
 起点课堂会员权益
起点课堂会员权益Kimi 2.5 震撼发布!万亿参数“大圣集群”现世,多项指标超越 GPT-5,国产模型正式进入“思维竞赛”时代
Moonshot AI的Kimi 2.5发布震撼全球AI圈,1万亿参数规模、原生INT4量化、100个分身并行协作的Agent Swarm等技术突破,不仅在HLE测试中超越GPT-5,更在普通电脑上实现高效运行。这款国产大模型通过MoE架构和量化感知训练,展示了前所未有的工程美学和思维深度,彻底改写了AI竞争的格局。

月之暗面(Moonshot AI)突然投下重磅炸弹:Kimi 2.5 正式发布并开源!
这不是一次简单的版本迭代。1万亿参数规模、原生 INT4 量化、支持 100 个分身并行协作的Agent Swarm(智能体集群)……当这一串硬核参数甩出来时,全球 AI 圈都被震动了。苹果大牛 Awni Hannun 惊叹:万亿模型竟然在两台 Mac 上就能跑起来 。更恐怖的是,在衡量模型“聪明极限”的 HLE 测试中,Kimi 2.5 直接干翻了尚未完全露面的 GPT-5。
国产模型,这次真的在“思维深度”上完成了对硅谷巨头的超越。
1. 万亿参数的“精算师”:MoE 架构的暴力美学
Kimi 2.5 采用了混合专家架构(MoE),总参数量达到了惊人的1 万亿(1T)。
但它并不是一个空有体量的“笨重巨兽”。通过精密的专家选择机制,Kimi 2.5 在推理时仅激活其中的 320 亿(32B)参数。这意味着它拥有万亿级的知识储备,却只需要轻量级模型的响应速度。
更让开发者兴奋的是,月之暗面在工程上实现了一个奇迹:原生 INT4 权重位量化。 通常万亿模型量化后会“变笨”,但 Kimi 2.5 通过量化感知训练,在性能几乎无损的前提下,将生成速度提升了2 倍。这也就是为什么,即便没有昂贵的 H100 集群,个人开发者用两台 M3 Ultra 芯片的 Mac 电脑也能流畅运行这个万亿巨无霸 。
2. 杀手级能力:Agent Swarm,从“单兵”到“集群”

如果说之前的 AI 是一个帮你写代码的“助手”,那 Kimi 2.5 就是一个能自主管理的“技术总监”。
Kimi 2.5 引入了全新的Agent Swarm(智能体集群)模式。 面对复杂任务,它不再单线思考,而是会根据需求自主创建最多100 个专项子智能体(分身)并行工作。
- 分工明确:它可以同时派出“AI 研究员”搜资料、“代码专家”写程序、“事实核查员”纠错。
- 效率爆炸:相比传统单线程模式,任务完成速度提升了约4.5 倍。
- 超强耐力:它能稳定执行 200 到 300 次工具调用而不“断片”,甚至能处理多达 1,500 次并行调用。
3. 视觉编程:给它一张截图,还你一个网站
Kimi 2.5 此次强化了原生多模态能力,尤其是“视觉编程”表现堪称惊艳。
你可以直接给它发一张精美的网页 UI 截图,甚至是一段视频。Kimi 2.5 能精准理解其中的布局、动态效果和交互逻辑,并直接输出生产级别的代码。 在测试中,它不仅复刻了复杂的 3D 效果,甚至能自主通过查看渲染结果进行“视觉 Debug”,直到代码运行效果与草图完全一致。
4. 榜单“屠夫”:全线 SOTA 的硬核实力
数据不会骗人。在最新的各项权威基准测试中,Kimi 2.5 展现了极强的统治力:


特别是在HLE测试中,这被公认为目前最难、最不容易被“刷榜”的逻辑测试,Kimi 2.5 的表现标志着它已经触及了目前 AI 推理能力的“天花板”。
5. API 价格:让大模型进入“一毛钱时代”
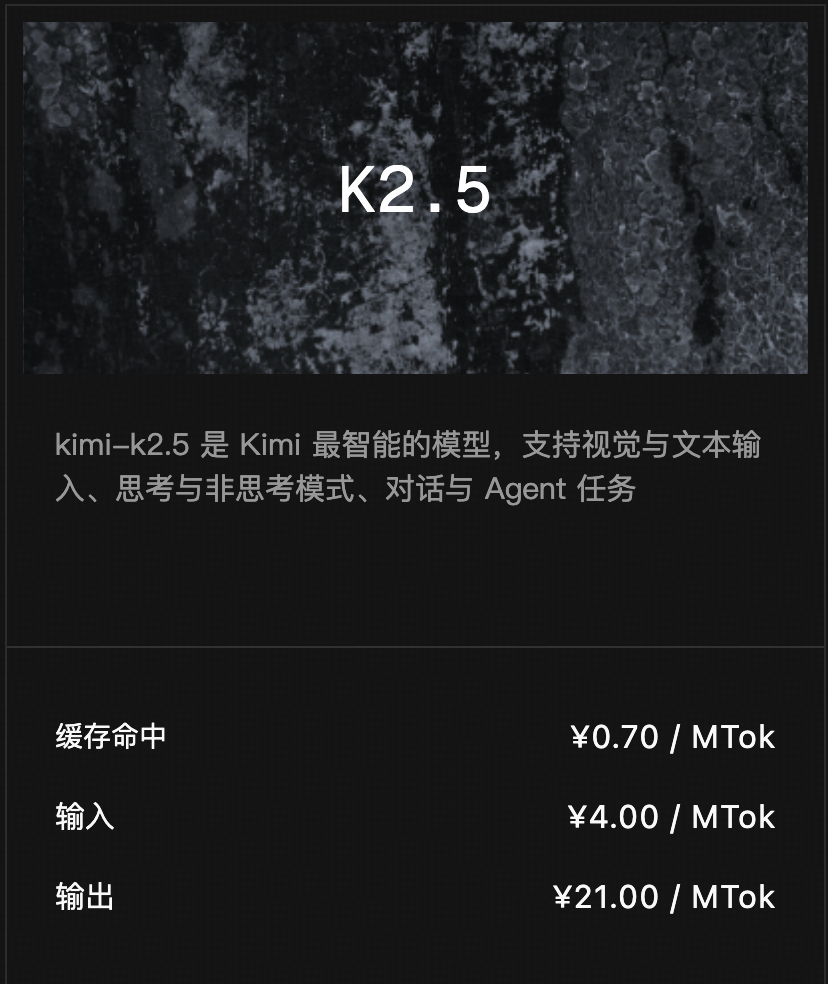
性能暴涨的同时,价格却在暴跌。Kimi 2.5 API 的定价极具攻击性:
- 缓存命中价格:仅需$0.10/MTok。
- 输入价格:$0.60/MTok,远低于同级别闭源模型。
这种低价策略配合其 SoTA 级的性能,意图非常明显:月之暗面要让 Kimi 2.5 成为 2026 年全球开发者构建智能体应用的“第一底座”。
结语:国产 AI 的下半场,是思维的较量
长期以来,国产大模型一直被贴着“追随者”的标签。但 Kimi 2.5 的出现改变了叙事逻辑。 它不再单纯比拼参数,而是通过MoE + Agent Swarm + 原生量化,在工程美学和思维深度上走出了一条独特的路。
当 AI 能够自主调度百人团队、能够对着一张草图思考编程、能够在普通电脑上跑出万亿参数的智慧时,我们知道,AI 的下半场竞争已经不再关乎“谁能说得更好”,而在于“谁能想得更深”。
本文由 @像素呼吸 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供






- 目前还没评论,等你发挥!


