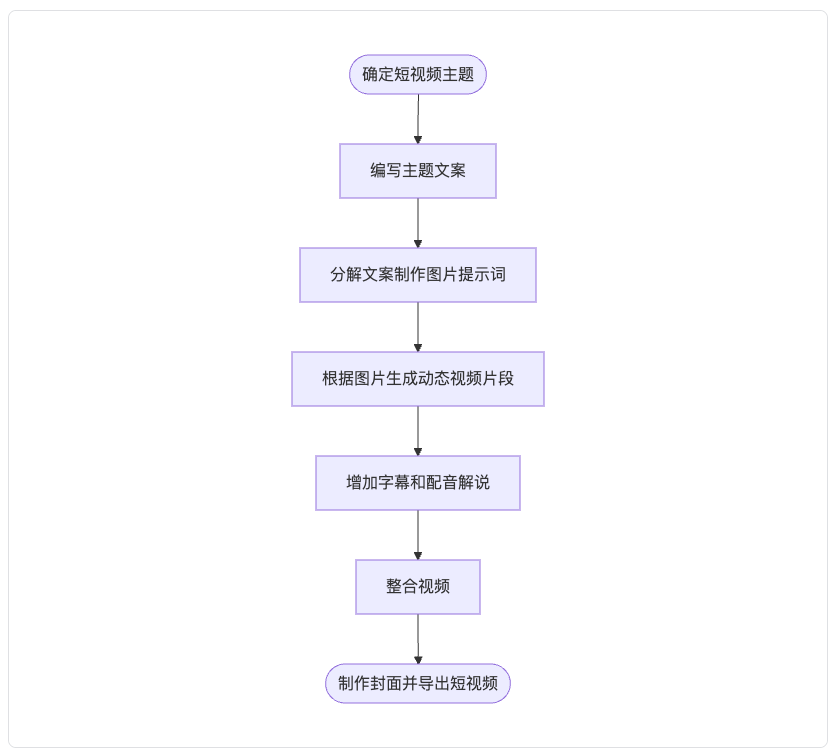
很显然,这是一个创作的工作流,既然是一个标准的流程,我们就可以通过结合我们的实际过程操作搭建一个Agent,来为我们做这些事情,也就相当于,我一人的工作室里,有帮我根据主题,创作文案的“员工”,也有对文案进行解读拆分,生成对应创作脚本的“员工”,也有根据指令生成图片的“员工”,还有基于图片,生成动态视频的“员工”,最后还有一个帮我做剪辑的“员工”,将各种视频素材整合,配音和加字幕,最后呈现出一个完整的科普视频。
是不是很有意思?相当于只有我一个人,通过Agent实现了一个视频工作室的配置。由之前个人制作需要2天的时间,变为了现在5分钟左右,就可以完成一个科普短视频的创作,提效明显,同时,也不需要额外去招聘相应岗位的员工,Agent全部可以实现,这对于很多人准备打造初创公司,节省了不小的人力成本。
一、Agent搭建实战
话不多说,我们直接上干货。结合我自己日常实际操作的动作和任务,我们进行每个任务节点的Agent搭建。由于Agent搭建,需要具有基础的AI工具使用经验和背景知识,因此,涉及到一些基础的操作,例如Agent平台的账号注册,如何通过提示词操作大模型生成内容,这些内容本文将不再过多讲述,如果读者有需要咨询的地方,可以联系作者。我们为Agent起个名称,“科普短视频生成”,我自己一般会在名称前加一个类型,方便后续应用比较多的时候,可以从名称上直观看出是工作流、应用还是Agent。初始界面如下图所示。
1.1 编写主题文案
本节点主要功能是根据我们输入主题,自动为我们生成对应文案,需要我们约定提示词,以便于大模型可以根据我们的要求,生成内容。因为Agent功能的实现,需要依赖工作流的创建,我们在这里创建工作流。
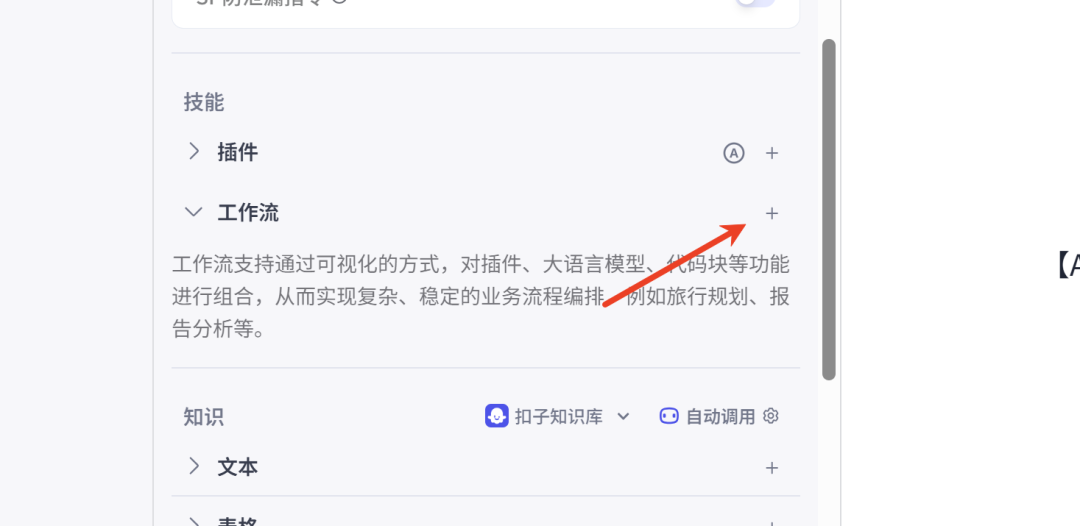
主题文案生成的功能是,我们希望输入一个关于脑科学科普的主题,按我们的要求生成和主题有关的文案。我们通过一个简单的工作流实现。我们为这个工程流起名为【workflow_brain_text】,也就是我们之前说的命名方法,如果是工作流,我们在名称前加上【workflow】,便于后续内容比较多的时候,可以快速识别这些组件类型。
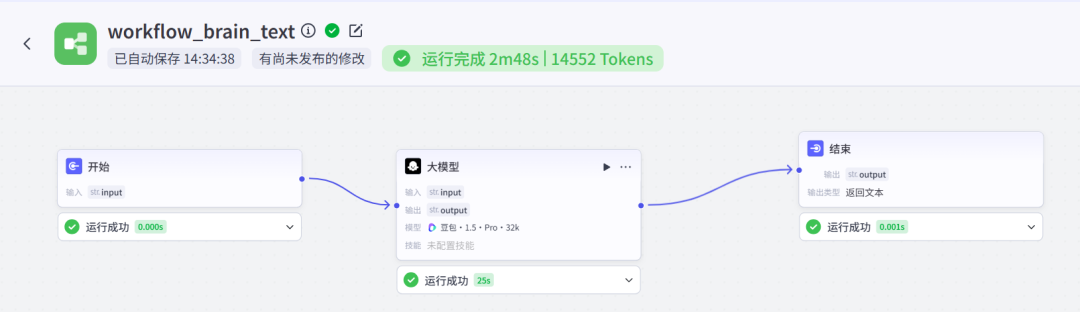
我们进入到我们刚搭建的智能体,关联好我们刚配置的工作流。
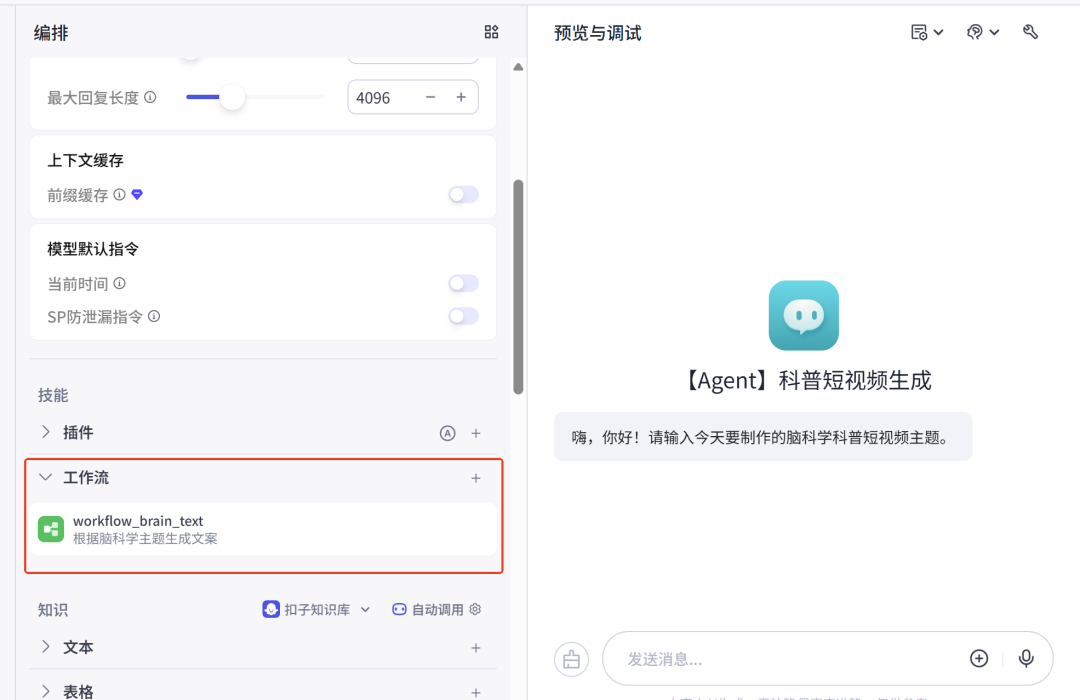
试运行一下,在“发送消息”输入框中,输入【从脑科学的视角为什么吃甜食会令人愉悦】,为主题的内容,看一下智能体的给我们输出的文案。
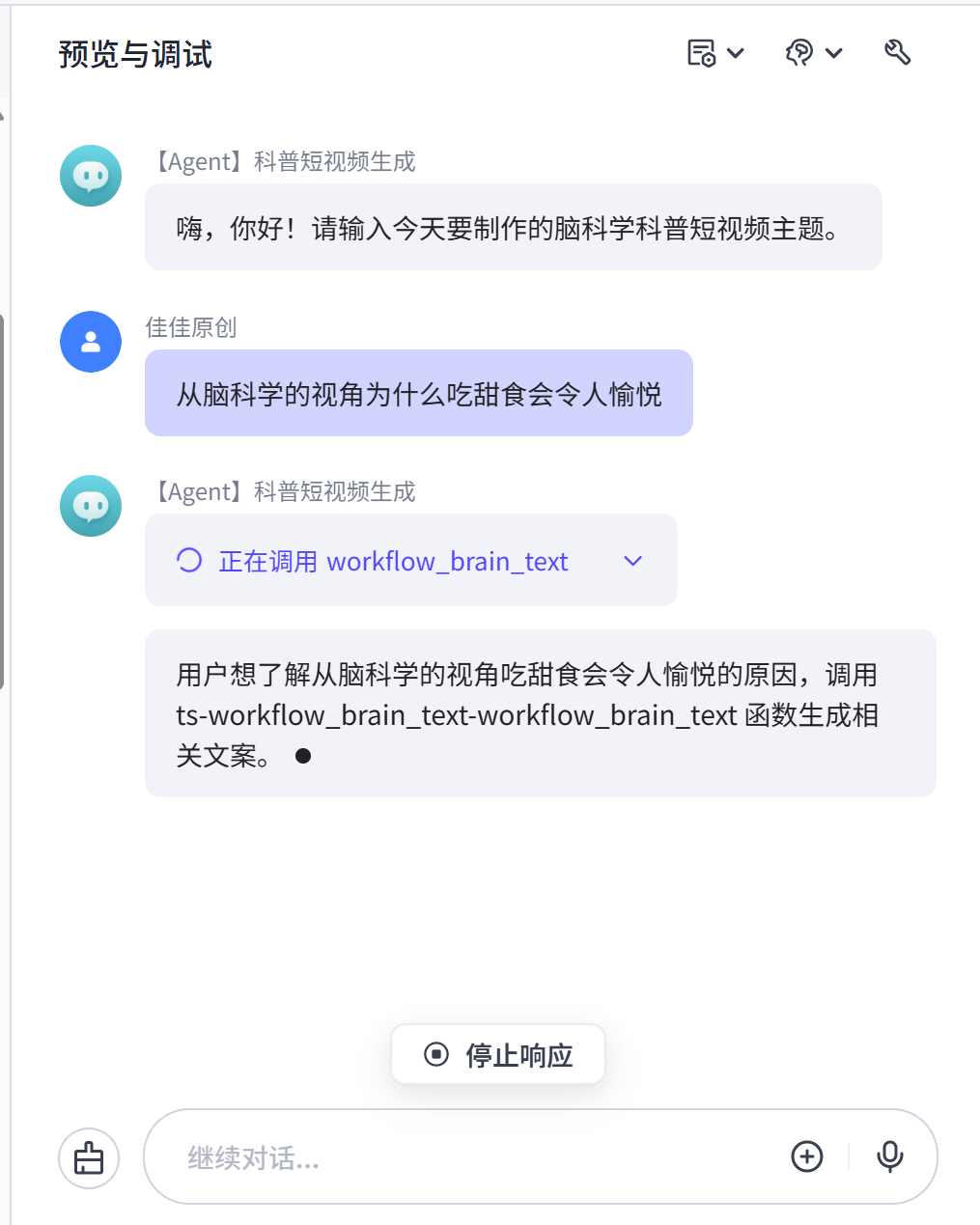
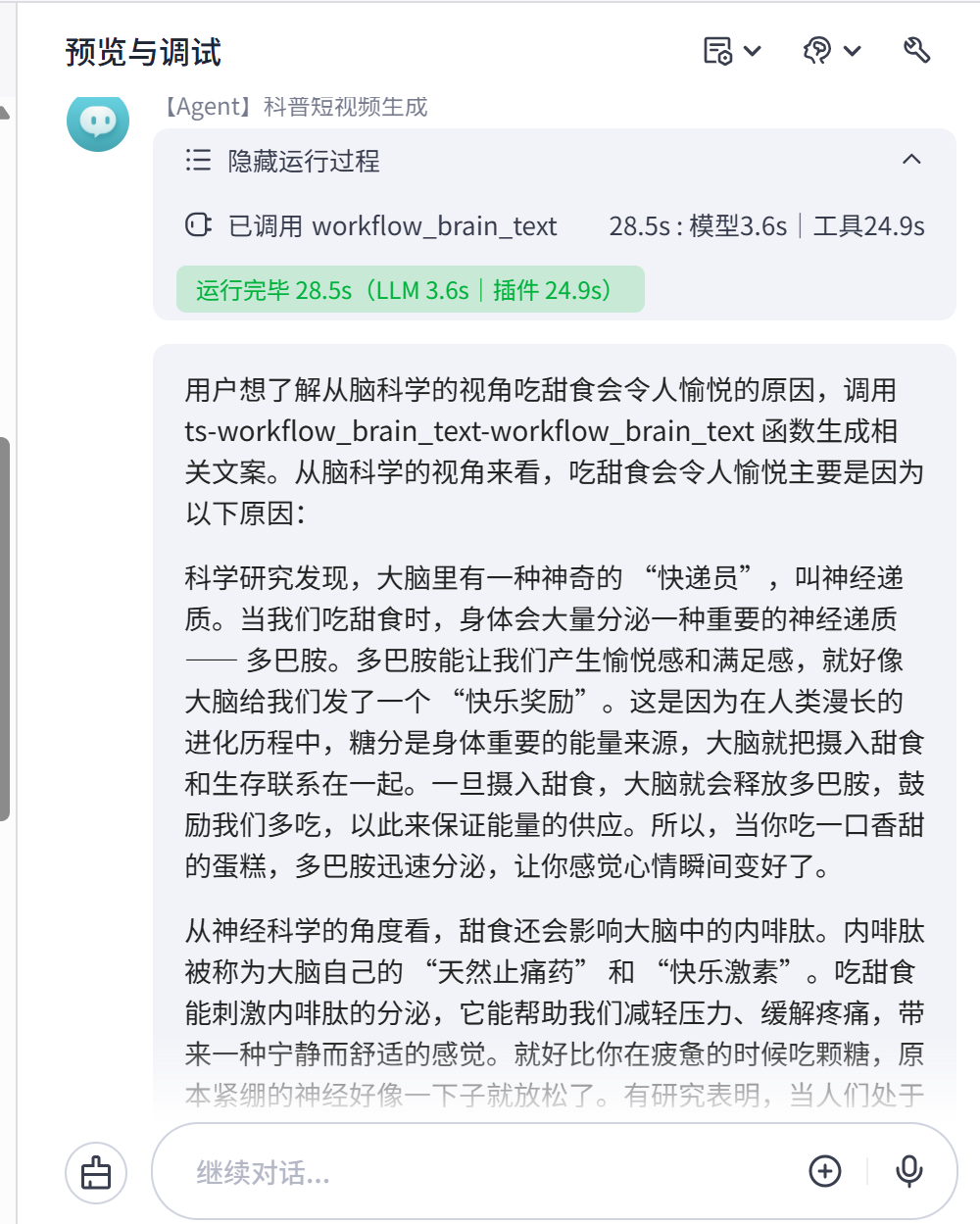
Agent开始响应我们的指令,并成功调用我们之前配置的工作流【workflow_brain_text】,生成的内容返回对话框,我们看到,已经成功生成了内容。
1.2 分解文案制作图片提示词
主题文案编写完成后,我们需要将主题文案进行分拆,以便于根据分拆后的内容制作生成相应的图片,我们继续对工作流【workflow_brain_text】进行扩展,主要实现以下功能,一个是将生成的文案分拆,另一个是基于分拆后的内容进一步生成图片提示词,然后基于提示词生成图片。
我们先来实现分拆功能,通过调用分拆文案的插件,实现对我们生成的文案分拆,生成一个列表,之后调用一个循环的插件实现对这个列表中,拆分后的文案依次调用大模型生成文案。生成的结果如下图所示。
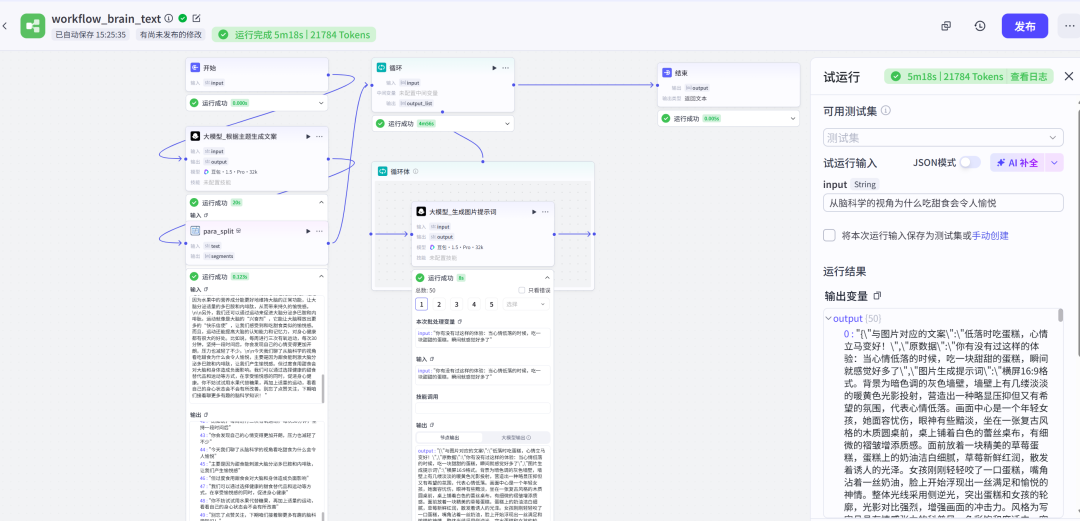
我们发现生成的内容还是比较多的,有50次循环调用,因为我们是在调试阶段,其实我们可以通过改变大模型的提示词,让大模型生成的内容稍微少一些,比如控制在100字以内。
接下来我们让大模型将分拆好的内容生成图片。也就是在工作流【workflow_brain_text】中,加入生成图片的插件,我们看一下效果。如下图所示,已经根据我们的主题生成了文案,并基于文案生成了图片。
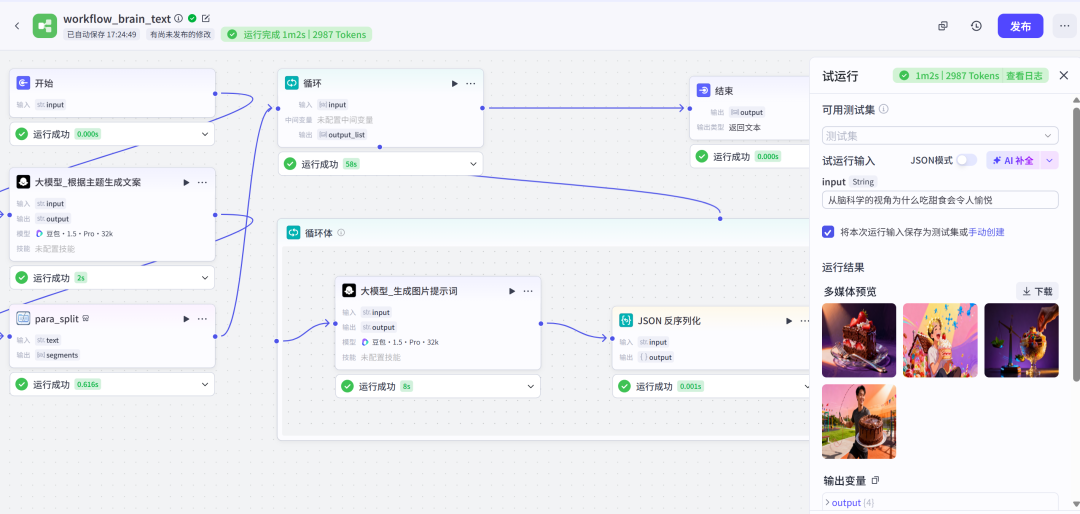
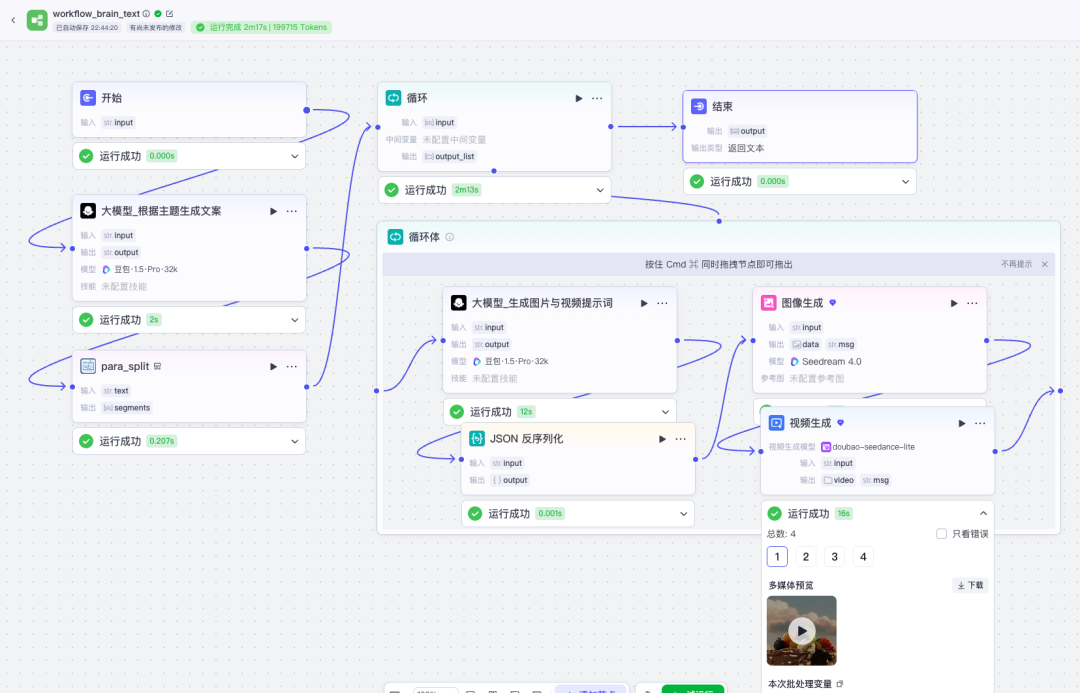
1.3 根据图片生成动态视频片段
接下来,我们基于图片生成动态视频。我们同样在循环体中加入生成视频的插件。 在循环的过程中,生成对应每一个文案的视频,由于我们生成的视频主要是用于练习和讲解,考虑到Token节约,我们选择生成视频为5秒,分辨率为480P。如果后续正式商业化产出,我们可以将生成视频的分辨率值设置为720P或1080P,以提升视频清晰度。
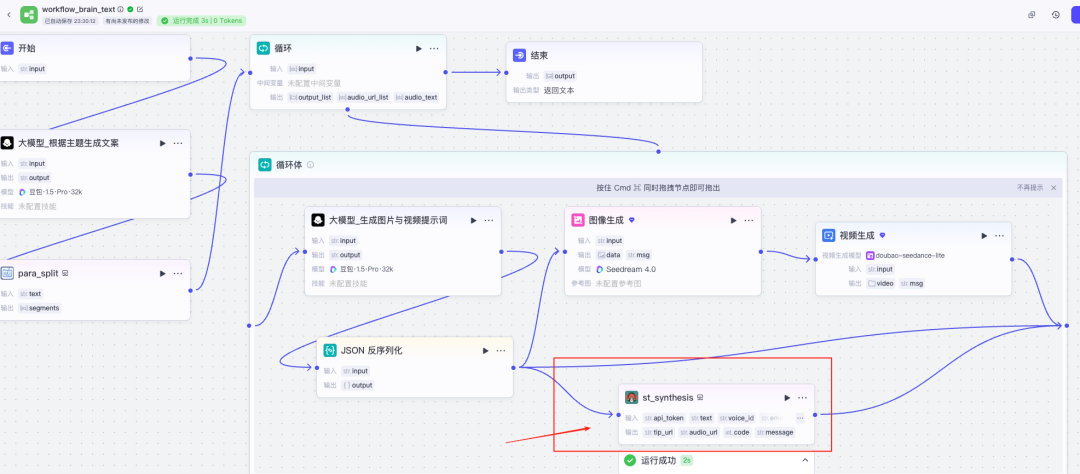
1.4 增加字幕和配音解说
同生成视频一样,我们在循环体中加入与视频对应的文案,同时调用插件,将文案转化为音频,用于后期合成视频中的声音。
1.5 整合视频
整合视频这一步的关键在于使用成熟的第三方插件,为了避免有广告嫌疑,我在此就不提供具体的三方API名称了,相关的这类产品有很多。
其核心思路是通过第三方插件的API,将声音、字幕和视频以批处理的方式传给API,最终我们获得第三方插件生成短视频的草稿链接,我们借助于第三方的客户端,或是通过链接下载完成整合的视频至本地电脑,然后上传至相应的短视频媒体平台。
二、实战验证
由于我们在最初的参数中做了限制,因此生成的视频播放时长比较短。视频的质量不是很理想,我们使用的工作流也比较简单。但可以证明使用Agent来自动完成短视频创作这条路是走得通的,后期可以随着我们经验的不断提升,可以用Agent制作出大片级的爆款短视频一定是可以的。
三、结语
本次实战,我们围绕科普短视频创作场景,手把手搭建了一个“科普短视频生成Agent”,从主题输入到完整视频产出,实现了全流程自动化,不仅解决了人工创作耗时耗力、效率低下的痛点,更通过实操环节,拆解了Agent的核心知识与底层逻辑,让大家既能复刻操作,也能理解Agent的工作原理。
对于个人创作者、初创工作室而言,Agent的核心价值在于“降本、提效、规模化”——它能让一个人完成一个团队的工作,无需投入大量人力成本,就能实现内容批量产出,快速接受市场检验。
而对于想要学习Agent的新手而言,最核心的不是掌握多少工具,而是理解“Agent是决策者,工作流是执行路径,工具是执行手段”,先从简单场景入手,逐步扩展复杂功能,就能快速掌握Agent的搭建与使用技巧。
之前有人问,如何做到10万+的短视频播放量?我的回答是:一直做。只要我们方法正确,总有一天,我们会有量变引发质变,实现从0到1,从1到100的跨越。
未来已来,AI一定是一个很强大的生产工具,AI本身并不会淘汰员工,未来淘汰的是不会使用AI的员工。积极拥抱变化,快速学习起来,不论结果怎样,Just Do It!欢迎大家随时交流。
本文由人人都是产品经理作者【王佳亮】,微信公众号:【佳佳原创】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自作者提供






- 目前还没评论,等你发挥!


